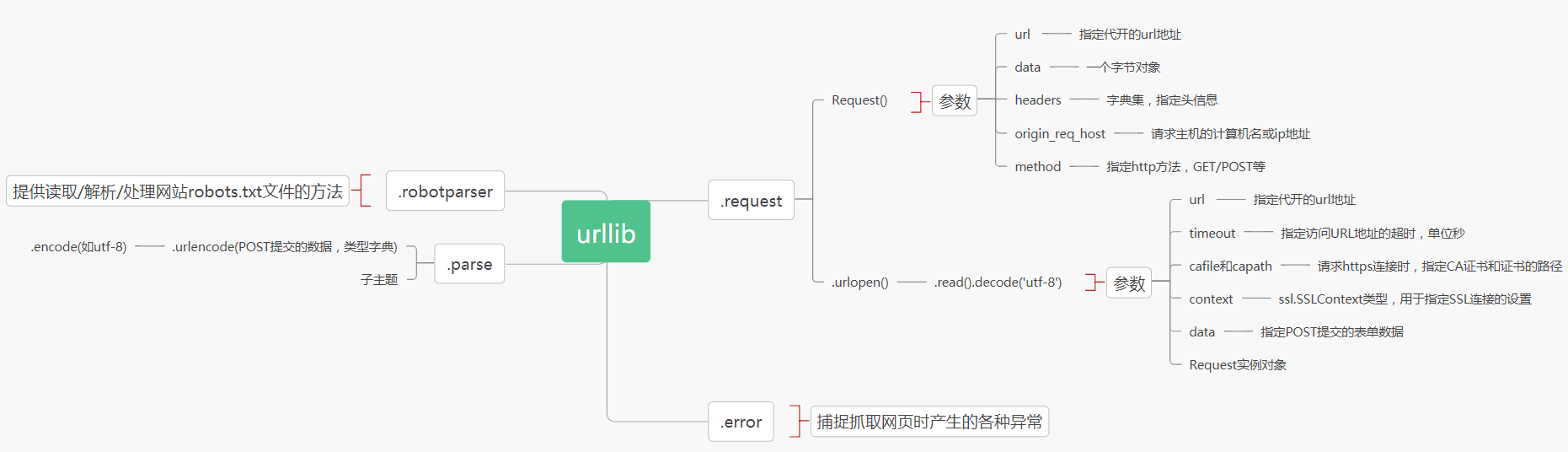
爬虫初窥day1:urllib
模拟“豆瓣”网站的用户登录
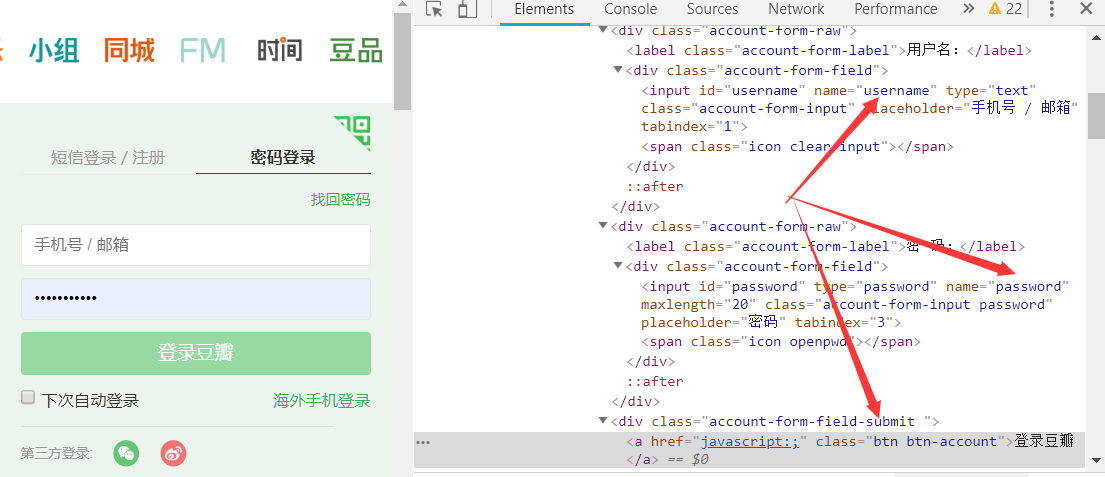
# coding:utf-8 import urllib url = 'https://www.douban.com/' data = urllib.parse.urlencode({'username':'15x82x54x2x','password':'yxxxxxx65'}) data = data.encode('utf-8') headers = {} headers['User-Agent']='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' response = urllib.request.Request(url=url,data=data,headers=headers) html = urllib.request.urlopen(response).read() f = open('haha.html','wb') f.write(html) f.close()
