python进阶之 网络编程
other
互联网协议按照功能不同分为osi七层或tcp/ip五层或tcp/ip四层
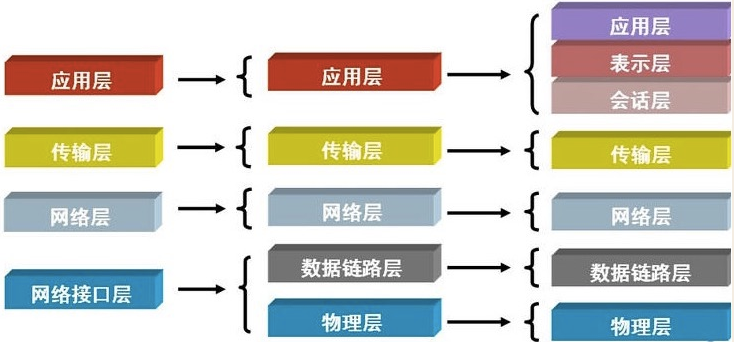
每一层的作用

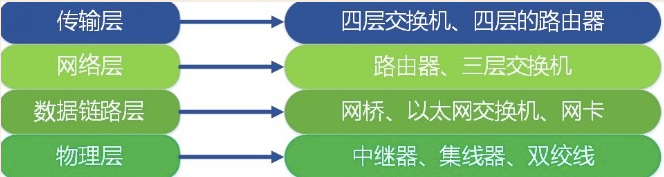
每层运行常见的物理设备
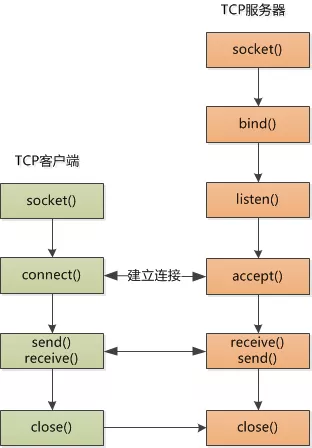
socket五层通讯流程
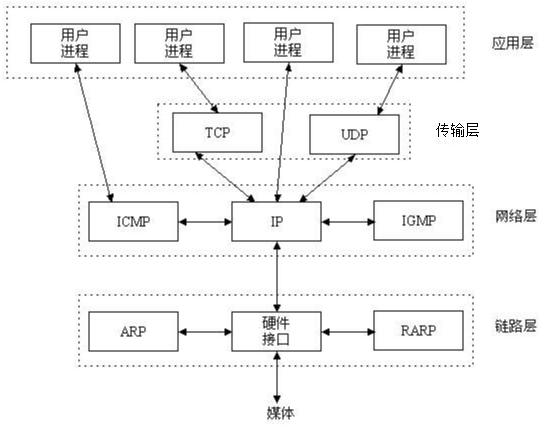
osi每层作用


1.应用层:为应用软件提供接口,使应用程序能够使用网络服务 常见的应用协议:http80 https443 dns53 ftp(20/21) smtp(25) pop3(110) telnet(23) 2.表示层:数据的解码和编码 加密和解密 压缩和解压缩 图片:jpg,gif 音频:MP3,wma,aac 视频:MP4,avi 3.会话层:负责建立管理和终止表示层实体之间的会话链接 在设备或节点之间提供会话控制,协调通信过程。 并提供三种不同的方式(单工,半双工,全双工)来组织他们之间的通信 4.传输层(tcp/udp):负责建立端到端的连接,保证报文在端到端之间进行传输,负责数据重传,冗余校验等 服务点编址,分段与重组,连接控制,流量控制,差错控制 5.网络层:为网络设备逻辑寻址,进行路由选择,路由表维护等等 负责将分组数据从源端传输到目的端, 代表设备:路由器和三层交换机 6.数据链路层:在不可靠的物理链路上提供可靠的数据传输服务,把封装好数据帧从(一跳)节点移动到另一节点(另一跳) 组帧,物理编址,流量控制,差错控制,接入控制 代表设备:交换机 7.物理层:负责把逐个的比特从一跳(结点)移动到另一跳(结点)。 定义接口和媒体的物理特性(线序、电压、电流) 定义比特的表示、数据传输速率、信号的传输模式 定义网络物理拓扑(网状、星型、环型、总线型等拓扑) 代表:集线器
1.tcp和udp协议的区别
tcp/ip协议简介:
TCP/IP协议(传输控制协议/互联网协议)不是简单的一个协议,而是一组特别的协议,包括:TCP,IP,UDP,ARP等,这些被称为子协议。在这些协议中,最重要、最著名 的就是TCP和IP。因此,大部分网络管理员称整个协议族为“TCP/IP”。
TCP协议
面向连接\可靠\慢\对传递的数据的长短没有要求
两台机器之间要想传递信息必须先建立连接
之后在有了连接的基础上,进行信息的传递
可靠 : 数据不会丢失 不会重复被接收
慢 : 每一次发送的数据还要等待结果
三次握手和四次挥手
UDP协议
无连接\不可靠\快\不能传输过长的数据0
机器之间传递信息不需要建立连接 直接发就行
不可靠 : 数据有可能丢失
TCP(Transmission Control Protocol)可靠的、面向连接的协议(eg:打电话)、传输效率低全双工通信(发送缓存&接收缓存)、面向字节流。使用TCP的应用:Web浏览器;文件传输程序。
UDP(User Datagram Protocol)不可靠的、无连接的服务,传输效率高(发送前时延小),一对一、一对多、多对一、多对多、面向报文(数据包),尽最大努力服务,无拥塞控制。使用UDP的应用:域名系统 (DNS);视频流;IP语音(VoIP)。
![]()
import socket
sk = socket.socket()
sk.bind(('0.0.0.0',9090))
sk.listen(5)
conn,addr = sk.accept()
accept 相当于和客户端的connect 一起完成了TCP的三次握手
至于之前的sk, 它只起到一个大门的作用了, 意思是说,欢迎敲门, 进门之后我将为你生成一个独一无二的socket描述符sk!
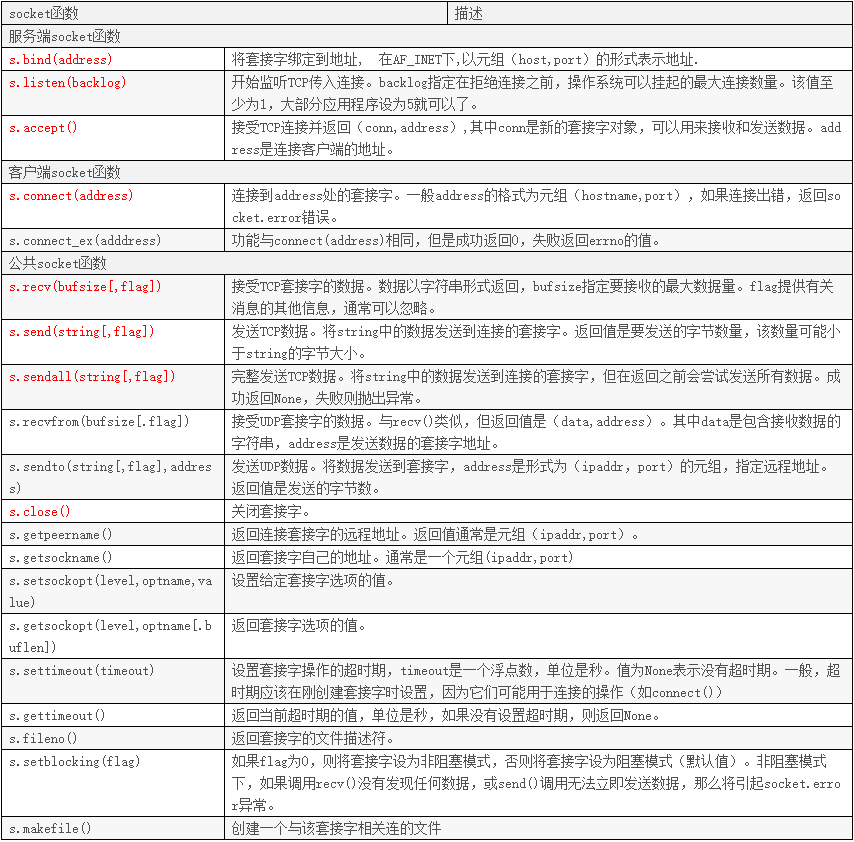
2.socket模块
socket模块方法

socket各个方法的解释:
socket简介
套接字简介?
套接字起源于 20 世纪 70 年代加利福尼亚大学伯克利分校版本的 Unix,即人们所说的 BSD Unix。 因此,有时人们也把套接字称为“伯克利套接字”或“BSD 套接字”。一开始,套接字被设计用在同 一台主机上多个应用程序之间的通讯。这也被称进程间通讯,或 IPC。套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的
什么是socket? 建立网络通信连接至少要一对端口号(socket)。
socket本质是编程接口(API),对TCP/IP的封装,TCP/IP也要提供可供程序员做网络开发所用的接口,这就是Socket编程接口;
HTTP是轿车,提供了封装或者显示数据的具体形式;Socket是发动机,提供了网络通信的能力。
socket又称为套接字,它是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,
Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
两种套接字:基于文件和面向网络的
基于文件的:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
基于网络的:AF_INIT
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址
家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET)
特殊意义的解释socket:
socekt又称为‘套接字’,用于描述IP和地址端口,是一个通信链路的句柄,应用程序通常通过套接字向网络发出请求或者应答网络请求。
socket起源于Unix,所以也遵从“一切皆文件”的基本哲学,对于文件,进行打开/读取/关闭的操作模式。
socket就是该模式的一个实现,socket即是一种特殊的文件,一些socket函数就是对其进行的操作(读/写IO、打开、关闭)。
socket和file文件的区别:
file模块是针对指定文件进行打开、读写、关闭操作。
socket模块是针对服务器和客户端socket进行打开、读写、关闭操作。
python中socket模块:
地址簇:
socket.AF_INET IPv4(默认)
socket.AF_INET6 IPv6
socket.AF_UNIX 只能够用于单一的Unix系统进程间通信
类型:
socket.SOCK_STREAM 流式socket , for TCP (默认)
socket.SOCK_DGRAM 数据报式socket , for UDP
tcp/ip和http的关系?
tcp/ip协议是传输层协议,主要解决数据如何在网络中传输,而HTTP协议是应用层协议,主要解决如何包装数据。
我们在传输数据时,可以只使用(传输层)TCP/IP协议,但是那样的话,如果没有应用层,便无法识别数据内容。
如果想要使传输的数据有意义,则必须使用到应用层协议。 应用层协议有很多,比如HTTP、FTP、TELNET等,也可以自己定义应用层协议。
WEB使用HTTP协议作应用层协议,以封装HTTP文本信息,然后使用TCP/IP做传输层协议将它发到网络上。”
socket对象
Socket对象 sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM,0) 参数一:地址簇 参数 描述 socket.AF_INET IPv4(默认) socket.AF_INET6 IPv6 ocket.AF_UNIX 只能够用于单一的Unix系统进程间通信 参数二:类型 参数 描述 socket.SOCK_STREAM 流式socket , for TCP (默认) socket.SOCK_DGRAM 数据报式socket , for UDP socket.SOCK_RAW 原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以;其次,SOCK_RAW也可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头。 socket.SOCK_RDM 是一种可靠的UDP形式,即保证交付数据报但不保证顺序。SOCK_RAM用来提供对原始协议的低级访问,在需要执行某些特殊操作时使用,如发送ICMP报文。SOCK_RAM通常仅限于高级用户或管理员运行的程序使用。 socket.SOCK_SEQPACKET 可靠的连续数据包服务 Socket类方法 方法 描述 s.bind(address) 将套接字绑定到地址。address地址的格式取决于地址族。在AF_INET下,以元组(host,port)的形式表示地址。 sk.listen(backlog) 开始监听传入连接。backlog指定在拒绝连接之前,可以挂起的最大连接数量。 sk.setblocking(bool) 是否阻塞(默认True),如果设置False,那么accept和recv时一旦无数据,则报错。 sk.accept() 接受连接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据。address是连接客户端的地址。 sk.connect(address) 连接到address处的套接字。一般,address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 sk.connect_ex(address) 同上,只不过会有返回值,连接成功时返回 0 ,连接失败时候返回编码,例如:10061 sk.close() 关闭套接字连接 sk.recv(bufsize[,flag]) 接受套接字的数据。数据以字符串形式返回,bufsize指定最多可以接收的数量。flag提供有关消息的其他信息,通常可以忽略。 sk.recvfrom(bufsize[.flag]) 与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。 sk.send(string[,flag]) 将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。即:可能未将指定内容全部发送。 sk.sendall(string[,flag]) 将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。内部通过递归调用send,将所有内容发送出去。 sk.sendto(string[,flag],address) 将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。该函数主要用于UDP协议。 sk.settimeout(timeout) 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。 sk.getpeername() 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 sk.getsockname() 返回套接字自己的地址。通常是一个元组(ipaddr,port) sk.fileno() 套接字的文件描述符
基于tcp协议(流式socket):是两个进程之间的通信,通过端口号来区分不同进程
import socket sk = socket.socket() #)返回的用于监听和接受客户端的连接请求的套接字 # sk.bind(('192.168.16.96',9090)) sk.bind(('0.0.0.0',9090)) #能接收到所有的ip的访问 sk.listen(5) #监听链接,并且设置监听个数, conn,addr = sk.accept() # hold住,等待用户链接,accept()接受一个客户端的连接请求,并返回一个新的套接字,与客户端通信是通过这个新的套接字上发送和接收数据来完成的。 #每个连接进来的客户端,都会通过accept函数返回一个不同的客户端的socket对象和属于客户端的套接字 #bytes:是字节 b'kobe' #str:字符串类型 'kobe' #str----编码(encode)---->bytes #bytes-----解码(decode)--->str #英文字符串可以直接加b转成bytes #中文的必须的加上''.encode('utf-8') #发送回复信息,在网络传输中的最小单位为字节,所以,要将数据转为字节格式 conn.send('我接受到了'.encode('utf-8')) ret = conn.recv(4096) print(ret.decode('utf-8')) conn.close() #conn.close和cilent的sk.close()是四次挥手的过程 sk.close() #关闭socket,不接受任何client请求 import socket sk =socket.socket() sk.connect(('192.168.16.96',9090)) #只和server的accept对应 ret = sk.recv(1024) print(ret.decode('utf-8')) sk.send('你好啊'.encode('utf-8')) sk.close()
import socket sk =socket.socket() sk.connect(('192.168.16.96',9090)) #只和server的accept对应 ret = sk.recv(1024) print(ret.decode('utf-8')) sk.send('你好啊'.encode('utf-8')) sk.close()
基于udp协议(报文式socket)
import socket sk = socket.socket(type=socket.SOCK_DGRAM) #SOCK_DGRAM指的是udp协议 sk.bind(('192.168.16.96',8081)) while True: msg,client_addr = sk.recvfrom(1024) #在udp协议中,recvfrom接收返回的时候能接收到客户端的信息msg和客户端的链接信息client_addr, #在tcp协议中,在等待连接的conn,addr = sk.accept()会接受到conn客户端的socket和客户端的链接信息 print(str(client_addr)+":"+msg.decode('utf-8')) content = input('>>>') sk.sendto(content.encode('utf-8'),client_addr) #通过sendto和客户端的连接信息发送消息 sk.close()
import socket client_addr= ('192.168.16.96',8081) sk = socket.socket(type=socket.SOCK_DGRAM) while True: connect = input(">>>>") if connect.upper() !='Q': sk.sendto(connect.encode('utf-8'),client_addr) msg = sk.recv(1024).decode('utf-8') if msg.upper() == 'Q': break print(str(client_addr)+":"+msg) else: break
注意: 1.tcp协议服务端是通过accept来建立链接,获取客户端的链接信息 conn,addr = sk.accept() 通过recv来获取客户端消息 msg = sk.recv(1024).decode('utf-8')
通过send发送信息
conn.send('hello'.encode('utf-8'))
客户端需要连接服务端地址
sk.connect(服务器地址和端口)
客户端发送信息
sk.send('你好'.encode('utf-8'))
客户端接收信息
msg = sk.recv(1024).deocde('1024')
2.udp协议服务器是通过recvfrom来获取客户端发送的信息和客户端链接的信息
msg,addr1 = sk.recvfrom(1024)
通过sendto发送信息给客户端,要指定客户端信息
sk.sendto('hello'.encode('utf-8'),addr1)
udp客户端不需要链接服务器端,是通过sendto发送信息
sk.sendto('你好'.encode('utf-8'),服务器地址和端口)
通过recv来获取信息
msg = sk.recv(1024).decode('utf-8')
3.tcp黏包
什么叫做黏包?
一般所谓的TCP粘包是在一次接收数据不能完全地体现一个完整的消息数据。
为什么只有TCP通讯存在粘包?
主要原因是TCP是以流的方式来处理数据,并且能发送大量的数据,再加上网络上MTU的往往小于在应用处理的消息数据,所以就会引发一次接收的数据无法满足消息的需要,导致粘包的存在。
TCP协议拆包机制
当发送端缓冲区的长度大于网卡的(最大传输单元)时,tcp会将这次发送的数据拆成几个数据包发送出去。
MTU是Maximum Transmission Unit的缩写。意思是(网卡)网络上传送的最大数据包。MTU的单位是字节。 大部分网络设备的MTU都是1500。
如果本机的MTU比网关的MTU大,大的数据包就会被拆开来传送,这样会产生很多数据包碎片,增加丢包率,降低网络速度。
同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令时又会接到之前执行的另外一部分结果,这种就是黏包。
面向流的通信特点和Nagle(优化)算法
TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。 收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。 这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
对于空消息:tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),也可以被发送,udp协议会帮你封装上消息头发送过去。
可靠黏包的tcp协议:tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,
通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
黏包的两种情况
1,发送方的缓存机制:发送端需要等缓冲区满才发送出去,造成黏包(发送数据时间间隔很短,数据很小,会合到一起,产生黏包)
连续send两次且数据很小
2,接收方的缓存机制:接收不及时接收缓冲区的包,造成多个包接收(客户端发送一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿走上次剩余的数据,产生黏包。)
连续recv两次且第一个recv接收的数据小
为什么tcp传输是可靠的?
为何tcp是可靠传输,udp是不可靠传输 .tcp在数据传输时,发送端先把数据发送到自己的缓存中,然后协议控制将缓存中的数据发往对端,对端返回一个ack=1,发送端则清理缓存中的数据,对端返回ack=0,则重新发送数据,所以tcp是可靠的。 而udp发送数据,对端是不会返回确认信息的,因此不可靠
黏包处理
# -*- coding: utf-8 -*- # @Time : 2019/4/10 16:58 # @Author : p0st # @Site : # @File : 传递大文件server.py # @Software: PyCharm import time import json import struct import socket start_time = time.time() sk = socket.socket() ip_addr = (('127.0.0.1',9999)) sk.bind(ip_addr) sk.listen(5) conn,addr = sk.accept() num = conn.recv(4) l_num = struct.unpack('i',num)[0] #bytes类型的json的长度为45,因为struct.unpack是元组类型的 l_dic = conn.recv(l_num).decode('utf-8') #将bytes类型的json转成字符串类型的json dic = json.loads(l_dic) filesize = dic['file_size'] with open(dic['file_name'],'wb') as info: while filesize>=1024: content = conn.recv(1024) info.write(content) filesize -=1024 else: content = conn.recv(filesize) if content: info.write(content) conn.close() sk.close() print(time.time()-start_time)
# -*- coding: utf-8 -*- # @Time : 2019/4/10 17:03 # @Author : p0st # @Site : # @File : 传递大文件client.py # @Software: PyCharm import json import struct import socket import os sk = socket.socket() ip_addr = (('127.0.0.1',9999)) sk.connect_ex(ip_addr) file_path = input("请输入文件路径:>>>").strip() file_name = os.path.basename(file_path) #获取文件名字 file_size = os.path.getsize(file_path) #获取文件大小 s_dic = {'file_name':file_name,'file_size':file_size} j_s_dic = json.dumps(s_dic) #将字典序列化成json b_s_dic = j_s_dic.encode('utf-8') #将json转成bytes类脑,在网上传输 l_s_dic = len(b_s_dic) #常看bytes类型的长度 lalala = struct.pack('i',l_s_dic) #将bytes类型的长度通过struct的pack方法变成4个字节 sk.send(lalala) sk.send(b_s_dic) with open(file_path,'rb') as info: while file_size >= 1024: content = info.read(1024) sk.send(content) file_size -= 1024 else: content = info.read(file_size) if content: sk.send(content) sk.close() #1.将字典转成json,再转成bytes类型,查看其长度发送给服务器端 #2.将bytes类型的发送给服务器
发送大文件带注释版本
# -*- coding: utf-8 -*- # @Time : 2019/7/18 16:50 # @Author : p0st # @Site : # @File : server.py # @Software: PyCharm import struct import socket import hashlib import json import os my_file_path = os.path.join(os.path.dirname(__file__),'file') def socket_server(): ip_port = ('127.0.0.1',8080) server = socket.socket() # 创建socket对象 server.bind(ip_port) # 绑定ip地址和端口 server.listen(5) # 设置监听对象为5个 conn,addr = server.accept() # 设置等待连接 # 1.接收4个字节的固定长度 four_bytes = conn.recv(4) # 2.利用struct模块进行反解 head_len = struct.unpack('i',four_bytes)[0] # 3.接收bytes类型的数据 head_dic_json_bytes = conn.recv(head_len) # 4.将bytes类型的数据转成json类型的数据 head_dic_json = head_dic_json_bytes.decode('utf-8') # 5.将json类型的数据转成字典形式的数据 head_dic = json.loads(head_dic_json) # 6.边传输编计算MD5的值 md5 = hashlib.md5() with open(os.path.join(my_file_path,head_dic['new_file_name']),mode='wb') as info: while 1: data = conn.recv(1024) if data: md5.update(data) info.write(data) else: info.close() if md5.hexdigest() == head_dic['md5']: print('传输成功') break else: print('传输失败') break if __name__ == '__main__': socket_server()
# -*- coding: utf-8 -*- # @Time : 2019/7/18 16:50 # @Author : p0st # @Site : # @File : client.py # @Software: PyCharm import os import json import hashlib import socket import struct my_file_path = os.path.join(os.path.dirname(__file__),'1.png') def socket_client(): ip_port = ('127.0.0.1',8080) client = socket.socket() # 创建socket对象 client.connect(ip_port) # 1.制作字典了类型的数据 head_dic = { 'md5': md5(my_file_path), 'file_name': os.path.basename(my_file_path), 'file_size': os.path.getsize(my_file_path), 'new_file_name':'11.png', } # 2.将字典转换成json的数据类型 head_dic_json = json.dumps(head_dic) # 3.获取bytes类型的数据 head_dic_json_baytes = head_dic_json.encode('utf-8') # 4.获取bytes类型的字节数 head_len = len(head_dic_json_baytes) # 5.将bytes类型的总字节数转化成固定的4个字节 four_bytes = struct.pack('i',head_len) # 6.发送4个固定字节 client.send(four_bytes) # 7.发送head数据 client.send(head_dic_json_baytes) # 8.发送总数据 with open(my_file_path,mode='rb') as info: while 1: data = info.read(1024) if data: client.send(data) else: break def md5(file_path): md5 = hashlib.md5() with open(file_path, mode='rb') as info: while 1: data = info.read(1024) if data: md5.update(data) else: break return md5.hexdigest() #31e03dc9b5a06c91f63dbfee470f2c58 if __name__ == '__main__': socket_client()
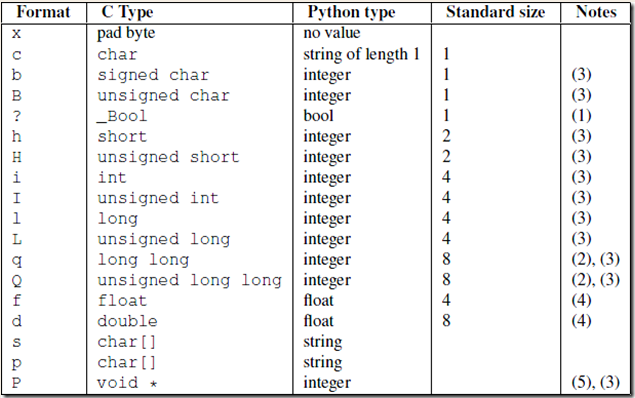
使用struct解决黏包:该模块可以把一个类型,如数字,转成固定长度的bytes
我们知道长度数字可以被转换成一个标准大小的4字节数字。因此可以利用这个特点来预先发送数据长度。
发送时 接收时
先发送struct转换好的数据长度4字节 先接受4个字节使用struct转换成数字来获取要接收的数据长度
再发送数据 再按照长度接收数据
理解下struct模块,通过该模块可以将一个类型,如数字,转成固定长度的bytes类型
![]()
import struct
# 将一个数字转化成等长度的bytes类型。
ret = struct.pack('i', 183346)
print(ret, type(ret), len(ret))
# 通过unpack反解回来
ret1 = struct.unpack('i',ret)[0]
print(ret1, type(ret1), len(ret1))
# 但是通过struct 处理不能处理太大
ret = struct.pack('l', 4323241232132324)
print(ret, type(ret), len(ret)) # 报错
并发的socketserver
import time import socketserver class Myserver(socketserver.BaseRequestHandler): def handle(self): conn = self.request for i in range(200): conn.send(('hello%s'%i).encode('utf-8')) print(conn.recv(1024)) time.sleep(0.5) print(conn) if __name__ == "__main__": HOST, PORT = "127.0.0.1", 9999 # 设置allow_reuse_address允许服务器重用地址 socketserver.TCPServer.allow_reuse_address = True # 创建一个server, 将服务地址绑定到127.0.0.1:9999 server = socketserver.TCPServer((HOST, PORT),Myserver) # 让server永远运行下去,除非强制停止程序 server.serve_forever() #sk.setblocking(False) #默认不阻塞,不阻塞模型,django和flask等等,setblocking做到和socketserver对tcp协议的非阻塞 # 非阻塞模型是一个突破,udp协议不用阻塞和不阻塞,udp协议能同时提供对多个客户端进行连接
import socket HOST, PORT = "127.0.0.1", 9999 data = "hello" # 创建一个socket链接,SOCK_STREAM代表使用TCP协议 with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock: sock.connect((HOST, PORT)) # 链接到客户端 sock.sendall(bytes(data + "\n", "utf-8")) # 向服务端发送数据 received = str(sock.recv(1024), "utf-8")# 从服务端接收数据 print("Sent: {}".format(data)) print("Received: {}".format(received))
数据报和数据流的区别
1.报文(message) 我们将位于应用层的信息分组称为报文。报文是网络中交换与传输的数据单元,也是网络传输的单元。报文包含了将要发送的完整的数据信息,其长短不需一致。报文在传输过程中会不断地封装成分组、包、帧来传输,封装的方式就是添加一些控制信息组成的首部,那些就是报文头。 2.报文段(segment) 通常是指起始点和目的地都是传输层的信息单元。 3.分组/包(packet) 分组是在网络中传输的二进制格式的单元,为了提供通信性能和可靠性,每个用户发送的数据会被分成多个更小的部分。在每个部分的前面加上一些必要的控制信息组成的首部,有时也会加上尾部,就构成了一个分组。它的起始和目的地是网络层。 4.数据报(datagram) 面向无连接的数据传输,其工作过程类似于报文交换。采用数据报方式传输时,被传输的分组称为数据报。通常是指起始点和目的地都使用无连接网络服务的的网络层的信息单元。 5.帧(frame) 帧是数据链路层的传输单元。它将上层传入的数据添加一个头部和尾部,组成了帧。它的起始点和目的点都是数据链路层。 6.数据单元(data unit) 指许多信息单元。常用的数据单元有服务数据单元(SDU)、协议数据单元(PDU)。 SDU是在同一机器上的两层之间传送信息。PDU是发送机器上每层的信息发送到接收机器上的相应层(同等层间交流用的)。 应用层——消息 传输层——数据段/报文段(segment) (注:TCP叫TCP报文段,UDP叫UDP数据报,也有人叫UDP段) 网络层——分组、数据包(packet) 链路层——帧(frame) 物理层——P-PDU(bit) 其实,segment,datagram,packet,frame是存在于同条记录中的,是基于所在协议层不同而取了不同的名字。我们可以用一个形象的例子对数据包的概念加以说明:我们在邮局邮寄产品时,虽然产品本身带有自己的包装盒,但是在邮寄的时候只用产品原包装盒来包装显然是不行的。必须把内装产品的包装盒放到一个邮局指定的专用纸箱里,这样才能够邮寄。这里,产品包装盒相当于数据包,里面放着的产品相当于可用的数据,而专用纸箱就相当于帧,且一个帧中通常只有一个数据包。 7.TCP数据流(TCP stream) Wireshark中是这么定义的:相同四元组(源地址,源端口,目的地址,目的端口)的包就为一条TCP流,即一条流有很多个包。
缓冲区
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。 write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。 TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。 read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。 这些I/O缓冲区特性可整理如下: 1.I/O缓冲区在每个TCP套接字中单独存在; 2.I/O缓冲区在创建套接字时自动生成; 3.即使关闭套接字也会继续传送输出缓冲区中遗留的数据; 4.关闭套接字将丢失输入缓冲区中的数据。 输入输出缓冲区的默认大小一般都是 8K,可以通过 getsockopt() 函数获取: 1.unsigned optVal; 2.int optLen = sizeof(int); 3.getsockopt(servSock, SOL_SOCKET, SO_SNDBUF,(char*)&optVal, &optLen); 4.printf("Buffer length: %d\n", optVal); socket缓冲区解释
缓冲区的作用
先结束的进程可以把结果放入缓冲区内,进行下面的工作,而后做完的进程可以从缓冲区内取出原来的数据继续工作。
缓冲区的作用是:在高速和低速设备之间起一个速度平滑作用;暂时存储数据;经常访问的数据可以放进缓冲区,减少对慢速设备的访问以提高系统的效率。提高上传和下载的速度
缓冲(buffering)
利用存储区缓解数据到达速度与离去速度不一致而采用的技术称为缓冲,此时同一数据只包含一个拷贝。例如:操作系统以缓冲方式实现设备的输入和输出操作主要是缓解处理机与设备之间速度不匹配的矛盾,从而提高资源利用律和系统效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号