
关于mvcc理解
1.并发事物带来了什么问题?
1.丢失修改 t1和t2两个事物分别对一个数据进行修改,t1先修改,t2事物后修改,t2的修改覆盖了t1的修改。
2.脏读 t1修改一个数据,t2读到了这个数据,随后t1撤销了这次修改,那么t2读到的就是脏数据。也就是事物a读取到了事物b已经修改但是尚未提交的数据,不符合隔离性
3.幻读 t1读取每个范围的数据,t2在这个范围内插入新的数据,t1再次读取这个范围的数据,此时读取的结果和第一次读取的结果不同。 事务a读取到了事务b新增的数据,不符合隔离性
4.不可重复读 t2读取一个数据,t1对该数据做了修改。如果t2再次读取这个数据,此时读取的结果和第一次读取的是不同的。 事务a读取到了事务b已经修改和删除的数据,不符合隔离性 在并发环境下,事务的隔离性很难保证,因此会出现很多并发一致性问题。所以要通过锁和隔离级别实现事物的隔离性 注意: 1.并发不一致的问题(都是因为隔离性没有保证,因为并发情况下,所有的事物都会去争抢资源,在mysql中也就是数据。所以通过锁来锁定数据,通过隔离级别来保证读一致性) 产生并发不一致的问题主要原因是破坏了事物的隔离性,解决办法是通过并发控制来保证隔离性。 并发控制可以通过锁来实现,但是封锁操作需要用户自己控制,相当复杂。 数据库管理系统提供了事务的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。 show variables like "tx_isolation"; # 查看mysql的默认隔离级别 2.不可重复读和幻读的区别 不可重复读的重点是修改和删除: 同样的条件,你读取过的数据,再次读取出来发现值不一样了 幻读的重点在于新增: 同样的条件,第 1 次和第 2 次读出来的记录数不一样
2.mysql中的mvcc
MVCC(Mutil-Version Concurrency Control),就是多版本并发控制。MVCC 是一种并发控制的方法,为了就是解决在多并发情况下出现的问题(个人觉得是读一致性的问题,以及mvcc实现了非阻塞读)。
MVCC使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能。 在Mysql的InnoDB引擎中就是指在已提交读(READ COMMITTD)和可重复读(REPEATABLE READ)这两种隔离级别下的事务对于SELECT操作会访问版本链中的记录的过程。 注意: 1.MVCC手段只适用于Msyql隔离级别中的读已提交(Read committed)和可重复读(Repeatable Read). 2.Read uncimmitted由于存在脏读,即能读到未提交事务的数据行,所以不适用MVCC. 原因是MVCC的创建版本和删除版本只在事务提交后才会产生。 3.串行化由于是会对所涉及到的表加锁,并非行锁,自然也就不存在行的版本控制问题。
innodb存储引擎实现mvcc:
InnoDB的MVCC,是通过undo来实现的,innodb的每行纪录在后面保存两个隐藏的列(其实是三个)。这两个列,一个保存了行的创建时间,一个保存了行的过期时间(或删除时间),当然存储的并不是实际的时间值,而是系统版本号。
每开始一个新的事务,系统版本号都会自动递增。事务开始时刻的系统版本号会作为事务的版本号,用来和查询到的每行纪录的版本号进行比较。
mvcc最大的好处就是读不加锁,读写不冲突。在读多写少的oltp应用中是非常重要的,极大的提升了系统的并发性。
undo两个最重要的作用:
回滚事务,实现mvcc(trx_id和roll_ptr来实现)
在mvcc并发控制中,读操作可分为两类:
快照读
读取的记录可见版本可能是是历史版本,不需要加锁
select * from xx where xxx
当前读:
读取的记录都会加上锁,保证并发的事务不会修改这条记录。特殊的读操作,插入,更新,删除都是属于特殊的当前读,需要加锁
select * from xxx where ? lock in share mode
select * from xxx where >for update
insert xxxx
update xxxx
delete xxxx

3.什么是版本链
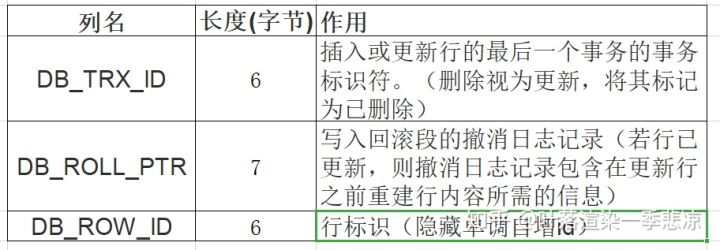
在InnoDB引擎表中,它的聚簇索引记录中有两个必要的隐藏列:
trx_id
这个id用来存储的每次对某条聚簇索引记录进行修改的时候的事务id。
roll_pointer
每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中。
这个roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。
(注意,插入操作的undo日志没有这个属性,因为它没有老版本,undo日志里面的就是最新的数据版本)。
![]()
比如现在有个事务id是60的执行的这条记录的修改语句
![]()
此时在undo日志中就存在版本链
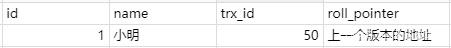
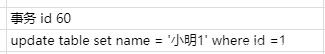

4.readview
已提交读和可重复读的区别就在于它们生成ReadView的策略不同。
ReadView中主要就是有个列表来存储我们系统中当前活跃着的读写事务,也就是begin了还未提交的事务。通过这个列表来判断记录的某个版本是否对当前事务可见。
读已提交隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView。
在读已提交的模式下,每次开启新的事物,就会去undo日志中拿到最新的版本数据
可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView。
在可重复度的模式下,多少次事物都使用的时第一次获取到的undo日志中的版本数
RC和RR级别下readview的

RR和RC级别下如何访问数据
对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的, 核心问题就是:
需要判断一下版本链中的哪个版本是当前事务可见的。为此,设计InnoDB的大叔提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容: m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。 min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。 max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。 # 注意:max_trx_id并不是m_ids中的最大值,事务id是递增分配的。比方说现在有id为1,2,3这三个事务,之后id为3的事务提交了。那么一个新的读事务在生成ReadView时,m_ids就包括1和2,min_trx_id的值就是1,max_trx_id的值就是4。 creator_trx_id:表示生成该ReadView的事务的事务id。 小贴士: 我们前边说过,只有在对表中的记录做改动时(执行INSERT、DELETE、UPDATE这些语句时)才会为事务分配事务id,否则在一个只读事务中的事务id值都默认为0。胡说八道,为0还怎么搞mvcc多版本读? 有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见: 如果被访问版本的trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。 如果被访问版本的trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。 如果被访问版本的trx_id属性值大于或等于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。 如果被访问版本的trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。 如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
undo在内存中,什么时候删除?
1 insert
commit后直接删除
2 update
设当前活跃事务集合C,其最小值为cmin,nextsac
当undo sac < cmin,或当C为空且undo sac < nextsac时,undo sac沉默,对将来所有事务可见,则undo sac链表下级 undo sac1可删除
5.innodb实现的mvcc
在InnoDB中,会在每行数据后添加两个额外的隐藏的值来实现MVCC,这两个值一个记录这行数据何时被创建,另外一个记录这行数据何时过期(或者被删除)。 在实际操作中,存储的并不是时间,而是事务的版本号,每开启一个新事务,事务的版本号就会递增。 在可重读Repeatable reads事务隔离级别下: SELECT时,读取创建版本号<=当前事务版本号,删除版本号为空或>当前事务版本号。 INSERT时,保存当前事务版本号为行的创建版本号 DELETE时,保存当前事务版本号为行的删除版本号 UPDATE时,插入一条新纪录,保存当前事务版本号为行创建版本号,同时保存当前事务版本号到原来删除的行 通过MVCC,虽然每行记录都需要额外的存储空间,更多的行检查工作以及一些额外的维护工作,但可以减少锁的使用,大多数读操作都不用加锁,读数据操作很简单,性能很好,并且也能保证只会读取到符合标准的行,也只锁住必要行。 我们不管从数据库方面的教课书中学到,还是从网络上看到,大都是上文中事务的四种隔离级别这一模块列出的意思,RR级别是可重复读的,但无法解决幻读,而只有在Serializable级别才能解决幻读。
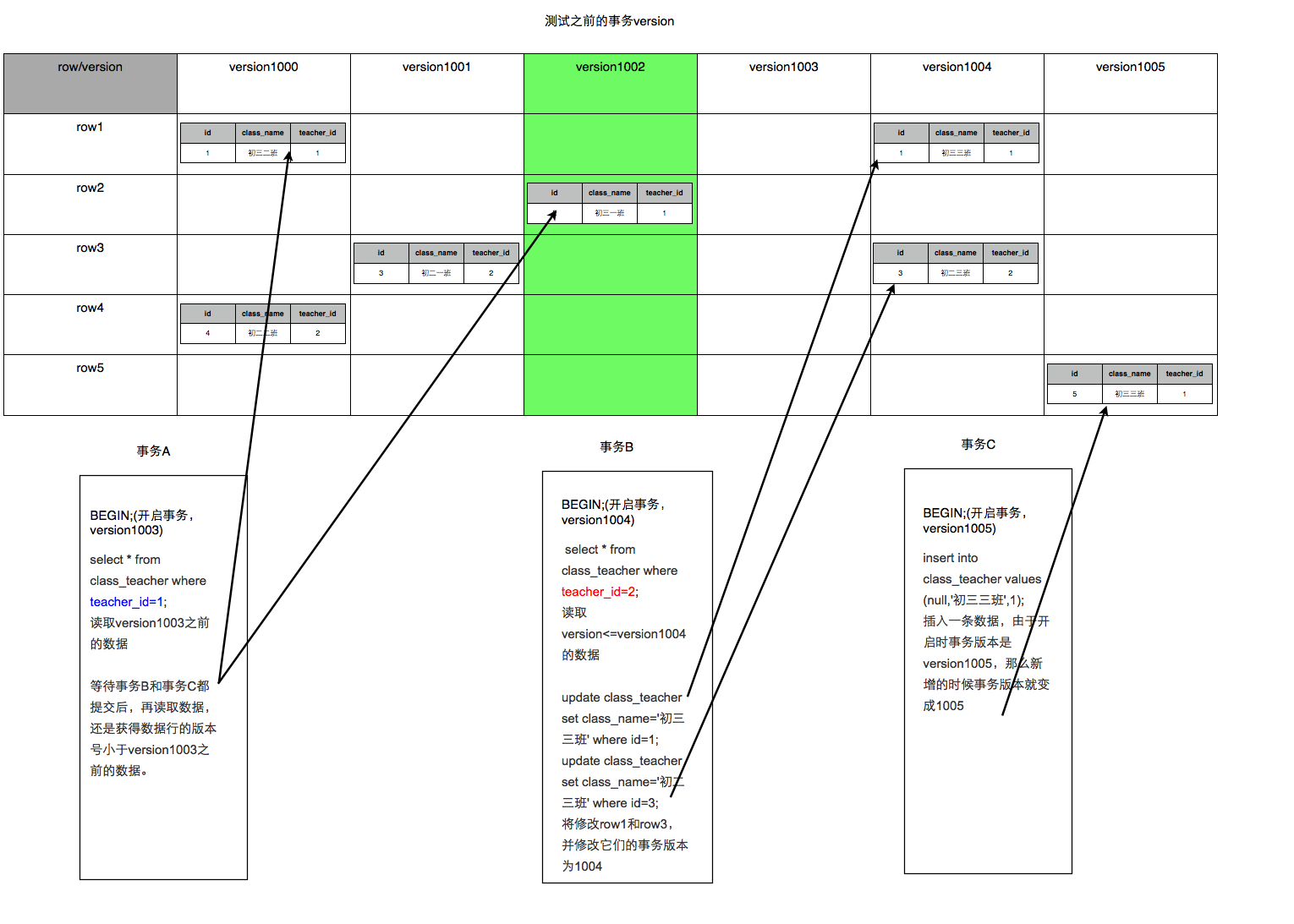
于是我就加了一个事务C来展示效果。在事务C中添加了一条teacher_id=1的数据commit,RR级别中应该会有幻读现象,事务A在查询teacher_id=1的数据时会读到事务C新加的数据。
但是测试后发现,在MySQL中是不存在这种情况的,在事务C提交后,事务A还是不会读到这条数据。可见在MySQL的RR级别中,是解决了幻读的读问题的
6.mvcc总结
客观上,我们认为他就是乐观锁的一整实现方式,就是每行都有版本号,保存时根据版本号决定是否成功。
但由于Mysql的写操作会加排他锁(前文有讲),如果锁定了还算不算是MVCC?
了解乐观锁的小伙伴们,都知道其主要依靠版本控制,即消除锁定,二者相互矛盾,so从某种意义上来说,Mysql的MVCC并非真正的MVCC,他只是借用MVCC的名号实现了非阻塞读而已。
快照读的幻读通过mvcc来解决了,当前读的幻读通过行锁+next lock组成的gap锁来解决的
提高并发的演进思路,就在如此:
-
普通锁,本质是串行执行
-
读写锁,可以实现读读并发
-
数据多版本,可以实现读写并发
7.mysql只读事务
#------ 设置事务隔离登记----- #读已提交 set session transaction isolation level read committed ; #读未提交 set session transaction isolation level read uncommitted ; #可重复度 mysql默认级别 set session transaction isolation level repeatable read ; #串行化 set session transaction isolation level serializable ; #------ 开启事务----- #开启可读写事务 start transaction; #开启只读事务 start transaction read only; #开启读写事务 与start transaction;等价 start transaction read write; # 提交事务 commit; # 事务回滚 rollback; #------事务挂起----- #记录事务保存点 mm为保存点自定义的id savepoint mm; #回滚事务到mm 保存点.直接运行rollback全部回滚 ROLLBACK TO mm; #删除保存点 RELEASE SAVEPOINT mm; # 获取事务隔离类 如 read committed等 SHOW VARIABLES LIKE 'transaction_isolation';
8.mvcc文章
https://draveness.me/database-concurrency-control https://www.zhihu.com/question/67739617 # 知乎上mvcc和锁的案例 https://baijiahao.baidu.com/s?id=1629409989970483292&wfr=spider&for=pc # 百度百科上mvcc的案例
https://zhuanlan.zhihu.com/p/75737955
https://www.cnblogs.com/silyvin/p/13808439.html
pass
上帝说要有光,于是便有了光;上帝说要有女人,于是便有了女人!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号