


【转】Design distributed lock with Redis
原文: https://medium.com/@bb8s/design-distributed-lock-with-redis-e42f452cb60f
-----------------------------
Design distributed lock with Redis
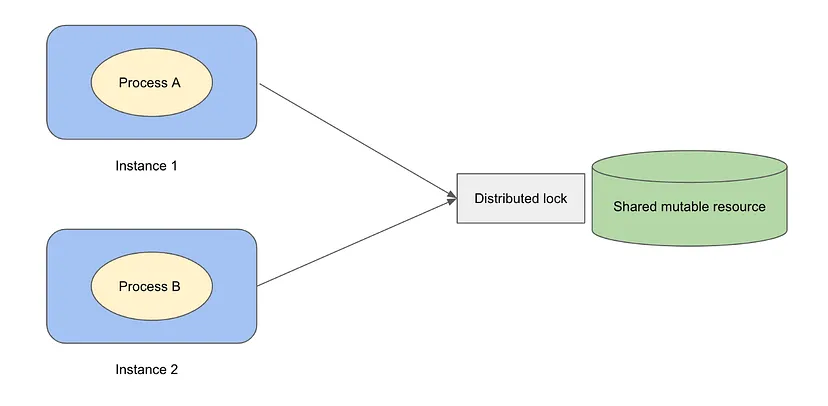
Redis is well-known for its high performance and ability to support high read/write QPS, which are highly desirable properties as the backing storage of a distributed lock service. Further, Redis natively supports Lua scripts as well. There are many implementations of distributed lock based on Redis in the open source community. Overall, Redis-based distributed lock can be more performant than MySQL-based counterpart. Let’s take a look at a few examples on how to build distributed lock using Redis.
Distributed lock with single Redis instance
Implementation 1. use built-in SETNX
SETNX means set if not exists. This command sets a key-value pair if the key does not exist. Otherwise, it is no-op. Redis key-value pairs can be used to represent locks. If a key exists, it means a client holds a lock. Any key can be used as a lock for a shared resource. Let’s say we define a lock named lock_name, when trying to acquire the lock, we can use this command:
SETNX lock_name true
here we attempted to set a k-v pair, with the key being the lock name lock_name, and the value being an arbitrary value true. In general, the lock name can be any valid Redis variable name, and the value is arbitrary since we are only interested in if the key exists. If this command succeeds, the lock is acquired. Otherwise it means the lock is held by other clients, and the current client should retry after some time.
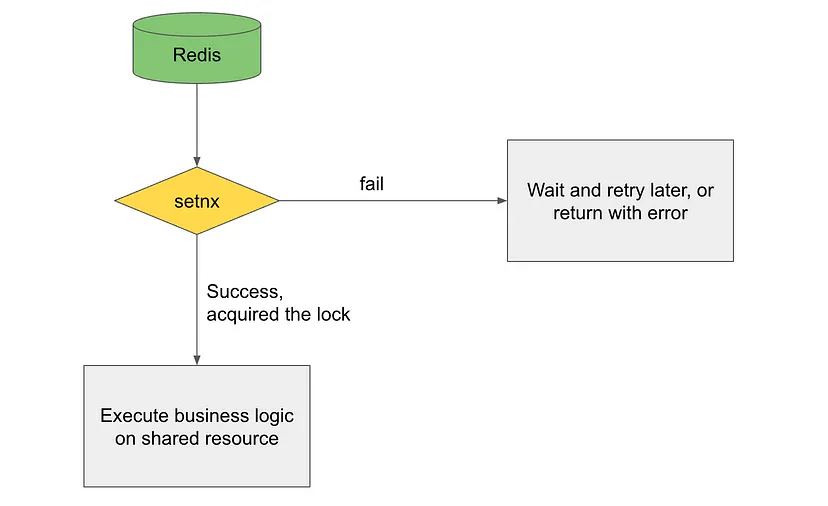
When we are done with the shared resource and want to release the lock, we can simply use the DEL command to delete the key in Redis.
DEL lock_name
SETNX ensures exclusiveness of the distributed lock lock_name— only one client can hold the lock at any time. However, this simple implementation is not reliable against failures. For example, if the client holding the lock is not responsive due to network partition or process exit, the lock cannot be correctly released. Dead lock happens, as other clients cannot acquire this lock either. This failure mode is quite common in distributed systems, so we need to use a more robust implementation.
Implementation 2. use built-in SET (NX EX)
As mentioned in the previous post Design distributed lock with MySQL, a commonly used approach to avoid the above-mentioned deadlock is to set a TTL for the lock. Once the key expires, it is automatically deleted by Redis (i.e. the lock is auto-released after TTL), even if the client holding the lock cannot release the lock. Since SETNX does not support directly setting a TTL, an additional EXPIRE command is needed. Conceptually, the workflow to acquire the lock should be like:
SETNX lock_name arbitrary_lock_value
EXPIRE lock_name 10
The problem with this approach is that the SETNX and EXPIRE is not an atomic operation but rather two separate operations. It is always possible that SETNX succeeds while EXPIRE fails.
Redis natively supports SET command with a set of options such as SET (key, value, NX, EX, timeout), allowing atomic operation of SETNX and EXPIRE. To acquire/release the lock:
SET lock_name arbitrary_lock_value NX EX 10 # acquire the lock# ... do something to the shared resourceDEL lock_name # release the lock
In the above command, NX has the same meaning as in SETNX, while EX 10 means the TTL is 10 seconds.
Now we have a Redis-based distributed lock service that provides exclusiveness, and can auto-release the lock should the client failed to do so. However, there is another failure mode we should consider for a minimum viable lock service. Let’s say client A is holding the lock, and it takes A takes longer than usual to complete the task, but the key is TTL-ed and the lock is auto-released. It is possible that another client B then successfully acquires the same lock by writing the k-v pair again to Redis. In this case, client A still thinks that it holds the lock, so after the task completes, client A tries to delete the k-v entry in Redis and succeeds. Essentially, client A deleted lock held by other clients, which may be disastrous in real production environment.
Implementation 3. SET (NX EX) + check unique client ID before lock release
When setting a key, client should add a unique client ID to the k-v pair. Before deleting the key, the client should check this ID to determine if it still holds the lock. If the ID does not match, it means the lock is held by other clients, and the current client should not delete the key. Conceptually, the workflow is:
SET lock_name client_id NX EX 10 # acquire the lock# ... do something to the shared resource# check if client_id matches stored value in k-v pair
IF client_id == GET lock_name
DEL lock_name # release the lock
Again, the IF conditional and DEL should be atomic, but they are actually two separate operations. Such get-compare-delete operation is needed when a client attempts to release a lock. In this case, we can use Lua script to wrap these commands into an atomic operation. Almost all implementations of Redis distributed locks contain a snippet of Lua script similar to the following:
// if the value from Redis GET operation equals the value passed in // from argument, then delete the keyif redis.call("get", "lock_name") == ARGV[1]
then
return redis.call("del", "lock_name")
else
return 0
end
Here the ARGV[1] is an input parameter. The previously set client_id when acquiring the lock should be passed here. The client_id can be a meaningful identifier of the client, or simply a UUID.
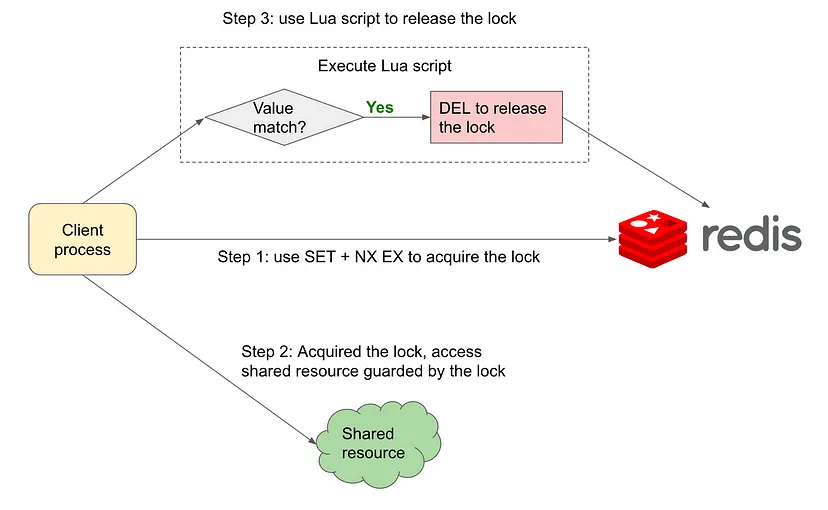
This implementation fulfills the following 3 functional requirements.
- mutually exclusive guaranteed by NX option in SET
- TTL mechanism to auto-release lock should client fails, also uses unique client_id to ensure that a client is not allowed to release arbitrary locks held by other clients.
- APIs for acquire and release locks
Implementation 4. open source solution Redisson
In the above solution, we implemented get-compare-set to avoid accidentally releasing locks (i.e. deleting corresponding k-v pairs from Redis) held by other clients. There is one additional problem we need to solve: let’s say client A is holding the lock, and is taking longer than usual to complete tasks on the shared resource. However, what if the lock is auto-released due to TTL, while client A actually still needs the lock?
One simple approach is to set the TTL long enough. In reality it would be difficult to set the TTL just “right” considering the huge number of heterogenous clients a distributed lock service usually serve, and that each client has its unique business logic to process after acquiring the lock.
A more generalized solution is that once a client holds the lock, it starts a daemon thread to periodically check if the lock exists. If so, the daemon thread will reset the TTL to prevent lock auto-release. This strategy is sometimes referred to as the lease strategy, meaning that a lock is only leased to a client with a fixed lease length, and before lease expiration, client should renew the lease if the lock is still needed. For example, open source solution Redisson uses this strategy. Here is a high level schematic of the watch dog daemon in Redisson:
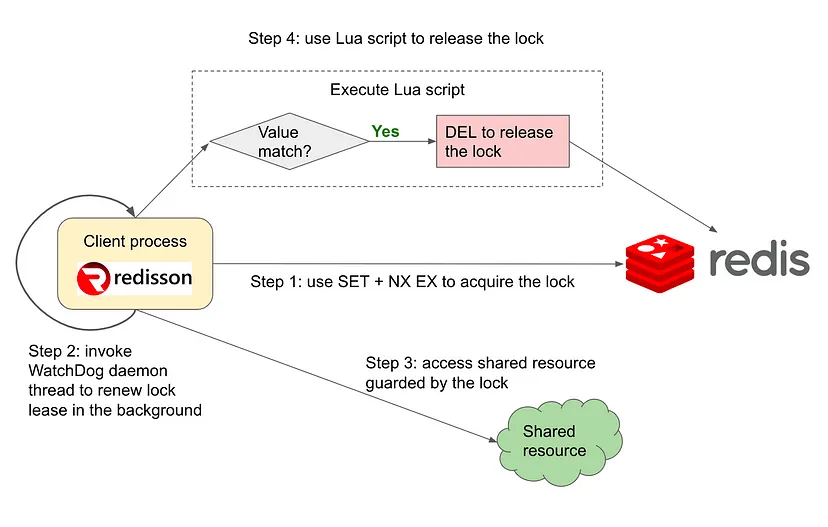
A WatchDog daemon thread is started once a lock is acquired. This background thread periodically checks if client still holds the lock and resets the TTL accordingly. This strategy helps to prevent pre-mature lock release.
Distributed lock with Redis cluster
To briefly recap, we now have a distributed lock service built on a single Redis instance. Built-in Redis commands SET (NX EX) is used to atomically acquire lock and set TTL, while Lua script is used to atomically release the lock. Unique client id and get-compare-set logic are used so that a client cannot release arbitrary locks that are held by other clients. Further, daemon thread is used to renew lock lease in the background.
The only weak spot now is the Redis instance itself, which is a single point of failure. The max lock acquire/release QPS the system can handle is also limited by the CPU/memory of the single Redis instance. To improve availability and scalability, Redis cluster is commonly used. Please refer to an earlier post How Redis cluster achieves high availability and data persistence for more details on Redis cluster. The use of cluster, however, will introduce more failure modes we need to consider. Let’s take a look at the main problems here. Stay tuned for the next post, where we will do a deep dive into the solutions.
Replication lag and leader failover
Let’s take a look at this failure scenario caused by leader failover in a cluster:
- Client acquired a lock from the Redis leader instance.
- Due to replication lag, the k-v pair representing the lock on the leader instance is not synced to follower instance yet.
- leader fails, and failover process is triggered, one of the follower instances is promoted as the new leader.
- k-v pairs not synced will be lost. For other clients requesting the new leader, it is as if these locks are still available. As a result, more than one client can successfully acquire the same lock, violating the exclusiveness requirement.
To tackle this problem, Redis inventors proposed the RedLock algorithm.
Redis proxy may not support Lua
As discussed in Deep dive into Redis cluster: sharding algorithms and architecture, sharded Redis cluster + proxy is commonly used in real production environments. In such Redis architecture, clients will directly talk to the proxy, rather than the underlying Redis cluster. The proxy computes a hash of the key, and determines which Redis instance should handle the task. Not all proxies support Lua script though.
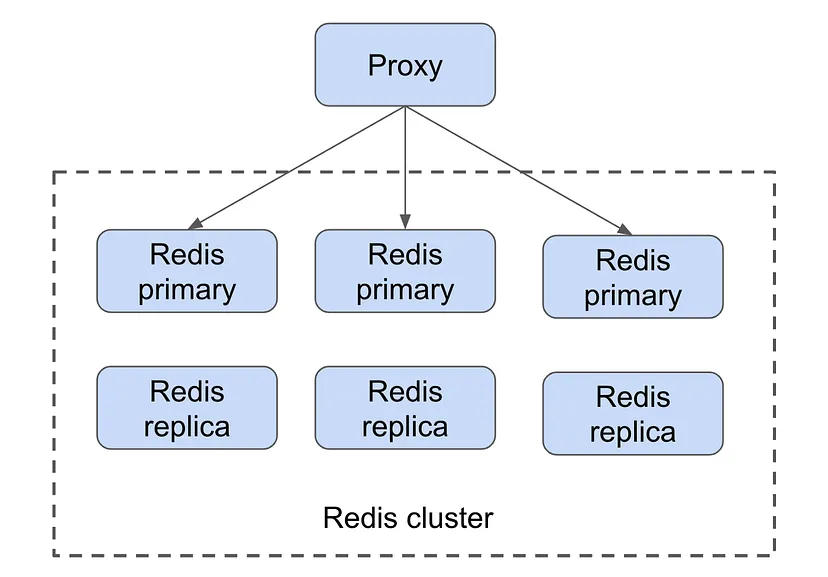
In such cases, we need to implement our own atomic get-compare-set operation using languages supported by the proxy. For example, redislock is an open-source Golang implementation of distributed lock on Redis.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2018-02-09 win10 powershell 验证下载的包的MD5/sha1的签名值
2018-02-09 【转】AOP
2018-02-09 [转]控制反转与依赖注入模式
2018-02-09 [转]乐观锁、悲观锁、死锁的区别