ZooKeeper 入门指引
定义
Apache ZooKeeper is an effort to develop and maintain an open-source server which enables highly reliable distributed coordination.
ZooKeeper是一个开源的,高可靠性的分布式系统协调器。它公开了一些常用的服务,如命名,配置管理,同步和组服务,你可以用它来共识、组管理、领导人选举和出席协议,甚至可以根据自己的需求来构建它.
特点
1.简单
zookeeper实现分布式协调的功能是通过一个共享的层级空间,类似于标准的文件系统,它有所谓的znodes组成,即类似文件系统中的文件和目录。但是跟文件系统不同的是,它不是用来存储的,他的数据保存在内存中,这样可以达到高吞吐低延迟的目标。在CAP理论中,zookeeper保证了CP即一致性和分区容错性,
2.可靠
zk通过一组集群来保证高度的可靠,如下图zookeeper集群当中broker相互都知道对方的存在,它们的数据状态都维护在内存,同时在磁盘会有失误日志和数据快照,只要大部分server有效就能保证zk有效。
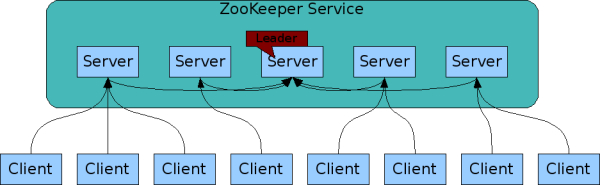
3.顺序一致性
zk为每个更新添加一个反映所有ZooKeeper事务顺序的数字。后续操作可以使用该顺序来实现更高级别的抽象,例如同步原语
4.快
它在“以读为主”的工作负载中尤其快。ZooKeeper应用程序运行在数千台机器上,在读操作比写操作更常见的情况下,它的性能最好,其比率大约为10:1。
5.类似文件系统的模型架构
zk提供的命名空间非常类似于标准文件系统的名称空间。名称是由斜杠(/)分隔的路径元素序列。zk命名空间中的每个节点都由路径标识。
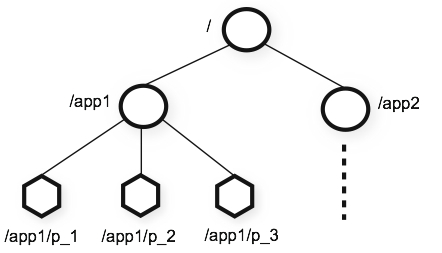
6.永久节点和临时节点
znode维护一个stat结构,其中包括数据更改、ACL更改和时间戳的版本号,以允许缓存验证和协调更新。每次znode的数据更改时,版本号都会增加。例如,每当客户机检索数据时,它也会收到数据的版本。存储在命名空间中每个znode的数据是以原子方式读写的。Reads获取与znode关联的所有数据字节,write替换所有数据。每个节点都有一个访问控制列表(ACL),它限制了谁可以做什么。
临时节点:只要创建znode的会话处于活动状态,这些znode就存在。会话结束时,znode被删除。
7.事件监听
ZooKeeper允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper服务端会将事件通知到感兴趣的客户端上去。该机制是 ZooKeeper 实现分布式协调服务的重要特性
8.简单的API
- create : 创建节点
- delete : 删除节点
- exists : 判断节点是否存在
- get data : 读取节点数据
- set data : 写节点数据
- get children : 获取子节点
- sync : 等待数据传播
下载安装
下载地址: https://zookeeper.apache.org/releases.html#download 解压到合适目录,测试版本3.5.5
将conf下样例配置文件zoo_sample.cfg复制一份重来命名为zoo.cfg,配置下数据目录和日志目录,接下来启动测试
服务端启动:zkServer.cmd
客户端启动:zkCli.cmd
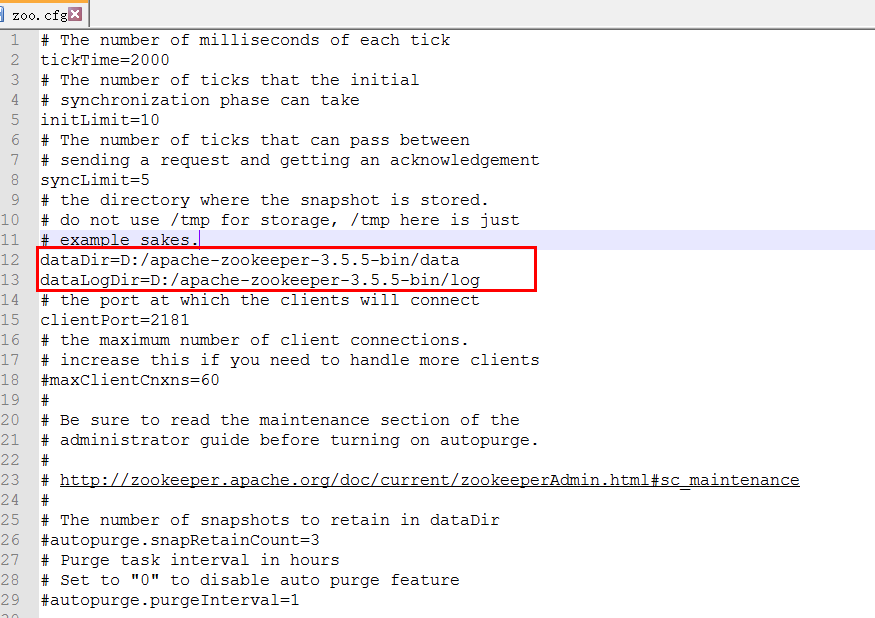

启动服务端时似乎端口被占用,所以再加个配置项
admin.serverPort=8888
同时看到myid值为空,window下测试时也没有生成myid文件,默认会去dataDir配置的目录找这个文件,可自己创建一个myid文件并在文件里写入一个序号标识该服务器,注意文件名为myid而不是myid.txt
服务端启动后可以看到有个java.exe 侦听端口2181

启动客户端


集群模式
zk的安装模式可以分为3种,分别为:单机模式,集群模式和伪集群模式。上面演示的即为单机模式;通过多台集群提供服务即为集群模式;一台电脑还可以进行伪集群模式,即在一台物理电脑上运行多个zk实例。
集群模式是通过配置文件的配置项来设置,主要涉及的配置项如下:
initLimit=10
syncLimit=5
server.1=192.168.191.1:2888:3888
server.2=192.168.191.2:2888:3888
-
initlimit:用来配置zk接受客户端(指zk集群中连接都leader的follower服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过10个心跳时间(即tickTime)长度后zk服务器还没有收到客户端返回的信息,那么表明这个客户端连接失败。总时间长度为10*2000=20s
-
synclimit:标识leader和follower之间发送消息,请求和应答时间长度,最长不能超过多少个ticktime的时间长度,总时间程度为:5*2000=10s
-
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口,通俗一点讲就是C端口用于集群内部通信,D端口用于leader选举。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
集群模式下还需要修改一个文件myid,这个文件在dataDir目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server。
对于集群模式,至少需要三台服务器,强烈建议使用奇数个服务器。如果您只有两台服务器,那么您将处于这样一种情况:如果其中一台服务器发生故障,则没有足够的计算机组成多数仲裁。两台服务器天生就比一台服务器不稳定,因为有两个单点故障
接下来我们做一个为集群模式的测试,配置出3个zk实例
-
配置文件修改,zoo.cfg文件配置出3份
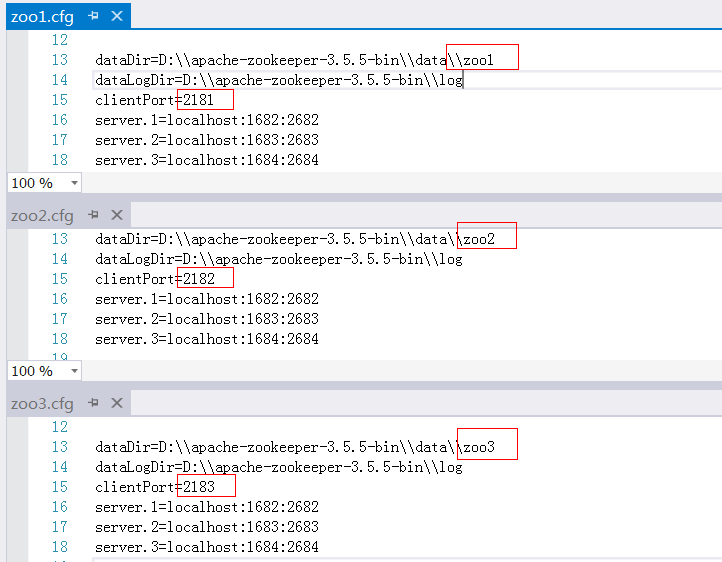
响应的在各自的datadir下创建自己的myid文件,注意无后缀名,内容为1,2,3 分别用来表示第几号服务器 -
服务端启动配置文件,同样复制3份

-
启动服务
当启动第1个cmd文件zkServer1.cmd时,会报如下错误,启动第2个cmd文件zkServer2.cmd就正常了,依次启动zkserver1.cmd,zkserver2.cmd,zkserver3.cmd,报错信息是zookeeper的Leader选举算法的异常信息,当节点没有启动完毕的时候,Leader无法正常进行工作,这种错误信息是可以忽略的,等其他节点启动之后就正常了。

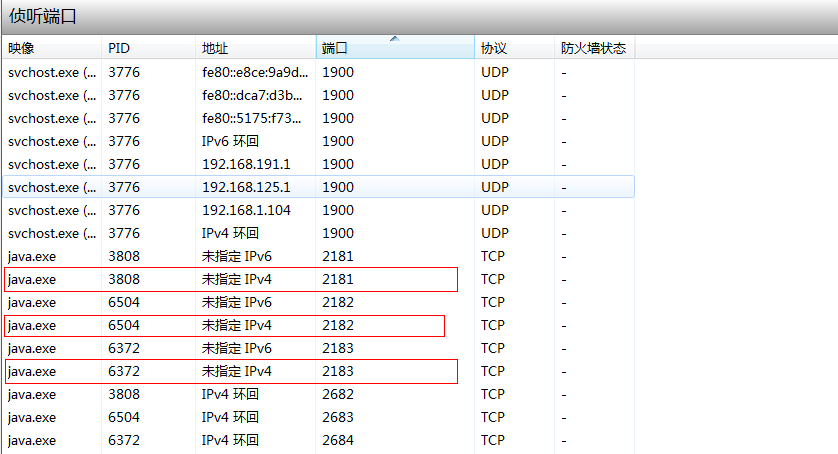
3个端口已全部启动
参考链接 https://zookeeper.apache.org/doc/r3.6.2/zookeeperOver.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号