python基础之 time,datetime,collections
1.time模块
python中的time和datetime模块是时间方面的模块 time模块中时间表现的格式主要有三种: 1、timestamp:时间戳,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量 2、struct_time:时间元组,共有九个元素组。 3、format time :格式化时间,已格式化的结构使时间更具可读性。包括自定义格式和固定格式。
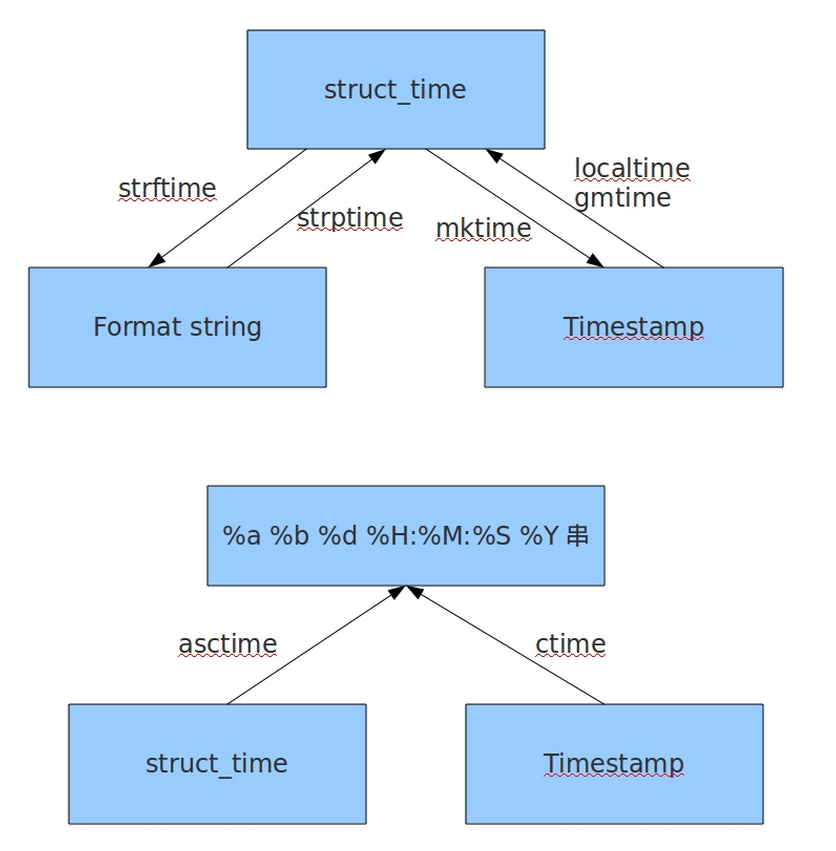
time的生成方法和time格式的转换
生成时间 import time 生成时间戳格式的时间: print(time.time()) #是机器看的时间,拿到的是float类型的 time = 1553066161.9998 生成结构化格式的时间: print(time.localtime()) #用在修改时间是使用的,得到一个命名元祖time.struct_time time = time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=15, tm_min=16, tm_sec=1, tm_wday=2, tm_yday=79, tm_isdst=0) 生成字符串格式的时间: print(time.strftime('%Y-%m-%d %H;%M:%S')) #或者'%Y-%m-%d %X/x time = 2019-03-20 15:17:04 时间格式转换 注意:字符串格式的时间不能与时间戳格式的时间相互转换 转换顺序:字符串时间 <----->结构化时间<---->时间戳 字符串时间---->结构化时间 t = '2018-11-30 12:30:00' f = time.strptime(t,'%Y-%m-%d %H:%M':%S) 结构化时间---->字符串时间 t = time.localtime() f = time.strftime('%Y-%m-%d %H:%M:%S',t) 结构化时间---->时间戳时间 t = time.localtime() f = (time.mktime(t)) 时间戳时间---->格式化时间 t = time.time() f = time.localtime(t)
注意:
time.strftime() #获取当前字符串时间
timt.time()=1553052418.0508 #获取当时间时间戳
时间戳--结构化 time.localtime(time.time())
结构化--时间戳 time.mktime(f) #f =time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=11, tm_min=25, tm_sec=56, tm_wday=2, tm_yday=79, tm_isdst=0)
结构化--字符串 time.strftime('%Y-%m-%d %H:%M:%S',f) f=结构化时间 格式可以少写
字符串--结构化 f =time.strptime('2019-03-20 10:40:00','%Y-%m-%d %H:%M:%S') 格式可以少写
time模块练习


t = time.time() #获取当前时间戳 t1 = t - 30*86400 #按照30天算,求出30天之前的时间戳 old_time = time.localtime(t1) #将时间戳时间转换成字符串时间 print(time.strftime('%Y-%m-%d %X',old_time))
t = '2018-11-30 12:30:00' t1 = time.strptime(t,'%Y-%m-%d %H:%M:%S') #将字符串时间转成格式化时间 t2 =time.mktime(t1 ) + 60*60*2 #将格式化时间转成时间戳+7200秒 t3 = time.localtime(t2) print(time.strftime('%Y-%m-%d %H:%M:%S',t3))
2.datetime模块
from datetime import datetime ,timedelta f =datetime.now() #精确到毫秒 datetime.now()拿到的是时间对象 f1=datetime.timestamp(f) #将时间对象转成时间戳 f2=datetime.fromtimestamp(f1) #将时间戳转换成时间对象 f3= datetime.strptime('1984-1-29','%Y-%m-%d') #将字符串转成时间戳 f5 = datetime.strftime(f,'%Y-%m-%d') #将时间对象转成字符串 当前时间减去2个小时 print(datetime.now() - timedelta(hours=2)) #这个是datetime的精华 注意;datetime没有结构化时间
注意:将a格式的转化为b格式的时间,就应该用b将a包起来,比如将结构化的时间转成字符串时间print(time.strftime('%Y-%m-%d %X',time.localtime()))
3.数据结构的补充(官方文档)
Counter:计数器
引入模块:from collections import Counter Counter 集成于 dict 类,因此也可以使用字典的方法,此类返回一个以元素为 key 、元素个数为 value 的 Counter 对象集合 #读取history中执行过最多的十条命令 import os from collections import Counter c = Counter() with open(os.path.expanduser('~/.bash_history')) as cmd_info: for line in cmd_info: cmd = line.strip().split() if cmd: c[cmd[0]]+=1 print(c.most_common(10))
常用操作:
sum(c.values()) # 所有计数的总数
c.clear() # 重置Counter对象,注意不是删除
list(c) # 将c中的键转为列表
set(c) # 将c中的键转为set
dict(c) # 将c中的键值对转为字典
c.items() # 转为(elem, cnt)格式的列表
Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象
c.most_common()[:-n:-1] # 取出计数最少的n-1个元素
c += Counter() # 移除0和负值
文章
nametuple:命名函数
引入模块:from collections import namedtuple namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。 这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便 #当元组的元素较多时们就可以使用命名元组来明确标明每个元素是什么意思 tu = namedtuple('people',['name','age','sex','hobby']) #是一个类 print(tu('kobe','19','man','抽烟,喝酒烫头')) ll =tu('kobe','19','man','抽烟,喝酒烫头') #实例化一个类。对象 print(ll.name) #调用名字之后返回值
deque:双端队列
导入模块 from collections import deque 使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。deque是为了高效实现插入和删除操作的双向列表。 适合用于队列和栈: #增 d = deque([1,2,3,4,5]) d.append(10) print(d) d.appendleft(-10) print(d) d.insert(2,9999) #在索引为2的地方添加999 print(d) #删 print(d.pop()) print(d.popleft()) deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict:默认字典
导入模块:from collections import defaultdict 使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict: from collections import defaultdict dd = defaultdict(lambda: 'N/A') dd['key1'] = 'abc' dd['key1'] # key1存在 'abc' dd['key2'] # key2不存在,返回默认值 'N/A' 注意:默认值是调用函数返回的,而函数在创建defaultdict对象时传入。除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
ordereddict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。 如果要保持Key的顺序,可以用OrderedDict: from collections import OrderedDict d = dict([('a', 1), ('b', 2), ('c', 3)]) print(d) {'a': 1, 'c': 3, 'b': 2} #dict的key是无序的
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) OrderedDict([('a', 1), ('b', 2), ('c', 3)]) #OrderedDict的key是有序的 注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序: >>> od = OrderedDict() >>> od['z'] = 1 >>> od['y'] = 2 >>> od['x'] = 3 >>> od.keys() # 按照插入的Key的顺序返回 ['z', 'y', 'x'] OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
other
双端队列和列表的区别:表现在效率,底层的数据结构上 向列表最后一个地方存值和删除都是非常快的 尽量写append() pop(), 列表中删除第一个或使用insert插入一个数据是非常耗费性能的,再删除的时候,后面的值都要向上和之前未删除的连接起来, 在插入的时候,在插入位置后面的数据都要向下后移一个位置,所以尽量写append() pop(),不要写insert和pop(0) 如果从中间插入或者删除比较频繁的操作使用:双端队列 如果单纯的增加append和删除pop的话,使用列表最好,但是尽量别使用pop(0)或者insert(1,'23')等
列表的sort()和sorted()的区别是什么?
一个在原有的基础上进行修改, alist.sort()
一个是生成一个新的列表 返回一个新的列表 sorted(),但是alist.sort(更节省内存)
list提供的方法都是修改这个列表本身
注意:reversed返回一个生成器
内置函数是在已有序列的基础上,再生成一个新的
filter zip map等内置函数返回的都是生成器或迭代器,为的就是节省内存
上帝说要有光,于是便有了光;上帝说要有女人,于是便有了女人!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号