自监督-Self-supervised Learning on Graphs:Deep Insights and New Directions
动机
- 图数据于图像或者文本数据不同, 图像或者文本时属于欧式数据且都是服从独立同分布; 而对于图数据而言, 它是非欧式数据, 并且图中的节点相互连接表示着他们独立同分布的
贡献
- 探究了图上的自监督任务, 具体来说, 图有多种潜在的代理任务; 因此, 了解
SSL在什么时候和为什么适用于GNN, 以及哪种策略可以更好地集成GNN的SSL是很重要的 - 在图上启发
SSL的新方向. 特别是, 研究这些见解是如何激发更复杂的方法来设计代理任务的. 为了实现第一个目标,直接基于属性和结构信息设计了基本类型的代理任务. 通过深入分析SSL对GNN性能的影响,在图上得出了一些关于SSL的重要发现. 这些发现允许我们提出一个新的方向SelfTask设计更先进的代理任务, 经经验证明, 在各种图数据集上实现最先进的性能
前置知识
问题说明
一个图表示: \(\mathcal{G} = (\mathcal{V}, \mathcal{E}, X)\), \(\mathcal{V} = \{v_1,v_2,...,v_N\}\) 表示 \(N\) 个节点的集合, \(\mathcal{E}\) 表示边集, \(X = [x_1, x_2, ... , x_N]\) 是特征矩阵, 其中节点 \(v_i\) 的特征为 \(x_i\) , 图结构信息用一个邻接矩阵表示: \(A \in [0,1]^{N\times N}\), 其中 \(1\) 表示存在边, \(0\) 表示不存在边. 在半监督的节点分类任务中, 有标签的节点集合 \(\mathcal{V}_{L}\) 所关联对应的标签 \(\mathcal{Y}_{L}\). 定义标签数据 \(\mathcal{D}_{L} = (\mathcal{V}_{L},\mathcal{Y}_{L})\), 没有标签的数据 \(\mathcal{D}_{U}\), 让 \(f_{\theta}: \mathcal{V}_{L} \rightarrow \mathcal{Y}_{L}\), 半监督节点分类任务可以形式化为最小化损失 \(\mathcal{L}_{task}\):
其中 \(\theta\) 是用于 \(f_{\theta}\) 的参数, \(f_{\theta}(\mathcal{G})_{v_i}\) 预测节点 \(v_i\) 的标签, \(\ell(\cdot,\cdot)\) 定义为损失函数用于测量真实标签和预测标签的度量.
问题1
给定图的数据集,该数据集表示为带有成对标记数据 \(\mathcal{D}_{L} =(\mathcal{V}_{L},\mathcal{Y}_{L})\) 的图 \(G= (A,X)\), 目标是构建一个具有相应损失函数 \(\mathcal{L}_{self}\) 的自监督代理任务, 该任务可以与特定于任务的 \(\mathcal{L}_{task}\) 集成, 以学习一个能够更好地推广未标记数据的图神经网络 \(f_θ\)
Basic Pretext Tasks on Graphs(基本代理任务)
Structure Information(结构信息)
在图中提取自监督信息的第一自然选择是数据背后的固有结构. 这是因为与图像和文本不同. 在图中, 我们的数据实例是相关的(即节点链接在一起). 因此, 一个主要方向是基于未标记节点的局部结构信息, 或者它们如何与图的其余部分相关联, 为它们构建自我监督信息. 换句话说, 用于建立自监督借口任务的结构信息可以被分类为局部或全局结构信息
局部结构信息
-
NodeProperty(节点特征: eg 度): 在此任务中, 旨在预测图中每个节点的属性, 如它们的度、局部节点重要性和局部聚类系数. 这个代理任务的目标是(进一步)鼓励GNN除了正在优化的特定任务之外, 还学习本地结构信息. 在这项工作中, 我们使用节点度作为代表性的本地节点属性进行自我监督, 而将其他节点属性(或其组合)作为一项未来工作. 更正式地说, 我们让 \(d_i = \sum_{j = 1}^{N} A_{i,j}\) 定义为 \(v_i\) 的度, 并将自监督代理任务的相关损失构造为:\[\mathcal{L}_{self} (\theta',A,X,\mathcal{D}_{U}) = \frac{1}{|\mathcal{D}_{U}|} \sum_{v_i \in \mathcal{D_{U}}}(f_{\theta'}(\mathcal{G})_{v_i} - d_i)^2 \]中 \(\theta\) 用于表示图神经网络模型的参数 \(f_{\theta}\), \(\mathcal{D_{U}}\) 表示图中未标记节点和相关代理任务标签的集合, 并且使用\(f_{\theta'}(\mathcal{G})_{v_i}\) 表示节点 \(v_i\) 的预测本地节点属性(在本例中是预测节点度). 构建与本地节点属性相关的自监督代理任务的直觉是最终引导来自
GNN的特征(即节点表示)来保存该信息. 这依赖于这样的假设, 即这样的节点属性信息与感兴趣的特定任务相关. -
EdgeMask(边掩蔽): 对于边屏蔽任务, 我们寻求发展自我监督不仅基于单个节点本身, 而是基于图中两个节点之间的连接成对地. 具体来说, 首先随机屏蔽一些边, 然后要求模型重建被屏蔽的边. 具体做法首先掩蔽的边 \(m_e\) 定义为集合 \(\mathcal{M}_e \subset \mathcal{E}\), 并对大小相等的节点对(即 \(|\bar{\mathcal{M}_e}| =|\bar{\mathcal{M}}_e|=m_e\)) 的集合 \(\mathcal{M}_e=\{(v_i,v_j)|v_i, v_j\in \mathcal{V}~~~and~~~~ (v_i,v_j) \notin\mathcal{E} \}\) 进行采样. 然后, 这里的SSL代理任务是预测给定节点对之间是否存在链接. 更正式地说, 我们将相关损失构建为:\[\mathcal{L}_{self} =(\theta',A,X,\mathcal{D}_{U}) = \frac{1}{{\mathcal{M_e}}} \sum_{v_i,v_j \in \mathcal{M}_e} \ell(f_w(f_{\theta'}(\mathcal{G})_{v_i} - f_{\theta'}(\mathcal{G})_{v_j|}),1) + \frac{1}{\bar{\mathcal{M_e}}} \sum_{v_i,v_j \in \bar{\mathcal{M}_e}} \ell(f_w(f_{\theta'}(\mathcal{G})_{v_i} - f_{\theta'}(\mathcal{G})_{v_j|}),0) \]其中 \(f_{\theta'}(\mathcal{G})_{v_i}\) 参见节点 \(v_i\) 的嵌入, \(\ell(\cdot,\cdot)\) 是交叉熵损失, \(f_w\) 线性映射到 \(1\) 维, 而\(v_i\) 和 \(v_j\) 之间具有链接的类别由 \(1\) 和 \(0\) 表示. 总之, 这种方法有望帮助
GNN了解有关本地连接的信息.
全局结构信息
-
PairwiseDistance(双向距离): 边掩蔽代理任务是从基于掩蔽的局部结构角度出发, 试图恢复/预测图中的局部边. 我们进一步开发了 “(PairwiseDistance)双向距离”, 旨在通过成对比较来指导图神经网络维护全局拓扑信息. 换句话说, 借口任务被设计成能够区分/预测不同节点对之间的距离. 我们注意到, 距离可以通过多种方式来测量, 例如是否在相同的连接部分/集群中, 个性化的PageRank或其他计算节点相似度的全局链路预测方法[12]等. 在这项工作中, 类似于[11]中的全局上下文预测, 我们选择使用最短路径长度作为节点之间距离的度量. 更具体地说, 我们首先计算所有节点对 \(\{(v_i,v_j)|v_i,v_j \in \mathcal{V}\}\) 的成对节点最短路径长度 \(p_{ij}\), 并进一步将长度分为四类 \(p_{ij} = 1、p_{ij}= 2、p_{ij}= 3、p_{ij}≥4\). 为两个节点之间的路径长度选择四个的原因是,GNN应该能够在某种程度上正确判断两个节点之间的距离, 但是如果我们要包括更多的类, 它将: 1)需要更多的计算来发现所有实际的成对距离(如果大于 \(4\)); 以及 2)潜在地过度匹配图中的一些较长的成对距离, 与较短的路径长度相比, 这些距离变得相当嘈杂. 此外, 由于在训练过程中使用目标中的所有节点对在计算上是昂贵的, 因此在实践中, 我们在每个时期随机抽样一定数量的节点对用于自我监督,SSL损失然后可以被公式化为如下的多类分类问题\[\mathcal{L}_{self}(\theta',A,X,\mathcal{D}_{U}) = \frac{1}{|\mathcal{S}|} \sum_{v_i,v_j \in \mathcal{S}} \ell(f_w(|f_{\theta'}(\mathcal{G})_{v_i} - f_{\theta'}(\mathcal{G})_{v_j}|),C_{p_{i,j}}) \] -
Distance2Clusters(距离簇): 尽管PairsewiseDistance采用了一种采样策略来降低时间复杂度, 但它仍然非常耗时, 因为我们需要计算所有节点对的成对距离. 相反, 我们通过预测从未标记的节点到预定义的图簇的距离(同样根据最短路径长度)来导出一个新的探索全局结构信息的SSL代理任务. 这将迫使表示学习每个节点的全局位置向量. 换句话说, 不是一个节点成对地预测到图中任意其他节点的距离, 而是我们建立一组与图簇相关联的固定锚/中心节点, 然后每个节点将预测到这组锚节点的距离. 具体来说, 我们首先对图进行划分, 得到 \(\{C_1, C_2, ..., C_k\}\) 通过应用METIS图划分算法[13], 因为它在文献中被普遍使用. 在每个集群 \(C_j\) 中, 我们将具有最高度的节点指定为相应集群的中心, 表示为 \(c_j\). 然后, 我们可以有效地为每一个节点创建一个集群距离向量 \(d_i \in \mathbb{R}^{k}\), 其中 \(d_i\) 的第 \(j\) 个元素的距离是从 \(v_i\) 到中心 \(C_j\) . 因此,Distance2Clusters的SSL目标是预测这个距离向量, 优化问题可以表述为多元回归问题:\[\mathcal{L}_{self}({\theta'},A,X,\mathcal{D}_{U}) = \frac{1}{|\mathcal{D}_{U}|} \sum_{v_i \in \mathcal{D}_{U}}\|f_{\theta'}(\mathcal{G})_{v_i} - d_{i}\|^2 \]
Attribute Information(属性信息)
AttributeMask(属性掩蔽): 这个任务类似于EdgeMask, 但是我们希望GNN可以通过SSL学习更多的属性信息. 因此,我们随机屏蔽(即设置为零)节点 \(m_a\) 的特征 \(\mathcal{M}_a \subset \mathcal{V}\), 然后要求自监督重构这些特征, 更正式地说:
然而,大多数真实数据集的特征通常是高维和稀疏的。因此,在实践中,我们首先使用主成分分析(PCA)在应用属性屏蔽之前获得减少的密集特征
PairwiseAttrSim(节点相似): 与图像等其他领域的数据样本相比, 在图结构数据中, 聚合过程实际上是合并来自多个实例的特征, 以发现学习到的表示. 因此, 给定具有相似属性的两个节点, 它们的学习表示不一定相似(与例如两个精确的图像将在典型的深度学习模型中获得相同的表示相比). 更一般地, 由于来自两个节点局部邻域的GNN聚集特征, 两个节点在输入特征空间中的相似性在学习的表示中不能得到保证. 这可能会产生一把双刃剑, 因为尽管我们希望利用GNN的本地邻域来增强节点特征变换, 但我们仍然希望在某种程度上保持数据实例相似性的概念, 并且不允许节点的邻域大幅改变其属性签名. 因此, 我们建立了节点属性相似性的基于属性的SSL代理任务. 由于大多数成对相似度接近于零, 我们开发了以下成对采样策略. 首先, 我们将 \(\mathcal{T}_s\) 和 \(\mathcal{T}_d\) 分别表示具有最高相似性和不相似性的节点对的集合,我们更正式地将其定义为:
其中 \(s_{ij}\) 测量 \(v_i、v_j\)(根据余弦相似性)节点特征相似性和 \(K\) 是为每个节点选择的顶部/底部对的数量. 现在,我们可以将回归问题如下
其中 \(\mathcal{T} = \mathcal{T}_s \cup \mathcal{T}_d\) 并且 \(f_w\) 线性映射到一维.
训练方式
Joint Training(联合训练)
联合训练的目标是同时优化自监督损失 \(\mathcal{L}_{self}\) 和监督损失 \(\mathcal{L}_{task}\), 联合训练如下图所示; 其本质上可以分为两个阶段: 特征提取过程和自监督的代理任务以及下游任务, 对于特征提取层我们使用的是相同的参数 \(\theta_z\), 其特征提取便可以表示为 \(f_{\theta} \rightarrow Z\) , 而相应的节点嵌入 \(z_i = f_{\theta_z}(\mathcal{G}_{v_i})\) ,而对于各自向的任务则用相应的参数, 使用 $f_{\theta_y}(z_i) \rightarrow \hat{y_i} $ 表示适配器/分类器通过 \(f_{\theta}\) 将节点 \(v_i\) 的embeding\(z_i\) 映射到预测的类, 此外,自监督代理任务可以被公式化以利用相同的特征提取器 \(f_{\theta_z}\) 和额外的适配器 \(f_{\theta_s}\), 因此, 总体目标可定义如下:
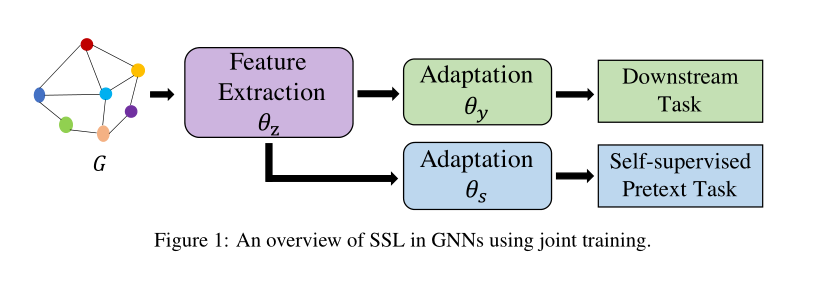
Two-stage Training(两次训练)
两次训练的目的就是预训练 (pretrain) 和微调 (Fine-tuning)

不同策略的训练效果比较
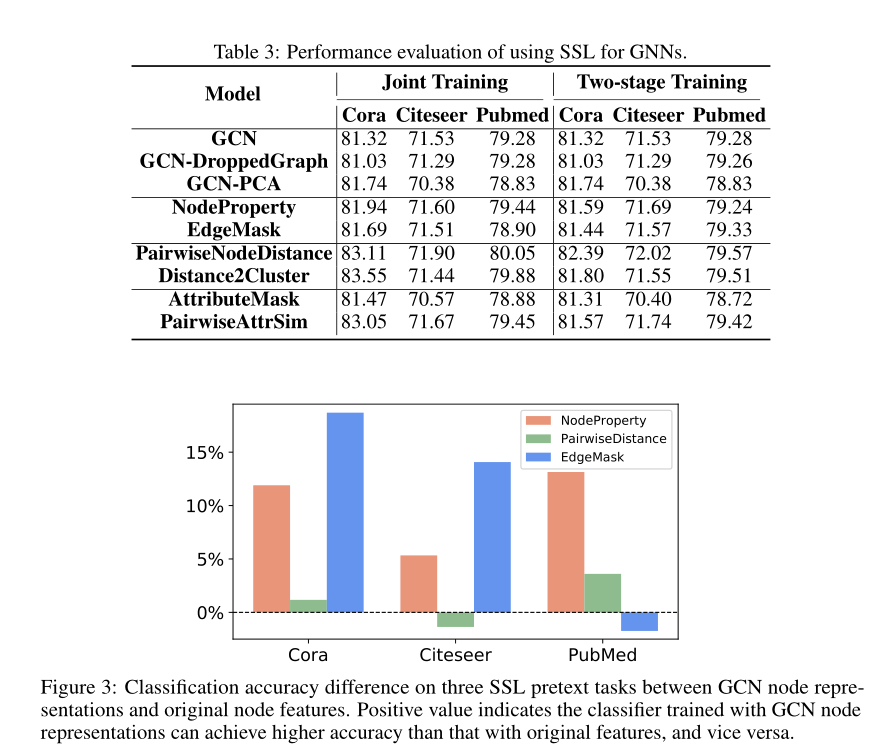
- 实验结果表明联合训练方式实际上是比预训练-微调的训练方式更加的有效, 由于联合训练没有那么复杂, 只需要调节参数 \(\lambda\) 即可, 而预训练-微调训练方式由更高的灵敏度且工作量很大, 所以效果没有那么好.
- 对于一些自监督任务来时, 有全局信息的能更好的帮助模型提高分类准确率, 而局部信息提升的准确率比较低, 由此也可以知道
GCN一般能学习的局部的信息, 而不能学习到全局特征信息. - 为什么自监督代理任务可以提升
GCN, 正如我们前面提到的,GCN对于节点分类自然是半监督的, 已经探索了未标记的节点. 因此, 一些自我监督无济于事的一个可能原因可能是, GCN本身已经可以了解到这些信息. 如果是这种情况, 那么在额外的自我监督代理任务上的训练可能不会进一步提高性能可以为了验证这个假设, 我们在来自GCN的原始节点特征和节点表示上训练逻辑回归分类器(没有自监督代理任务) 去预测代理任务, 上图表示了GCN可以学习到图的一些局部信息而很少能学习到一些全局信息.
思想
SelfTask: Distance2Labeled
首先研究修改性能最好的全局结构借口任务之一 Distance2Cluster, 以考虑来自标记节点的信息. 为了将标签信息与图结构信息相结合, 提出预测每个节点到标签节点 (\(\mathcal{V}_L\)) 的距离向量作为 SSL 任务. 对于类 \(c_j \in \{1,...,K\}\) 和未标记节点 \(v_i\in \mathcal{V}_U\), 我们计算了从 \(v_i\) 到类 \(c_i\) 中所有标记节点的平均、最小和最大最短路径长度. 因此, 节点 \(v_i\) 的向量距离可以表示为 \(d_i\in \mathbb{R}^{3K}\). 在形式上, SSL目标可以表述为如下的多元回归问题:
这个公式可以看作是加强全局结构代理的一种方式,但主要集中在利用标记节点的任务特定信息上
SelfTask: ContextLabel
利用结构、属性和当前标记的节点为每个节点构建邻居标记分布上下文向量, 如下所示:
更具体地说,定义节点的上下文通过其 \(k\) 跳邻居中的所有节点, 其中标签分布向量的第 $c $ 个元素可以定义为:
其中 \(\mathcal{N}_{\mathcal{V}_{U}}(v_i)\) 定义为邻居集合从 \(\mathcal{V}_U\) 中的节点 \(v_i\), \(\mathcal{N}_{\mathcal{V}_U}(v_i, c)\) , 表示邻域集中已经被赋值了类c(对于 \(V_L\) 邻域集有类似的定义), 而 \(\mathcal{D}_U = (\mathcal{V}_U, \{ y_i|v_i\in \mathcal{V}_U\})\)). 此外, 基于常规任务等价概念的代理任务的目标函数可以被表述为:
可以选择几种方法将标签信息扩展到所有未标记的节点. 一种方法是使用基于结构等价的方法, 在这种方法中, 选择使用标签传播(\(LP\)), 因为它只使用 \(A\)(尽管其他方法, 如最短路径, 可以在这里扩展, 如在Distance2Lable 中使用的). 另一种方法是同时使用结构等价和属性等价, 其中我们使用利用两者的迭代分类算法(\(ICA\)). 邻居标签分布上下文向量 \(\{ \bar{y}_i | v_i \in \mathcal{V}_U\}\) 可能有噪声,因为包含了由 \(f_s\) 产生的弱标签(例如,当使用 \(LP\) 或 \(ICA\) 时). 接下来我们介绍两种改进 ContextLabel的方法
SelfTask: EnsembleLabel
有各种方法来定义基于相似性的函数,如线性规划和独立分量分析。因此,一种改进ContextLabelis的可能方法是集成各种函数。如果在fs内部使用LP和ICA时,我们让一个nodevito的类概率分别为σLP(vi)和σICA(vi),那么我们可以将它们组合起来选择yias,
我们可以使用集合的YF来构造上下文标签分布, 如公式 \((12)\) 并遵循等式中定义的代理目标 \((13)\).
SelfTask: CorrectedLabel
我们设计了修正标签作为替代接口任务, 通过迭代改进上下文向量来增强上下文标签. 更具体地说, 我们采用迭代训练 GNN 和校正标签的方法, 类似于[20]中使用训练和校正阶段的迭代训练. 在训练阶段, 我们使用校正后的标签为未标记的节点构建校正后的上下文标签分布向量, 类似于等式 \((12)\) 除了用于 SSL任务的 \(\mathcal{D}_U= (\mathcal{V}_U,\{ \hat{y}_i|v_i \in \mathcal{V}_U\})\) 之外,我们还使用\(\mathcal{D}_U= (\mathcal{V}_U,\{ \bar{y}_i|v_i \in \mathcal{V}_U\})\) 来表示具有其校正的上下文标签分布的未标记数据样本. 然后, 在原始(例如 \(y_i\) )和校正(例如 \(y_i\) )上下文分布上训练 GNN \(f_θ\),其中损失可以表述:
其中第一和第二项分别适合原始和校正的上下文分布, \(α\) 控制来自校正的上下文分布的贡献. 在标签校正阶段, 我们使用经过训练的 GCN 来选择类别原型 \(Z_c= \{z_{c1},...,z_{cp}\}\)(表示为深层要素), 用于生成校正后的标签. 更具体地说, 首先随机采样同一个类中的节点来计算它们的成对相似性矩阵, 其中基于它们的嵌入来计算两个节点之间的余弦相似性. 然后我们将每个节点的密度 \(ρ_i\) 定义为:
其中 \(S_c\) 是一个常数值(我们选择它作为[20]中建议的前 \(40\%\)中的值)和 \(sign(x) = 1,0 ~~~~if~~~~~x >0,= 0 ~~~or~~~ <0\)。 根据公式,较小的 \(ρ\) 表示该节点与同一类中的其他节点不太相似. 标签不一致的节点通常彼此隔离,而标签正确的节点应该彼此靠近. 因此, 我们选择具有顶级目标 \(ρ\) 值的节点作为类原型. 然后我们计算修正后的标签 \(\hat{y}_i \in \{ 1,...,K \}\) 对于节点 \(v_i \in \hat{\mathcal{V}_U}\)
其中 \(cos(\cdot,\cdot)\) 用于表示两个样本之间的余弦相似性. 换句话说, 我们用\(v_i\) 和 \(p\) 之间的平均相似度来表示 \(v_i\) 和相应类之间的相似度, 然后将相似度最大的类分配给 \(c\). 通过迭代这两个阶段, GNN 可以逐渐学习校正后的标签(例如,\(\hat{y}i\)).
实验

结论
仔细研究了用于节点分类任务的 GNNs 中的 SSL. 首先为图介绍了各种基本的 SSL 代理任务, 并给出了详细的实证研究, 以了解 SSL何时以及为什么适用于 GNNs, 以及哪种策略可以更好地适用于 GNNs. 接下来, 基于我们的见解, 我们提出了一个新的方向自我监督任务来构建高级代理任务, 进一步利用特定任务的自我监督信息. 在真实数据集上的大量实验表明, 我们的先进方法获得了最先进的性能. 未来的工作可以在探索新的借口任务和在预训练图神经网络中应用所提出的SSL策略上进行.

