6.824 Lab 4
题目:http://nil.csail.mit.edu/6.824/2022/labs/lab-shard.html
Part A: The Shard controller
Hint: The code in your state machine that performs the shard rebalancing needs to be deterministic. In Go, map iteration order is not deterministic.
为了保证相同的输出产生相同的rebalance结果,需要对gid进行排序,因为map的key输出顺序是不确定的。这也就是hin3中说的deterministic。
Part B: Sharded Key/Value Server
前期准备
随着模块数量的增多(shardkv-client、shardkv-server、shardctrl-client、shardctrl-server、raft)加上有的模块还存在副本,例如shardkv-server有三个group,每个group里有三个server,那么就会有九个状态机和raft实例。如果这些模块的日志都集中输出到一个文件中,势必会给debug带来不少的麻烦,因此为了方便定位问题,有必要对各个模块的日志输出策略做灵活的控制。
我的策略是在不同模块对应的结构体中,各自定义了一个*log.Logger和name,name在输出日志时作为log prefix,这样就可以区分不同模块、不同副本打印的内容了。同时,各个模块还可以独立设置是否输出日志,以及日志输出路径。这样做带来的另一个好处是:如果我在机器上同时运行lab2和lab4的测试用例,lab2的raft日志我希望打印出来,而lab4我只关心server层的输出,不关心raft的日志,那么就可以把lab4的raft日志关闭,从而实现了不同lab对同一个raft实例日志开关的独立控制。
分片状态
Lab4 part B最重要的就是分配状态的迁移,管理好分配的状态是通过所有测试的关键,一个shard有四种状态:
- WORKING:表示当前节点负责shard
- MIGRATING:从其他节点转移到本节点后的shard状态,此状态的shard需要把数据迁移过来
- REQUEST_DELETE:数据已经迁移过来了,需要将原节点中shard清理掉,这时的shard处于这个状态
- OUTDATE:从本节点转移到其他节点后的shard状态,此状态的shard等待其他节点发起清理请求
四种状态的迁移图如下所示:
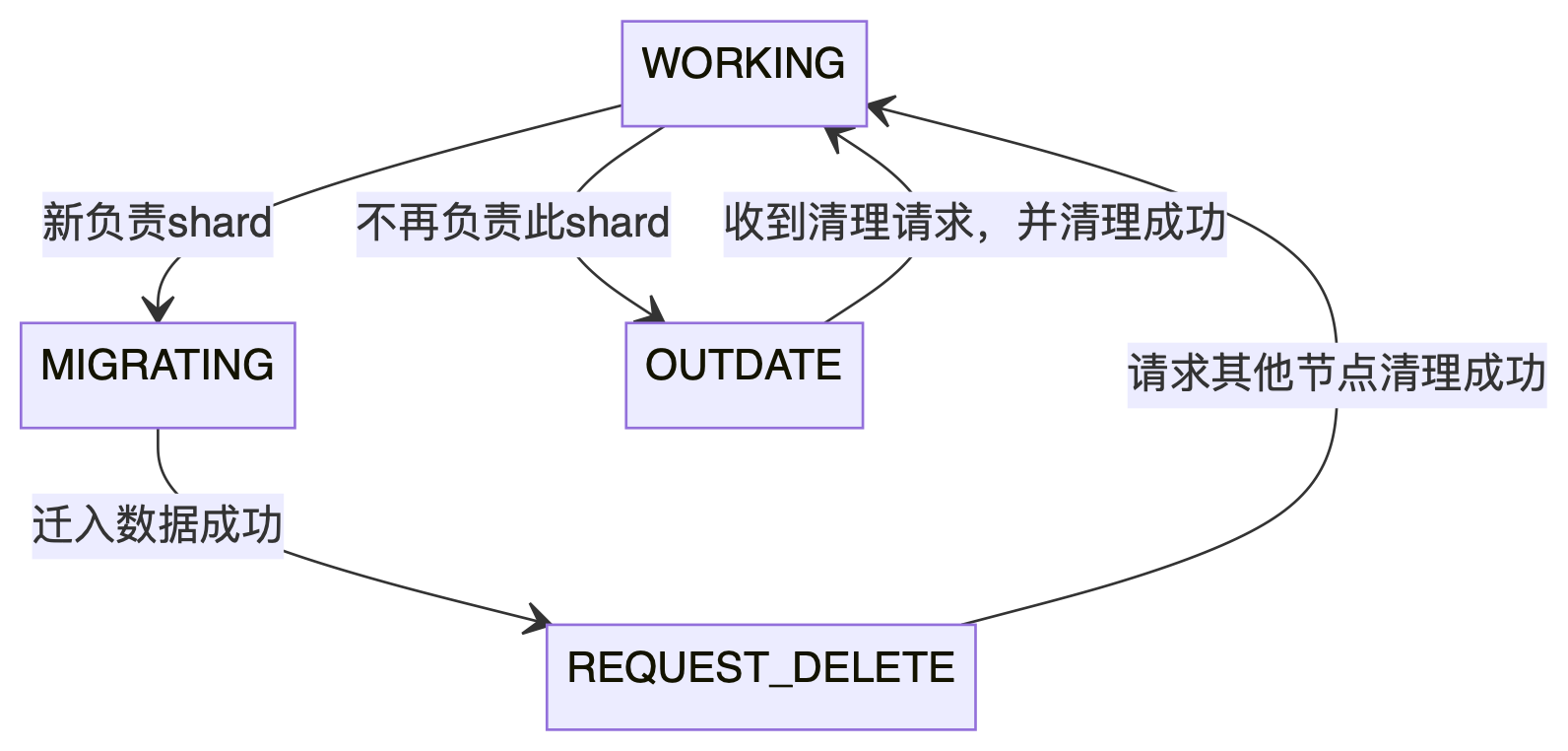
可以看出,一个shard的起始状态和终止状态都是WORKING,也就是说,配置更新事件出发了shard状态的迁移,每个节点根据状态机做相应的操作,最终又收敛到了WORKING状态。
配置拉取
开一个单独的协程,定期从ShardCtrler获取新配置,频率为100ms。
Note: Your server will need to periodically poll the shardctrler to learn about new configurations. The tests expect that your code polls roughly every 100 milliseconds; more often is OK, but much less often may cause problems.
有几点需要注意:
- 一个group中只有leader负责拉取配置,非leader节点直接空跑即可;
- 只有当一个版本的配置中所有shard都收敛到
WORKING状态,才能拉取下一个版本的配置; - 从1号配置开始,递增往后拉取,配置编号不能跳跃着拉取,否则shard状态会乱掉,只有拉取到的配置编号大于本地配置编号+1时,才需要发起Raft协商,防止无意义的协商操作;
- 为了满足线性一致性,对拉取到的配置发起一次Raft协商,apply时才能修改配置相关状态,负责拉取的协程不能变更配置状态,从而保证一个group中的所有副本,同时对外提供服务或者同时对外停止服务;
- 如果存在状态不为
WORKING的shard,不应拉取配置,否则刚拉取到的最新配置可能会覆盖尚未完成更新的配置; - 配置拉取协程中的判断逻辑,需要和apply协程中的更新配置逻辑互斥,防止并发产生的误判。
Apply配置
在apply协程中应用新配置,应用之前需要判断新配置编号是否等于当前配置编号+1,因为拉取配置的协程可能对同一个新配置先后多次发起Raft协商,导致apply协程接收到相同的新配置,如果直接用新配置覆盖旧配置,那么配置状态就有可能乱掉。
分片迁移
分片迁移使用pull模式(push模型试了很久,效果不好最终放弃了),开一个单独的协程,定期检测这一轮配置中那些shard需要从其他group迁入。拉取到的shard数据发起一轮raft协商,保证线性一致。
这里有几个点需要注意:
-
发起raft协商时需要带上配置编号,apply时检查编号是否等于当前最新配置编号,防止在server刚启动回放过程中迁入shard。
-
在apply迁入的shard时,需要检测这些shard是否在本节点是否处于等待状态,只有等待状态才能迁入,这样可以防止下面的情况:
- 迁移线程拉取shard 1、2,发起raft协商A
- 迁移线程拉取shard 1、2,发起raft协商B
- Apply协商A,覆盖本地shard 1、2
- Client成功修改了shard 1中的某个key
- Apply协商B,覆盖本地shard 1、2,这时步骤4的写入就丢失了
-
迁出方如何处理pull请求?
- 非leader不处理;
- Leader要判断config num,不匹配需要拒绝,因为shard可能还没有对外停止服务。
用例TestUnreliable2跑出的问题:Leader收到put请求,传给Raft做复制,复制过程中变为follower,然后收到install snapshot请求,apply之后需要通知之前挂起中的put线程,也就是唤醒所有等待在lastIncludedIndex之前的client RPC线程,返回错误让client重试。
死锁问题:Raft中持有mutex并apply数据,server层收到apply的数据需要先加server层mutex,然后才能更新状态,但是server层的mutex被另一个协程持有并且调用了rf.Start()接口,该接口内部需要对raft mutex加锁,而这把锁又在最开头被apply操作所持有,形成了一个mutex的循环依赖。解决方法是调用rf.Start()之前先释放server层锁。
Challenge1
题目要求失去shard ownership的server需要把这些shard数据删除掉,避免空间浪费。实现上类似shard迁移,也是开一个单独的协程,周期性检查需要删除哪些group的哪些老旧shard。
首先,需要给每个shard添加一个REQUEST_DELETE状态,shard迁入成功就会从MIGRATING状态变为REQUEST_DELETE状态,表示这个shard的全部内容已经从其他group迁移过来了,现在可以向原group发起删除请求了。同时,这个状态的shard可以正常对外提供服务。之所以需要这样一个状态,是因为清理协程需要区分哪些shard需要清理,之前清理过的shard不再重复发起清理。
其次,对于清理接收方,leader需要在收到请求后通过发起一轮raft协商,在apply协程中清理shard,然后将shard状态从OUTDATE变为WORKING;对于清理发起方,需要在确认接收方已经删除成功的前提下,也发起一轮raft协商,在apply协程中,将shard状态从REQUEST_DELETE变为WORKING。
注意,清理发起方要确认清理接收方真的把shard数据清空了,才能从REQUEST_DELETE状态转变到WORKING状态,否则可能出现下面的异常场景:
- server-100-0向server-101-0发起shard 1的清理请求;
- server-101-0收到请求,发起raft协商,然后返回OK;
- server-100-0收到OK,也发起raft协商,在apply协程中将shard 1的状态从
REQUEST_DELETE变为WORKING; - 步骤2中发起的entry在group 101中复制,但由于异常情况丢失了;
- 由于server-100-0的shar 1状态已经是
WORKING了,便不再发起清理请求,但server-101-0中的shard 1却仍然处于OUTDATE状态,永远没有机会被更新了,最终导致server-101-0无法拉取新配置而陷入卡死状态。
最后,不管是清理发起方还是清理接收方,在发起raft协商的时候都要带上一个配置版本号,在apply时校验这个版本号是否和本地配置版本号相等,只有相等才能进行状态变迁。
Challenge2
题目要求当部分shard ownership发生改变,剩余的shard需要能够正常提供服务。另一个要求是,单个shard迁入数据成功后就可以立刻提供服务,而不需要等到其他shard也迁入成功。
因此,我们需要为每个shard单独维护一个有限状态机,根据每个shard的状态决定这个shard是否能对外提供服务。上面已经描述了分片状态相关的内容,这里不再赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号