


【转】Everything you need to know about NoSQL databases
原文: https://dev.to/lmolivera/everything-you-need-to-know-about-nosql-databases-3o3h
-----------------------------------------------------------------------------------------
Everything you need to know about NoSQL databases
 Lucas Olivera Jun 4 Updated on Jun 05, 2019 ・16 min read
Lucas Olivera Jun 4 Updated on Jun 05, 2019 ・16 min read
Hello DEV! It's been some time but here I am with an article that took a lot of research, as I felt that the answers here were not enough for me.
I suggest you first check this article I made about Relational Databases to be able to understand this article more easily.
Index
- What is NoSQL?
- Advantages and disadvantages
- Types of NoSQL databases
- NoSQL and Relational Databases Comparison
- Choosing a particular database
- How to design a NoSQL database
- Important links
- Sources
What is NoSQL?
Definition
Relational Databases were created some time ago when Waterfall model was very popular, but they were not designed to cope with the scale and agility of modern applications, neither to take advantage of the commodity storage and processing power available today.
NoSQL are type of databases created in the late 90s to solve these problems, called like that because they didn’t use SQL (but today they are called “Not Only SQL” due to some Management Systems which implement Query Languages). NoSQL databases mostly address some of the points: being non-relational, distributed, open-source and horizontally scalable.
It is important to mention that nowadays Relational Databases have improved dramatically, having resolved most of the problems they had when dealing with today's technology. NoSQL Databases are another way of storing data, not necessarily better than Relational Databases. Both are designed to resolve different kinds of needs.
Features
- Distributed computing system.
- Higher Scalability.
- Reduced Costs.
- Flexible schema design.
- Process unstructured and semi-structured data.
- No complex relationship.
- Open-sourced.
Terminology
- Node: Networked computer that offers some kind of service, local storage and access to a larger distributed system or file store.
- Clusters: Set of nodes.
- Sharding (or horizontal partitioning): Partitioning the database on the value of some field.
- Replication: Portions of data are written to multiple nodes in case one of them fails (ensuring availability).
- ACID: Atomicity, Consistency, Isolation, Durability. Is a set of properties of database transactions intended to guarantee validity even in the event of errors, power failures, etc.
- BASE: Basically available (no 24/7 availability), soft-state (database may be inconsistent) and eventually consistent (eventually, it will be consistent).
Advantages and disadvantages
Advantages
- Elastic scalability: These databases are designed for use with low-cost commodity hardware.
- Big Data Applications: Massive volumes of data are easily handled by NoSQL databases.
- Economy: Relational Databases require installation of expensive storage systems and proprietary servers, while NoSQL databases can be easily installed in cheap commodity hardware clusters as transaction and data volumes increase. This means that you can process and store more data at much less cost.
- Dynamic schemas: NoSQL databases need no schemas to start working with data. In Relational Database you have to define a schema first, making things more difficult because you have to change the schema everytime the requirements change. Note: This means that every data quality control must be done on the application. Note 2: Having no schema is not a characteristic of every NoSQL database and could also be a disadvantage if we don't organize data properly.
- Auto-sharding: Relational Databases scale vertically, which means you often have a lot of databases spread across multiple servers because of the disk space they need to work. NoSQL databases usually support auto-sharding, meaning that they natively and automatically spread data across an arbitrary number of servers, without requiring the application to even be aware of the composition of the server pool.
- Replication: Most NoSQL databases also support automatic database replication to maintain availability in the event of outages or planned maintenance events. More sophisticated NoSQL databases are fully self-healing, offering automated failover and recovery, as well as the ability to distribute the database across multiple geographic regions to withstand regional failures and enable data localization.
- Integrated caching: Many NoSQL technologies have excellent integrated caching capabilities, keeping frequently-used data in system memory as much as possible and removing the need for a separate caching layer.
Disadvantages
- NoSQL databases don’t have the reliability functions which Relational Databases have (basically don’t support ACID).
- This also means that NoSQL databases offer consistency in performance and scalability.
- In order to support ACID developers will have to implement their own code, making their systems more complex.
- This may reduce the number of safe applications that commit transactions, for example bank systems.
- NoSQL is not compatible (at all) with SQL.
- Note: Some NoSQL management systems do use a Structured Query Language.
- This means that you will need a manual query language, making things slower and more complex.
- NoSQL are very new compared to Relational Databases, which means that are far less stable and may have a lot less functionalities.
Types of NoSQL databases
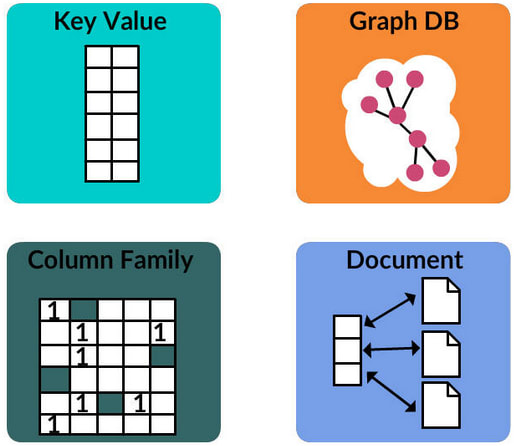
Note: Some rules will depend on the Management System you choose.
Key-value
Key-value Stores are the simplest NoSQL databases. Every single item in the database is stored as an attribute name (or 'key'), together with its value, similar to a dictionary.
Features
- Scalability: Large amounts of data and users.
- Speed: Large number of queries.
- Data model: Key-value pairs.
- Consistency.
- Transactions.
- Querying ability.
- Scalability.
Operations
- get(key): Get a value given a key.
- put(key, value): Create/Update a value given a key.
- delete(key): Deletes a value given a key.
- execute(key): Invoke an operation to a value.
Limitations
- No relationships among Multiple-Data.
- Multi-operation Transactions: If you are storing many keys and there is a failure to save one of the keys, you can’t roll back the rest of the operations.
- Query Data by 'value': Searching the 'keys' based on some info found in the 'value' part of the key-value pairs.
- Operation by groups: As operations are confined to one key at a time, there exists no way to run several keys simultaneously.
Real life examples
Key-Value would be best-fit to store user profile:
- userId, username.
- additional attributes/preferences:
- Language
- Country
- Timezone
- User favorites
- and so on
Key-value databases
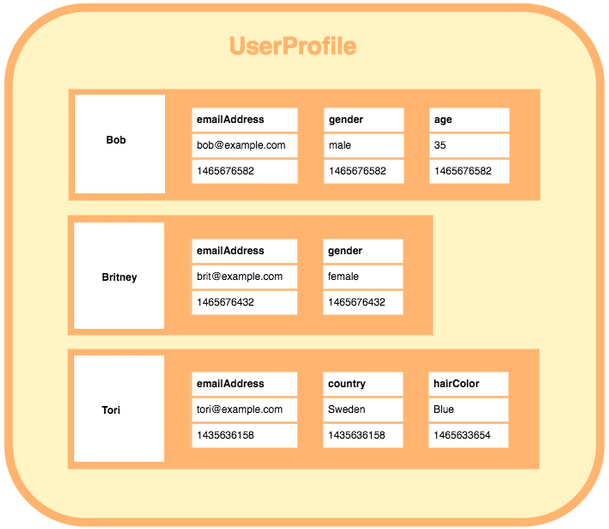
Document
Document Stores pair each key with a complex data structure known as a document that can contain many different key-value pairs, or key-array pairs, or even nested documents. Documents are treated as wholesome and splitting a document into its constituent name/value pairs are avoided.
Features
- Scalability: For more complex objects.
- Data model: Collection of documents.
- Similar to JSON and XML.
- Implements ACID transactions and adapt RDBMS characteristics.
- Allows indexing of documents based on its primary identifier and properties.
- Supports Query transactions (to an extent).
- Design pattern allows retrieving info in a single operation.
- Avoids performing joins within the application.
Operations
- Search by:
- Field
- Range
- Regular Expression
- Queries: Can include Javascript functions.
- Indexing: Can be done on any field.
Types
XML Databases:
- XML document formed the first Document DB.
- XML has a variety of standards and tools to assist with authoring, validation, searching, and transforming XML documents.
- XPath: Syntax for retrieving specific elements from an XML document.
- XQuery: Query language for grilling XML documents, also known as “the SQL of XML”.
- XML schema: Document Template that explains which all elements may be present in a specified class of XML documents to validate document correctness.
- XSLT: Language to transform XML documents into other formats, like non-XML formats such as HTML.
- Famous XML databases: eXist (open-source) and MarkLogic (commercial).
JSON Databases:
- JSON document database expects the data to be stored in the format of JSON.
- Resembles row in an RDBMS.
- Contains one or more key-value pairs, nested documents, and arrays. Arrays may hold complex hierarchical structure.
- Collection (data bucket) is a group of documents sharing some common objective (resembles table in an RDBMS).
- Although preferred, documents in a collection need not be of the same type.
- JSON databases:
- MongoDB
- CouchDB
- OrientDB
- DocumentDB.
Data modelling
- Less deterministic compared to RDBMS.
- Driven by nature of the queries to be executed, while in RDBMS it is driven by the kind of data to be stored.
Limitations
- Base info duplication across multiple documents
- Complicates design resulting in inconsistency.
- Solution: Link multiple documents using document identifiers (resembles foreign key in RDBMS)
Real life examples
Here is a list of real life cases.
Document databases
Graph
Graph Stores are an expressive structure with the collection of Nodes and relationships interlinking them, used to store information about networks of data, such as social connections. Based on the mathematical theory of graphs.
Parts of a graph
- Nodes - representation of entities.
- Properties - Information about nodes.
- Can be indexed.
- Edges - Relationships between nodes.
- Can be indexed.
- Unidirectional or bidirectional, no limit of edges.
Understanding Graph theory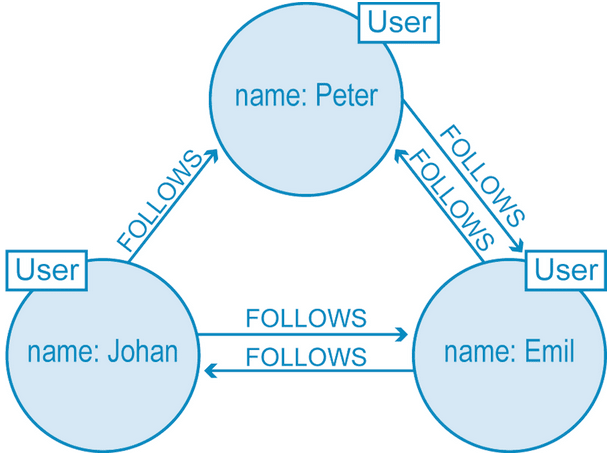
According to Graph theory, the major constituents of a graph include:
- Vertices or Nodes representing distinct objects.
- Edges or Relationships or arcs establishing connectivity among these objects.
- Both Nodes and Relationships carry some properties.
- Properties of Nodes are similar to those of relational table/JSON document.
- Properties of Relationship considers the type, strength, or history of the relationship.
Graph theory assigns mathematical notation for
- Adding/removing nodes or relationships from graph
- Performing operations to trace adjacent nodes.
Core Rule - 'No broken links': A relationship should always have a start and end node. Deletion of a node is not possible without deleting its associated relationships.
Types
At a very high level, Graph store can be categorized into two kinds:
1) Graph Database - (Real-time)
- Performs transactional online graph persistence in real-time.
- Similar to online transactional processing (OLTP) databases in RDBMS area.
2) Graph Compute Engine - (Batch Mode)
- Performs offline graph analytics in batch as series of steps.
- Similar to online analytical processing (OLAP) for analysis of data in bulk, such as data mining.
Features
- Scales to the complexity of data.
- Focus on interconnectivity.
- Many query languages.
Operations
Will depend on it’s query language. For example, Neoj4 uses Cypher Query Language.
Limitations
- Lack of high performance concurrency: In many cases, Graph Databases provide multiple reader and single writer type of transactions, which hinders their concurrency and performance as a consequence, somewhat limiting the threaded parallelism.
- Lack of standard languages: The lack of a well established and standard declarative language is being a problem nowadays. Neo4j is proposing Cypher and Oracle is working on a language.
- Lack of parallelism: One important issue is the fact that partitioning a graph is a problem. Thus, most do not provide shared nothing parallel queries on very large graphs. Thus, allowing for parallelism is intrinsically a problem.
Real life examples
Graph Store is used to model all kind of different scenarios such as:
- Construction of a space rocket.
- Transportation system (roads and trains).
- Supply-chain and Logistics.
- Medical history.
- Fraud Detection.
- Network and IT Operations.
Graph databases
Columnar
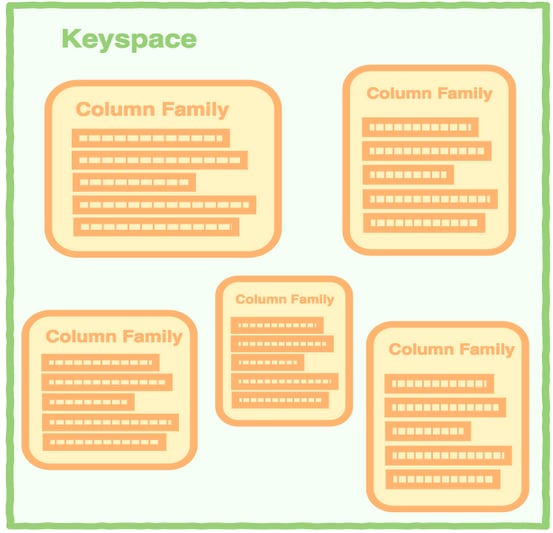
Wide-column/Columnar/Column Stores are optimized for queries over large datasets, which are stored on a column-family basis. Column stores databases use a concept called a keyspace. A keyspace is kind of like a schema in the relational model. The keyspace contains all the column families, which contain rows, which contain columns.
Columnar databases are pretty different from relational databases under the hood: instead of tables comprising a set of rows or tuples which have a value for each column, tables are a set of columns, each of which may or may not contain a value for a particular row key.
Features
- Compression: Column stores are very efficient at data compression and/or partitioning.
- Aggregation queries: Due to their structure, columnar databases perform particularly well with aggregation queries (such as SUM, COUNT, AVG, etc).
- Scalability: Columnar databases are very scalable. They are well suited to massively parallel processing, which involves having data spread across a large cluster of machines – often thousands of machines.
- Fast to load and query: Columnar stores can be loaded extremely fast. A billion row table could be loaded within a few seconds.
These are just some of the benefits that make columnar databases a popular choice for organizations dealing with big data.
Operations
Operations and some features vary wildly depending on the Management System you use.
Limitations
- Incremental data loading: It takes more time writing data than reading. Online Transaction Processing (OLTP) usage.
- Queries against only a few rows: Reading specific data takes more time than intended.
Real life examples
- A column family for vegetables of a supermarket.
- A column family for clients.
- A column family for users.
Columnar databases
The CAP Theorem

It is very important to understand the limitations of NoSQL database. NoSQL can not provide consistency and high availability together. This was first expressed by Eric Brewer in CAP Theorem.
CAP theorem or Eric Brewers theorem states that we can only achieve at most two out of three guarantees for a database: Consistency, Availability and Partition Tolerance.
- Consistency: Every read receives the most recent write or an error.
- Availability: Every request receives a (non-error) response – without the guarantee that it contains the most recent write.
- Partition tolerance: Even if there is a network outage in the data center and some of the computers are unreachable, still the system continues to perform.
No system can provide more than 2 guarantees. In the case of a distributed systems, the partitioning of the network is a must, so the trade-off is always between consistency and availability.
If you want to know more about CAP, check this link and this one.
NoSQL and Relational Databases Comparison
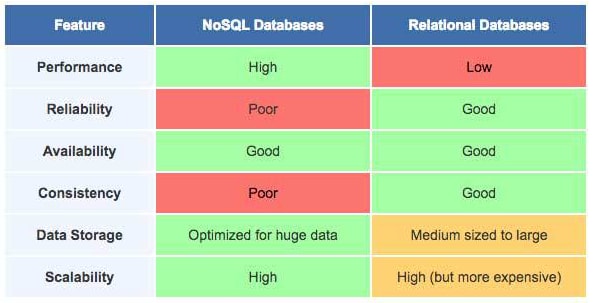
Take into consideration that this comparison is at database level, it doesn’t include any management system that implements both of them. Database Management Systems include their own techniques to sort this problems and also improve performance and reliability.
- Relational Databases: Vertical Scaling.
- Architecture design runs well on a single machine.
- To handle larger volumes of operations is to upgrade the machine with a faster processor or more memory.
- There is a limitation to size/level of scaling as you need more computers to handle more data.
- NoSQL Databases: Horizontal Scaling.
- NoSQL databases are intended to run on clusters of comparatively low-specification servers.
- To handle more data, add more servers to the cluster.
- Calibrated to operate with full throttle even with low-cost hardware.
- Relatively cheaper approach to handle increased: Number of operations and Size of the data.
- Relational Databases: Maintaining high-end RDBMS systems is expensive and requires trained workforce for database management.
- NoSQL Databases: Require minimal management, and it supports many features, which makes the need for administration and tuning requirements becomes less. This covers Automatic repair, easier data distribution and simpler data models.
- Relational Databases: Rigid Data Model.
- RDBMS requires data in structured format as per defined data model.
- As change management is a big headache in SQL with a strong dependency on primary/foreign keys, ad-hoc data insertion becomes tougher.
Note: It's worth to mention that relational databases have been getting better at working with un-structured or semi-structured data, with PostgreSQL's indexable binary JSONB datatype leading the pack. If you have a mix, fitting your unstructured data into a relational context is a lot easier and safer than trying to adapt your relational data into a NoSQL context.
- NoSQL Databases: No Schema/Data model.
- NoSQL database is schema-less so that data can be inserted into a database with ease, even without any predefined schema.
- The format or data model could be changed anytime, without application disruption.
- Relational Databases: The caching in typical RDBMS database requires separate infrastructure.
- NoSQL Databases: NoSQL database supports caching in system memory, so it increases data output performance.
Choosing a particular database
Now that we have gone through the different kinds of NoSQL, you should know by now that NoSQL databases are not similar and are not made to solve the same problems.
It is important to understand which database is appropriate depending of the scenario. The parameters to be taken into consideration when choosing a NoSQL database are:
- Database features
- Performance
- Context-based criteria
The best way to group them is comparing their features to choosing the correct one for the problem we are facing.
Feature Comparison
Scalability
- Not all NoSQL databases promise horizontal scalability on equal margins.
- HBase and Hypertable carry an advantage, while Redis, MongoDB, and Couchbase Server lag behind.
- The difference becomes more amplified as the data size grows over a few petabytes.
Transactional integrity and consistency
- Transactional integrity is applicable only when data gets modified, updated, created, and deleted.
- Not relevant in pure data warehousing and mining contexts where data is written once and read multiple times.
- Like web traffic logs, social networking status updates, stock market tick data, and game scores.
- RDBMS makes best fit if updates are common and range of operations require integrity of updates.
- Column-family databases (HBase and Hypertable), and document databases (MongoDB) are suited well if atomicity at an individual item level is sufficient.
Data modeling
Relational Database Management Systems (RBDMS) offers a consistent and organized way of modeling data with standardized implementation. The NoSQL world does not offer any room for the standardized and well-defined data model as they are not bound to solve the same problem or have the same architecture.
MongoDB has gradually adopted few RDBMS concepts, like:
- SQL-like querying.
- Rudimentary relational references.
- Database objects (inspired by the standard table and column-based model).
Query support
Querying data from any database with ease and effectively is considered to be an interesting puzzle to be solved. With standardized syntax and semantics, RDBMS thrives on SQL support for easy access to data.
Among NoSQL:
- MongoDB and CouchDB (Document DB) come with querying capabilities which are equally powerful to RDBMS.
- Redis (Key-Value DB) alone comes with querying the data structures it stores.
- Under Columnar DB, HBase has a little bit of querying capabilities.
Access and interface availability
- MongoDB dominates in this space with the availability of drivers for mainstream libraries for interfacing and interacting.
- CouchDB also has few drivers available as well as the RESTful HTTP interface.
- Language bindings to connect from most mainstream languages are available for few like Redis, Membase, Riak, HBase, Hypertable, Cassandra, and Voldemort.
NoSQL over Relational
You should choose a NoSQL database over a Relational database if:
- You have unstructured or semi-structured data, or a mix of unstructured and relational data.
- You need to support multiple queries while simultaneously loading a lot of data.
- You need to reuse portions of your data for multiple projects.
- You have rapidly changing schemas or need to take on new information sources without a six-month (or longer) development cycle.
- You need to consolidate multiple, disparate data types and sources without being forced to model data or create a schema.
Polyglot persistence
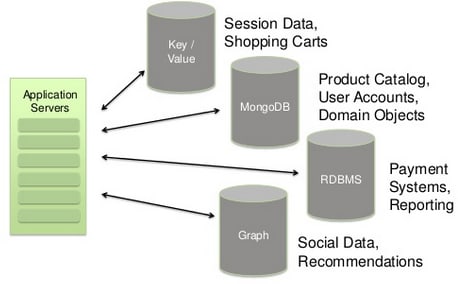
Polyglot: Knowing or using several languages.
Polyglot programming allow us to choose the appropriate language for the appropriate task. One database does not fit all sizes and knowledge and adoption of more than one database is a wise strategy. The knowledge and use of multiple database products and methodologies are popularly now being called polyglot persistence.
Benchmarking databases
Benchmarking allow us to get an insight on how the different NoSQL products stack up.
- Yahoo! Cloud Services Benchmark is one of the famous benchmarking infrastructures for comparing NoSQL products
- Tokyo Cabinet Benchmarks
- How fast is Redis
How to design a NoSQL Database
The design of NoSQL databases depends on the type of database.
-
For a guide on modeling a NoSQL Document Database, enter here. One more link here.
-
Here is a Microsoft Oficial Youtube Account video for modeling Document databases.
-
Here is the official documentation for Amazon's Key-value database DynamoDB.
- I have been told that is useful for Cassandra too if you replace references to the “Partition Key” with “Shard Key” and “Sort Key” with “Index”. They translate to MongoDB as well.
-
This link and this other one include every kind of database.
-
You can also check this interesting thread.
Important links
- NoSQL-database: A bit outdated website containing a LOT of information about NoSQL databases.
- MongoDB official documentation: Get started using the most famous Document Database.
- This article explains how to use MongoDB in Node easily thanks to Mongoose:
- Freecodecamp: It has a certificate called "Apis and Microservices" in which they teach you how to use MongoDB with Mongoose in Node.
- Free Udemy courses about NoSQL.
- Comparison of a lot of NoSQL databases.
- And, I found what I think is a controversial blog post about MongoDB that I thought you might find interesting.

Sources
- A training at my job.
- http://nosql-database.org
- MongoDB: NoSQL Explained.
- https://blog.pandorafms.org/es/bases-de-datos-nosql/
- https://blogs.oracle.com/spain/qu-es-una-base-de-datos-nosql
- https://www.hadoop360.datasciencecentral.com/blog/advantages-and-disadvantages-of-nosql-databases-what-you-should-k
- https://mapr.com/blog/data-modeling-guidelines-nosql-json-document-databases/
- Limitations of NoSQL.
- Medium: Differences between SQL and NoSQL.
- Wikipedia: ACID.
- Wikipedia: CAP Theorem.
- Wikipedia: Polyglot Persistence.
- https://howtodoinjava.com/hadoop/brewers-cap-theorem-in-simple-words/
- https://cloudxlab.com/assessment/slide/11/nosql/345/nosql-cap-theorem
- https://database.guide/what-is-a-column-store-database/
- https://www.flydata.com/blog/whats-unique-about-a-columnar-database/
- https://mapr.com/blog/data-modeling-guidelines-nosql-json-document-databases/
- https://neo4j.com/blog/why-graph-databases-are-the-future/
- https://www.quora.com/What-is-a-limitation-of-graph-database-Is-there-any-situation-when-the-performance-of-the-graph-database-degrades
- https://www.slideshare.net/blimpyacht/polyglot-persistence-52711581
- NoSQL for Dummies.
- Enterprise NoSQL for Dummies, MarkLogic Special Edition: Enter the link to get this ebook for free!
Final words
I hope you find this article useful and if you see some error and want me to correct it don't hesitate to tell me in the comments!
Thanks to Dian Fay and Slavius for corrections made in the comments!
Thank you for reading. Don't forget to follow me on dev.to and Twitter!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2018-06-05 windows 用wireshark抓本机的包