预训练-STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORK
STRATEGIES FOR PRE-TRAINING GRAPH NEURAL NETWORK
标签: 预训练、图神经网络
动机
- 在特定任务中,标签数据极其缺失,这个问题在重要的科学领域的图表数据集中更加严重,例如化学和生物,并且数据标签化是资源和时间密集型的
- 来自真实事件通常包含分布外的样本,这意味着训练集与测试集中的图形在结构上有很大差异
贡献
-
首次对 GNN 的训练前策略进行了系统的大规模调查。为此,建立了两个信的大型预训练数据集
-
提出一种有效的神经网络预训练策略,并对其有效性和对硬迁移学习问题的非分布泛化能力进行了验证
核心思想
核心思想是添加用易于得到的节点级别的信息,使得 GNN 捕获关于节点和边的邻域特定知识,以及图级别的特定领域知识,这有助于 GNN 在全局和局部级别学习有用的表示,并且对于能够生成健壮且可转移到不同下游任务的图级表示
图神经网络预训练策略
节点级预训练
上下文预测(CONTEXT PREDICTION) - 利用图结构的分布
在上下文预测中,我们利用子图去预测他们周围的图结构,目标是预训练一个 GNN, 以便它将具有相似周围结构的节点映射到距离相近的嵌入
Neighborhood and context graphs
对于节点 \(v\) , 它的邻居和上下文如下:
k-hop beighborhood : \(v\) 的 \(k\) 跳邻域包含图中距离 \(v\) 最多 \(k\) 跳的所有节点和边, \(k\) 层的 GNN 的节点的 embedding \(h_v^k\) 相当于节点 \(k\) 阶邻居聚合
context graph : 节点 \(v\) 的周围的邻居节点所连接的子图,由两个超参决定 \(r_1\) 和 \(r_2\), 其实也就是距离在 \([r_1, r_2]\) 范围内的节点, 这些节点提供了邻居和 context graph 是如何相连的
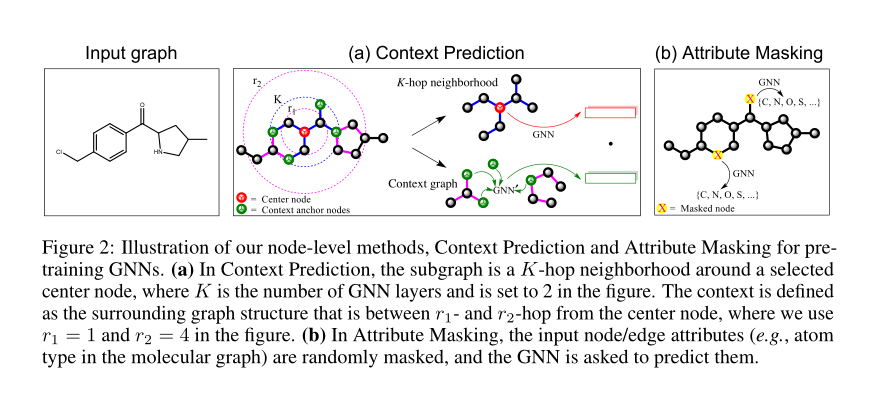
Encoding context into a fixed vector using an auxiliary GNN
使用辅助 GNN 将上下文编码成一个固定的向量。我们首先应用上下文 GNN 去获得节点嵌入,然后对上下文锚节点(context anchor nodes) 的嵌入进行平均化, 得到一个固定长度的上下文嵌入,对于图中的每个节点 \(v\) , 我们定义上下文节点嵌入为 \(c_v^ G\)
Learning via negative sampling
使用负采样联合学习 main GNN 和 context GNN , main GNN 对邻域编码获得 embedding , context GNN 编码上下文图过的上下文 embedding , 并且,Context Prediction 的目标是一个对于特定的邻域和上下文图是否属于同一个节点的二分类。所使用的负采样率为1(每1个正样本中就有1个负样本),并使用负对数似然作为损失函数。经过预训练后,保留main GNN作为预训练模型。
\(\sigma(·)\) 为 sigmoid 函数, \(1(·)\) 为指示函数
Masking node and edges attributes
首先对节点和边的属性进行掩码,然后让 GNN 根据邻域结构进行预测属性,例如, 对于分子图,使用特殊的标记来 mask 掉这些属性,然后使用 GNN 得到相应的节点和边的 embeddings ,最后用线性模型来预测被 mask 掉的节点和边的属性。
图级别的预训练
我们的目标是预先训练神经网络生成有用的图嵌入,使得该嵌入在下游任务之间更具有健壮性
SUPERVISED GRAPH-LEVEL PROPERTY PREDICTION(有监督的图级别的属性预测)
使用图级别的多任务的有监督预训练,联合预测一个图的多个标签。为了共同预测许多图的属性,其中每个属性对应于一个二分类任务,在图表示的基础上应用线性分类器。
STRUCTURAL SIMILARITY PREDICTION(结构相似度预测)
建模两个图间结构的相似性。类似的任务有:建模图的编辑距离、预测图结构的相似性。作者认为这个方法超出了本文的范围,将其作为未来的工作。
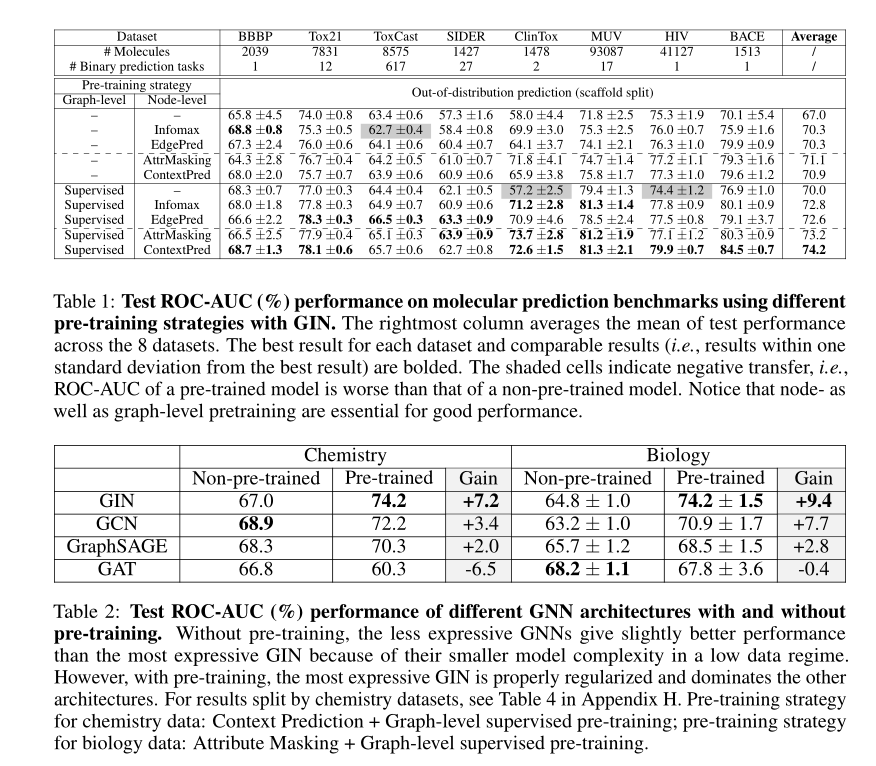
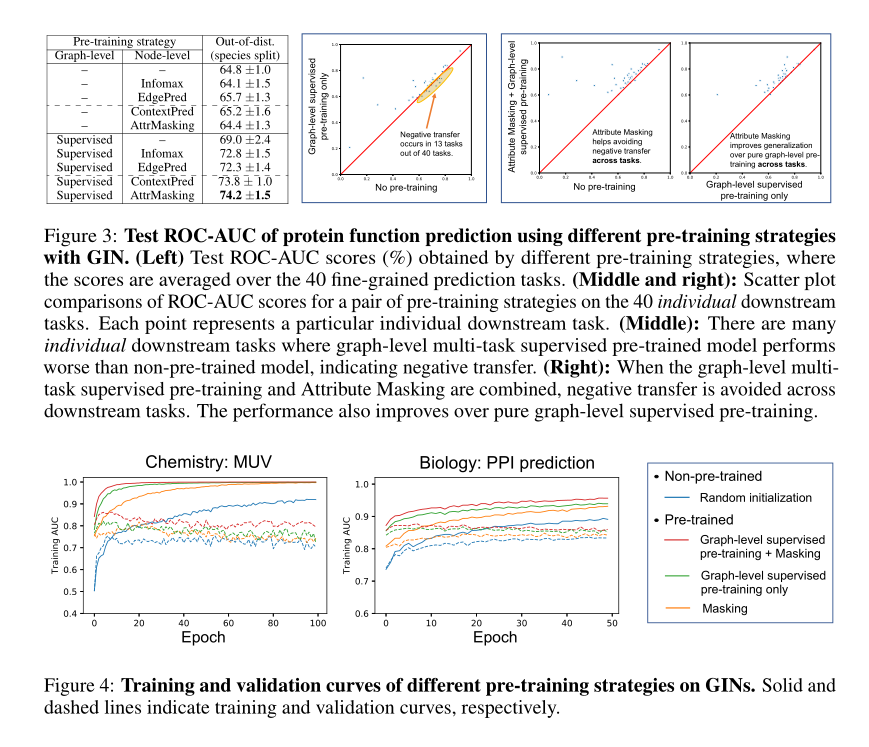
结果