
论文精读:面向物流网络中包裹的多峰行程时间分布预测的基于图的混合密度网络
论文精读《GMDNet:A Graph-Based Mixture Density Network for Estimating Packages’ Multimodal Travel Time Distribution》
一种面向物流网络中包裹的多峰行程时间分布预测的基于图的混合密度网络
摘要
- 研究内容:物流网络中根据路线准确估算包裹的行程时间分布(TTD)问题。
- 意义:准确预测包裹的到达时间分布对消费者和物流平台都具有重要意义。
- 之前的研究:路网中的行程时间和行程时间分布预测上取得较好成果,但不能很好地应用于物流网络中的TTD预测。
- 研究的特殊性:物流网络中的行程时间分布预测需要在捕获物流网络中复杂时空相关性的同时建模包裹的多峰行程时间分布MTTD。
- 研究方法:一种基于图的混合密度网络GMDNet,训练过程中为保证局部收敛采用期望最大化。
介绍
-
研究背景:在物流平台中,最关键的任务之一是估算包裹从起始节点到目的地节点的路径的行程时间分布(TTD)。准确估算行程时间分布对消费者和平台都具有重要价值。
①消费者:帮助他们安排取货时间,减轻等待焦虑。
②物流平台:帮助物流网络中的目的地节点提前制定更好的调度计划。 -
面临挑战:
挑战一:物流网络中复杂的空间关联和影响因素。
首先,如图1左侧所示,物流网络中的节点通过包裹流自然地与其他节点相连和相关。上游节点的包裹突然增加,会扩散到下游节点,导致向下游节点流动过程中的停留时间和转移时间发生变化。因此,物流网络中的节点在空间上是相关的。其次,包裹在节点中的停留时间受到多种复杂因素的影响,例如节点中当前的包裹数量,节点中的包裹数量越多,包裹离开节点所需的时间就越长。之前的研究基于链路对的行程时间来估计交通道路网络的 TTD,但这种方法不能很好地应用于处理图结构数据和物流网络中的复杂相关性。
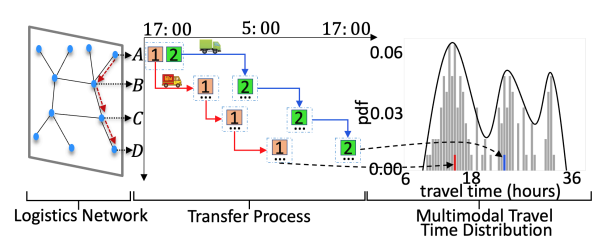
图1:给定物流网络路线的包裹 MTTD。17:00 发送的包裹从物流网络中的节点 A 到节点 D 的行程时间分布(左侧部分)是多峰的(右侧部分)。由于路线(中间部分)传输过程的不确定性,包裹 1(橙色)比包裹 2(绿色)更早到达。
挑战二:包裹的行程时间分布是多峰的,意味着一条给定的路线可能有不止一个输出。图中,包裹1和包裹2的路线相同,都是17:00从A出发前往D。然而,包裹1比包裹2 更早到达目的地D。由于转运过程中的不确定性,很难确定每个包裹将被分配到哪辆卡车上(即使它们在同一条路线上)。有些包裹(本例中为包裹 1)可能会幸运地被一辆几乎满载的卡车提前运往下一个节点,而其他同时到达的包裹(本例中为包裹 2)则不得不等待下一辆卡车。这样就产生了物流网络中包裹典型的多峰行程时间分布。虽然很多针对公路网络中行程时间估算(TTE)的研究都考虑到了图结构数据,但他们将TTE视为预测平均值的回归问题,因此未能描述包裹旅行时间的MTTD。
-
研究的贡献点:
①扩展基于图的TTE方法的功能。
②提出一种基于图的混合密度网络GMDNet,用于准确预测包裹的 MTTD。
③在两个真实物流数据集上进行实验验证GMDNet的性能明显优于其他解决方案。
相关工作
行程时间估算(TTE)
- 基于路段的方法:预测每个路段的行程时间,将所有路段的预测时间相加。
优点:效率高
缺点:无法纳入路线的上下文信息,例如路线中的交叉口造成的延误。 - 基于路线的方法:将路线作为一个整体,直接估算行程时间,以解决基于路段方法的局限性。
- 采用RNN使用各种特征学习行程时间
- 采用GNN来实现更精确的TTE。
- 上述方法缺点:可以实现精确的TTE,但输出被限制为预期值或单峰分布。
行程时间分布估算 (TTD)
- 高斯马尔科夫随机场
- 学习行程时间均值模型:建立方差与均值之间的关系来推导行程时间的分布。
- 深度生成模型:通过实时交通状况的条件来学习行程时间分布。
- 深度图学习和生成对抗网络以分布形式估计行程时间。
- 上述方法缺点:没有探讨MTTD的估算
多峰行程时间分布预测 (MTTD)
- 高斯混合模型和马尔科夫链模型估计公路网络中路线的MTTD
- 生成式对抗网络框架估计道路网络中的MTTD
- 上述方法缺点:通过对链路对的行程时间建模来估计 MTTD,而不考虑整个网络的拓扑结构。
准备工作
定义1 物流网络
物流网络本质上是一个有向图,定义为
定义2 路径
物流网络中的一条路径用元组
问题陈述
给定物流网络
GMDNet模型
1 总体思路:MLE假设
为使模型具备多峰输出功能,利用混合密度网络MDN的来学习条件分布 。具体来说,通过求解最大似然估计(MLE)来估计混合分量、权重,将K个混合分量与混合权重 相结合,以产生混合高斯分布。给定一个假设空间H,我们寻求可以最大化似然 的最优MLE估计 :
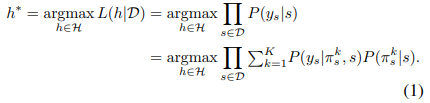
最大似然估计MLE:从已知的数据中找到最有可能生成这些数据的参数值
argmax:取使后面的函数取得最大值的那个参数值
L(h|D):似然函数,“h”是参数,“D”是观测数据。最大似然估计的思想:对于给定的观测数据D,我们希望从所有的参数中找出最大概率生成观测数据的参数 作为估计结果。
潜变量在概率模型中不直接观察到的变量,对于描述数据的分布或生成过程很有用。
边缘化:去除一个或多个变量的影响从而得到另一个变量的分布。
举例:有一个模型描述了一个班级学生成绩的分布,但是我们知道学生的智力水平是一个很重要的因素,而且它是无法直接观察到的(是一个潜在变量)。我们可以引入一个潜在变量 “I”代表学生的智力水平,然后我们的模型就可以写成“P(成绩|智力水平)P(智力水平)”,其中 “P(成绩|智力水平)”表示在给定智力水平的情况下成绩的分布,“P(智力水平)”表示智力水平的分布。如果我们只关心成绩的分布而不关心智力水平,我们可以使用边缘化操作,去除潜在变量“I”的影响,得到 “P(成绩)”。这个过程就是边缘化掉智力水平的过程。
潜变量可能为:交通流量和拥堵情况、天气和环境因素、道路质量和施工情况、运输工具状态、订单和货物属性、路线选择。
潜变量
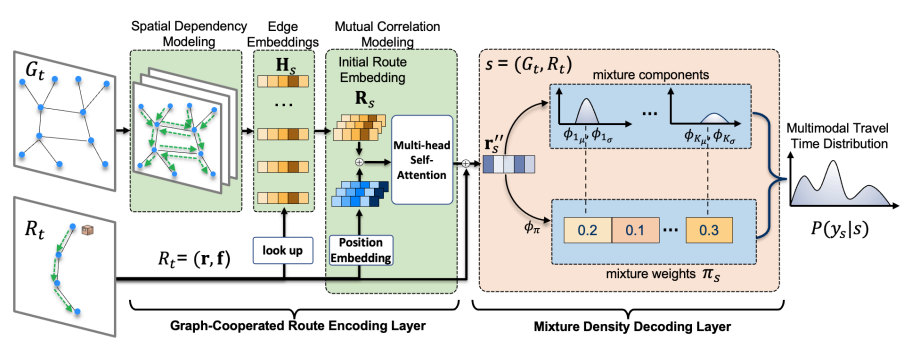
图2:GMDNet的结构
2 输入层Input Layer
在请求时间为t,输入包括物流网络
-
网络特征Network Features
令
给定节点
给定时间t的一条边 -
路线特征Route Features
路线
上述特征中,
3 图协同路径编码层Graph-Cooperated Route Encoding Layer
对物流网络中的空间依赖性进行建模(得到点的嵌入和边的嵌入),并整合了路径中边之间的相互关系,以生成路径的综合表示(得到路径嵌入)。
-
空间依赖性建模Spatial Dependency Modeling
给定节点和边特征通过线性变换获得的
让
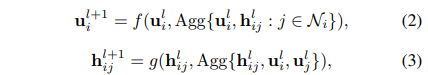
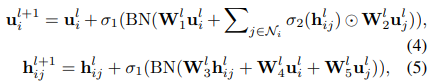
其中, -
互相关建模Mutual Correlation Modeling
整合路线中各边之间的相互关联,生成路线的综合嵌入。
初始路线嵌入(用
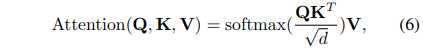
其中,
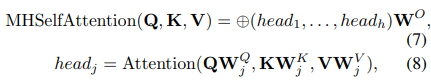
其中,h是注意力头的数量。
在路径编码层,为初始路径嵌入
最后,根据请求时间t的输入
4 混合密度解码层Mixture Density Decoding Layer
根据路径嵌入
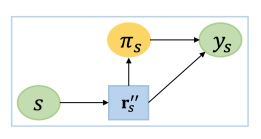
图3:
的建模过程可以表示为一个贝叶斯网络.
将混合权重
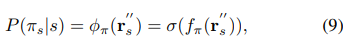
假设混合分量的条件分布来自于高斯分布族。混合分量的条件密度函数可以表述为:
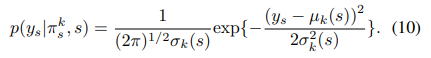
采用网络
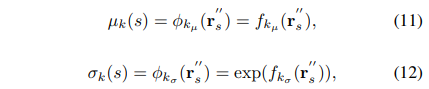
5 通过EM框架进行模型训练Model Training via EM Framework
- 训练
最大似然估计中似然函数的对数取法如下
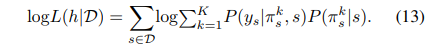
由于对数似然函数中存在潜变量,采用期望最大化框架来解决MLE估计问题,相比梯度下降更新参数,EM框架可以保证局部收敛。
引入指示变量
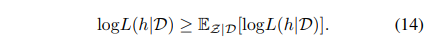
进一步推导得:
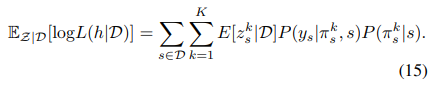
基于对数似然的下界,通过计算指示变量的后验概率执行EM的E-step:
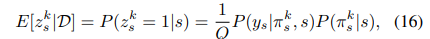
通过边缘化推导得出:
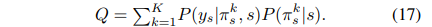
最终的目标函数:
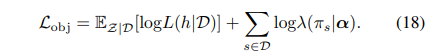
- 预测

实验
1 数据集
来自菜鸟网络的两个不同地区的真实物流数据集。这两个数据集均包含2022年2月6日至2022年3月8日的物流网络中包裹的行程信息。

2 基准
- 历史平均(HA)
- LightGBMI:传统机器学习算法
- Wide-Deep-Recurrent(WDR):深度神经网络
- 混合密度网络(MDN)
- 核密度估计(KDE)
- GCGTTE:深度学习+GAN
- GMDNet-GD:通过梯度下降训练的GMDNet
3 评估指标
- 平均绝对误差MAE和平均绝对百分比误差MAPE:衡量预测与标签之间的偏差程度。
- 对数似然
- 较大的
4 实验结果
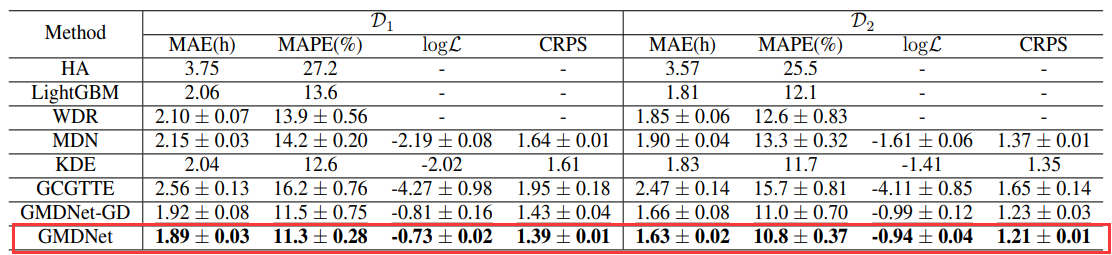
由图可知,GMDNet在两个数据集上表现均优于其他方法。
成分分析
设计GMDNet三个变体并在D1数据集进行比较。
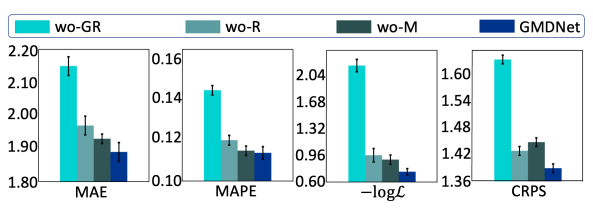
- wo-GR:将GMDNet中的图协同路径编码层替换为多层感知器。评估指标上性能下降表明有效处理物流网络中的复杂空间依赖性和相互关联性的必要性。
- wo-R:去除相互关联建模模块,性能下降表明通过在路径中整合边之间的相互信息来生成路由嵌入有助于提高性能。
- wo-M:将GMDNet的混合组件数量设置为1,。MAE和MAPE之间的差异不太显著但更低的-logL和CRPS表明,对行程时间分布进行多峰建模更近似真实分布情况。
案例分析
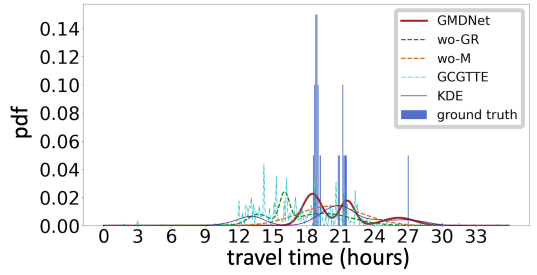
wo-GR、wo-M、GCGTTE、KDE、GMDNet以及给定输入路线下包裹实际行程时间分布的输出分布。纵轴pdf表示概率密度函数。
结论
通过研究物流网络中包裹的MTTD,提出一种基于图的混合密度网络GMDNet,可以实现准确预测包裹的行程时间分布,同时训练过程采用EM框架。实验证明了模型的有效性。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律