Mybatis学习笔记
1.创建实体类(ORM,与数据库数据对应)
2.创建Dao接口
3.用mapper,一个xml文件实现Dao接口
4.mybatis-config.xml里注册mapper
2 CRUD
2.1 基本的增删改查
注意:
1.增删改需要提交事务
2.参数和返回值为基本类型可以不写
====Dao int deleteUser(int id); ====mapper <delete id="deleteUser">
2.2 模糊查询
方式一:在Java语句里添加%%
List<User> users = userdao.getUserByNameLike("%xiao%");
方式二:在sql里添加%%
select * from mybatis.user where name like "%"#{any}"%"
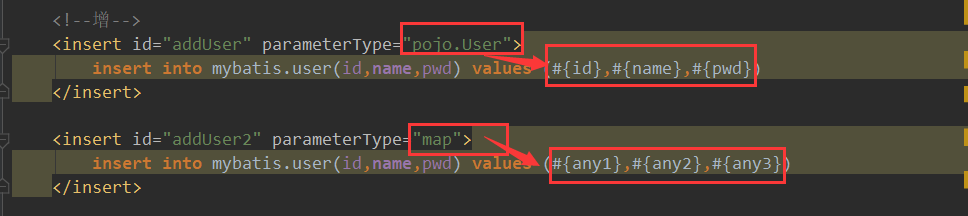
3 参数用map取代实体类及一切其他类
3.1 例子
比如
public interface UserDao {
User getUserById(int id);
int addUser(User user);
int updateUser(User user);
int deleteUser(int id);
}
参数可全部替换为map
public interface UserDao {
List<User> getUserList(Map<String,Object> map);
User getUserById(Map<String,Object> map);
int addUser(Map<String,Object> map);
int updateUser(Map<String,Object> map);
int deleteUser(Map<String,Object> map);
}
通过传递一个map就可以取代一切其他类型(实体类,基础类,,,)
HashMap<String, Object> map = new HashMap<>();
map.put("any1", 5);
map.put("any2", "test5");
map.put("any3", "12345");
userdao.addUser2(map);
3.2 打破了什么限制?
如果用实体类,则参数名被限制得死死的,不能有一丝疏忽。如果用map,参数名可自行设置。
3.3 参数一般用map或者注解
4 核心配置文件篇
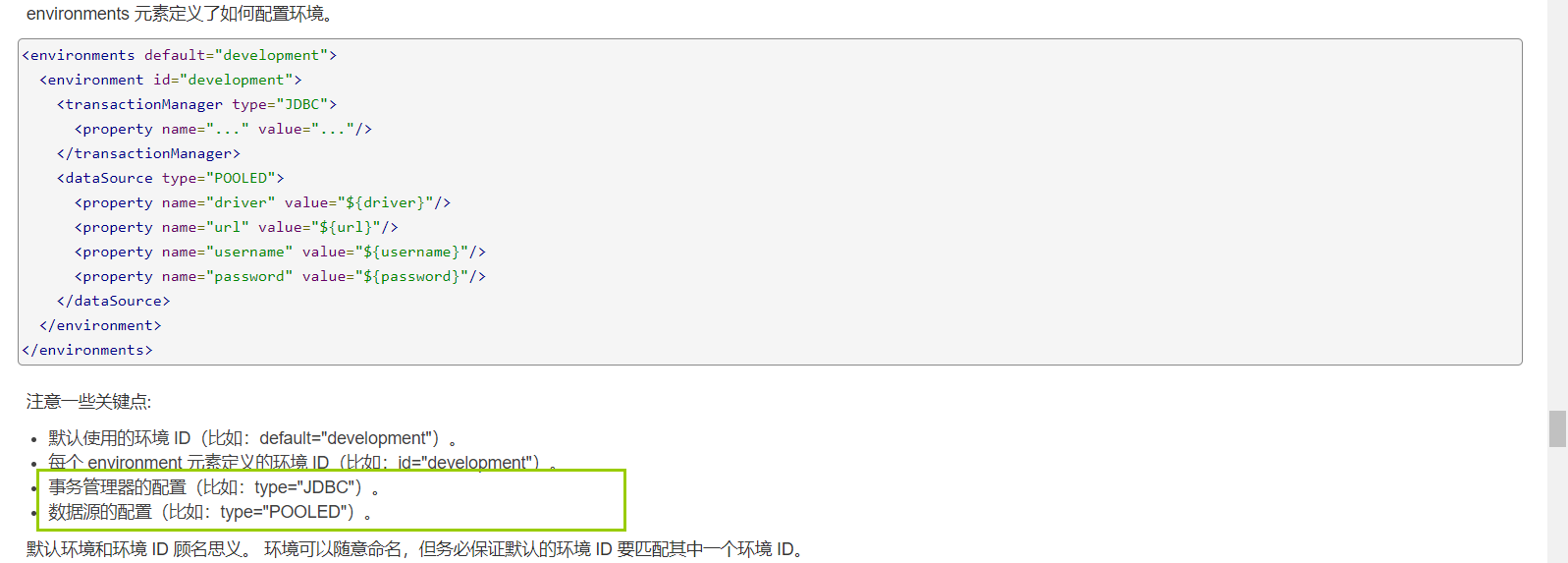
4.1 环境配置(environments)
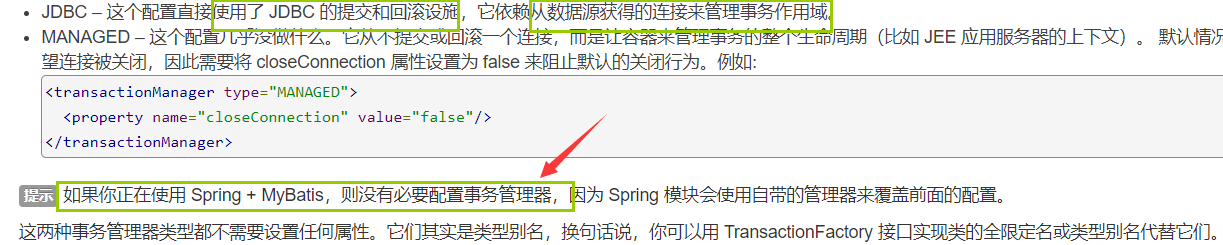
事务管理器
在 MyBatis 中有两种类型的事务管理器(也就是 type="[JDBC|MANAGED]"):
数据源
有三种内建的数据源类型(也就是 type="[UNPOOLED|POOLED|JNDI]")

4.2 映射器(mappers)
注意:
1.第二中不建议使用。
2.第三第四种,
(1)接口名与Mybatis的映射文件名一定要一模一样。即UserMapper(接口)和UserMapper.xml。
(2)必须把Mapper接口和XML配置文件放在同一包下才能使用。
<!-- 使用相对于类路径的资源引用 --> <mappers> <mapper resource="org/mybatis/builder/AuthorMapper.xml"/> <mapper resource="org/mybatis/builder/BlogMapper.xml"/> <mapper resource="org/mybatis/builder/PostMapper.xml"/> </mappers> <!-- 使用完全限定资源定位符(URL) 一般不用--> <mappers> <mapper url="file:///var/mappers/AuthorMapper.xml"/> <mapper url="file:///var/mappers/BlogMapper.xml"/> <mapper url="file:///var/mappers/PostMapper.xml"/> </mappers> <!-- 使用映射器接口实现类的完全限定类名 --> <mappers> <mapper class="org.mybatis.builder.AuthorMapper"/> <mapper class="org.mybatis.builder.BlogMapper"/> <mapper class="org.mybatis.builder.PostMapper"/> </mappers> <!-- 将包内的映射器接口实现全部注册为映射器 --> <mappers> <package name="org.mybatis.builder"/> </mappers>
4.3 属性(properties)
就是一个键值对,在任何可以使用<properties resource="">标签的地方都可以引用。
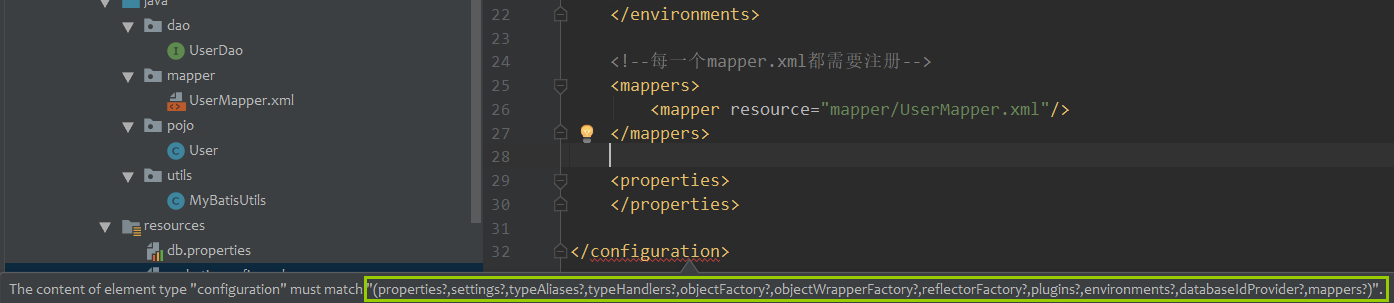
补充:xml中,标签可规定顺序。mybatis核心配置文件就是。
4.4 类型别名(typeAliases)
为Java类型设置一个较短(较好记)的名字
1 为类设置一个别名
语法
<typeAliases> <typeAlias type="domain.blog.Author" alias="Author"/> ... </typeAliases>
2 指定一个包名,批量为类设置别名
扫描实体类的包,批量为实体类设置别名。它的默认别名就是这个类的类名(首字母小写)。
语法
<typeAliases> <package name="domain.blog"/> </typeAliases>
3 补充(注解的方式)
若有注解,则最终使用注解名。
@Alias("author")
public class Author {
...
}
”加_是基本类型,不加_是包装类型?“ ???没听懂


4.5 设置(settings)
完整settings
<settings> <setting name="cacheEnabled" value="true"/> <setting name="lazyLoadingEnabled" value="true"/> <setting name="multipleResultSetsEnabled" value="true"/> <setting name="useColumnLabel" value="true"/> <setting name="useGeneratedKeys" value="false"/> <setting name="autoMappingBehavior" value="PARTIAL"/> <setting name="autoMappingUnknownColumnBehavior" value="WARNING"/> <setting name="defaultExecutorType" value="SIMPLE"/> <setting name="defaultStatementTimeout" value="25"/> <setting name="defaultFetchSize" value="100"/> <setting name="safeRowBoundsEnabled" value="false"/> <setting name="mapUnderscoreToCamelCase" value="false"/> <setting name="localCacheScope" value="SESSION"/> <setting name="jdbcTypeForNull" value="OTHER"/> <setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/> </settings>
我们只需掌握
| 设置名 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| cacheEnabled | 全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。 | true|false | true |
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 |
true|false | false |
| logImpl | 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。SLF4J | SLF4J ,LOG4J,LOG4J2,JDK_LOGGING,COMMONS_LOGGING,STDOUT_LOGGING,NO_LOGGING | 未设置 |
spring以后也不用了。
4.6 其他配置
插件(plugins)
-
mybatis-generator-core
-
mybatis-plus
-
通用mapper
5 作用域和生命周期
作用域和生命周期至关重要,错误的使用会导致非常严重的并发问题。
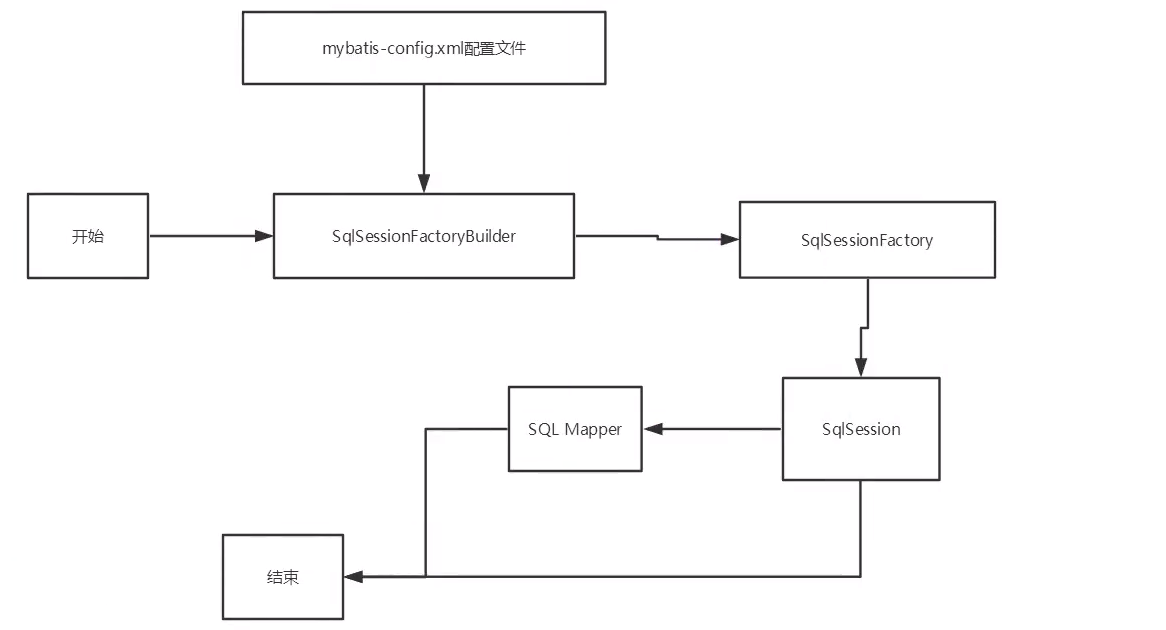
SqlSessionFactoryBuilder:
一旦创建了SqlSessionFactory,就不再需要了。
SqlSessionFactory:
类似数据库连接池。一旦被创建就应该在应用运行周期一直存在。
SqlSession:
类似连接到连接池的一个请求,连接完需关闭。SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。
6 映射文件(mapper设置)
6.1 九个元素
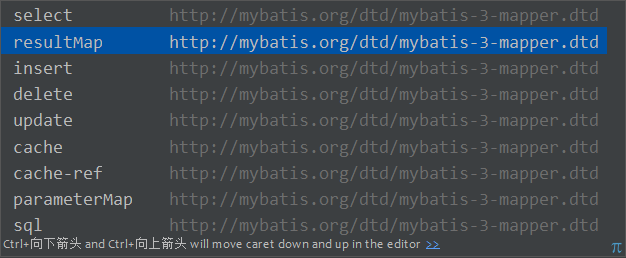
1 元素(CRUD)的属性
| select | insert | update | delete | |
|---|---|---|---|---|
| parameterType | √ | √ | √ | √ |
| databaseId | √ | √ | √ | √ |
| flushCache | √ | √ | √ | √ |
| lang | √ | √ | √ | √ |
| parameterMap | √ | √ | √ | √ |
| statementType | √ | √ | √ | √ |
| timeout | √ | √ | √ | √ |
| keyColumn | √ | √ | ||
| keyProperty | √ | √ | ||
| useGeneratedKeys | √ | √ | ||
| resultMap | √ | |||
| resultType | √ | |||
| fetchSize | √ | |||
| resultOrdered | √ | |||
| resultSets | √ | |||
| resultSetType | √ | |||
| useCache | √ |
select独有的:resultMap,resultType,fetchSize,resultOrdered,resultSets,resultSetType,useCache。
insert和update独有的:keyColumn,keyProperty,userGeneratedKeys。
2 元素(resultMap)的属性
打算细细分析一波!另一篇存档。Mybatis-resultMap.md
resultMap 是mybatis中最重要最强大的元素!
-
constructor - 用于在实例化类时,注入结果到构造方法中
-
idArg- ID 参数;标记出作为 ID 的结果可以帮助提高整体性能 -
arg- 将被注入到构造方法的一个普通结果
-
-
id– 一个 ID 结果;标记出作为 ID 的结果可以帮助提高整体性能 -
result– 注入到字段或 JavaBean 属性的普通结果 -
association – 一个复杂类型的关联;许多结果将包装成这种类型
-
嵌套结果映射 – 关联可以是
resultMap元素,或是对其它结果映射的引用
-
-
collection – 一个复杂类型的集合
-
嵌套结果映射 – 集合可以是
resultMap元素,或是对其它结果映射的引用
-
-
discriminator– 使用结果值来决定使用哪个resultMap
-
case– 基于某些值的结果映射
-
嵌套结果映射 –
case也是一个结果映射,因此具有相同的结构和元素;或者引用其它的结果映射
-
-
案例一
| 实体类 | 表 |
|---|---|
| id | user_id |
| name | user_name |
| password | user_password |
solv1.sql语句起别名
select user_id as id,user_name as name,user_password as password from ...
solv2.resultMap(结果集映射)
<resultMap id="UserMap" type="pojo.User"> <!--column列->数据库中的字段,property属性->实体类中的属性--> <result column="user_id" property="id"/> <result column="user_name" property="name"/> <result column="user_password" property="password"/> </resultMap> <!--id方法名--> <!--查--> <select id="getUserList" resultMap="UserMap"> select * from mybatis.user </select>
注意:属性和字段相同的地方不需要映射。
7 日志
7.1 日志工厂
用处:数据库操作出现异常需要排错!
曾今:sout,debug。现在:日志工厂。
在4(核心配置文件篇).5里的logImpl提到过。需要在配置文件里配置
掌握:LOG4J(需要导包+配置),STDOUT_LOGGING(设置就好)
其他:了解
<!--日志配置:不允许有空格-->
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
8 分页
8.1 limit实现分页
#接口 List<User> getUsersBylimit(Map<String,Integer> map); #Mapper <select id="getUsersBylimit" parameterType="map" resultMap="UserMap"> select * from mybatis.user limit #{startIndex},#{pageSize} </select> #test @Test public void test11(){ SqlSession sqlSession = MyBatisUtils.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); HashMap<String, Integer> hashMap = new HashMap<>(); hashMap.put("startIndex", 0); hashMap.put("pageSize", 3); List<User> users = mapper.getUsersBylimit(hashMap); for (User user : users) { System.out.println(user); } sqlSession.close(); }
8.2 RowBounds实现分页
#接口(即查询全部) List<User> getUserList(); #mapper(即查询全部) <select id="getUserList" resultMap="UserMap"> select * from mybatis.user </select> #test @Test public void test12(){ SqlSession sqlSession = MyBatisUtils.getSqlSession(); //通过java代码层面实现分页 RowBounds bounds = new RowBounds(0, 3); List<User> users = sqlSession.selectList("dao.UserMapper.getUserList",null,bounds); //注意,路径是dao接口不是mapper实现 /*查看全部则是*/ /*List<User> userss = sqlSession.selectList("dao.UserMapper.getUserList");*/ for (User user : users) { System.out.println(user); } sqlSession.close(); }
3.分页插件
有很多,知道有这东西即可。
https://pagehelper.github.io/
9 注解开发
临时补充1
面向接口编程:解耦,可拓展,提高复用,利于分层开发。
接口与实现分离。接口是骨架,实现是肉。骨架确定,肉怎么长没关系。
接口有两类:
1.抽象体(abstract class),对一个个体的抽象。
2.抽象面(interface),对一个个体某一方面的抽象。
临时补充2
自动提交事务commit
public static SqlSession getSqlSession(){ //return sqlSessionFactory.openSession(); return sqlSessionFactory.openSession(true); }
9.1 关于注解开发
注解在mybatis文档所言不多。
使用方法是:在接口上面增加一条注解就可以。
注意:
1.XML和注解不能同时作用。
2.使用注解时,在配置文件中绑定接口时(可以使用映射器第三第四种方法而不必将dao和mapper放在同一路径下【因为此时压根没用上mapper,或者说mapper用注解的方式在dao路径下实现了】)。很鸡肋,当我没说!
本质:
反射机制实现。
底层:
动态代理。
9.2 注解CRUD
@Select("select user_id as id,user_name as name,user_password as password from user where user_id=#{id}")
User getUserById(@Param("id") int any1);
@Insert("insert into mybatis.user(user_id,user_name,user_password) values(#{id},#{name},#{password})")
int addUser(User user);
int addUser2(Map<String,Object> map);
@Update("update mybatis.user set user_name=#{name},user_password=#{password} where user_id=#{id};")
int updateUser(User user);
@Delete("delete from mybatis.user where user_id = #{uid}")
int deleteUser(@Param("uid") int any);
关于Param注解
-
多个基本类型的参数和String类型,必须加上。
-
引用类型,不需要加。
-
一个基本类型,不需要加
#{}和${}的区别
#{}会自动加上"",很大程度防止sql注入。
${}则不会。
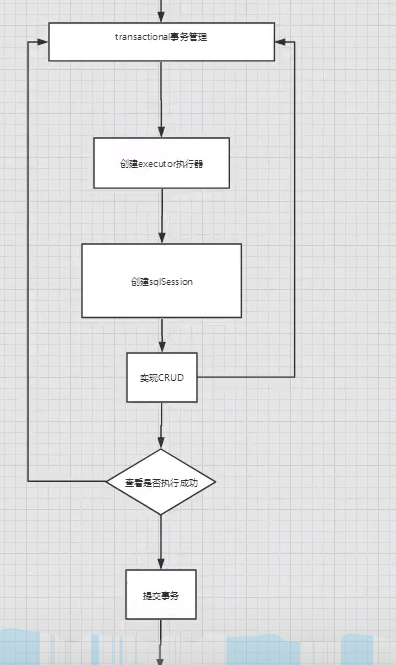
10 mybatis的详细执行流程
Resources获取全局配置文件
实例化SqlsessionFactoryBuilder构造器
解析配置流文件XMLConfigBuilder
Configuration所有的配置信息
SqlsessionFactory实例化 ↓
11 lombok
用前须知:一旦启用lombok插件,那么团队中其他成员也必须安装此插件,否则会编译报错。
使用步骤:
1.在IDEA中安装Lombok插件
setting->plugins->Browse repositories-> emmm等了很久没找到,换硬盘安装。
安装教程参考https://www.cnblogs.com/han-1034683568/p/9134980.html
因为存在版本 兼容问题(笔者IDEA2018.2.5破解版),所以选择

setting->plugins->install plugin from disk->选中保存文件,重启IDEA。
2.导包
->maven仓库
3.使用
@Data:无参构造,get,set,toString,hashCode,equals,canEqual
@AllArgsConstructor:有参构造
以上两个就够了!
package pojo; import lombok.*; @Data @AllArgsConstructor public class User { private int id; private String name; private String password; }

12 复杂的查询环境
对学生而言:多个学生关联一个老师,多对一 。
一个学生实体里包含了一个老师对象。
对老师而言:一个老师集合多个学生,一对多 。
一个老师实体里包含学生对象的集合
12.1 多对一
1 环境搭建
create table `teacher`( `id` int(10) not null primary key , `name` varchar(30) default null ) ENGINE=INNODB default charset=utf8; insert into teacher(`id`,`name`) values (1,'Teacheryang'); create table `student`( `id` int(10) not null primary key , `name` varchar(30) default null, `tid` int(10) default null, key `fktid` (`tid`), constraint `fktid` foreign key (`tid`) references `teacher` (`id`) ) ENGINE=INNODB default charset=utf8; insert into `student`(`id`,`name`,`tid`) values (1,'stu1','1'); insert into `student`(`id`,`name`,`tid`) values (2,'stu2','1'); insert into `student`(`id`,`name`,`tid`) values (3,'stu3','1'); insert into `student`(`id`,`name`,`tid`) values (4,'stu4','1'); insert into `student`(`id`,`name`,`tid`) values (5,'stu5','1');
lombox+注解开发都用上,简化环境搭建。
老师实体类
@Data //无需有参构造 public class Teacher { private int id; private String name; }
学生实体类
@Data public class Student { private int id; private String name; private Teacher teacher;(这就是上面说的:一个学生实体里包含了一个老师对象) }
查询所有的学生信息,以及对应辅导员的信息。
👇
2 按照查询嵌套处理(对应sql:子查询。较难理解)
#接口
List<Student> getStudent();
#mapper
<!-- 思路: 1.查询所有的学生信息 2.根据查询出来的学生的tid,寻找对应的老师。 --> <select id="getStudent" resultMap="Student_Associate_Teacher"> select * from mybatis.student </select> <select id="getTeacher" resultType="pojo.Teacher"> select * from mybatis.teacher where id=#{id} </select> <resultMap id="Student_Associate_Teacher" type="pojo.Student"> <!--实体和相同可以不写--> <result property="id" column="id"/> <result property="name" column="name"/> <association property="teacher" column="tid" javaType="pojo.Teacher" select="getTeacher"/> </resultMap>
小小分析不难理解:
1.第一个SELECT语句拿到所有的学生信息,但是从数据表里只能拿到教师的tid。需要由tid得到教师全部信息。
2.构造第二个SELECT语句,由教师id得到教师全部信息。
3.返回类型必须是结果集映射resultMap类型,构造此类型。

3 按照结果嵌套处理(对应sql:联表查询。较简单)
#接口
List<Student> getStudent2();
#mapper
<select id="getStudent2" resultMap="Student_Associate_Teacher2"> select s.id sid,s.name sname ,t.id tid,t.name tname from student s,teacher t where s.tid=t.id; </select> <resultMap id="Student_Associate_Teacher2" type="pojo.Student"> <result property="id" column="sid"/> <result property="name" column="sname"/> <association property="teacher" javaType="pojo.Teacher"> <result property="id" column="tid"/> <result property="name" column="tname"/> </association> </resultMap>
小小分析不难理解:
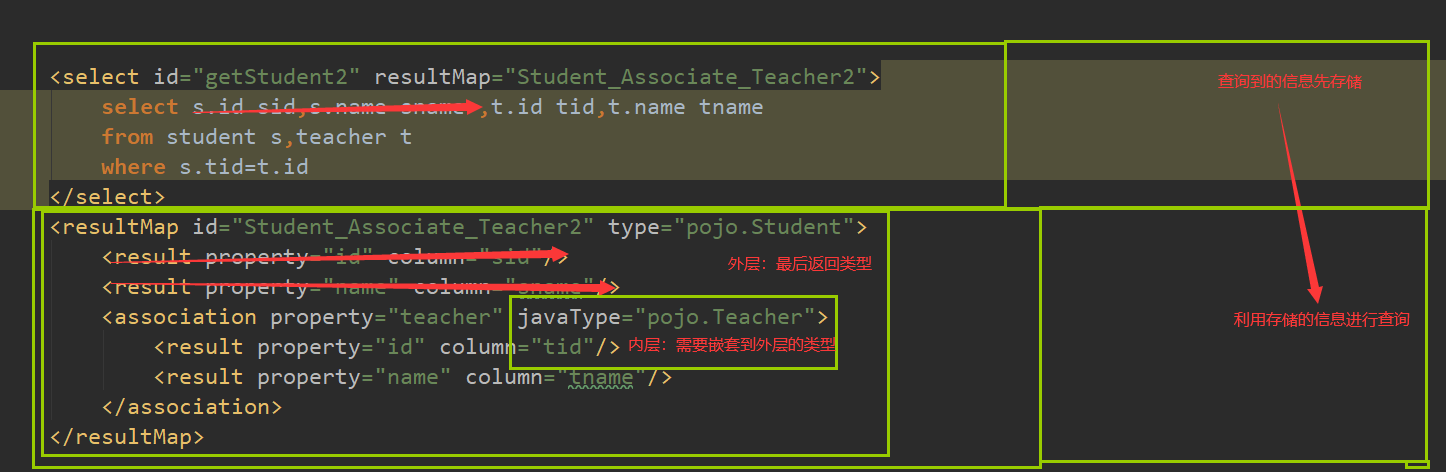
12.2 一对多
1 环境搭建
数据库环境和刚才一样
项目组织结构和刚才一样
=========开始==========
学生实体类
@Data public class Student { private int id; private String name; private int tid; }
老师实体类
@Data public class Teacher { private int id; private String name; private List<Student> students; }
2 按照查询嵌套处理
#接口
Teacher getTeachers2(int id);
#mapper
<select id="getTeachers2" resultMap="Teacher_collection_students2"> select * from mybatis.teacher where id = #{tid} </select> <select id="getStudent" resultType="pojo.Student"> select * from mybatis.student where tid=#{any_tid} </select> <resultMap id="Teacher_collection_students2" type="pojo.Teacher"> <!--很奇怪,这里id如果不进行映射赋值,得到的教师id为0(本该为1)。--> <result property="id" column="id"/> //javaType和ofType为返回类型,students为返回变量名,select为函数,column为输入。 <collection property="students" javaType="ArrayList" ofType="pojo.Student" select="getStudent" column="id"/> </resultMap>
3 按照结果嵌套处理
#接口
//查询某一老师的信息
Teacher getTeachers(int id);
#mapper
<mapper namespace="dao.TeacherMapper"> <select id="getTeachers" resultMap="Teacher_collection_students"> select s.id sid,s.name sname,t.name tname,t.id tid from mybatis.student s,mybatis.teacher t where s.tid = t.id and t.id = #{any_tid} </select> <resultMap id="Teacher_collection_students" type="pojo.Teacher"> <result property="id" column="tid"/> <result property="name" column="tname"/> <!--如果是基本类型或自定义类型,用javaType。 如果是集合中的泛型信息,则用ofType获取。--> <collection property="students" ofType="pojo.Student"> <result property="id" column="sid"/> <result property="name" column="sname"/> <result property="tid" column="tid"/> </collection> </resultMap> </mapper>
12.3 小结
1.关联-association【多对一】
2.集合-collection【一对多】
3.javaType & ofType
-
javaType指定实体类中属性的类型
-
ofType指定映射到List或者集合中的pojo类型,泛型中的约束类型。
面试高频:
Mysql引擎
InnoDB底层原理
索引
索引优化
13 动态SQL
hello所谓的动态sql,本质还是sql语句,只是我们可以在sql层面,去执行一个逻辑代码。
概述:
if是为了解决where后多个and或or情况的问题。0个~多个。
choose则从多个条件里选择一个。 1个。choose<when,when...otherwise>
where则取代了sql语句里的where,当子句为where后第一个子句时,自动去除子句里的"and"或"or"。
foreach则是处理需要对集合进行遍历(尤其是在构建 IN 条件语句的时候)的情况。
1 环境搭建
1.1 基本环境搭建
Blog实体类
@Data public class Blog { private String id; private String title; private String author; private Date createTime;//属性名和字段名不一致 private int views; }
Blog数据表
create table `blog`( `id` varchar(50) not null comment '博客id', `title` varchar(100) not null comment '博客标题', `author` varchar(30) not null comment '博客作者', `create_time` datetime not null comment '创建时间', `views` int(30) not null comment '浏览量' )engine =INNODB default charset=utf8;
自动产生id的工具类
package utils; public class IDutils { public static String getId(){ return UUID.randomUUID().toString().replaceAll("-", ""); } }
mapper映射文件BlogMapper.xml以及注册进核心配置文件
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!--namespace绑定一个对应的mapper接口--> <mapper namespace="dao.BlogMapper"> </mapper> 注册进核心配置文件mybatis-config.xml <mapper resource="mapper/BlogMapper.xml"/>
1.2 插入点数据
#接口
package dao; import pojo.Blog; import java.util.List; public interface BlogMapper { int addBlog(Blog blog); }
#mapper
<insert id="addBlog" parameterType="pojo.Blog"> insert into mybatis.blog(id, title, author, create_time, views) values(#{id},#{title},#{author},#{createTime},#{views}); </insert>
#Test插入数据
@Test public void test(){ SqlSession sqlSession = MyBatisUtils.getSqlSession(); BlogMapper blogMapper = sqlSession.getMapper(BlogMapper.class); Blog blog = new Blog(); blog.setId(IDutils.getId()); blog.setTitle("javaweb基础"); blog.setAuthor("xiaoyang"); blog.setCreateTime(new Date()); blog.setViews(9999); blogMapper.addBlog(blog); blog.setId(IDutils.getId()); blog.setTitle("java如此简单"); blogMapper.addBlog(blog); blog.setId(IDutils.getId()); blog.setTitle("mybatis如此简单"); blogMapper.addBlog(blog); sqlSession.close(); }
2 IF
#接口
List<Blog> queryBlogIf(Map map);
#mapper
<!--说明:title和author都是可选项--> <select id="queryBlogIf" parameterType="map" resultType="pojo.Blog"> select * from mybatis.blog where 1=1 <if test="title != null"> and title like "%"#{title}"%" </if> <if test="author != null"> and author=#{author} </if> </select>
#Test
//只有author //有author,有title @Test public void test1(){ SqlSession sqlSession = MyBatisUtils.getSqlSession(); BlogMapper blogMapper = sqlSession.getMapper(BlogMapper.class); HashMap<String, String> hashMap = new HashMap<>(); hashMap.put("author", "xiaoyang"); List<Blog> blogs = blogMapper.queryBlogIf(hashMap); for (Blog blog : blogs) { System.out.println(blog); } System.out.println("========================"); HashMap<String, String> hashMap1 = new HashMap<>(); hashMap1.put("author", "xiaoyang"); hashMap1.put("title", "java"); List<Blog> blogs1 = blogMapper.queryBlogIf(hashMap1); for (Blog blog : blogs1) { System.out.println(blog); } }
#输出

3 Choose(when,otherwise)
#接口
List<Blog> queryBlogChoose(Map map);
#mapper
<select id="queryBlogChoose" parameterType="map" resultMap="To Blog"> select * from mybatis.blog <where> <choose> <when test="title != null"> and title like "%"#{title}"%" </when> <when test="author != null"> and author=#{author} </when> <otherwise> and views=#{views} </otherwise> </choose> </where> </select> <resultMap id="ToBlog" type="pojo.Blog"> <result property="createTime" column="create_time"/> </resultMap>
#Test
//只有author //有author,有title //author和title为空,则根据views取值 @Test public void test1(){ SqlSession sqlSession = MyBatisUtils.getSqlSession(); BlogMapper blogMapper = sqlSession.getMapper(BlogMapper.class); HashMap<String, String> hashMap = new HashMap<>(); hashMap.put("author", "xiaoyang"); List<Blog> blogs = blogMapper.queryBlogChoose(hashMap); for (Blog blog : blogs) { System.out.println(blog); } System.out.println("========================"); HashMap<String, String> hashMap1 = new HashMap<>(); hashMap1.put("author", "xiaoyang"); hashMap1.put("title", "java"); List<Blog> blogs1 = blogMapper.queryBlogChoose(hashMap1); for (Blog blog : blogs1) { System.out.println(blog); } System.out.println("========================"); HashMap<String, Integer> hashMap2 = new HashMap<>(); hashMap2.put("views", 9999); List<Blog> blogs2 = blogMapper.queryBlogChoose(hashMap2); for (Blog blog : blogs2) { System.out.println(blog); } }
#输出
4 trim(where,set)
where在查询语句(select .. where)里出现,会智能去除无关"and"/"or"
set在更新语句(update .. set)里出现,会智能去除无关逗号","


trim是定制类如where,set这样的工具


网上很多关于trim的实现
5 forEach
foreach 元素的功能非常强大,它允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。这个元素也不会错误地添加多余的分隔符,看它多智能!
提示 你可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值。
<select id="selectPostIn" resultType="domain.blog.Post"> SELECT * FROM POST P WHERE ID in //("kitty","lili","bob","xiaoyang") <foreach item="item" index="index" collection="list" open="(" separator="," close=")"> #{item} </foreach> </select>
例如:
查询id为1,2,5的数据
sql为:
select * from mybatis.blog where 1=1 and (id=1 or id=2 or id=5) select * from mybatis.blog where id in (1,2,5)
#接口
List<Blog> queryBlogForeach(Map map);
#mapper
/*select * from mybatis.blog where 1=1 and (id=1 or id=2 or id=3)*/ <select id="queryBlogForeach" parameterType="map" resultMap="ToBlog"> select * from mybatis.blog <where> <foreach collection="ids" item="_id" open="and (" close=")" separator=" or "> id=#{_id} </foreach> </where> </select>
或者
/*select * from mybatis.blog where id in (1,2,4,5)*/ ... <foreach collection="ids" item="_id" open="id in(" close=")" separator=","> #{_id} </foreach> ...
#Test
@Test public void test4(){ SqlSession sqlSession = MyBatisUtils.getSqlSession(); BlogMapper blogMapper = sqlSession.getMapper(BlogMapper.class); HashMap map = new HashMap<>(); ArrayList<Integer> ids = new ArrayList<>(); //1.什么都不加->全部结果 //2.add(1,2,5),查询id=(1,2,5)的数据 ids.add(1);ids.add(2);ids.add(5); map.put("ids", ids); List<Blog> blogs = blogMapper.queryBlogForeach(map); for (Blog blog : blogs) { System.out.println(blog); } }
#结果

6 sql片段
功能:将sql片段提取出来,方便复用。
使用:
-
用sql标签抽取公共的部分
-
在需要使用的地方用include标签引用即可
比如:
<sql id="Blog-If-tile-author"> <if test="title != null"> and title like "%"#{title}"%" </if> <if test="author != null"> and author=#{author} </if> </sql> <select id="queryBlogIf" parameterType="map" resultMap="ToBlog"> select * from mybatis.blog <where> <include refid="Blog-If-tile-author"/> </where> </select>
注意:
-
最好基于单表来定义SQL片段
-
不要存在where/set标签
建议:
-
先在mysql里测试准确的sql,再改造成mybatis动态sql。
14 缓存
Mybatis默认缓存:
Mybatis默认定义了两级缓存:一级缓存和二级缓存
-
一级缓存默认开启。SqlSession级,也称本地缓存。
-
二级缓存需要手动配置开启。nameSpace级,也称全局缓存。
-
为了提供拓展性,Mybaits定义了缓存接口Cache。可以通过实现接口Cache来自定义二级缓存。
配置:
一级缓存无需配置,可手动关闭。
二级缓存默认关闭
全局缓存默认开启,允许每个namespace配置自己的二级缓存。可在mybatis核心配置文件关闭。
14.1 一级缓存
1 测试
@org.junit.Test public void test4(){ SqlSession sqlSession = MyBatisUtils.getSqlSession(); TeacherMapper mapper = sqlSession.getMapper(TeacherMapper.class); //查找不会更新缓存 teacher1==teacher Teacher teacher = mapper.getTeachers2(1); Teacher teacher1 = mapper.getTeachers2(1); System.out.println(teacher1 == teacher); //增删改会更新缓存 teacher2 != teacher mapper.updateById(1); Teacher teacher2 = mapper.getTeachers2(1); System.out.println(teacher2 == teacher); sqlSession.close(); }
结果
Opening JDBC Connection Created connection 2051853139. ...... true ...... false Closing JDBC Connection [com.mysql.cj.jdbc.ConnectionImpl@7a4ccb53] Returned connection 2051853139 to pool.
2 手动清理缓存
sqlsession.clearCache();
上面的例子
//查找不会更新缓存 teacher1==teacher。但是如果在两次查询中手动清理缓存,则 teacher1 != teacher Teacher teacher = mapper.getTeachers2(1); sqlSession.clearCache(); Teacher teacher1 = mapper.getTeachers2(1);
14.2 二级缓存
1某个mapper(namespace)里开启二级缓存
在这个mapper的映射文件中加入
<cache/>
效果【一级缓存默认开启,且不能关闭】

提示 缓存只作用于 cache 标签所在的映射文件中的语句。如果你混合使用 Java API 和 XML 映射文件,在共用接口中的语句将不会被默认缓存。你需要使用 @CacheNamespaceRef 注解指定缓存作用域。
提示 二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。
cache标签拥有属性
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
注意 开启二级缓存的namespace空间用到的实体类必须序列化。
2 然而还是 演示失败!!!!!!
false
3 全局缓存开关
所有二级缓存的总开关。
核心配置文件里配置,默认开启。

提示 上一节中对缓存的配置(如清除策略、可读或可读写等),不能应用于自定义缓存。
3 自定义缓存
ehcache,redis(hot)

