HDFS之DataNode
DataNode工作机制
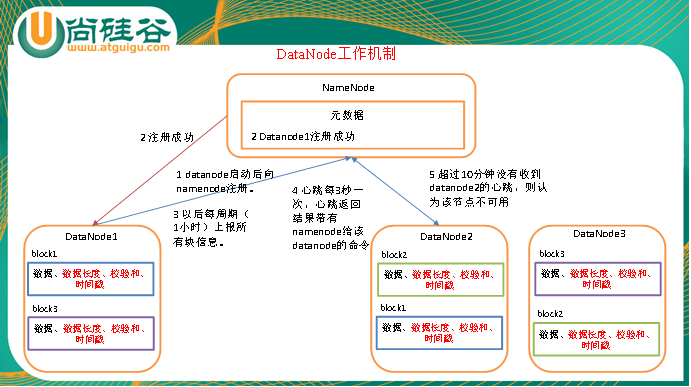
1)一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器
数据完整性
1)当DataNode读取block的时候,它会计算checksum
2)如果计算后的checksum,与block创建时值不一样,说明block已经损坏。
3)client读取其他DataNode上的block.
4)datanode在其文件创建后周期验证checksum
掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
|
<property> <name>dfs.namenode.heartbeat.recheck-interval</name> <value>300000</value> </property> <property> <name> dfs.heartbeat.interval </name> <value>3</value> </property> |
服役新数据节点
(1)在namenode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
[atguigu@hadoop105 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop105 hadoop]$ touch dfs.hosts
[atguigu@hadoop105 hadoop]$ vi dfs.hosts
添加如下主机名称(包含新服役的节点)
hadoop102
hadoop103
hadoop104
hadoop105
(2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性
|
<property> <name>dfs.hosts</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value> </property> |
(3)刷新namenode
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
(4)更新resourcemanager节点
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
(5)在namenode的slaves文件中增加新主机名称
增加105 不需要分发
hadoop102
hadoop103
hadoop104
hadoop105
(6)单独命令启动新的数据节点和节点管理器
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
(7)在web浏览器上检查是否ok
3)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 sbin]$ ./start-balancer.sh
退役旧数据节点
1)在namenode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts.exclude文件
[atguigu@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[atguigu@hadoop102 hadoop]$ touch dfs.hosts.exclude
[atguigu@hadoop102 hadoop]$ vi dfs.hosts.exclude
添加如下主机名称(要退役的节点)
hadoop105
2)在namenode的hdfs-site.xml配置文件中增加dfs.hosts.exclude属性
|
<property> <name>dfs.hosts.exclude</name> <value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts.exclude</value> </property> |
3)刷新namenode、刷新resourcemanager
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
4)检查web浏览器,退役节点的状态为decommission in progress(退役中),说明数据节点正在复制块到其他节点。
5)等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh stop datanode
[atguigu@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
6)从include文件中删除退役节点,再运行刷新节点的命令
(1)从namenode的dfs.hosts文件中删除退役节点hadoop105
hadoop102
hadoop103
hadoop104
(2)刷新namenode,刷新resourcemanager
[atguigu@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
[atguigu@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
7)从namenode的slave文件中删除退役节点hadoop105
hadoop102
hadoop103
hadoop104
8)如果数据不均衡,可以用命令实现集群的再平衡
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-balancer.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号