


字节序--大端字节序和小端
https://www.cnblogs.com/liujie-php/p/10716811.html
https://www.cnblogs.com/onedime/archive/2012/11/20/2779707.html
-------------------------
学了这么多年C语言、C++、VC、MFC,但却从来没有认真研究过各种数据类型在内存中是如何存储的。感觉自己一直在弄的都是皮毛,没有触及真正核心的东西。直到昨天,重新翻看谭浩强老师经典的《C程序设计(第三版)》,在“第十四章 常见错误和程序调试”中有一个例子是这样的:
1 int a=3;
2 float b=4.5;
3 printf("%f %d",a,b);
输出的结果是这样的:

为什么会是这样的结果呢?让我们看一看a和b在内存中的存储方式吧?
int 和 long 一样,按 2 的补码、低位字节在前的形式存储于 4 个字节中;
float 按 IEEE 754 单精度数的形式存储于 4 个字节中;
double 按 IEEE 754 双精度数的形式存储于 8 个字节中。
a是int型的,在内存中占4个字节,在内存中的存储方式:
地址:0x0012ff7c 0x0012ff7d 0x0012ff7e 0x0012ff7f
数值: 03 00 00 00
b是float型的,在内存中占4个字节,在内存中的存储方式:
地址:0x0012ff70 0x0012ff71 0x0012ff72 0x0012ff73
数值: 00 00 90 40
-----------------------------------------------------------------------
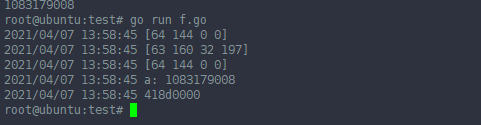
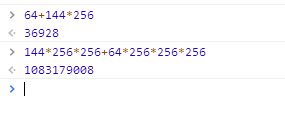
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | package mainimport ( "log" "bytes" "encoding/binary")//整形转换成字节func IntToBytes(n int) []byte { x := int32(n) bytesBuffer := bytes.NewBuffer([]byte{}) binary.Write(bytesBuffer, binary.LittleEndian, x) return bytesBuffer.Bytes()}func bytes2Int(b []byte) int { bytesBuffer := bytes.NewBuffer(b) var tmp uint32 err := binary.Read(bytesBuffer, binary.BigEndian, &tmp) if err != nil { log.Println("[]byte 2 int err:", err) return 0 } return int(tmp)}func float64ToByte(f float32) []byte { var buf bytes.Buffer err := binary.Write(&buf, binary.BigEndian, f) if err != nil { log.Println("binary.Write failed:", err) } return buf.Bytes()}func main() { var a int a = 36928 log.Println(IntToBytes(a)) var b,c,d float32 b =1.251 log.Println(float64ToByte(b)) c = 4.5 log.Println(float64ToByte(c)) log.Println("a:", bytes2Int(float64ToByte(c))) d = 17.625log.Printf("%x",float64ToByte(d))} |
c代码:
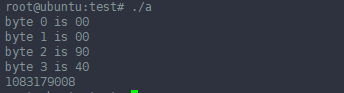
C Function to Convert float to byte array
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #include <stdio.h>int main(void) { int ii; union { float a; unsigned char bytess[4]; int b; } thing; thing.a = 4.5; for (ii=0; ii<4; ii++) printf ("byte %d is %02x\n", ii, thing.bytess[ii]); printf("%d\n", thing.b); return 0;} |
-------------------
主机字节序
主机字节序模式有两种,大端数据模式和小端数据模式,在网络编程中应注意这两者的区别,以保证数据处理的正确性;例如网络的数据是以大端数据模式进行交互,而我们的主机大多数以小端模式处理,如果不转换,数据会混乱 参考 ;一般来说,两个主机在网络通信需要经过如下转换过程:主机字节序 —> 网络字节序 -> 主机字节序
大端小端区别
大端模式:Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端
低地址 --------------------> 高地址
高位字节 地位字节
小端模式:Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端
低地址 --------------------> 高地址
低位字节 高位字节
什么是高位字节和低位字节
例如在32位系统中,357转换成二级制为:00000000 00000000 00000001 01100101,其中
00000001 | 01100101
高位字节 低位字节
int和byte转换
在go语言中,byte其实是uint8的别名,byte 和 uint8 之间可以直接进行互转。目前来只能将0~255范围的int转成byte。因为超出这个范围,go在转换的时候,就会把多出来数据扔掉;如果需要将int32转成byte类型,我们只需要一个长度为4的[]byte数组就可以了
大端模式下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func f2() { var v2 uint32 var b2 [4]byte v2 = 257 // 将 257转成二进制就是 // | 00000000 | 00000000 | 00000001 | 00000001 | // | b2[0] | b2[1] | b2[2] | b2[3] | // 这里表示b2数组每个下标里面存放的值 // 这里直接使用将uint32强转成uint8 // | 00000000 0000000 00000001 | 00000001 直接转成uint8后等于 1 // |---这部分go在强转的时候扔掉---| b2[3] = uint8(v2) // | 00000000 | 00000000 | 00000001 | 00000001 | 右移8位 转成uint8后等于 1 // 下面是右移后的数据 // | | 00000000 | 00000000 | 00000001 | b2[2] = uint8(v2 >> 8) // | 00000000 | 00000000 | 00000001 | 00000001 | 右移16位 转成uint8后等于 0 // 下面是右移后的数据 // | | | 00000000 | 00000000 | b2[1] = uint8(v2 >> 16) // | 00000000 | 00000000 | 00000001 | 00000001 | 右移24位 转成uint8后等于 0 // 下面是右移后的数据 // | | | | 00000000 | b2[0] = uint8(v2 >> 24) fmt.Printf("%+v\n", b2) // 所以最终将uint32转成[]byte数组输出为 // [0 0 1 1]} |
小端模式下
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// 在上面我们讲过,小端刚好和大端相反的,所以在转成小端模式的时候,只要将[]byte数组的下标首尾对换一下位置就可以了func f3() { var v3 uint32 var b3 [4]byte v3 = 257 // 将 256转成二进制就是 // | 00000000 | 00000000 | 00000001 | 00000001 | // | b3[0] | b3[1] | b3[2] | [3] | // 这里表示b3数组每个下标里面存放的值 // 这里直接使用将uint32l强转成uint8 // | 00000000 0000000 00000001 | 00000001 直接转成uint8后等于 1 // |---这部分go在强转的时候扔掉---| b3[0] = uint8(v3) // | 00000000 | 00000000 | 00000001 | 00000001 | 右移8位 转成uint8后等于 1 // 下面是右移后的数据 // | | 00000000 | 00000000 | 00000001 | b3[1] = uint8(v3 >> 8) // | 00000000 | 00000000 | 00000001 | 00000001 | 右移16位 转成uint8后等于 0 // 下面是右移后的数据 // | | | 00000000 | 00000000 | b3[2] = uint8(v3 >> 16) // | 00000000 | 00000000 | 00000001 | 00000001 | 右移24位 转成uint8后等于 0 // 下面是右移后的数据 // | | | | 00000000 | b3[3] = uint8(v3 >> 24) fmt.Printf("%+v\n", b3) // 所以最终将uint32转成[]byte数组输出为 // [1 1 0 0 ]} |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2018-04-07 [转]文件IO详解(二)---文件描述符(fd)和inode号的关系
2016-04-07 javascript 实现加法分离。 plus(3)(4); // => 得到 7