基于Storm的WordCount
Storm WordCount 工作过程
Storm 版本:
1、Spout 从外部数据源中读取数据,随机发送一个元组对象出去;
2、SplitBolt 接收 Spout 中输出的元组对象,将元组中的数据切分成单词,并将切分后的单词发射出去;
3、WordCountBolt 接收 SplitBolt 中输出的单词数组,对里面单词的频率进行累加,将累加后的结果输出。
Java 版本:
1、读取文件中的数据,一行一行的读取;
2、将读到的数据进行切割;
3、对切割后的数组中的单词进行计算。
Hadoop 版本:
1、按行读取文件中的数据;
2、在 Mapper()函数中对每一行的数据进行切割,并输出切割后的数据数组;
3、接收 Mapper()中输出的数据数组,在 Reducer()函数中对数组中的单词进行计算,将计算后的统计结果输出。
源代码
storm的配置、eclipse里maven的配置以及创建项目部分省略。
Mainclass
package com.test.stormwordcount;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class MainClass {
public static void main(String[] args) throws AlreadyAliveException, InvalidTopologyException {
//创建一个 TopologyBuilder
TopologyBuilder tb = new TopologyBuilder();
tb.setSpout("SpoutBolt", new SpoutBolt(), 2); tb.setBolt("SplitBolt", new SplitBolt(), 2).shuffleGrouping("SpoutBolt");
tb.setBolt("CountBolt", new CountBolt(), 4).fieldsGrouping("SplitBolt", new Fields("word"));
//创建配置
Config conf = new Config();
//设置 worker 数量
conf.setNumWorkers(2);
//提交任务
//集群提交
//StormSubmitter.submitTopology("myWordcount", conf, tb.createTopology());
//本地提交
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("myWordcount", conf, tb.createTopology());
}
}
SplitBolt 部分
package com.test.stormwordcount;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class SplitBolt extends BaseRichBolt{
OutputCollector collector;
/** * 初始化 */
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/** * 执行方法 */
public void execute(Tuple input) {
String line = input.getString(0);
String[] split = line.split(" ");
for (String word : split) {
collector.emit(new Values(word));
}
}
/** * 输出 */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
CountBolt 部分
package com.test.stormwordcount;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichBolt;
import backtype.storm.tuple.Tuple;
public class CountBolt extends BaseRichBolt{
OutputCollector collector;
Map<String, Integer> map = new HashMap<String, Integer>();
/** * 初始化 */
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/** * 执行方法 */
public void execute(Tuple input) {
String word = input.getString(0);
if(map.containsKey(word)){
Integer c = map.get(word);
map.put(word, c+1);
}else{
map.put(word, 1);
}
//测试输出
System.out.println("结果:"+map);
}
/** * 输出 */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
SpoutBolt 部分
package com.test.stormwordcount;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class SpoutBolt extends BaseRichSpout{
SpoutOutputCollector collector;
/** * 初始化方法 */
public void open(Map map, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
}
/** * 重复调用方法 */
public void nextTuple() {
collector.emit(new Values("hello world this is a test"));
}
/** * 输出 */
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("test"));
}
}
POM.XML 文件内容
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.test</groupId>
<artifactId>stormwordcount</artifactId>
<version>0.9.6</version>
<packaging>jar</packaging>
<name>stormwordcount</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>0.9.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.test.stormwordcount.MainClass</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
遇到的问题
基于Storm的WordCount需要eclipse安装了maven插件,之前的大数据实践安装的eclipse版本为Eclipse IDE for Eclipse Committers4.5.2,这个版本不自带maven插件,后续安装失败了几次(网上很多的教程都已经失效),这里分享一下我成功安装的方法:
使用链接下载,Help->Install New SoftWare
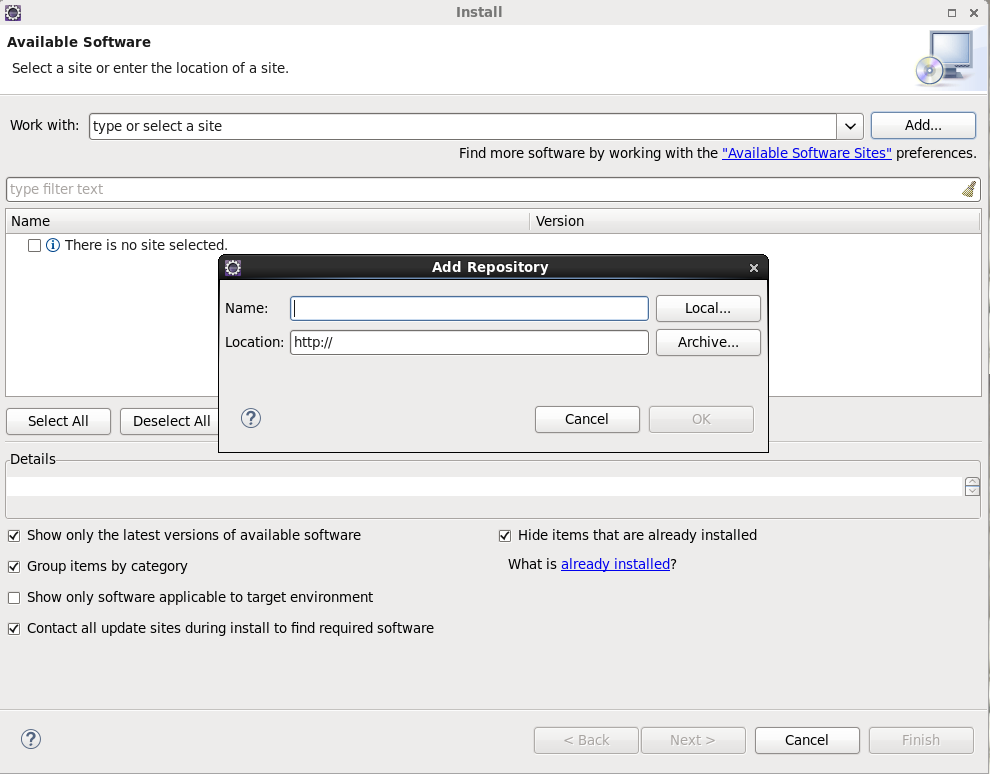
点击Add,name输入随意,在location输入下载eclipse的maven插件,下载地址可以这样获取
点击连接:http://www.eclipse.org/m2e/index.html 进入网站后点击download,拉到最下面可以看到很多eclipse maven插件的版本和发布时间,选在适合eclipse的版本复制链接即可。建议取消选中Contack all update sites during install to find required software(耗时太久)。
但是安装成功后还是无法配置(这里原因不太清楚,没找到解决办法),就直接上官网换成自带maven插件的JavaEE IDE了...
后续的maven的配置这些都比较顺利,第一次创建maven-archetype-quickstat项目报错,试了网上很多办法都还没成功,然后打开 Windows->Preferencs->Maven->Installation发现之前配置了的maven的安装路径没了...重新配置了下就可以创建项目了。
最后运行成功的结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号