爬虫实例-淘宝页面商品信息获取
------------恢复内容开始------------
一、完整代码:
在MOOC课上嵩天老师的课上有一个查找商品页面的实例,学习了一下,发现跟着嵩天老师的源代码已经爬不出来了。这是因为2019年开始淘宝搜索页面就必须登录了,所以要爬取商品内容必须登录账号,具体的header与cookie信息如下:
cookie登录信息可以登录淘宝页面后经过在元素控制台内部查找。(记得刷新)
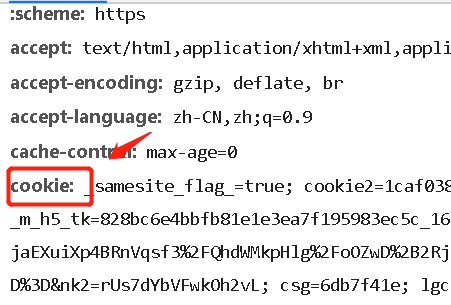
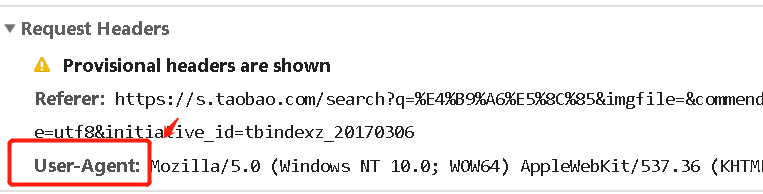
先给出完整代码
import requests import re def getHTMLText(url): try: header = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'cookie': '_samesite_flag_=t*********************kmn' } r = requests.get(url, timeout=30, headers=header) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parsePage(ilt, html): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("1312") def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号","价格","商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count,g[0],g[1])) def main(): goods = '手表' depth = 2 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44 * i) html = getHTMLText(url) parsePage(infoList, html) except: continue printGoodsList(infoList) main()
二、代码解析:
总共把代码分为三个部分:
1、获取商品页面信息==》getHTMLText
2、解析商品页面信息==》parsePage
3、打印商品信息 ==》printGoodsList
(一)、getHTMLText
def getHTMLText(url): try: header = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'cookie': '_samesite_flag_=t*********************kmn' } r = requests.get(url, timeout=30, headers=header) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return ""
1. 首先定义header部分,登录信息与浏览器信息等。
2. r.raise_for_status() 当爬取失败的时候会报错,让try进入except,使代码整体健壮。
3. r.encoding = r.apparent_encoding解析代码编码,让r资源的编码 = 显示的编码apparent_encoding
4. 最终返回r.text 文本部分
(二)、parsePage
def parsePage(ilt, html): try: plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html) tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("")
这个部分是代码最关键的部分,即核心代码,负责查找与解析r.text中的文本。
先说明其中的正则表达式
r'\"view_price\"\:\"[\d\.]*\"'
在淘宝搜索书包之后可以发现其商品价格前面的都有一个关键词 view_price,同理发现商品标题都有raw_title关键词:

其中\"view_price\"\:\"[\d\.]*\"之所以出现这么多\,是因为转义字符其意义是 查找"view_price: [\d.]*"这样的一个字符串,使用findall函数可以爬取全部的资源。
同理,经过商品标题可以选择title与raw_title不过最后选择了raw_title,因为title在一个商品信息内出现了两次。
最终plt 与 tlt 分别是所有商品信息的价格和标题,其序号是一一对应的。
for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price, title])
最终把所有商品信息的价格和名称放入列表ilt内
这plt去除外面的双引号后使用SPLIT方法吧view_price:129这样的商品元素分开,并取位置[ 1 ]上的元素,即商品的价格。
三、商品价格信息打印:printGoodsList
def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号","价格","商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count,g[0],g[1]))
先定义TPLT格式信息,最后使用count计数当做序号。
四、main()函数执行
def main(): goods = '手表' depth = 2 start_url = 'https://s.taobao.com/search?q=' + goods infoList = [] for i in range(depth): try: url = start_url + '&s=' + str(44 * i) html = getHTMLText(url) parsePage(infoList, html) except: continue printGoodsList(infoList)
根据查找淘宝页面的url我们可以发现其搜索的接口为 search?q=
并且其页面元素为44位一页,第一页为空 第二页为44 第三页为88
所以根据查找多少我们可以定义一个深度depth为查找的页面,遍历次数即每一次翻页的次数。
https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=6&ntoffset=6&p4ppushleft=1%2C48&s=0 https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s=44 https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=0&p4ppushleft=1%2C48&s=88
最终运行结果为:

