预训练-Graph Contrastive Learning with Augmentations
预训练-Graph Contrastive Learning with Augmentations
标签:预训练、图神经网络
动机
- 对于特定任务的标签可能非常稀缺,利用图神经网络训练出来的结果用于进行下游任务时不是很好
- 真实世界的图数据往往是巨大的,即使是基准数据集也变得越来越大
- 针对用于下游任务的图神经网络像 GAE 和 graphSAGE 等重构顶点邻域有时候并以是很好,因为过分强调了邻域信息可能还会造成图结构信息改变,所以我们需要设计何理的预训练框架来扑获图结构数据中的高度异构信息
贡献
- 由于数据增强是对比性学习的前提,但在图数据中探索不足,首先设计了四种类型的图数据增强,每一种对于先前图数据都有所增强,并并对成都和模型进行了参数化
- 利用不同的增强手段提出一种新的用于 GNN 预训练的图对比学习框架,证明了GraphCL实际上实现了互信息最大化,并将 GraphCL 与最近提出的对比学习方法联系起来,证明了 GraphCL 可以被重写为一个统一于图结构数据上的一大类对比学习方法的通用框架
- 对不同类型数据集的不同扩展进行了系统的性能评估,揭示了性能的基本原理,并为具体数据集采用该框架提供了指导。
- 实验表明,GraphCL 在半监督学习、无监督表示学习和迁移学习的环境下都取得了最好的性能。此外,它还增强了抵御常见对手攻击的健壮性。
前置知识
图数据增强: 传统的自训练方法利用训练好的模型来标注未标注的数据,或者在对抗性学习中下训练生成器-分类器网络来生成虚假的节点以及在图结构上对节点特征产生对抗性扰动
对比学习 : 对比学习的主要思想是在适当的变换下使表征彼此一致,从而引起了最近视觉表征学习的热潮。另一方面,对于图数据,试图重建顶点的邻接信息的传统方法可以被视为一种“局部对比”,而过度强调邻接信息而忽视结构信息。之后提出在局部表示和全局表示之间进行对比学习,以更好地捕捉结构信息。然而,图的对比学习并没有像那样从强制扰动不变性的角度进行探索。
核心思想
图数据增强( Graph data augmentation)
数据扩充是在不影响语义标签的情况下,通过一定的变换产生新颖、逼真的合理数据,我们重点放在图级别的扩充,在原图 \(G\) 的基础上扩充成一个增广图 \(\hat{G}\) ,其中增广图在预定义原图的条件下的服从扩充分布
节点丢失(Node dropping): 在给定图 \(G\) 的情况下,节点丢弃将随机丢弃某些部分顶点及其链接,每个节点丢弃的概率服从独立同分布的均匀分布
边扰动(Edge prtturbation) : 随机增加或删除一定比例的边来扰动图 \(G\) 的连贯性,每个边的增加或者删除的概率服从独立同分布的均匀分布
属性掩蔽(Attribute masking) : 随机掩蔽图终顶点属性,通过上下文信息(剩下的属性)重构被掩蔽的顶点的属性
子图划分(subgraph): 使用随机游走对 \(G\) 进行采样得到一个子图
基于 GNN 的编码器(GNN-based encoder )
通过上式将增广图 \(\hat{G}\) 输出成图的embedding
投影头(Projection head)
一种名为投影头的非线性变换 \(g(·)\) 将扩充到表示映射到另一个潜在空间,在哪里计算对比损失,在图对比学习中,使用两层感知机 (MLP) 获得 \(z_i、z_j\)
对比损失函数(Contrastive loss function)
使得与负样本对相比正样本对之间的一致性最大化(这里是指的两种数据增强方式之间的一致性)
\(l_n = -log\frac{exp(sim(z_{n, i}, z_{n, j})/\tau)}{\sum_{n' = 1, n'≠n}^N exp(sim(z_{n, i}, z_{n, j})/\tau)}\)
实验结果
首先实验是否以及何时应用数据扩充总体上有助于图对比学习,使用从头开始训练相比的精度增益进行总结
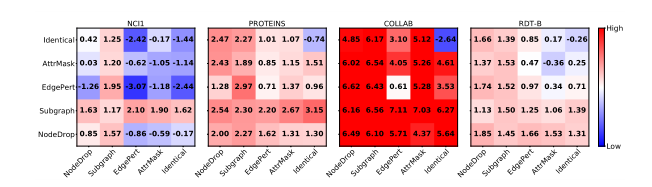
颜色越深表示提升越大
结论
- 右上角的精度损失来看,在没有任何数据增强图的情况下,对比学习是没有帮助的,而且往往比从头开始训练更差。相比之下,组成原始图并对其进行适当的增强可以提高下游的性能。
- 单一最佳增强的图形对比学习在没有穷尽的超参数调整的情况下获得了相当大的改善:NCI1为1.62%,PROTEINS 为3.15%,Collab为6.27%,RDT-B为1.66%,这种观察符合我们的直觉。在没有扩充的情况下,GraphCL 只是将两个原始样本作为负对进行比较(正对损失变为零),导致同质地将所有图表示彼此推开,这是不直观的。重要的是,当应用适当的扩充时,关于数据分布的对应先验被灌输,强制模型通过最大化图与其扩充之间的一致性来学习不随期望的扰动而变化的表示
- 组合不同的增强方式效果更好
针对不同的图数据实验分析
- 边缘扰动有益于社交网络,但会伤害一些生化分子图。这取决于边的重要程度
- 应用属性屏蔽可在更密集的图中实现更好的性能
- 节点删除和子图通常对图数据集有益。节点删除在丢失某些顶点不会更改语义信息的先验条件下直观的迎合了我们的认知。子图刻意增强局部(即子图)和全局信息的一致性有助于表示学习。
- 对于过于简单的图学习任务,对比学习的效果不显著。



