web安全之机器学习入门——2.机器学习概述
目录
0 前置知识
什么是机器学习
机器学习的算法
机器学习首先要解决的两个问题
一些基本概念
数据集介绍
1 正文
数据提取
数字型
文本型
数据读取
0 前置知识
什么是机器学习
机器学习的算法
属于监督式学习的算法有:回归模型,决策树,随机森林,K近邻算法,逻辑回归等算法
属于无监督式学习的算法有:关联规则,K-means聚类算法等
属于强化学习的算法有:马尔可夫决策过程
机器学习首先要解决的两个问题
找到合适的训练数据和测试数据,即数据集的提取;
如何把身边各种形态的实物最终转换成机器可以理解的数学特征,即特征提取。
一些基本概念
有监督学习:对具有概念标记分类的训练样本进行学习,以便尽可能对训练样本集外的数据进行标记分类预测。这里,所有的标记分类是已知的。因此,训练样本的歧义性低。
无监督学习:对具有概念标记分类的训练样本进行学习,以便发现训练集中的结构性知识。这里,所有的标记分类是未知的。因此,训练样本的歧义性高。聚类就是典型的无监督学习。
准确率和召回率:对一个二分问题,会出现四种情况。实例为真,预测为真,真正类(TP);实例为假,预测为真,假正类(FP);实例为假,预测为假,真负类(TN);实例为真,预测为假,假负类(FN)。
召回率=TP/(TP+FN);
准确率=TP/(TP+FP).
数据集介绍[by the way]
数据集和算法缺一不可,很多时候数据集比算法更重要。
1. KDD 99数据
一个网络连接的定义:在某个时间内从开始到结束的TCP数据包序列,并且在这段时间内,数据在预定义的协议下从源ip到目的ip地址的传递。
4大类共39种攻击类型
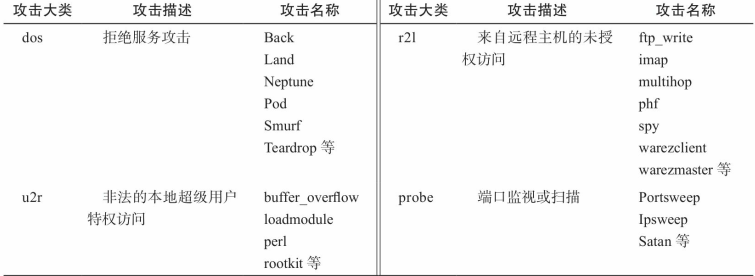
每个连接用41个特征来描述

TCP连接的基本特征
TCP连接的内容特征
基于时间的网络流量统计特征
基于主机的网络流量统计特征
2. HTTP DATASET CSIC 2010
包含大量标注过的针对web服务的36000个正常请求和25000个攻击请求。攻击类型包括sqli,xss,文件包含,缓冲区溢出,信息泄露等。
3. SEA数据集
涵盖70多个UNIX系统用户的行为日志,这些数据来自于UNIX系统acct机制记录的用户使用的命令。
用户日志类似于下面的命令序列

schonlau在他的个人网站上公开了数据集
4. ADFA-LD数据集
一套主机级入侵检测系统的数据集合,包括windows和linux,记录了系统调用数据。项目主页。
数据集将各类系统调用完成了特征化,并针对攻击类型进行了标注。
各种攻击类型列表

5. Alexa域名数据
提供了全球排名TOP100w的网站域名下载,文件格式是CSV。
6. Scikit-learn数据集
最常见的是iris数据集。2个属性,iris.data(4×150矩阵),iris.target(长度150的数组,值同数据类型)
7. MNIST数据集
入门级的计算机视觉数据集,包含了各种手写数字图片。包含了60000个训练数据和10000个测试数据。
也可以使用离线版的mnist文件
8. Movie Review Data
包含了1000条正面评论和1000条负面评论,被广泛用于文本分类,尤其是恶意评论识别方面。后续使用版本polarity dataset v2.0。地址。
9. SpamBase数据集
入门级的垃圾邮件分类训练集。一共58个特征,最后一个是垃圾邮件的标记位。地址。
10. Enron数据集
使用不同文件夹区分正常邮件和垃圾邮件。地址。
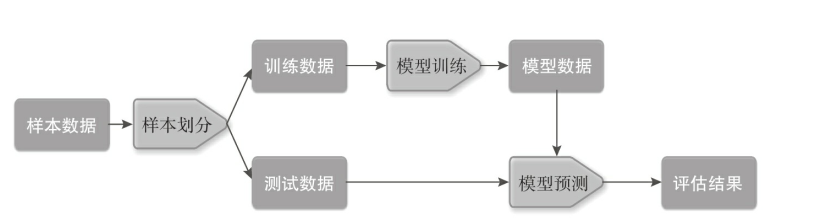
1 正文
特征提取
体力活,工程量大。数字型和文本型特征提取最为常见。
数字型
数字型特征可以直接作为特征,但对于一个多维的特征,某一特征值取值范围特别大的时候,很可能导致其他特征对结果的影响被忽略,这时候就需要对特征做预处理。常见的预处理方式有:
标准化
from sklearn import preprocessing
import numpy as np
x = np.array([[1.,-1.,2.],[2.,0.,0.],[0.,1.,-1.]])
print(preprocessing.scale(x))
[[ 0. -1.22474487 1.33630621]
[ 1.22474487 0. -0.26726124]
[-1.22474487 1.22474487 -1.06904497]]
正则化
from sklearn import preprocessing
import numpy as np
x = np.array([[1.,-1.,2.],[2.,0.,0.],[0.,1.,-1.]])
print(preprocessing.normalize(x,norm='l2'))
[[ 0.40824829 -0.40824829 0.81649658]
[ 1. 0. 0. ]
[ 0. 0.70710678 -0.70710678]]
归一化
from sklearn import preprocessing
import numpy as np
x = np.array([[1.,-1.,2.],[2.,0.,0.],[0.,1.,-1.]])
print(preprocessing.MinMaxScaler().fit_transform(x))
[[ 0.5 0. 1. ]
[ 1. 0.5 0.33333333]
[ 0. 1. 0. ]]
文本型
较数字型复杂很多,本质上是做单词划分,不同的单词当作一个新的特征。
如:
{'city':'zunyi','temperature':23},{'city':'guiyang','temperature':21},{'city':'hangzhou','temperature':18}
键值city具有多个取值,把每个取值当作特征;temperature是数字型,作为一个特征。
from sklearn.feature_extraction import DictVectorizer
import numpy as np
measurements = [{'city':'zunyi','temperature':23},{'city':'guiyang','temperature':21},{'city':'hangzhou','temperature':18}]
x = DictVectorizer()
print(x.fit_transform(measurements).toarray())#词袋数据
print(x.get_feature_names())#特征名称
[[ 0. 0. 1. 23.]
[ 1. 0. 0. 21.]
[ 0. 1. 0. 18.]]
['city=guiyang', 'city=hangzhou', 'city=zunyi', 'temperature']
文本特征有两个很重要的模型。
词集模型:集合中的单词不会重复出现。
词袋模型:集合中的单词不会重复出现,还会记录每个单词出现的次数。
"""和上例相似"""
#导入相关函数库
from sklearn.feature_extraction.text import CountVectorizer
#实例化分词对象
vectorizer = CountVectorizer(min_df=1)
#将文本进行词袋处理
corpus = ['This is the first document.','This is the second document.','And the third one.',]
x = vectorizer.fit_transform(corpus)
#获取对应特征名称
print(vectorizer.get_feature_names())
#获取词袋数据
print(x.toarray())
['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this']
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 1 1 0 1]
[1 0 0 0 1 0 1 1 0]]
我们定义的词袋的特征空间叫做词汇表vocabulary(输入空间、输出空间、特征空间与假设空间)
vocabulary = vectorizer.vocabulary_
对于其他文本,使用现有的词袋的特征进行向量化。
new_vectorizer = CountVectorizer(min_df=1,vocabulary=vocabulary)
TensorFlow有类似实现
...
数据读取
CSV是最常见的格式,文件每行记录一个向量,最后一行为标记。
TensorFlow从CSV文件中读取数据
#导入相关函数库 import tensorflow,numpy as tf,np #读取数据 training_set = tf.contrib.learn.datasets.base.load_csv_with_header( filename = "iris_training.csv",#文件名 target_dtype=np.int,#标记数据的类型 features_dtype=np.float32)#特征数据的类型 feature_columns = [tf.contrib.layers.real_valued_column("",dimension=4)] #??? #访问数据集合的特征以及标记的方式 x = training_set.data print(x) y = training_set.target print(y)
...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号