自监督-How to find your friendly neighborhood: Graph Attention Design with Self-Supervision
动机
- 当图存在噪声的时候, 图注意力网络不总是有效的
贡献
- 提出了两种
GAT的改进 - 并且结合边预测的节点作为自监督训练的任务进行训练
技术
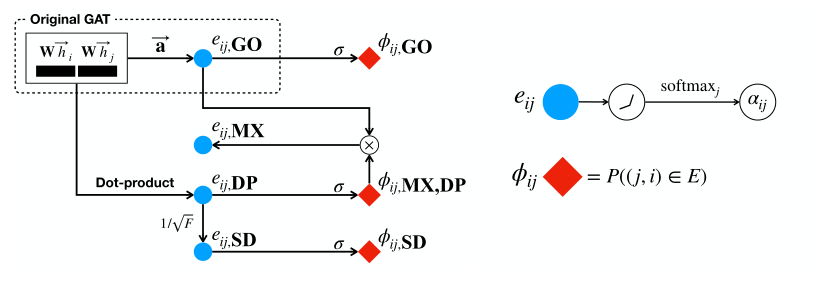
符号
对于一个图 \(\mathcal{G}(V,E)\), \(N\) 是节点的数量, \(F^l\) 是第 \(l\) 层的特征, 图注意力层就是将一个特征集合 \(\mathbb{H}^l = \{h_1^l,...,h_N^l\},h_i^l \in \mathbb{R}^{F^l}\) 作为输入然后进行输入 \(\mathbb{H}^{l + 1} = \{h_{1}^{l + 1},...,h_{N}^{l + 1}\}\), 为了计算 \(h_i^{l + 1}\), 模型将权重 \(W^{L + 1} \in \mathbb{R}^{F^{l + 1} \times F^l}\), 通过注意力系数 \(\alpha_{ij}^{l + 1}\) 和一阶邻居的特征先行结合, 最后应用一个激活函数 \(\rho\), \(h_{i}^{ + 1} = \rho(\sum_{j \in \cup \{i\}}\alpha_{ij}^{l + 1}W^{l + 1}h_j^{l})\), 通过归一化 \(e_{ij}^{l + 1} = a_e(W^{l + 1}h_{i}^{l}, W^{l + 1}h_{j}^{l})\) 计算 \(\alpha_{ij}^{l + 1} = softmax_j(LReLU(e_{ij}^{l + 1})\)
图注意力形式
两种广泛使用的注意力机制, 原始的 GAT(GO) 是通过参数化 \(a^{l + 1} \in \mathbb{R}^{2 \times F^{l + 1}}\) 的单层前馈网络计算系数:
另一种是通过点乘注意力:
思想
Self-supervised Graph Attention Network(自监督图注意力网络)
提出了 SuperGAT, 其思想是通过节点对之间有无边来引导注意力. 利用链接预测任务用来自边的标签来自我监督注意力: 对于一对节点 \((i,j)\), 如果边存在, 则为1,否则为0. 我们引入 \(a_{\phi}\) 和 sigmoid \(σ\) 来推断 \(i\) 和 \(j\) 之间的边的概率:
基于 GO和 DP 注意力,采用了四种类型 (GO、DP、SD、MX) 的 SuperGAT 测试. 对于 \(a_{\phi}\) , 其形式在 \(SuperGAT_{GO}\) 和 \(SuperGAT_{DP}\) 上相同的 \(a_{e}\),我们分别将其命名为 \(SuperGAT_{GO}\) 和 \(SuperGAT_{DP}\). 对于更高级的版本,我们通过不规范的注意 \(e_{ij}\) 和概率 \(\phi_{ij}\) 来描述\(SuperGAT_{SD}\) (缩放的点积)和 \(SuperGAT_{MX}\) (混合的 GO 和 DP)
\(SuperGAT_{SD}\) 将点积除以维数的平方根即为 Transformer , 主要是为了防止 softmax 之后过大的值占据整个注意力, \(SuperGAT_{MX}\) 将 GO 和带有 sigmoid 的DP 相乘, 其动机来自于门控循环单位的门控机制, 由于使用sigmoid的DP注意力代表了一条边的概率, 它可以柔化掉不太可能链接的邻居, 同时隐式地将重要性分配给其余节点. 训练样本来自边集合和互补集合 \(E^{c} = (V \times V) / E\), 如果节点的数量很大, 适用所有在 \(E^c\) 上的负样例是没有效率, 因此, 在训练单词过图嵌入时使用负采样, 在 \(E^c\) 中任意训责数量为 \(p_n \cdot |E|\) 的负样本 \(E^-\), 其中负采样率为 \(p_n \in \mathbb{R}^+\) 时一个超参, \(SuperGAT\) 能够对认为足够多的负样本对的稀疏图进行建模, 定义第 \(l\) 层的优化目标为一个二进制交叉熵损失 \(\mathcal{L}_{E}^{l}\):
其中 \(1_·\) 为指示函数. 我们使用 \(E\cup E^−\) 的一个子集, 在每次训练迭代中以概率 \(p_e \in (0,1)\) (也是一个超参数)采样, 以获得来自随机性的正则化效果. 最后, 我们将节点标签的交叉熵损失(\(\mathcal{L}_V\) )、所有层的自监督图注意损失(\(\mathcal{L}^l_E\)) 和 L2 正则化损失与混合系数 \(\lambda_E\) 和 \(\lambda_2\) 结合起来
我们在 GAT 中采用相同的多头注意形式, 取每个头的注意值的均值计算 \(\phi_{ij}\). 需要注意的是, SuperGAT 与 GAT 具有相同的时间和空间复杂度. 为了计算一个头, 我们需要对 \(O(F^l·|E\cup E^−|)\) 进行额外的运算, 而不需要额外的参数
结果
RQ1. 注意力是否学习标签的一致性
本文认为, 相连接的节点的表征在深层 GAT 中收敛到相同的值, 如果两个标签不一样的节点存在边, 那么即使足够深的网络也无法将其区分. 所以, 理想的注意力应该把所有权重都赋予标签一致的邻居, 从而证明注意力时能够学习到标签的一致性.
构建了归一化的注意力 \(\alpha_k = [\alpha_{kk}, \alpha_{k1},...,\alpha_{kJ}]\), 还有标签一致性分布 \(\ell_k = [\ell_{kk}, \ell_{k1}, ..., \ell_{KJ}]\), 其中 \(J\) 表示其邻居节点:
并利用 KL 散列来进行衡量, 当注意力很好捕捉到一个节点与其邻居之间标签一致时, KL 散度的值就会变得很小:
RE1.

GO 学习到标签一致性要比 DP 好, DP 注意力的方差随着层次的加深而增加, 而 GO 的方差只依赖于特征的范数, DP 的方差则依赖于输入点积的平方的期望值和输入点积的方差. 在叠加 GAT 层时, 与之相关的特征越多, 输入的点积越大. 经过 softmax 对 DP 注意进行归一化处理后, 它们中的较大值得到强化, 归一化处理后DP注意只注意到邻居的一小部分, 学习到有偏差的表征.
RQ2. 注意力能预测边是否存在
为了评估在 SuperGAT 中边信息编码的良好程度, 我们使用 \(SuperGAT_{go}\) 和 \(SuperGAT_{DP}\) 进行了链路预测实验, 并使用最后一层的 \(\phi_{ij}\) 作为预测器. 通过多次运行的并使用 AUC 来度量性能. 由于链路预测性能取决于混合系数等式6,我们采用多个 \(\lambda_E \in \{10^{−3},10^{−2},…10^3\}\). 用一个不完整的边集进行训练, 用缺失边和相同数量的负样本进行测试. 与此同时, 使用相同的设置来测量节点分类性能, 以了解学习边的存在如何影响节点分类
RE2.

DP 预测的边存在优于 GO , 这意味着, 通过简单地优化图的注意来进行链接预测, 很难从边学习关系重要性.
RQ3. 对于给定的图, 我们应该使用那种注意力
以上两个研究问题中探讨了在有无边缘存在监督的情况下, 不同的图注意力会学到什么. 那么, 对于给定的图, 哪种图注意是有效的呢? 假设在不同的同质性和平均度下, 不同的图注意力对图的建模能力不同. 我们在各种图统计信息中选择这两个属性, 因为它们决定了自监督任务中标签的质量和数量. 从带边缘标签的图注意力监督学习的角度来看, 学习结果取决于标签的噪声程度(即标签的噪声程度). 同质性有多低)和有多少标签存在(即平均学位有多高).
RE3.
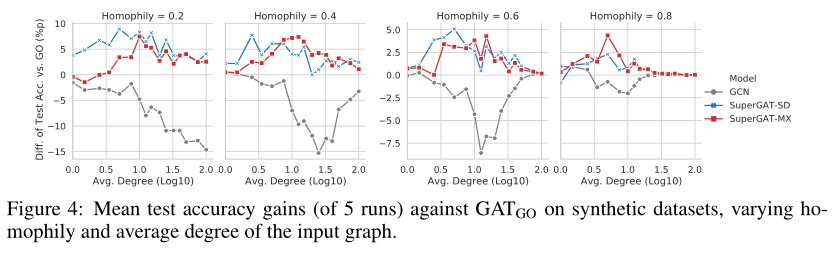
依赖同质性和度的平均
同质性指的是网络中噪声的大小, 平均出度指的是网络中建立边的频率. 其中, 同质性的计算方法如下:
在平均出度问题上, 文章指出, 具有正确标签的数据的绝对数量比噪声和正确标签间的相对比例更能影响学习质量
总结
据输入图的特点, 提出了一种新的图神经结构设计来实现对图注意力的自监督. 首先评估了什么是图注意力在学习, 并分析了边缘自监督对链接预测和节点分类性能的影响. 该分析表明, 两种广泛应用的注意机制(原始的 GAT 和 dot-product )难以同时编码标签一致性和边缘存在. 为了解决这一问题, 提出了几种图的注意形式来平衡这两个因素, 并认为图的注意应根据输入图的平均程度和同质性来设计. 我们的实验表明, 我们的图注意力配方适用于各种真实世界的数据集, 因此根据配方设计的模型优于其他基线模型.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号