知识蒸馏--Distilling the Knowledge in a Neural Network
知识蒸馏--Distilling the Knowledge in a Neural Network
动机
- 在普遍的训练当中,经过 softmax 后都是最大化正标签的概率,最小化负标签的概率。但是这样训练的效果导致了正标签的概率输出越来越接近 1, 负标签的概率越来越接近 0, 使得原本的负标签的概率有一些是比其他的大得多,但是这种相对关系在经过多次训练后他们的概率都是渐渐趋近 0. 所以导致模型输出概率原本还有大量的信息丢失。
- 一般认为,用于训练的目标函数应该是尽可能反应用户的真实标签,因为越接近真实标签那么精度或者准确率却高,但是机器学习所需要的是学习它的泛化能力,并不是它的真值标签。在遇到未曾讲过的样本要能够进行正确的分类。然而由于条件所限,我们一般把提升模型的泛化能力这个目标简化为训练模型在训练集上对真值标签的预测能力,我们也认为,训练得到的模型对真值标签的预测能力越强,它的泛化能力也应该越强,这也是很合理的。
贡献
- 提出了知识蒸馏,把大模型对样本输出的概率向量作为软目标“soft targets”,去让小模型的输出尽量去和这个软目标靠。
思想
预备知识
\(softmax\) 函数:
交叉熵:
交叉熵损失函数:
假设样本数量 \(n\) ,真实标签为 T,\(T = \{t_1, t_2, ... , t_c\} \quad \quad t_i \in R^{c}\),预测值为 Y, \(Y = \{y_1,y_2, ..., y_n\}\quad\quad y_i \in R^p\)
对于分类问题,在神经网络最后一层的激活函数一般是 \(softmax\) 归一化并且输出概率向量,并通过最小化交叉熵损失函数进行反向传播更新参数,假设标签为 \(one-hot\) 形式, 那么上式交叉熵损失函数化简为 \(l_{CE} = -\sum_{i = 1}^{n} \log y_{ik} \quad s.t\quad t_{ik} == 1\) ,最小化损失函数,就是要最大化概率值,既是使真标签对应概率不断趋近于 1, 负标签的概率不断趋近于 0,最后输出的概率(目标)就是趋近 \(one-hot\) 形式,我们称为\(L_{hard}\),该目标称为 hard target。
与 hard target 对应的就是 soft target,soft target 中分布的熵相对更高,其蕴含的知识就更加丰富。
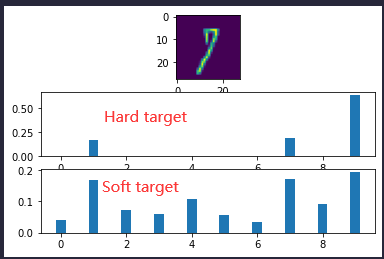
那如何才能得到熵相对高的 soft target 呢,由于传统的 \(softmax\) 如果直接作为 soft target 那么导致负标签的概率趋近 0,正标签的概率趋近 1, 熵就会相对的低,这时候就要引入温度
为什么引入温度就可以,可以通过看一下 指数函数 \(y=e^x\) 的曲线。
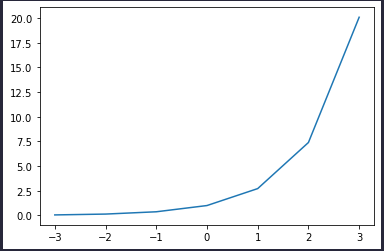
可以发现,\(Z\) 如果本身就是类似\([-10, 20, 40, -5, -8]\) 这样的向量经过指数后原本存在的差距将会变得越来越大(正的越来越大,负的越来越趋近 0),导致 softmax 归一化后的更偏向于 \(one -hot\) 形式,而这也是指数函数达到一个放缩的效果。 而通过引入温度后,使得 \(Z\) 都趋于集中,让 softmax 输出更加平滑(也就是 \(Z\) 在指数函数上更趋于平滑 )。 让它的分布的熵更大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
框架
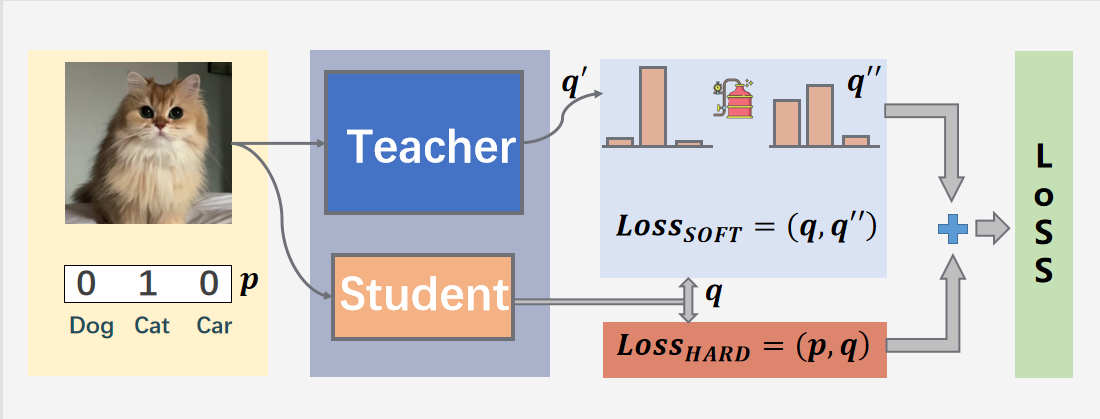
teacher 模型就是一个大的复杂模型,效果好,student 模型是一个轻量型的模型,我们的目的是将student 模型经过训练后达到 teacher 模型的效果,或者比teacher模型更好。对于训练 student 模型中损失函数主要由两部分组成,一部分使 teacher 模型经过知识蒸馏后得到 soft loss,在于自己模型普通训练后的 hard loss。总的loss = soft loss + hard loss。
核心
就是在原来的损失函数进行加权 \(L_{soft}\):
其中 \(\alpha 、\beta\) 分别为超参数
\(v_i,z_i\) 分别表示在相同温度下 teacher,student 网络下输出的预测的每个值 (logits),还没有经过 softmax
实验

 浙公网安备 33010602011771号
浙公网安备 33010602011771号