预训练-Contrastive Self-supervised Learning for Graph Classification
预训练-Contrastive Self-supervised Learning for Graph Classification
标签:预训练、图神经网络、对比学习
动机
- 图分类在真实世界中有广泛的应用,比如一些化学分子和生物相关的研究,但是这些分子结构往往有很多,但是缺少真是标记,用于训练的图数量是有限的,当训练数据有限的时候,模型就会倾向于过拟合,对测试数据的性能就会大幅度降低。
- 在大多数无监督的图对比学习中,都是比较关注于图的局部信息,比如节点和子图,很少有关注于整图的表示。
贡献
- 提出了 CSSL-pretrain 方法,该方法是通过运用对比学习的方式对使得图编码器学习刚高阶的表示,防止过拟合。
- 提出了 CSSL-Reg 方法,该方法时基于 CSSL 上的依赖数据正则化器,以降低图编码器偏向于在小规模训练数据上的数据不足而导致分类任务风险。
核心思想
思想
首先基于原始图生成增广图,创建预测任务,预测两个增广图是否来自通过原始图,并通过该任务训练图编码器
图增强
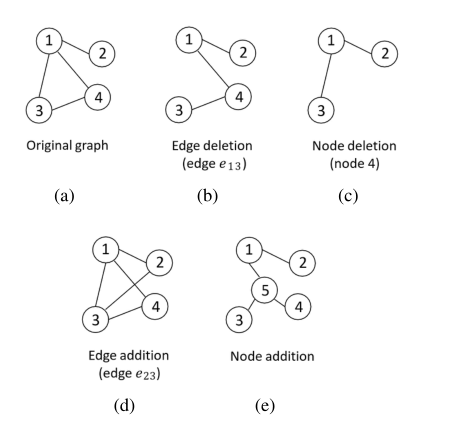
Edge deletion : 随机选择一条边进行删除 ,如图中 (b)
Node deletion: 随机删除一个点,并将与这个点相连的边都进行删除
Edge insertion:随机选择没有直接相连两个点,为它们增加一条边
Node insertion :选择一个连联通的子图,将这个子图中的所有边进行删除,添加一个点后,将所有的点都与添加的点进行连边
如何进行增强?
拿到一个原始图 \(G\), 我们有 \(t\) 个步骤进行增强,在每次进行增强的时候我们都是基于上一次增强的图进行增强,并且每次增强的方式是随机选择四个增强方式中一个增强方式。
如何创建预测任务?
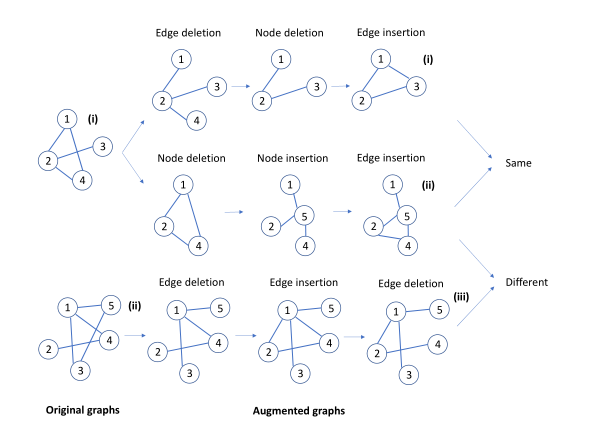
如图,对于两个原始图,我们对于同一个图进行增广,经过一系列增广后得到两个图, 并为这个图打上相似的标签,可以看作正对,然对用另外一个图增广得到的增广图,我们打上 不相似的标签,可以看作负对。
对比损失函数
sim 为余弦相似度,\(\tau\) 为温度参数
并且我们利用 MoCo 优化该对比损失函数。
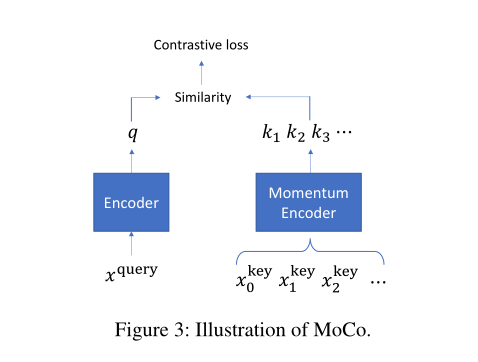
基于与 batch 大小无关的队列。这个队列包含一组动态的扩充图(称为 keys)。在每次迭代中,最新的小批图被添加到队列中;同时,最老的 minibatch 将从队列中删除。通过这种方式,队列与 batch 大小解耦。上图显示了 MoCo 的架构。这些 keys 是用动量编码器编码的。给定当前 minibatch 中的一个扩充图(称为查询)和队列中的一个 key,如果它们来自同一个图,则认为它们是正数对,否则认为它们是负数对。在查询的编码和每个键的编码之间计算一个相似度评分。对比损耗是根据相似度和二进制标号定义的。
CSSL-pretrain
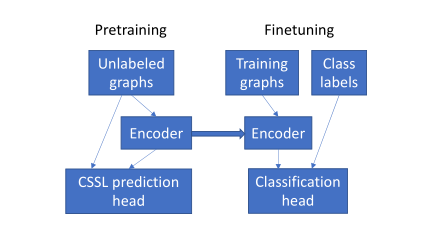
预训练是在无标签的情况下训练编码器, 微调是在有真实标签下微调图编码器。
微调: 保留隐层中的参数,然后根据实际的训练的数据进调整输出层。
实验
\(5\) 个图分类的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号