算法复现,密码进阶
HEX编码
hex编码就是将字符转为ASCII码之后进行hex转码,将一个字节的高四位转成一个hex数据,再将低四位转成一个hex数据
比如‘x’----->ASCII对应120------>二进制对应1101 0001------>高四位转为D 低四位转为1 ------->得到D1
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 将ByteString转换为十六进制字符串表示
char* hex(const unsigned char* byteArray, size_t length) {
// 每个字节对应2个十六进制字符,加上末尾的空字符
char* hexString = (char*)malloc((length * 2 + 1) * sizeof(char));
if (hexString == NULL) {
printf("内存分配失败\n");
exit(1); // 退出程序,避免后续错误
}
// 遍历字节数组,将每个字节转换为十六进制字符串
for (size_t i = 0; i < length; i++) {
sprintf(&hexString[i * 2], "%02x", byteArray[i]);
}
// 确保字符串以空字符结束
hexString[length * 2] = '\0';
return hexString;
}
int main() {
// 示例字节数组
unsigned char byteArray[] = {0x12, 0xA3, 0xFF, 0x5C, 0x00, 0x1E};
size_t length = sizeof(byteArray) / sizeof(byteArray[0]);
// 调用hex()函数并输出结果
char* hexStr = hex(byteArray, length);
printf("十六进制表示: %s\n", hexStr);
// 释放动态分配的内存
free(hexStr);
return 0;
}
所以其实可以看到的是一个字符转hex需要两个十六进制数来接收,这也就是为什么申请的数组要是hexString[i * 2]
MD5算法加密
数据处理:
- 对明文进行 Hex 编码
xiaojianbang ==> 78 69 61 6f 6a 69 61 6e 62 61 6e 67
- 填充:
2.1 把明文填充到 448bit,**先填充(二进制)一个 1 ,后面跟对应个数的 0 **
比如要填充到448bit,就应该填充plaintext+padding=448bit padding=1000 0000 0000..........=(十六进制)80 00 00 00
2.2 附加消息长度
-
用 64bit 表示消息长度(总合正好是512bit)
-
00 00 00 00 00 00 00 18 转小端序 18 00 00 00 00 00 00 00 上面的字节数是24---->十六进制18
-
如果内容过长, 64 个比特放不下。就取低 64bit 。所以 MD5 输入长度可以无限大, SHA3 算法也是无限大,其他哈希算法不是
明文最后处理成————>78 69 61 6f 6a 69 61 6e 62 61 6e 67 80 ...... 18 00 00 00 00 00 00 00 -
MD5 输入数据无限大,不可能一起处理,需要分组
-
MD5 分组长度为 512bit ,数据需要处理到 512 的倍数,因此需要填充填充位数为 1-512bit ,如果明文长度刚好 448bit ,那么就填充 512bit
-
字节序
大端字节序、小端字节序、字节序的转换
什么时候需要转换字节序
MD5 算法使用的是小端字节
把处理后的明文分成 16 块 M1-M16(这里的分组过程中需要进行字节转换,大转小) ,用于后续计算 512bit / 16 = 32bit
MD5初始化常量:
MD5 的初始化常量
A: 01 23 45 67 //因为是小端序且内存里面的结果要是这样的,所以才需要像下面那样进行常量的存储
B: 89 ab cd ef
C: fe dc ba 98
D: 76 54 32 10
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
加密过程:
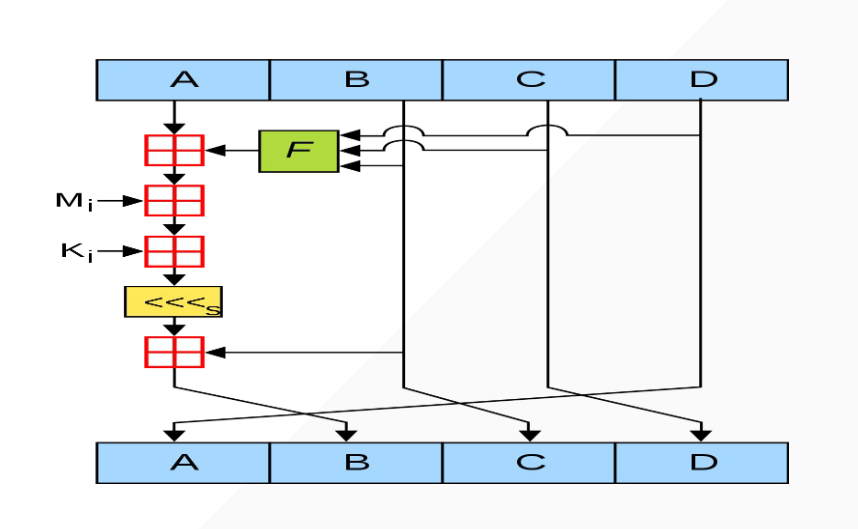
\image-20240914144853731.png)
- MD5 总共 64 轮,每一轮都会把旧的 D 直接给新的 A ,旧的 B 直接给新的 C ,旧的 C 直接
给新的 D ,也就是每一轮只计算一个新的 B
- 图中的田代表相加,这样的相加方式,F为一个函数需要传入b,c,d三个参数,x是明文的M1-M16直接的一个M,s是循环左移的轮数,ac为key常量表里面的值
#define FF(a,b,c,d,x,s,ac) \
{ \
a += F(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
- 图中的 F 函数并不是一个函数,而是由四个函数组成以下就是四个函数的实现过程,全是位运算
#define F(x,y,z) ((x & y) | (~x & z))
#define G(x,y,z) ((x & z) | (y & ~z))
#define H(x,y,z) (x^y^z)
#define I(x,y,z) (y ^ (x | ~z))
-
K 表里面的值由公式计算的,但体现在代码中一般都是常量
-
<<<s 代表循环左移,什么是循环左移?
-
最后把四个初始化常量不断变化后的值,拼接得到最终的摘要结果
代码实现:CPP
//
// Created by Administrator on 2021-07-28.
//
#include <iostream>
#include <memory.h>
#include "md5.h"
#include "string.h"
using namespace std;
unsigned char PADDING[] = { 0x80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };
void MD5Init(MD5_CTX* context) {
context->count[0] = 0;
context->count[1] = 0;
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
}
void MD5Update(MD5_CTX* context, unsigned char* input, unsigned int inputlen) {
unsigned int i = 0, index = 0, partlen = 0;
index = (context->count[0] >> 3) & 0x3F;//确保结果在0到63之间(缓冲区大小为64字节)。
partlen = 64 - index;
context->count[0] += inputlen << 3;//cont[0]存的bit位数
if (context->count[0] < (inputlen << 3))//假如低位的bit小于inputlen,就要去增加高位的bit位了
context->count[1]++;
context->count[1] += inputlen >> 29;
if (inputlen >= partlen) {//假如够64字节了
memcpy(&context->buffer[index], input, partlen);
MD5Transform(context->state, context->buffer);
for (i = partlen; i + 64 <= inputlen; i += 64)
MD5Transform(context->state, &input[i]);//处理剩下的input
index = 0;
}
else {
i = 0;
}
memcpy(&context->buffer[index], &input[i], inputlen - i);
}
void MD5Final(MD5_CTX* context, unsigned char digest[16]) {
unsigned int index = 0, padlen = 0;
unsigned char bits[8];
index = (context->count[0] >> 3) & 0x3F;
padlen = (index < 56) ? (56 - index) : (120 - index);
MD5Encode(bits, context->count, 8);//小端序
MD5Update(context, PADDING, padlen);//填充padding
MD5Update(context, bits, 8);//填充消息长度
MD5Encode(digest, context->state, 16);//把结果再一次进行字节转换给digetst得到结果
}
void MD5Encode(unsigned char* output, unsigned int* input, unsigned int len) {
unsigned int i = 0, j = 0;
while (j < len) {
output[j] = input[i] & 0xFF;
output[j + 1] = (input[i] >> 8) & 0xFF;
output[j + 2] = (input[i] >> 16) & 0xFF;
output[j + 3] = (input[i] >> 24) & 0xFF;
i++;
j += 4;
}
}
void MD5Decode(unsigned int* output, unsigned char* input, unsigned int len) {
unsigned int i = 0, j = 0;
while (j < len) {
output[i] = (input[j]) |
(input[j + 1] << 8) |
(input[j + 2] << 16) |
(input[j + 3] << 24);
i++;
j += 4;
}
}
void MD5Transform(unsigned int state[4], unsigned char block[64]) {
unsigned int a = state[0];
unsigned int b = state[1];
unsigned int c = state[2];
unsigned int d = state[3];
unsigned int x[64];
MD5Decode(x, block, 64);
FF(a, b, c, d, x[0], 7, 0xd76aa478); /* 1 */
FF(d, a, b, c, x[1], 12, 0xe8c7b756); /* 2 */
FF(c, d, a, b, x[2], 17, 0x242070db); /* 3 */
FF(b, c, d, a, x[3], 22, 0xc1bdceee); /* 4 */
FF(a, b, c, d, x[4], 7, 0xf57c0faf); /* 5 */
FF(d, a, b, c, x[5], 12, 0x4787c62a); /* 6 */
FF(c, d, a, b, x[6], 17, 0xa8304613); /* 7 */
FF(b, c, d, a, x[7], 22, 0xfd469501); /* 8 */
FF(a, b, c, d, x[8], 7, 0x698098d8); /* 9 */
FF(d, a, b, c, x[9], 12, 0x8b44f7af); /* 10 */
FF(c, d, a, b, x[10], 17, 0xffff5bb1); /* 11 */
FF(b, c, d, a, x[11], 22, 0x895cd7be); /* 12 */
FF(a, b, c, d, x[12], 7, 0x6b901122); /* 13 */
FF(d, a, b, c, x[13], 12, 0xfd987193); /* 14 */
FF(c, d, a, b, x[14], 17, 0xa679438e); /* 15 */
FF(b, c, d, a, x[15], 22, 0x49b40821); /* 16 */
/* Round 2 */
GG(a, b, c, d, x[1], 5, 0xf61e2562); /* 17 */
GG(d, a, b, c, x[6], 9, 0xc040b340); /* 18 */
GG(c, d, a, b, x[11], 14, 0x265e5a51); /* 19 */
GG(b, c, d, a, x[0], 20, 0xe9b6c7aa); /* 20 */
GG(a, b, c, d, x[5], 5, 0xd62f105d); /* 21 */
GG(d, a, b, c, x[10], 9, 0x2441453); /* 22 */
GG(c, d, a, b, x[15], 14, 0xd8a1e681); /* 23 */
GG(b, c, d, a, x[4], 20, 0xe7d3fbc8); /* 24 */
GG(a, b, c, d, x[9], 5, 0x21e1cde6); /* 25 */
GG(d, a, b, c, x[14], 9, 0xc33707d6); /* 26 */
GG(c, d, a, b, x[3], 14, 0xf4d50d87); /* 27 */
GG(b, c, d, a, x[8], 20, 0x455a14ed); /* 28 */
GG(a, b, c, d, x[13], 5, 0xa9e3e905); /* 29 */
GG(d, a, b, c, x[2], 9, 0xfcefa3f8); /* 30 */
GG(c, d, a, b, x[7], 14, 0x676f02d9); /* 31 */
GG(b, c, d, a, x[12], 20, 0x8d2a4c8a); /* 32 */
/* Round 3 */
HH(a, b, c, d, x[5], 4, 0xfffa3942); /* 33 */
HH(d, a, b, c, x[8], 11, 0x8771f681); /* 34 */
HH(c, d, a, b, x[11], 16, 0x6d9d6122); /* 35 */
HH(b, c, d, a, x[14], 23, 0xfde5380c); /* 36 */
HH(a, b, c, d, x[1], 4, 0xa4beea44); /* 37 */
HH(d, a, b, c, x[4], 11, 0x4bdecfa9); /* 38 */
HH(c, d, a, b, x[7], 16, 0xf6bb4b60); /* 39 */
HH(b, c, d, a, x[10], 23, 0xbebfbc70); /* 40 */
HH(a, b, c, d, x[13], 4, 0x289b7ec6); /* 41 */
HH(d, a, b, c, x[0], 11, 0xeaa127fa); /* 42 */
HH(c, d, a, b, x[3], 16, 0xd4ef3085); /* 43 */
HH(b, c, d, a, x[6], 23, 0x4881d05); /* 44 */
HH(a, b, c, d, x[9], 4, 0xd9d4d039); /* 45 */
HH(d, a, b, c, x[12], 11, 0xe6db99e5); /* 46 */
HH(c, d, a, b, x[15], 16, 0x1fa27cf8); /* 47 */
HH(b, c, d, a, x[2], 23, 0xc4ac5665); /* 48 */
/* Round 4 */
II(a, b, c, d, x[0], 6, 0xf4292244); /* 49 */
II(d, a, b, c, x[7], 10, 0x432aff97); /* 50 */
II(c, d, a, b, x[14], 15, 0xab9423a7); /* 51 */
II(b, c, d, a, x[5], 21, 0xfc93a039); /* 52 */
II(a, b, c, d, x[12], 6, 0x655b59c3); /* 53 */
II(d, a, b, c, x[3], 10, 0x8f0ccc92); /* 54 */
II(c, d, a, b, x[10], 15, 0xffeff47d); /* 55 */
II(b, c, d, a, x[1], 21, 0x85845dd1); /* 56 */
II(a, b, c, d, x[8], 6, 0x6fa87e4f); /* 57 */
II(d, a, b, c, x[15], 10, 0xfe2ce6e0); /* 58 */
II(c, d, a, b, x[6], 15, 0xa3014314); /* 59 */
II(b, c, d, a, x[13], 21, 0x4e0811a1); /* 60 */
II(a, b, c, d, x[4], 6, 0xf7537e82); /* 61 */
II(d, a, b, c, x[11], 10, 0xbd3af235); /* 62 */
II(c, d, a, b, x[2], 15, 0x2ad7d2bb); /* 63 */
II(b, c, d, a, x[9], 21, 0xeb86d391); /* 64 */
state[0] += a;
state[1] += b;
state[2] += c;
state[3] += d;
}
// void MD5Init(MD5_CTX* context);
// void MD5Update(MD5_CTX* context, unsigned char* input, unsigned int inputlen);
// void MD5Final(MD5_CTX* context, unsigned char digest[16]);
int main()
{
unsigned char* plainText = (unsigned char*)"(a12345678)";
MD5_CTX context;
MD5Init(&context);//初始化context
MD5Update(&context, plainText, strlen((const char*)plainText));//压入plaintext
unsigned char result[16];
MD5Final(&context, result);
char temp[2] = { 0 };
char finalResult[33] = { 0 };
for (int i = 0; i < 16; i++)
{
int index = i;
sprintf(temp, "%.2x", result[index]);
strcat(finalResult, temp);
}
cout << finalResult << endl;
}
MD5.h
#pragma once
//
// Created by Administrator on 2021-07-28.
//
#ifndef HOOKDEMO_MD5_H
#define HOOKDEMO_MD5_H
typedef struct
{
unsigned int count[2];
unsigned int state[4];
unsigned char buffer[64];
} MD5_CTX;
#define F(x,y,z) ((x & y) | (~x & z))
#define G(x,y,z) ((x & z) | (y & ~z))
#define H(x,y,z) (x^y^z)
#define I(x,y,z) (y ^ (x | ~z))
#define ROTATE_LEFT(x,n) ((x << n) | (x >> (32-n)))
#define FF(a,b,c,d,x,s,ac) \
{ \
a += F(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define GG(a,b,c,d,x,s,ac) \
{ \
a += G(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define HH(a,b,c,d,x,s,ac) \
{ \
a += H(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
#define II(a,b,c,d,x,s,ac) \
{ \
a += I(b,c,d) + x + ac; \
a = ROTATE_LEFT(a,s); \
a += b; \
}
void MD5Init(MD5_CTX* context);
void MD5Update(MD5_CTX* context, unsigned char* input, unsigned int inputlen);
void MD5Final(MD5_CTX* context, unsigned char digest[16]);
void MD5Transform(unsigned int state[4], unsigned char block[64]);
void MD5Encode(unsigned char* output, unsigned int* input, unsigned int len);
void MD5Decode(unsigned int* output, unsigned char* input, unsigned int len);
#endif //HOOKDEMO_MD5_H
初始化context:
void MD5Init(MD5_CTX* context) {
context->count[0] = 0;
context->count[1] = 0;
context->state[0] = 0x67452301;
context->state[1] = 0xEFCDAB89;
context->state[2] = 0x98BADCFE;
context->state[3] = 0x10325476;
}
UPdate:
void MD5Update(MD5_CTX* context, unsigned char* input, unsigned int inputlen) {
unsigned int i = 0, index = 0, partlen = 0;
index = (context->count[0] >> 3) & 0x3F;//确保结果在0到63之间(缓冲区大小为64字节)。
partlen = 64 - index;
context->count[0] += inputlen << 3;//cont[0]存的bit位数
if (context->count[0] < (inputlen << 3))//假如低位的bit小于inputlen,就要去增加高位的bit位了
context->count[1]++;
context->count[1] += inputlen >> 29;
if (inputlen >= partlen) {//假如够64字节了
memcpy(&context->buffer[index], input, partlen);
MD5Transform(context->state, context->buffer);//加密函数
for (i = partlen; i + 64 <= inputlen; i += 64)
MD5Transform(context->state, &input[i]);//处理剩下的input
index = 0;
}
else {
i = 0;
}
memcpy(&context->buffer[index], &input[i], inputlen - i);
}
IDA查看UPdate,静态分析:
int __fastcall MD5_Update(Context *context, char *input, size_t inputlen)
{
size_t len; // r4
unsigned int count0; // r2
int v7; // r3
unsigned int count1; // r1
unsigned int v9; // r0
int v10; // r1
unsigned int *state; // r7
bool v12; // cf
int v13; // r6
size_t v14; // r6
len = inputlen;
if ( inputlen )// 判断输入的长度是否为0
{
count0 = context->count[0];
v7 = 0;
count1 = context->count[1];
v9 = count0 + 8 * len; // Byte_to_bit
if ( v9 < count0 ) // 假如count0加上了len的bit都小于了count0,说明溢出了
v7 = 1;//高位就++
if ( v7 )
context->count[1] = ++count1;
context->count[0] = v9;
context->count[1] = count1 + (len >> 29);// 高位的进位累加
v10 = *&context->buffer[48]; // 已经填充的数目
if ( v10 )
{
state = context->state;
v12 = len >= 63;
if ( len <= 63 )
v12 = v10 + len >= 64;
if ( !v12 )
{
qmemcpy(state + v10, input, len);// 将输入数据拷贝到缓冲区
*&context->buffer[48] += len; // 更新缓冲区计数器
return 1;
}
v13 = 64 - v10;
qmemcpy(state + v10, input, 64 - v10); // 将缓冲区补满64字节
md5_Transform(context, context->state, 1);
memset(context->state, 0, 68u); // 清空缓冲区
len -= v13; // 更新剩余长度
input += v13;// 更新输入指针
}
if ( len >> 6 )// 如果剩余的数据长度 >= 64 字节
{
v14 = len >> 6;
md5_Transform(context, input, len >> 6);// 处理所有完整的64字节块
len -= len >> 6 << 6;// 更新剩余长度
input += 64 * v14;// 移动输入指针
}
if ( len )// 如果还有剩余不足64字节的数据
{
*&context->buffer[48] = len;// 更新缓冲区中未处理数据的长度
qmemcpy(context->state, input, len);// 将剩余的数据复制到缓冲区
}
}
return 1;
}
这里进行了字节转换之后直接就进行函数加密了
void MD5Transform(unsigned int state[4], unsigned char block[64]) {
unsigned int a = state[0];
unsigned int b = state[1];
unsigned int c = state[2];
unsigned int d = state[3];
unsigned int x[64];
MD5Decode(x, block, 64);//这里去进行了M1-M16的分组,以及对应分组之后的字节转换
函数的进一步填充
void MD5Final(MD5_CTX* context, unsigned char digest[16]) {
unsigned int index = 0, padlen = 0;
unsigned char bits[8];
index = (context->count[0] >> 3) & 0x3F;
padlen = (index < 56) ? (56 - index) : (120 - index);
MD5Encode(bits, context->count, 8);//小端序
MD5Update(context, PADDING, padlen);//填充padding
MD5Update(context, bits, 8);//填充消息长度
MD5Encode(digest, context->state, 16);//把结果再一次进行字节转换给digetst得到结果
}
字节转换
void MD5Decode(unsigned int* output, unsigned char* input, unsigned int len) {
unsigned int i = 0, j = 0;
while (j < len) {
output[i] = (input[j]) |
(input[j + 1] << 8) |
(input[j + 2] << 16) |
(input[j + 3] << 24);
i++;
j += 4;
}
}
input[j]:取字节的低8位,直接作为整数的最低字节。
input[j + 1] << 8:将第二个字节左移8位,作为整数的第二字节。
input[j + 2] << 16:将第三个字节左移16位,作为整数的第三字节。
input[j + 3] << 24:将第四个字节左移24位,作为整数的最高字节。
SHA1
- SHA1 算法的初始化常量有 5 个,其中前四个与 MD5 一致(所以MD5的输出是16个字节,而SHA1是20个字节)
- SHA1 算法对于明文的处理与 MD5 相同,区别是最后的消息长度是大端字节序(MD5是小端字节序)
https://blog.csdn.net/u012308586/article/details/96113806
- SHA1 的分组长度也是 512bit ,明文也要分段,类似 Mi ,区别是有 80 段,后 64 段是扩展出
来的,遵循大端字节序(MD5是64轮)
- SHA1 与 SHA0 的区别就是在扩展这 64 段的时候,增加了循环左移 1 位
W[t] = SHA1CircularShift(1, W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16]);
- SHA1 的核心计算过程与 MD5 差不多,区别是 K 值只有 4 个,每 20 轮用一个,总共 80 轮(MD5的key是一个数组)
- SHA1 最后计算的结果也是大端序
- SHA1 算法的源码分析
SHA1.cpp
/*
* sha1.c
*
* Description:
* This file implements the Secure Hashing Algorithm 1 as
* defined in FIPS PUB 180-1 published April 17, 1995.
*
* The SHA-1, produces a 160-bit message digest for a given
* data stream. It should take about 2**n steps to find a
* message with the same digest as a given message and
* 2**(n/2) to find any two messages with the same digest,
* when n is the digest size in bits. Therefore, this
* algorithm can serve as a means of providing a
* "fingerprint" for a message.
*
* Portability Issues:
* SHA-1 is defined in terms of 32-bit "words". This code
* uses <stdint.h> (included via "sha1.h" to define 32 and 8
* bit unsigned integer types. If your C compiler does not
* support 32 bit unsigned integers, this code is not
* appropriate.
*
* Caveats:
* SHA-1 is designed to work with messages less than 2^64 bits
* long. Although SHA-1 allows a message digest to be generated
* for messages of any number of bits less than 2^64, this
* implementation only works with messages with a length that is
* a multiple of the size of an 8-bit character.
*
*/
#include <stdio.h>
#include "SHA1.h"
#include <string.h>
#ifdef __cplusplus
extern "C"
{
#endif
/*
* Define the SHA1 circular left shift macro
*/
#define SHA1CircularShift(bits, word) \
(((word) << (bits)) | ((word) >> (32-(bits))))
/* Local Function Prototyptes */
void SHA1PadMessage(SHA1Context *);
void SHA1ProcessMessageBlock(SHA1Context *);
/*
* SHA1Reset
*
* Description:
* This function will initialize the SHA1Context in preparation
* for computing a new SHA1 message digest.
*
* Parameters:
* context: [in/out]
* The context to reset.
*
* Returns:
* sha Error Code.
*
*/
int SHA1Reset(SHA1Context *context)//初始化状态
{
if (!context) {
return shaNull;
}
context->Length_Low = 0;
context->Length_High = 0;
context->Message_Block_Index = 0;
context->Intermediate_Hash[0] = 0x67452301;//取得的HASH结果(中间数据)
context->Intermediate_Hash[1] = 0xEFCDAB89;
context->Intermediate_Hash[2] = 0x98BADCFE;
context->Intermediate_Hash[3] = 0x10325476;
context->Intermediate_Hash[4] = 0xC3D2E1F0;
context->Computed = 0;
context->Corrupted = 0;
return shaSuccess;
}
/*
* SHA1Result
*
* Description:
* This function will return the 160-bit message digest into the
* Message_Digest array provided by the caller.
* NOTE: The first octet of hash is stored in the 0th element,
* the last octet of hash in the 19th element.
*
* Parameters:
* context: [in/out]
* The context to use to calculate the SHA-1 hash.
* Message_Digest: [out]
* Where the digest is returned.
*
* Returns:
* sha Error Code.
*
*/
int SHA1Result(SHA1Context *context, uint8_t Message_Digest[SHA1HashSize]) {
int i;
if (!context || !Message_Digest) {
return shaNull;
}
if (context->Corrupted) {
return context->Corrupted;
}
if (!context->Computed) {//是否需要计算摘要
SHA1PadMessage(context);//填充和计算的地方
for (i = 0; i < 64; ++i) {
/* message may be sensitive, clear it out */
context->Message_Block[i] = 0;
}
context->Length_Low = 0; /* and clear length */
context->Length_High = 0;
context->Computed = 1;
}
printf("%x\n", context->Intermediate_Hash[0]);
printf("%x\n", context->Intermediate_Hash[1]);
printf("%x\n", context->Intermediate_Hash[2]);
printf("%x\n", context->Intermediate_Hash[3]);
printf("%x\n", context->Intermediate_Hash[4]);
for (i = 0; i < SHA1HashSize; ++i) {
Message_Digest[i] = context->Intermediate_Hash[i >> 2]
>> 8 * (3 - (i & 0x03));
}
return shaSuccess;
}
/*
* SHA1Input
*
* Description:
* This function accepts an array of octets as the next portion
* of the message.
*
* Parameters:
* context: [in/out]
* The SHA context to update
* message_array: [in]
* An array of characters representing the next portion of
* the message.
* length: [in]
* The length of the message in message_array
*
* Returns:
* sha Error Code.
*
*/
int SHA1Input(SHA1Context *context, const uint8_t *message_array, unsigned length) {
if (!length) {
return shaSuccess;
}
if (!context || !message_array) {
return shaNull;
}
if (context->Computed) {
context->Corrupted = shaStateError;
return shaStateError;
}
if (context->Corrupted) {
return context->Corrupted;
}
while (length-- && !context->Corrupted) {
context->Message_Block[context->Message_Block_Index++] =
(*message_array & 0xFF);
context->Length_Low += 8;
if (context->Length_Low == 0) {
context->Length_High++;
if (context->Length_High == 0) {
/* Message is too long */
context->Corrupted = 1;
}
}
if (context->Message_Block_Index == 64) {
SHA1ProcessMessageBlock(context);
}
message_array++;
}
return shaSuccess;
}
/*
* SHA1ProcessMessageBlock
*
* Description:
* This function will process the next 512 bits of the message
* stored in the Message_Block array.
*
* Parameters:
* None.
*
* Returns:
* Nothing.
*
* Comments:
* Many of the variable names in this code, especially the
* single character names, were used because those were the
* names used in the publication.
*
*/
void SHA1ProcessMessageBlock(SHA1Context *context) {
const uint32_t K[] = { /* Constants defined in SHA-1 */
0x5A827999,
0x6ED9EBA1,
0x8F1BBCDC,
0xCA62C1D6
};
int t; /* Loop counter */
uint32_t temp; /* Temporary word value */
uint32_t W[80]; /* Word sequence */
uint32_t A, B, C, D, E; /* Word buffers */
/*
* Initialize the first 16 words in the array W
*/
for (t = 0; t < 16; t++) {
W[t] = context->Message_Block[t * 4] << 24;
W[t] |= context->Message_Block[t * 4 + 1] << 16;
W[t] |= context->Message_Block[t * 4 + 2] << 8;
W[t] |= context->Message_Block[t * 4 + 3];
}
for (t = 16; t < 80; t++) {
W[t] = SHA1CircularShift(1, W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16]);
//W[t] = W[t - 3] ^ W[t - 8] ^ W[t - 14] ^ W[t - 16];SHA0
}
A = context->Intermediate_Hash[0];
B = context->Intermediate_Hash[1];
C = context->Intermediate_Hash[2];
D = context->Intermediate_Hash[3];
E = context->Intermediate_Hash[4];
for (t = 0; t < 20; t++) {
temp = SHA1CircularShift(5, A) +
((B & C) | ((~B) & D)) + E + W[t] + K[0];
E = D;
D = C;
C = SHA1CircularShift(30, B);
B = A;
A = temp;
}
for (t = 20; t < 40; t++) {
temp = SHA1CircularShift(5, A) + (B ^ C ^ D) + E + W[t] + K[1];
E = D;
D = C;
C = SHA1CircularShift(30, B);
B = A;
A = temp;
}
for (t = 40; t < 60; t++) {
temp = SHA1CircularShift(5, A) +
((B & C) | (B & D) | (C & D)) + E + W[t] + K[2];
E = D;
D = C;
C = SHA1CircularShift(30, B);
B = A;
A = temp;
}
for (t = 60; t < 80; t++) {
temp = SHA1CircularShift(5, A) + (B ^ C ^ D) + E + W[t] + K[3];
E = D;
D = C;
C = SHA1CircularShift(30, B);
B = A;
A = temp;
}
context->Intermediate_Hash[0] += A;
context->Intermediate_Hash[1] += B;
context->Intermediate_Hash[2] += C;
context->Intermediate_Hash[3] += D;
context->Intermediate_Hash[4] += E;
context->Message_Block_Index = 0;
}
/*
* SHA1PadMessage
*
* Description:
* According to the standard, the message must be padded to an even
* 512 bits. The first padding bit must be a ’1’. The last 64
* bits represent the length of the original message. All bits in
* between should be 0. This function will pad the message
* according to those rules by filling the Message_Block array
* accordingly. It will also call the ProcessMessageBlock function
* provided appropriately. When it returns, it can be assumed that
* the message digest has been computed.
*
* Parameters:
* context: [in/out]
* The context to pad
* ProcessMessageBlock: [in]
* The appropriate SHA*ProcessMessageBlock function
* Returns:
* Nothing.
*
*/
void SHA1PadMessage(SHA1Context *context) {
/*
* Check to see if the current message block is too small to hold
* the initial padding bits and length. If so, we will pad the
* block, process it, and then continue padding into a second
* block.
*/
if (context->Message_Block_Index > 55) {//大于55小于64填充0x80 00 00 00 00 00 00 00
context->Message_Block[context->Message_Block_Index++] = 0x80;
while (context->Message_Block_Index < 64) {
context->Message_Block[context->Message_Block_Index++] = 0;
}
SHA1ProcessMessageBlock(context);
while (context->Message_Block_Index < 56) {
context->Message_Block[context->Message_Block_Index++] = 0;
}
//先填充一个 0x80。
// 然后填充剩余的 0x00,直到填满 64 字节。
// 调用 SHA1ProcessMessageBlock(context) 处理当前块。
// 再清空块,填充到第 56 字节,留下最后 8 字节用于保存消息长度。
// 如果 Message_Block_Index <= 55,说明可以在当前块内完成填充:
// 填充 0x80。
// 填充 0x00,直到第 56 字节,预留最后 8 字节存储消息长度。
} else {
context->Message_Block[context->Message_Block_Index++] = 0x80;
while (context->Message_Block_Index < 56) {
context->Message_Block[context->Message_Block_Index++] = 0;
}
}
/*
* Store the message length as the last 8 octets
*/
context->Message_Block[56] = context->Length_High >> 24;
context->Message_Block[57] = context->Length_High >> 16;
context->Message_Block[58] = context->Length_High >> 8;
context->Message_Block[59] = context->Length_High;
context->Message_Block[60] = context->Length_Low >> 24;
context->Message_Block[61] = context->Length_Low >> 16;
context->Message_Block[62] = context->Length_Low >> 8;
context->Message_Block[63] = context->Length_Low;
SHA1ProcessMessageBlock(context);
}
#ifdef __cplusplus
}
#endif
int main()
{
SHA1Context context;
SHA1Reset(&context);//初始化SHA1Context
// const uint8_t *message_array
unsigned char *plainText = (unsigned char *)"xiaojianbang";
SHA1Input(&context,plainText,strlen(plainText));//这里直接去将明文进行赋值
unsigned char result[20];
SHA1Result(&context,result);//在这里进行计算操作了
char temp[2]={0};
char finalResult[40] = { 0 };
for (int i = 0; i < 20; i++)
{
int index = i;
sprintf(temp, "%.2x", result[index]);
strcat(finalResult, temp);
}
printf("SHA-1 Hash: %s\n", finalResult);
return 0;
}
sha1.h:
/*
* sha1.h
*
* Description:
* This is the header file for code which implements the Secure
* Hashing Algorithm 1 as defined in FIPS PUB 180-1 published
* April 17, 1995.
*
* Many of the variable names in this code, especially the
* single character names, were used because those were the names
* used in the publication.
*
* Please read the file sha1.c for more information.
*
*/
#ifndef _SHA1_H_
#define _SHA1_H_
#include <stdint.h>
/*
* If you do not have the ISO standard stdint.h header file, then you
* must typdef the following:
* name meaning
* uint32_t unsigned 32 bit integer
* uint8_t unsigned 8 bit integer (i.e., unsigned char)
* int_least16_t integer of >= 16 bits
*
*/
#ifndef _SHA_enum_
#define _SHA_enum_
enum {
shaSuccess = 0,
shaNull, /* Null pointer parameter */
shaInputTooLong, /* input data too long */
shaStateError /* called Input after Result */
};
#endif
#define SHA1HashSize 20
/*
* This structure will hold context information for the SHA-1
* hashing operation
*/
typedef struct SHA1Context {
uint32_t Intermediate_Hash[SHA1HashSize / 4]; /* Message Digest */
uint32_t Length_Low; /* Message length in bits */
uint32_t Length_High; /* Message length in bits */
/* Index into message block array */
int_least16_t Message_Block_Index;
uint8_t Message_Block[64]; /* 512-bit message blocks */
int Computed; /* Is the digest computed? */
int Corrupted; /* Is the message digest corrupted? */
} SHA1Context;
/*
* Function Prototypes
*/
int SHA1Reset(SHA1Context *);
int SHA1Input(SHA1Context *, const uint8_t *, unsigned int);
int SHA1Result(SHA1Context *, uint8_t Message_Digest[SHA1HashSize]);
#endif
SHA256算法
- 初始化常量 8 个
A = 0x6A09E667;
B = 0xBB67AE85;
C = 0x3C6EF372;
D = 0xA54FF53A;
E = 0x510E527F;
F = 0x9B05688C;
G = 0x1F83D9AB;
H = 0x5BE0CD19; - K 表 64 个,每轮 1 个 K 值
K1 = 0x428a2f98
K2 = 0x71374491
K3 = 0xb5c0fbcf
K4 = 0xe9b5dba5 - 输出长度为 32 个字节,或者说 64 个十六进制数
SHA256.h
#ifndef SHA256_H
#define SHA256_H
/*************************** HEADER FILES ***************************/
#include <stddef.h>
/****************************** MACROS ******************************/
#define SHA256_BLOCK_SIZE 32 // SHA256 outputs a 32 byte digest
/**************************** DATA TYPES ****************************/
typedef unsigned char BYTE; // 8-bit byte
typedef unsigned int WORD; // 32-bit word, change to "long" for 16-bit machines
typedef struct {
BYTE data[64]; // current 512-bit chunk of message data, just like a buffer
WORD datalen; // sign the data length of current chunk
unsigned long long bitlen; // the bit length of the total message
WORD state[8]; // store the middle state of hash abstract
} SHA256_CTX;
/*********************** FUNCTION DECLARATIONS **********************/
void sha256_init(SHA256_CTX *ctx);
void sha256_update(SHA256_CTX *ctx, const BYTE data[], size_t len);
void sha256_final(SHA256_CTX *ctx, BYTE hash[]);
#endif // SHA256_H
SHA256.c
/*********************************************************************
* Filename: sha256.c
* Original Author: Brad Conte (brad AT bradconte.com)
* Labeled and modified by: AnSheng(https://github.com/monkeyDemon)
* Copyright:
* Disclaimer: This code is presented "as is" without any guarantees.
* Details: Performs known-answer tests on the corresponding SHA1
implementation. These tests do not encompass the full
range of available test vectors, however, if the tests
pass it is very, very likely that the code is correct
and was compiled properly. This code also serves as
example usage of the functions.
*********************************************************************/
/*************************** HEADER FILES ***************************/
#include <stdlib.h>
#include <memory.h>
#include "sha256.h"
/****************************** MACROS ******************************/
#define ROTLEFT(a,b) (((a) << (b)) | ((a) >> (32-(b))))
#define ROTRIGHT(a,b) (((a) >> (b)) | ((a) << (32-(b))))
#define CH(x,y,z) (((x) & (y)) ^ (~(x) & (z)))
#define MAJ(x,y,z) (((x) & (y)) ^ ((x) & (z)) ^ ((y) & (z)))
#define EP0(x) (ROTRIGHT(x,2) ^ ROTRIGHT(x,13) ^ ROTRIGHT(x,22))
#define EP1(x) (ROTRIGHT(x,6) ^ ROTRIGHT(x,11) ^ ROTRIGHT(x,25))
#define SIG0(x) (ROTRIGHT(x,7) ^ ROTRIGHT(x,18) ^ ((x) >> 3))
#define SIG1(x) (ROTRIGHT(x,17) ^ ROTRIGHT(x,19) ^ ((x) >> 10))
/**************************** VARIABLES *****************************/
static const WORD k[64] = {
0x428a2f98,0x71374491,0xb5c0fbcf,0xe9b5dba5,0x3956c25b,0x59f111f1,0x923f82a4,0xab1c5ed5,
0xd807aa98,0x12835b01,0x243185be,0x550c7dc3,0x72be5d74,0x80deb1fe,0x9bdc06a7,0xc19bf174,
0xe49b69c1,0xefbe4786,0x0fc19dc6,0x240ca1cc,0x2de92c6f,0x4a7484aa,0x5cb0a9dc,0x76f988da,
0x983e5152,0xa831c66d,0xb00327c8,0xbf597fc7,0xc6e00bf3,0xd5a79147,0x06ca6351,0x14292967,
0x27b70a85,0x2e1b2138,0x4d2c6dfc,0x53380d13,0x650a7354,0x766a0abb,0x81c2c92e,0x92722c85,
0xa2bfe8a1,0xa81a664b,0xc24b8b70,0xc76c51a3,0xd192e819,0xd6990624,0xf40e3585,0x106aa070,
0x19a4c116,0x1e376c08,0x2748774c,0x34b0bcb5,0x391c0cb3,0x4ed8aa4a,0x5b9cca4f,0x682e6ff3,
0x748f82ee,0x78a5636f,0x84c87814,0x8cc70208,0x90befffa,0xa4506ceb,0xbef9a3f7,0xc67178f2
};
/*********************** FUNCTION DEFINITIONS ***********************/
void sha256_transform(SHA256_CTX *ctx, const BYTE data[])
{
WORD a, b, c, d, e, f, g, h, i, j, t1, t2, m[64];
// initialization 因为是64轮加密,所以需要先得到64个m[i]数组
for (i = 0, j = 0; i < 16; ++i, j += 4)
m[i] = (data[j] << 24) | (data[j + 1] << 16) | (data[j + 2] << 8) | (data[j + 3]);
for ( ; i < 64; ++i)
m[i] = SIG1(m[i - 2]) + m[i - 7] + SIG0(m[i - 15]) + m[i - 16];
a = ctx->state[0];
b = ctx->state[1];
c = ctx->state[2];
d = ctx->state[3];
e = ctx->state[4];
f = ctx->state[5];
g = ctx->state[6];
h = ctx->state[7];
for (i = 0; i < 64; ++i) {
t1 = h + EP1(e) + CH(e,f,g) + k[i] + m[i];
t2 = EP0(a) + MAJ(a,b,c);
h = g;
g = f;
f = e;
e = d + t1;
d = c;
c = b;
b = a;
a = t1 + t2;
}
ctx->state[0] += a;
ctx->state[1] += b;
ctx->state[2] += c;
ctx->state[3] += d;
ctx->state[4] += e;
ctx->state[5] += f;
ctx->state[6] += g;
ctx->state[7] += h;
}
void sha256_init(SHA256_CTX *ctx)
{
ctx->datalen = 0;
ctx->bitlen = 0;
ctx->state[0] = 0x6a09e667;
ctx->state[1] = 0xbb67ae85;
ctx->state[2] = 0x3c6ef372;
ctx->state[3] = 0xa54ff53a;
ctx->state[4] = 0x510e527f;
ctx->state[5] = 0x9b05688c;
ctx->state[6] = 0x1f83d9ab;
ctx->state[7] = 0x5be0cd19;
}
void sha256_update(SHA256_CTX *ctx, const BYTE data[], size_t len)
{
WORD i;
for (i = 0; i < len; ++i) {
ctx->data[ctx->datalen] = data[i];//这里是逐字节传递的
ctx->datalen++;
if (ctx->datalen == 64) {//这里到了64字节直接先进行加密
// 64 byte = 512 bit means the buffer ctx->data has fully stored one chunk of message
// so do the sha256 hash map for the current chunk
sha256_transform(ctx, ctx->data);
ctx->bitlen += 512;
ctx->datalen = 0;
}
}
}
void sha256_final(SHA256_CTX *ctx, BYTE hash[])
{
WORD i;
i = ctx->datalen;
//填充
// Pad whatever data is left in the buffer.
if (ctx->datalen < 56) {
ctx->data[i++] = 0x80; // pad 10000000 = 0x80
while (i < 56)
ctx->data[i++] = 0x00;
}
else {
ctx->data[i++] = 0x80;
while (i < 64)
ctx->data[i++] = 0x00;
sha256_transform(ctx, ctx->data);
memset(ctx->data, 0, 56);
}
// Append to the padding the total message's length in bits and transform.
ctx->bitlen += ctx->datalen * 8;
ctx->data[63] = ctx->bitlen;
ctx->data[62] = ctx->bitlen >> 8;
ctx->data[61] = ctx->bitlen >> 16;
ctx->data[60] = ctx->bitlen >> 24;
ctx->data[59] = ctx->bitlen >> 32;
ctx->data[58] = ctx->bitlen >> 40;
ctx->data[57] = ctx->bitlen >> 48;
ctx->data[56] = ctx->bitlen >> 56;
sha256_transform(ctx, ctx->data);
// copying the final state to the output hash(use big endian).
//(use big endian)
for (i = 0; i < 4; ++i) {
hash[i] = (ctx->state[0] >> (24 - i * 8)) & 0x000000ff;
hash[i + 4] = (ctx->state[1] >> (24 - i * 8)) & 0x000000ff;
hash[i + 8] = (ctx->state[2] >> (24 - i * 8)) & 0x000000ff;
hash[i + 12] = (ctx->state[3] >> (24 - i * 8)) & 0x000000ff;
hash[i + 16] = (ctx->state[4] >> (24 - i * 8)) & 0x000000ff;
hash[i + 20] = (ctx->state[5] >> (24 - i * 8)) & 0x000000ff;
hash[i + 24] = (ctx->state[6] >> (24 - i * 8)) & 0x000000ff;
hash[i + 28] = (ctx->state[7] >> (24 - i * 8)) & 0x000000ff;
}
}
int main()
{
SHA256_CTX context;\
sha256_init(&context); // 初始化SHA512Context
unsigned char *plainText = (unsigned char *)"xiaojianbang";
sha256_update(&context, plainText, strlen(plainText));//这里直接去将明文进行赋值
unsigned char result[64];
sha256_final(&context, result); //在这里进行计算操作了
char temp[2]={0};
char finalResult[64] = { 0 };
for (int i = 0; i < 32; i++)
{
int index = i;
sprintf(temp, "%.2x", result[index]);
strcat(finalResult, temp);
}
printf("SHA-256 Hash: %s\n", finalResult);
return 0;
}
SHA512:
- 初始化常量 8 个, IDA 反编译有时显示为 16 个
A = 0x6a09e667f3bcc908;
B = 0xbb67ae8584caa73b;
C = 0x3c6ef372fe94f82b;
D = 0xa54ff53a5f1d36f1;
E = 0x510e527fade682d1;
F = 0x9b05688c2b3e6c1f;
G = 0x1f83d9abfb41bd6b;
H = 0x5be0cd19137e2179; - K 表 80 个,每轮 1 个 K 值
K1 = 0x428a2f98d728ae22
K2 = 0x7137449123ef65cd
K3 = 0xb5c0fbcfec4d3b2f
K4 = 0xe9b5dba58189dbbc - 输出长度为 64 字节,或者说 128 个十六进制数
- md5 、 sha1 、 sha256 都是 512bit 分组, sha512 是 1024bit 分组
SHA512.C
#include <memory.h>
#include <stdio.h>
#include "sha512.h"
// 用于补齐的数,最多补128字节也就是1024bit
unsigned char padding_512[] = {
0x80, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
};
// 循环右移(64位)
#define ROR64(value, bits) (((value) >> (bits)) | ((value) << (64 - (bits))))
//////////////////////////////////////////////////////
// //
// Ch,:Maj操作 //
// S:循环右移 R:同2**128除余右移 //
// Sigma0:Sigma0函数 //
// Sigma1:Sigma2函数 //
// Gamma0:Gamma0函数 //
// Gamma1:Gamma1函数 //
//////////////////////////////////////////////////////
#define Ch(x, y, z) (z ^ (x & (y ^ z)))
#define Maj(x, y, z) (((x | y) & z) | (x & y))
#define S(x, n) ROR64( x, n )
#define R(x, n) (((x)&0xFFFFFFFFFFFFFFFFULL)>>((unsigned long long)n))
#define Sigma0(x) (S(x, 28) ^ S(x, 34) ^ S(x, 39))
#define Sigma1(x) (S(x, 14) ^ S(x, 18) ^ S(x, 41))
#define Gamma0(x) (S(x, 1) ^ S(x, 8) ^ R(x, 7))
#define Gamma1(x) (S(x, 19) ^ S(x, 61) ^ R(x, 6))
#define Sha512Round(a, b, c, d, e, f, g, h, i) \
t0 = h + Sigma1(e) + Ch(e, f, g) + K[i] + W[i]; \
t1 = Sigma0(a) + Maj(a, b, c); \
d += t0; \
h = t0 + t1;
void SHA512Init(SHA512_CB *context) {
context->count[0] = 0;
context->count[1] = 0;
context->state[0] = 0x6a09e667f3bcc908ULL;
context->state[1] = 0xbb67ae8584caa73bULL;
context->state[2] = 0x3c6ef372fe94f82bULL;
context->state[3] = 0xa54ff53a5f1d36f1ULL;
context->state[4] = 0x510e527fade682d1ULL;
context->state[5] = 0x9b05688c2b3e6c1fULL;
context->state[6] = 0x1f83d9abfb41bd6bULL;
context->state[7] = 0x5be0cd19137e2179ULL;
}
void SHA512Update(SHA512_CB *context, unsigned char *input, unsigned long long inputlen)
{
unsigned long long index = 0, partlen = 0, i = 0; // i记录input的当前位置(初始为0)
index = (context->count[1] >> 3) & 0x7F; //index:总字长除127(11111111)取余后的余数
partlen = 128 - index; //partlen:同128相差的长度
context->count[1] += inputlen << 3; //更新count
// 统计字符的bit长度,如果小于说明类型溢出了(64bit)无法装下了
// 由于最后留下128bit填充字符长度,因而必须引入count[1]保存
// 64bit+64bit=128bit
if (context->count[1] < (inputlen << 3))
context->count[0]++;
//右移动61位后就是count[0]应该记录的值。(左移3位,溢出的就是右移动61位的)
context->count[0] += inputlen >> 61;
// 如果此次更新的长度,大于原长度同128做差的值, //
// .ie. 加上刚更新的长度满足了128Bytes(1024位) //
// 因而可以进行一次加密循环 //
if (inputlen >= partlen) {
//将缺的partlen个字节数据加入缓冲区
memcpy(&context->buffer[index], input, partlen);
SHA512Transform(context->state, context->buffer);
// 如果输入的字,还可以进行(还有整128字的)就继续进行一次加密循环
for (i = partlen; i + 128 <= inputlen; i += 128)
SHA512Transform(context->state, &input[i]);
// 将当前位置设为0
index = 0;
} else {
i = 0;
}
// 重新设置buffer区(处理过的字被覆盖成新字)
memcpy(&context->buffer[index], &input[i], inputlen - i);
}
void SHA512Final(SHA512_CB *context, unsigned char digest[64]) {
unsigned int index = 0, padlen = 0;
unsigned char bits[16]; // 记录字长信息
index = (context->count[1] >> 3) & 0x7F; // 字长除127(11111111)取余长度
padlen = (index < 112) ? (112 - index) : (240 - index); // 补齐的字长
SHA512Encode(bits, context->count, 16);
SHA512Update(context, padding_512, padlen);
SHA512Update(context, bits, 16);
SHA512Encode(digest, context->state, 64);
}
void SHA512Encode(unsigned char *output, unsigned long long *input, unsigned long long len) {
unsigned long long i = 0, j = 0;
while (j < len) {
output[j + 7] = input[i] & 0xFF;
output[j + 6] = (input[i] >> 8) & 0xFF; //0xFF:11111111
output[j + 5] = (input[i] >> 16) & 0xFF;
output[j + 4] = (input[i] >> 24) & 0xFF;
output[j + 3] = (input[i] >> 32) & 0xFF;
output[j + 2] = (input[i] >> 40) & 0xFF;
output[j + 1] = (input[i] >> 48) & 0xFF;
output[j] = (input[i] >> 56) & 0xFF;
i++;
j += 8;
}
}
void SHA512Decode(unsigned long long *output, unsigned char *input, unsigned long long len) {
unsigned long long i = 0, j = 0;
while (j < len) {
output[i] = ((unsigned long long) input[j + 7]) |
((unsigned long long) input[j + 6] << 8) |
((unsigned long long) input[j + 5] << 16) |
((unsigned long long) input[j + 4] << 24) |
((unsigned long long) input[j + 3] << 32) |
((unsigned long long) input[j + 2] << 40) |
((unsigned long long) input[j + 1] << 48) |
((unsigned long long) input[j] << 56);
i++;
j += 8;
}
}
void SHA512Transform(unsigned long long state[8], unsigned char block[128]) {
unsigned long long S[8];
unsigned long long W[80];
unsigned long long t0;
unsigned long long t1;
int i = 0;
printf("\n填充后(1024bits):\n0x");
for (int index = 0; index < 128; index++) {
printf("%02x", block[index]);
}
printf("\n");
// 把state的值复制给S
for (i = 0; i < 8; i++) {
S[i] = state[i];
}
// 将字符数组保存的编码转为unsigned long long
SHA512Decode(W, block, 128);
for (i = 16; i < 80; i++) {
W[i] = Gamma1(W[i - 2]) + W[i - 7] + Gamma0(W[i - 15]) + W[i - 16];
}
for (i = 0; i < 80; i += 8) {
Sha512Round(S[0], S[1], S[2], S[3], S[4], S[5], S[6], S[7], i + 0);
Sha512Round(S[7], S[0], S[1], S[2], S[3], S[4], S[5], S[6], i + 1);
Sha512Round(S[6], S[7], S[0], S[1], S[2], S[3], S[4], S[5], i + 2);
Sha512Round(S[5], S[6], S[7], S[0], S[1], S[2], S[3], S[4], i + 3);
Sha512Round(S[4], S[5], S[6], S[7], S[0], S[1], S[2], S[3], i + 4);
Sha512Round(S[3], S[4], S[5], S[6], S[7], S[0], S[1], S[2], i + 5);
Sha512Round(S[2], S[3], S[4], S[5], S[6], S[7], S[0], S[1], i + 6);
Sha512Round(S[1], S[2], S[3], S[4], S[5], S[6], S[7], S[0], i + 7);
}
printf("\n");
printf("A:%I64u\n", S[0]);
printf("B:%I64u\n", S[1]);
printf("C:%I64u\n", S[2]);
printf("D:%I64u\n", S[3]);
printf("E:%I64u\n", S[4]);
printf("F:%I64u\n", S[5]);
printf("G:%I64u\n", S[6]);
printf("H:%I64u\n", S[7]);
printf("\n");
// Feedback
for (i = 0; i < 8; i++) {
state[i] = state[i] + S[i];
}
}
int main()
{
SHA512_CB context;\
SHA512Init(&context); // 初始化SHA512Context
unsigned char *plainText = (unsigned char *)"xiaojianbang";
SHA512Update(&context, plainText, strlen(plainText));//这里直接去将明文进行赋值
unsigned char result[64];
SHA512Final(&context, result); //在这里进行计算操作了
char temp[4]={0};
char finalResult[128] = { 0 };
for (int i = 0; i < 64; i++)
{
int index = i;
sprintf(temp, "%.2x", result[index]);
strcat(finalResult, temp);
}
printf("SHA-512 Hash: %s\n", finalResult);
return 0;
}
SHA512.h
#ifndef SHA512_H
#define SHA512_H
//////////////////////////////////////////////////////////
// SHA512_CB(control block) //
// SHA512_CB:SHA512控制块,包含算法运算过程中将用到的信息//
// count[2]:记录128位的数字长度(两个64位) //
// state[8]:A-H八个初始常量(64bit) //
// buffer[128]:用于每次运算的1024bit //
// //
//////////////////////////////////////////////////////////
typedef struct
{
unsigned long long count[2];
unsigned long long state[8];
unsigned char buffer[128];
} SHA512_CB;
// 每次子循环中用到的常量
// 后面加ULL表示long long
static const unsigned long long K[80] = {
0x428a2f98d728ae22ULL, 0x7137449123ef65cdULL, 0xb5c0fbcfec4d3b2fULL, 0xe9b5dba58189dbbcULL,
0x3956c25bf348b538ULL, 0x59f111f1b605d019ULL, 0x923f82a4af194f9bULL, 0xab1c5ed5da6d8118ULL,
0xd807aa98a3030242ULL, 0x12835b0145706fbeULL, 0x243185be4ee4b28cULL, 0x550c7dc3d5ffb4e2ULL,
0x72be5d74f27b896fULL, 0x80deb1fe3b1696b1ULL, 0x9bdc06a725c71235ULL, 0xc19bf174cf692694ULL,
0xe49b69c19ef14ad2ULL, 0xefbe4786384f25e3ULL, 0x0fc19dc68b8cd5b5ULL, 0x240ca1cc77ac9c65ULL,
0x2de92c6f592b0275ULL, 0x4a7484aa6ea6e483ULL, 0x5cb0a9dcbd41fbd4ULL, 0x76f988da831153b5ULL,
0x983e5152ee66dfabULL, 0xa831c66d2db43210ULL, 0xb00327c898fb213fULL, 0xbf597fc7beef0ee4ULL,
0xc6e00bf33da88fc2ULL, 0xd5a79147930aa725ULL, 0x06ca6351e003826fULL, 0x142929670a0e6e70ULL,
0x27b70a8546d22ffcULL, 0x2e1b21385c26c926ULL, 0x4d2c6dfc5ac42aedULL, 0x53380d139d95b3dfULL,
0x650a73548baf63deULL, 0x766a0abb3c77b2a8ULL, 0x81c2c92e47edaee6ULL, 0x92722c851482353bULL,
0xa2bfe8a14cf10364ULL, 0xa81a664bbc423001ULL, 0xc24b8b70d0f89791ULL, 0xc76c51a30654be30ULL,
0xd192e819d6ef5218ULL, 0xd69906245565a910ULL, 0xf40e35855771202aULL, 0x106aa07032bbd1b8ULL,
0x19a4c116b8d2d0c8ULL, 0x1e376c085141ab53ULL, 0x2748774cdf8eeb99ULL, 0x34b0bcb5e19b48a8ULL,
0x391c0cb3c5c95a63ULL, 0x4ed8aa4ae3418acbULL, 0x5b9cca4f7763e373ULL, 0x682e6ff3d6b2b8a3ULL,
0x748f82ee5defb2fcULL, 0x78a5636f43172f60ULL, 0x84c87814a1f0ab72ULL, 0x8cc702081a6439ecULL,
0x90befffa23631e28ULL, 0xa4506cebde82bde9ULL, 0xbef9a3f7b2c67915ULL, 0xc67178f2e372532bULL,
0xca273eceea26619cULL, 0xd186b8c721c0c207ULL, 0xeada7dd6cde0eb1eULL, 0xf57d4f7fee6ed178ULL,
0x06f067aa72176fbaULL, 0x0a637dc5a2c898a6ULL, 0x113f9804bef90daeULL, 0x1b710b35131c471bULL,
0x28db77f523047d84ULL, 0x32caab7b40c72493ULL, 0x3c9ebe0a15c9bebcULL, 0x431d67c49c100d4cULL,
0x4cc5d4becb3e42b6ULL, 0x597f299cfc657e2aULL, 0x5fcb6fab3ad6faecULL, 0x6c44198c4a475817ULL
};
// 初始化函数,初始化SHA_CB的各个值
void SHA512Init(SHA512_CB *context);
// 将数据加入
void SHA512Update(SHA512_CB *context, unsigned char *input, unsigned long long inputlen);
// 处理完最后再调用,这个处理尾数
void SHA512Final(SHA512_CB *context, unsigned char digest[32]);
// 加密处理函数:Hash加密的核心工厂
void SHA512Transform(unsigned long long state[8], unsigned char block[128]);
// 编码函数:将整型编码转为字符
void SHA512Encode(unsigned char *output, unsigned long long *input, unsigned long long len);
// 解码函数:将字符数组保存的编码转为整型
void SHA512Decode(unsigned long long *output, unsigned char *input, unsigned long long len);
#endif
MAC算法
- MAC 算法其实就是两次加盐,两次 hash 的一种 hash 算法
- 公式中的一些符号含义
m 明文
K’ 扩展后的密钥
ipad 0x36
opad 0x5c
|| 级联
H hash 函数
MAC 算法
1. 密钥扩展
a) 密钥 a12345678 转 Hex 编码
61 31 32 33 34 35 36 37 38
b) 然后填充 0 ,让密钥长度到达算法的分组长度, MD5 的话就是 512bit
61 31 32 33 34 35 36 37 38 00 00 ... 00 00
c) 如果密钥太长,就先进行 MD5 ,再填充 0
16 字节 + 一堆 00
2. 扩展后的密钥与 0x36 异或
57 07 04 05 02 03 00 01 0e 36 36 ... 36 36
3. 异或后的数据与明文 (Message) 级联
57 07 04 05 02 03 00 01 0e 36 36 ... 36 36 61 31 32 33 34 35 36 37 38
4. 级联后的数据进行 Hash(MD5) 算法
df d5 ff a5 3b 3a cf 37 f2 91 1f a9 35 e6 32 16
5. 扩展后的密钥与 0x5c 异或
3d 6d 6e 6f 68 69 6a 6b 64 5c 5c ... 5c 5c
6. 异或的结果与 Hash 的结果级联
3d 6d 6e 6f 68 69 6a 6b 64 5c 5c ... 5c 5c df d5 ff a5 3b 3a cf 37 f2 91 1f
a9 35 e6 32 16
7. 再次进行 Hash 算法
a1cf883260ad4b25f37ae2e572e203d4
9. MAC 算法的简单识别
找 0x36 和 0x5c 、 54 和 92 来分辨是不是 HMAC 算法
也可以靠猜,比如 MD5 、魔改的 MD5 、 HmacMD5 最后的输出结果都是 16 个字节
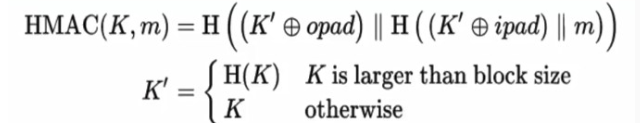
hmac_md5.c:
#include "hmac_md5.h"
#include "md5.h"
#include <stdio.h>
#include <string.h>
#define LENGTH_MD5_RESULT 16
#define LENGTH_BLOCK 64
void hmac_md5(unsigned char *out, unsigned char *data, int dlen, unsigned char *key, int klen) {
int i;
unsigned char tempString16[LENGTH_MD5_RESULT];
unsigned char OneEnding[LENGTH_BLOCK];
unsigned char TwoEnding[LENGTH_BLOCK];
unsigned char ThreeEnding[LENGTH_BLOCK + dlen];
unsigned char FourEnding[LENGTH_MD5_RESULT]; /*如下步骤四生成的结果*/
unsigned char FiveEnding[LENGTH_BLOCK]; /*步骤五生成的结果*/
unsigned char SixEnding[LENGTH_BLOCK + LENGTH_MD5_RESULT];
char ipad;
char opad;
MD5_CTX md5;
ipad = 0x36;
opad = 0x5c;
/*
* (1) 在密钥key后面添加0来创建一个长为B(64字节)的字符串(OneEnding)。如果key的长度klen大于64字节,则先进行md5运算,使其长度klen=16字节。
* */
for (i = 0; i < LENGTH_BLOCK; i++) {
OneEnding[i] = 0;
}
//小于512bit(64字节)的就直接进行0的填充
if (klen > LENGTH_BLOCK) {//假如key大于了64byte,就先进行md5 结果就是Md5(plainText)+00 00 00....
MD5Init(&md5);
MD5Update(&md5, key, klen);
MD5Final(&md5, tempString16);
for (i = 0; i < LENGTH_MD5_RESULT; i++)
OneEnding[i] = tempString16[i];
} else {
for (i = 0; i < klen; i++)//没有大于,直接赋值 结果就是plainText+00 00 00....
OneEnding[i] = key[i];
}
/*
* (2) 将上一步生成的字符串(OneEnding)与ipad(0x36)做异或运算,形成结果字符串(TwoEnding)。
* */
for (i = 0; i < LENGTH_BLOCK; i++) {
TwoEnding[i] = OneEnding[i] ^ ipad;
}
/*
* (3) 将数据流data附加到第二步的结果字符串(TwoEnding)的末尾。
* */
for (i = 0; i < LENGTH_BLOCK; i++) {
ThreeEnding[i] = TwoEnding[i];
}
for (; i < dlen + LENGTH_BLOCK; i++) {
ThreeEnding[i] = data[i - LENGTH_BLOCK];
}
/*
* (4) 做md5运算于第三步生成的数据流(ThreeEnding)。
* */
MD5Init(&md5);
MD5Update(&md5, ThreeEnding, LENGTH_BLOCK + dlen);
MD5Final(&md5, FourEnding);
/*
* (5) 将第一步生成的字符串(OneEnding)与opad(0x5c)做异或运算,形成结果字符串(FiveEnding)。
* */
for (i = 0; i < LENGTH_BLOCK; i++) {
FiveEnding[i] = OneEnding[i] ^ opad;
}
/*
* (6) 再将第四步的结果(FourEnding)附加到第五步的结果字符串(FiveEnding)的末尾。
* */
for (i = 0; i < LENGTH_BLOCK; i++) {
SixEnding[i] = FiveEnding[i];
}
for (; i < (LENGTH_BLOCK + LENGTH_MD5_RESULT); i++) {
SixEnding[i] = FourEnding[i - LENGTH_BLOCK];
}
/*
* (7) 做md5运算于第六步生成的数据流(SixEnding),输出最终结果(out)。
* */
MD5Init(&md5);
MD5Update(&md5, SixEnding, LENGTH_BLOCK + LENGTH_MD5_RESULT);
MD5Final(&md5, out);
}
int main()
{
unsigned char* plainText = (unsigned char*)"xiaojianbang";
unsigned char* key = (unsigned char*)"a12345678";
unsigned char result[16];
hmac_md5(result, plainText, strlen((const char*)plainText), (unsigned char*)key, strlen((const char*)key));
char temp[2]={0};
char finalResult[32] = { 0 };
for (int i = 0; i < 16; i++)
{
int index = i;
sprintf(temp, "%.2x", result[index]);
strcat(finalResult, temp);
}
printf("hamc_md5: %s\n", finalResult);
return 0;
}
hmac_md5.h:
#ifndef ENCRYPTDEMO_HMAC_MD5_H
#define ENCRYPTDEMO_HMAC_MD5_H
void hmac_md5(unsigned char *out, unsigned char *data, int dlen, unsigned char *key, int klen);
#endif //ENCRYPTDEMO_HMAC_MD5_H
DES:
- 不考虑填充方式
- 不考虑加密模式
- 不考虑iv向量
- 输入明文为8个字节,密钥为8个字节,输出结果也为8个字节
明文:0123456789ABCDEF
密钥:133457799BBCDFF1
子密钥的生成
把密钥转二进制
133457799BBCDFF1 ===== 00010011 00110100 01010111 01111001 10011011 10111100 11011111 11110001
根据PC1表,对密钥进行重新排列
int PC1_Table[56] = {
57, 49, 41, 33, 25, 17, 9, 1, 58, 50, 42, 34, 26, 18,
10, 2, 59, 51, 43, 35, 27, 19, 11, 3, 60, 52, 44, 36,
63, 55, 47, 39, 31, 23, 15, 7, 62, 54, 46, 38, 30, 22,
14, 6, 61, 53, 45, 37, 29, 21, 13, 5, 28, 20, 12, 4};
密钥编排后的结果(这里考虑的是二进制位上面的位置的重排)
1111000 0110011 0010101 0101111 0101010 1011001 1001111 0001111
接下来将这56比特长的密钥分成左右两部分,命名为C0,D0
C0 = 1111000 0110011 0010101 0101111
D0 = 0101010 1011001 1001111 0001111
循环左移规定的位数,得到C1,D1到C16,D16的十六个数据(这里先按照)
key_shift = [1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1];
C1 = 1110000 1100110 0101010 1011111
D1 = 1010101 0110011 0011110 0011110
C2D2可以对C1D1分别左移1位来得到,C2D2也可以对C0D0分别左移2位来得到
将C1D1拼接起来,继续后续的处理
C1D1 = 1110000 1100110 0101010 1011111 1010101 0110011 0011110 0011110
根据PC2表进行重排,56bit长的CnDn只留下48比特(这里直接缩小了子密钥)
int PC2_Table[48] = {
14, 17, 11, 24, 1, 5, 3, 28, 15, 6, 21, 10,
23, 19, 12, 4, 26, 8, 16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55, 30, 40, 51, 45, 33, 48,
44, 49, 39, 56, 34, 53, 46, 42, 50, 36, 29, 32};
重排后CnDn就是子密钥,命名为Kn
后续DES的十六轮运算中,第n轮就是用Kn,16个子密钥为
K1 = 000110 110000 001011 101111 111111 000111 000001 110010
K2 = 011110 011010 111011 011001 110110 111100 100111 100101
K3 = 010101 011111 110010 001010 010000 101100 111110 011001
K4 = 011100 101010 110111 010110 110110 110011 010100 011101
K5 = 011111 001110 110000 000111 111010 110101 001110 101000
K6 = 011000 111010 010100 111110 010100 000111 101100 101111
K7 = 111011 001000 010010 110111 111101 100001 100010 111100
K8 = 111101 111000 101000 111010 110000 010011 101111 111011
K9 = 111000 001101 101111 101011 111011 011110 011110 000001
K10 = 101100 011111 001101 000111 101110 100100 011001 001111
K11 = 001000 010101 111111 010011 110111 101101 001110 000110
K12 = 011101 010111 000111 110101 100101 000110 011111 101001
K13 = 100101 111100 010111 010001 111110 101011 101001 000001
K14 = 010111 110100 001110 110111 111100 101110 011100 111010
K15 = 101111 111001 000110 001101 001111 010011 111100 001010
K16 = 110010 110011 110110 001011 000011 100001 011111 110101
总结密钥的生成:
- 首先是PC1表,对密钥进行重新排列;64bit——>56bit
- 从新排列之后的数据分为C0,D0两个部分;
- 通过按位左移可以得到C0-C15,D0-D15;
- 通过将C0,D0的值进行组合根据PC2表进行重排;56bit——>48bit
*第2步:明文的编排*
把明文转二进制
00000001 00100011 01000101 01100111 10001001 10101011 11001101 11101111
根据IP表,对明文进行初始置换
int IP_Table[64] = {
58, 50, 42, 34, 26, 18, 10, 2, 60, 52, 44, 36, 28, 20, 12, 4,
62, 54, 46, 38, 30, 22, 14, 6, 64, 56, 48, 40, 32, 24, 16, 8,
57, 49, 41, 33, 25, 17, 9, 1, 59, 51, 43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5, 63, 55, 47, 39, 31, 23, 15, 7};
明文重新排列后的结果
11001100 00000000 11001100 11111111 11110000 10101010 11110000 10101010
*第3步:明文的运算*
首先将明文分成左右两半,像上面的密钥一样,L0 和 R0
L0:11001100 00000000 11001100 11111111
R0:11110000 10101010 11110000 10101010
16轮迭代的基本套路
Ln = Rn-1
Rn = Ln-1 + f(Rn-1, Kn)
以n = 1为例:
L1 = R0 = 11110000 10101010 11110000 10101010
R1 = L0 xor f(R0, K1)
F函数:F = P(S(K1+E(R0)))
F = P(S(K1+E(R0)))
- 首先是R0的明文的32bit通过E表拓展到48bit
- 再进行一个与K1表的异或操作
- 异或操作之后得到的结果再进行一个S表的置换得到8个4bit的数据从而又回到32bit
- 最后进行一个P表的重排
f函数传入了R0与K1,即第1个子密钥
R0 = 11110000 10101010 11110000 10101010
K1 = 000110 110000 001011 101111 111111 000111 000001 110010
R0为32bit,K1为48bit(之前总结过的),长度不同,没法按位异或
扩展:将32bit的R0扩展成48bit,使用到E表(由于只有32bit,所以肯定有重复的)
int E_Table[48] = {
32, 1, 2, 3, 4, 5, 4, 5, 6, 7, 8, 9,
8, 9, 10, 11, 12, 13, 12, 13, 14, 15, 16, 17,
16, 17, 18, 19, 20, 21, 20, 21, 22, 23, 24, 25,
24, 25, 26, 27, 28, 29, 28, 29, 30, 31, 32, 1};
E(R0) = 011110 100001 010101 010101 011110 100001 010101 010101
进行密钥混合 E(R0) ^ K1
E(R0) = 011110 100001 010101 010101 011110 100001 010101 010101
K1 = 000110 110000 001011 101111 111111 000111 000001 110010
K1+E(R0)= 011000 010001 011110 111010 100001 100110 010100 100111
将上一步的结果分成8块6bit(分组)
B1 = 011000
B2 = 010001
B3 = 011110
B4 = 111010
B5 = 100001
B6 = 100110
B7 = 010100
B8 = 100111
把B1-B8的值当成索引,在S1-S8盒中取值,规则如下:
以B1为例,值为011000,将它分成0 1100 0,得到
i = 00 即 0
j = 1100 即 12
在S1中查找第0行第12列的值(这里从0开始算)
int S_Box[8][4][16] = {
// S1
14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7,
0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8,
4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0,
15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13,
// S2
15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10,
3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5,
0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15,
13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9,
// S3
10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8,
13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1,
13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7,
1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12,
// S4
7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15,
13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9,
10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4,
3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14,
// S5
2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9,
14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6,
4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14,
11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3,
// S6
12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11,
10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8,
9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6,
4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13,
// S7
4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1,
13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6,
1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2,
6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12,
// S8
13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7,
1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2,
7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8,
2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11};
第0行第12列的值为5,B1 = 5 = 0101
再以B2为例,B2 = 0 1000 1 ,i = 01 = 1 ,j = 1000 = 8 , B2 = 12 = 1100
B1在S1中找,B2在S2中找,以此类推
最后8个6比特的值在S盒作用下变成8个4比特的值
S(K1+E(R0)) = 0101 1100 1000 0010 1011 0101 1001 0111
得到的结果进行P表的重排
int P_Table[32] = {
16, 7, 20, 21, 29, 12, 28, 17, 1, 15, 23, 26, 5, 18, 31, 10,
2, 8, 24, 14, 32, 27, 3, 9, 19, 13, 30, 6, 22, 11, 4, 25};
P(S(K1+E(R0))) = 0010 0011 0100 1010 1010 1001 1011 1011
F函数完事,即F = P(S(K1+E(R0)))
最后的运算:
F的结果与L0异或
L1 = R0 = 11110000 10101010 11110000 10101010
R1 = Ln-1 xor f(Rn-1,Kn) = 11101111 01001010 01100101 01000100
一轮运算完毕,16轮运算的操作完全一致
L1: 11110000 10101010 11110000 10101010
R1: 11101111 01001010 01100101 01000100
L2: 11101111 01001010 01100101 01000100
R2: 11001100 00000001 01110111 00001001
L3: 11001100 00000001 01110111 00001001
R3: 10100010 01011100 00001011 11110100
L4: 10100010 01011100 00001011 11110100
R4: 01110111 00100010 00000000 01000101
L5: 01110111 00100010 00000000 01000101
R5: 10001010 01001111 10100110 00110111
L6: 10001010 01001111 10100110 00110111
R6: 11101001 01100111 11001101 01101001
L7: 11101001 01100111 11001101 01101001
R7: 00000110 01001010 10111010 00010000
L8: 00000110 01001010 10111010 00010000
R8: 11010101 01101001 01001011 10010000
L9: 11010101 01101001 01001011 10010000
R9: 00100100 01111100 11000110 01111010
L10:00100100 01111100 11000110 01111010
R10:10110111 11010101 11010111 10110010
L11:10110111 11010101 11010111 10110010
R11:11000101 01111000 00111100 01111000
L12:11000101 01111000 00111100 01111000
R12:01110101 10111101 00011000 01011000
L13:01110101 10111101 00011000 01011000
R13:00011000 11000011 00010101 01011010
L14:00011000 11000011 00010101 01011010
R14:11000010 10001100 10010110 00001101
L15:11000010 10001100 10010110 00001101
R15:01000011 01000010 00110010 00110100
L16:01000011 01000010 00110010 00110100
R16:00001010 01001100 11011001 10010101
L16和R16倒换,左右调一下顺序,结果为R16L16
R16L16 = 00001010 01001100 11011001 10010101 01000011 01000010 00110010 00110100
最后一步,根据FP表进行末置换
10000101 11101000 00010011 01010100 00001111 00001010 10110100 00000101
int FP_Table[64] = {
40, 8, 48, 16, 56, 24, 64, 32, 39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30, 37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28, 35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26, 33, 1, 41, 9, 49, 17, 57, 25};
上述数据的十六进制形式为:85 e8 13 54 0f 0a b4 05
加密方式的填充:
- 明文长度不够 1 个分组,就需要填充。以下内容以最常用的 PKCS7 填充为例
- 明文没有内容或者明文刚好一个分组长度(1-64bit),都需要再填充一个分组
- 最多填充 1 个分组, 08 08 08 08 08 08 08 08
- 其他填充的情况
ab cd ef ab cd ef ab 01
ab cd ef ab cd ef 02 02
ab cd ef ab cd 03 03 03
...
ab 07 07 07 07 07 07 07
0a 07 07 07 07 07 07 07
// 如果明文里有半个字节,先补 0 再填充, 0a 算最终明文,填充部分解密后会去掉
- DES 的密文长度是 8 字节的倍数 , 但密钥不存在填充, DES 密钥必须 8 字节
- 填充并不是 DES 特有,像3DES,AES都会填充的
加密方式的模式:
ECB 模式:
- 每个分组之间单独加密,互不关联(体现在DES中就是前八个字节和后八个字节不相关联)
- 2 个分组明文一样,结果也一样,那么只需爆破其中 1 个就可以了
- 每个分组互不关联,可以分段同时来爆破,不安全
- 可以通过替换某段密文来达到替换明文的目的
BC 模式
每个明文分组先和上个分组的密文块进行异或,得到的结果进行加密
第 1 个明文块没有上个分组的密文块,需要指定一个 64 比特的输入,也就是初始化向量 IV
CBC 模式举例:
明文: 123456789ABCDEF0
密钥: 133457799BBCDFF1
IV : 0123456789ABCDEF
结果: 0ecb68bac16aece0 7cbadcfa7a974bcc
- 明文先和IV向量进行异或:123456789ABCDEF0 和 0123456789ABCDEF 异或来得到
123456789ABCDEF0 ^ 0123456789ABCDEF = 1317131f1317131f - 得到的结果也就是第一组进行DES加密的数据,1317131f1317131f 进行 DES_ECB 加密,得到 0ecb68bac16aece0 fdf2e174492922f8
- 由于我们的明文加密的长度是8个字节,所以PKCS7padding直接填充一个分组长度的08 08....
- 所以将第一组DES加密的结果异或上第二组的明文0ecb68bac16aece0 ^ 0808080808080808 = 06c360b2c962e4e8
- 得到第二组需要进行DES加密的数据进行DES加密,得到 7cbadcfa7a974bcc fdf2e174492922f8
CFB 模式
明文: 123456789ABCDEF0
密钥: 133457799BBCDFF1
IV : 0123456789ABCDEF
结果: 97dc452c95b66af5
IV 即 0123456789ABCDEF 的 des 加密结果 85e813540f0ab405
85e813540f0ab405 与 123456789ABCDEF0 的异或结果是 97dc452c95b66af5
OFB 模式
明文: 123456789ABCDEF0
密钥: 133457799BBCDFF1
IV : 0123456789ABCDEF
结果: 97dc452c95b66af5
即一个分组的 OFB 与 CFB 是一样一样的
两个分组的 OFB 模式
明文: 123456789ABCDEF0 123456789ABCDEF0
密钥: 133457799BBCDFF1
IV : 0123456789ABCDEF
结果: 97dc452c95b66af5 759a2c51fb637db5
第二个分组 759a2c51fb637db5 是明文和加密两次的 IV 的异或结果
CFB/OFB 都可以作为流加密
明文: a1
密钥: 0123456789abcdef
IV : 0123456789ABCDEF
结果: f7
先把 IV 加密,得到 56cc09e7cfdc4cef
56cc09e7cfdc4cef ^ a1 = f7
AES加密
- AES 算法的一些特点
1.1 在一个分组长度内,明文的长度变化, AES 的加密结果长度都一样
1.2 密钥长度 128 、 192 、 256 三种,如果少 1 个十六进制数,会在前面补 0
1.3 分组长度只有 128 一种
1.4 密文长度与填充后的明文长度有关,一般是 16 字节的倍数
- Rijndael 算法也叫 AES 算法
Rijndael 算法本身分组长度可变,但是定为 AES 算法后,分组长度只有 128 一种
- DES 中是针对 bit 进行操作, AES 中是针对字节进行操作
- AES128 -> 10 轮运算、 AES192 -> 12 轮运算、 AES256 -> 14 轮运算
AES.c
#include <stdint.h>
#include <stdio.h>
#include <string.h>
typedef struct {
uint32_t eK[44], dK[44]; // encKey, decKey
int Nr; // 10 rounds
} AesKey;
#define BLOCKSIZE 16 //AES-128分组长度为16字节
// uint8_t y[4] -> uint32_t x
#define LOAD32H(x, y) \
do { (x) = ((uint32_t)((y)[0] & 0xff)<<24) | ((uint32_t)((y)[1] & 0xff)<<16) | \
((uint32_t)((y)[2] & 0xff)<<8) | ((uint32_t)((y)[3] & 0xff));} while(0)
// uint32_t x -> uint8_t y[4]
#define STORE32H(x, y) \
do { (y)[0] = (uint8_t)(((x)>>24) & 0xff); (y)[1] = (uint8_t)(((x)>>16) & 0xff); \
(y)[2] = (uint8_t)(((x)>>8) & 0xff); (y)[3] = (uint8_t)((x) & 0xff); } while(0)
// 从uint32_t x中提取从低位开始的第n个字节
#define BYTE(x, n) (((x) >> (8 * (n))) & 0xff)
/* used for keyExpansion */
// 字节替换然后循环左移1位
#define MIX(x) (((S[BYTE(x, 2)] << 24) & 0xff000000) ^ ((S[BYTE(x, 1)] << 16) & 0xff0000) ^ \
((S[BYTE(x, 0)] << 8) & 0xff00) ^ (S[BYTE(x, 3)] & 0xff))
// uint32_t x循环左移n位
#define ROF32(x, n) (((x) << (n)) | ((x) >> (32-(n))))
// uint32_t x循环右移n位
#define ROR32(x, n) (((x) >> (n)) | ((x) << (32-(n))))
/* for 128-bit blocks, Rijndael never uses more than 10 rcon values */
// AES-128轮常量
static const uint32_t rcon[10] = {
0x01000000UL, 0x02000000UL, 0x04000000UL, 0x08000000UL, 0x10000000UL,
0x20000000UL, 0x40000000UL, 0x80000000UL, 0x1B000000UL, 0x36000000UL
};
// S盒
unsigned char S[256] = {
0x63, 0x7C, 0x77, 0x7B, 0xF2, 0x6B, 0x6F, 0xC5, 0x30, 0x01, 0x67, 0x2B, 0xFE, 0xD7, 0xAB, 0x76,
0xCA, 0x82, 0xC9, 0x7D, 0xFA, 0x59, 0x47, 0xF0, 0xAD, 0xD4, 0xA2, 0xAF, 0x9C, 0xA4, 0x72, 0xC0,
0xB7, 0xFD, 0x93, 0x26, 0x36, 0x3F, 0xF7, 0xCC, 0x34, 0xA5, 0xE5, 0xF1, 0x71, 0xD8, 0x31, 0x15,
0x04, 0xC7, 0x23, 0xC3, 0x18, 0x96, 0x05, 0x9A, 0x07, 0x12, 0x80, 0xE2, 0xEB, 0x27, 0xB2, 0x75,
0x09, 0x83, 0x2C, 0x1A, 0x1B, 0x6E, 0x5A, 0xA0, 0x52, 0x3B, 0xD6, 0xB3, 0x29, 0xE3, 0x2F, 0x84,
0x53, 0xD1, 0x00, 0xED, 0x20, 0xFC, 0xB1, 0x5B, 0x6A, 0xCB, 0xBE, 0x39, 0x4A, 0x4C, 0x58, 0xCF,
0xD0, 0xEF, 0xAA, 0xFB, 0x43, 0x4D, 0x33, 0x85, 0x45, 0xF9, 0x02, 0x7F, 0x50, 0x3C, 0x9F, 0xA8,
0x51, 0xA3, 0x40, 0x8F, 0x92, 0x9D, 0x38, 0xF5, 0xBC, 0xB6, 0xDA, 0x21, 0x10, 0xFF, 0xF3, 0xD2,
0xCD, 0x0C, 0x13, 0xEC, 0x5F, 0x97, 0x44, 0x17, 0xC4, 0xA7, 0x7E, 0x3D, 0x64, 0x5D, 0x19, 0x73,
0x60, 0x81, 0x4F, 0xDC, 0x22, 0x2A, 0x90, 0x88, 0x46, 0xEE, 0xB8, 0x14, 0xDE, 0x5E, 0x0B, 0xDB,
0xE0, 0x32, 0x3A, 0x0A, 0x49, 0x06, 0x24, 0x5C, 0xC2, 0xD3, 0xAC, 0x62, 0x91, 0x95, 0xE4, 0x79,
0xE7, 0xC8, 0x37, 0x6D, 0x8D, 0xD5, 0x4E, 0xA9, 0x6C, 0x56, 0xF4, 0xEA, 0x65, 0x7A, 0xAE, 0x08,
0xBA, 0x78, 0x25, 0x2E, 0x1C, 0xA6, 0xB4, 0xC6, 0xE8, 0xDD, 0x74, 0x1F, 0x4B, 0xBD, 0x8B, 0x8A,
0x70, 0x3E, 0xB5, 0x66, 0x48, 0x03, 0xF6, 0x0E, 0x61, 0x35, 0x57, 0xB9, 0x86, 0xC1, 0x1D, 0x9E,
0xE1, 0xF8, 0x98, 0x11, 0x69, 0xD9, 0x8E, 0x94, 0x9B, 0x1E, 0x87, 0xE9, 0xCE, 0x55, 0x28, 0xDF,
0x8C, 0xA1, 0x89, 0x0D, 0xBF, 0xE6, 0x42, 0x68, 0x41, 0x99, 0x2D, 0x0F, 0xB0, 0x54, 0xBB, 0x16
};
//逆S盒
unsigned char inv_S[256] = {
0x52, 0x09, 0x6A, 0xD5, 0x30, 0x36, 0xA5, 0x38, 0xBF, 0x40, 0xA3, 0x9E, 0x81, 0xF3, 0xD7, 0xFB,
0x7C, 0xE3, 0x39, 0x82, 0x9B, 0x2F, 0xFF, 0x87, 0x34, 0x8E, 0x43, 0x44, 0xC4, 0xDE, 0xE9, 0xCB,
0x54, 0x7B, 0x94, 0x32, 0xA6, 0xC2, 0x23, 0x3D, 0xEE, 0x4C, 0x95, 0x0B, 0x42, 0xFA, 0xC3, 0x4E,
0x08, 0x2E, 0xA1, 0x66, 0x28, 0xD9, 0x24, 0xB2, 0x76, 0x5B, 0xA2, 0x49, 0x6D, 0x8B, 0xD1, 0x25,
0x72, 0xF8, 0xF6, 0x64, 0x86, 0x68, 0x98, 0x16, 0xD4, 0xA4, 0x5C, 0xCC, 0x5D, 0x65, 0xB6, 0x92,
0x6C, 0x70, 0x48, 0x50, 0xFD, 0xED, 0xB9, 0xDA, 0x5E, 0x15, 0x46, 0x57, 0xA7, 0x8D, 0x9D, 0x84,
0x90, 0xD8, 0xAB, 0x00, 0x8C, 0xBC, 0xD3, 0x0A, 0xF7, 0xE4, 0x58, 0x05, 0xB8, 0xB3, 0x45, 0x06,
0xD0, 0x2C, 0x1E, 0x8F, 0xCA, 0x3F, 0x0F, 0x02, 0xC1, 0xAF, 0xBD, 0x03, 0x01, 0x13, 0x8A, 0x6B,
0x3A, 0x91, 0x11, 0x41, 0x4F, 0x67, 0xDC, 0xEA, 0x97, 0xF2, 0xCF, 0xCE, 0xF0, 0xB4, 0xE6, 0x73,
0x96, 0xAC, 0x74, 0x22, 0xE7, 0xAD, 0x35, 0x85, 0xE2, 0xF9, 0x37, 0xE8, 0x1C, 0x75, 0xDF, 0x6E,
0x47, 0xF1, 0x1A, 0x71, 0x1D, 0x29, 0xC5, 0x89, 0x6F, 0xB7, 0x62, 0x0E, 0xAA, 0x18, 0xBE, 0x1B,
0xFC, 0x56, 0x3E, 0x4B, 0xC6, 0xD2, 0x79, 0x20, 0x9A, 0xDB, 0xC0, 0xFE, 0x78, 0xCD, 0x5A, 0xF4,
0x1F, 0xDD, 0xA8, 0x33, 0x88, 0x07, 0xC7, 0x31, 0xB1, 0x12, 0x10, 0x59, 0x27, 0x80, 0xEC, 0x5F,
0x60, 0x51, 0x7F, 0xA9, 0x19, 0xB5, 0x4A, 0x0D, 0x2D, 0xE5, 0x7A, 0x9F, 0x93, 0xC9, 0x9C, 0xEF,
0xA0, 0xE0, 0x3B, 0x4D, 0xAE, 0x2A, 0xF5, 0xB0, 0xC8, 0xEB, 0xBB, 0x3C, 0x83, 0x53, 0x99, 0x61,
0x17, 0x2B, 0x04, 0x7E, 0xBA, 0x77, 0xD6, 0x26, 0xE1, 0x69, 0x14, 0x63, 0x55, 0x21, 0x0C, 0x7D
};
/* copy in[16] to state[4][4] */
int loadStateArray(uint8_t (*state)[4], const uint8_t *in) {
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
state[j][i] = *in++;
}
}
return 0;
}
/* copy state[4][4] to out[16] */
int storeStateArray(uint8_t (*state)[4], uint8_t *out) {
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
*out++ = state[j][i];
}
}
return 0;
}
//秘钥扩展
int keyExpansion(const uint8_t *key, uint32_t keyLen, AesKey *aesKey) {
if (NULL == key || NULL == aesKey) {
printf("keyExpansion param is NULL\n");
return -1;
}
if (keyLen != 16) {
printf("keyExpansion keyLen = %d, Not support.\n", keyLen);
return -1;
}
uint32_t *w = aesKey->eK; //加密秘钥
uint32_t *v = aesKey->dK; //解密秘钥
/* keyLen is 16 Bytes, generate uint32_t W[44]. */
/* W[0-3] */
for (int i = 0; i < 4; ++i) {
LOAD32H(w[i], key + 4 * i);
}
/* W[4-43] */
for (int i = 0; i < 10; ++i) { //这里是直接去操作的w指针指向的位置
w[4] = w[0] ^ MIX(w[3]) ^ rcon[i];
w[5] = w[1] ^ w[4];
w[6] = w[2] ^ w[5];
w[7] = w[3] ^ w[6];
w += 4;
}
w = aesKey->eK + 44 - 4;
//解密秘钥矩阵为加密秘钥矩阵的倒序,方便使用,把ek的11个矩阵倒序排列分配给dk作为解密秘钥
//即dk[0-3]=ek[41-44], dk[4-7]=ek[37-40]... dk[41-44]=ek[0-3]
for (int j = 0; j < 11; ++j) {
for (int i = 0; i < 4; ++i) {
v[i] = w[i];
}
w -= 4;
v += 4;
}
return 0;
}
// 轮秘钥加
int addRoundKey(uint8_t (*state)[4], const uint32_t *key) {
uint8_t k[4][4];
/* i: row, j: col */
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
k[i][j] = (uint8_t) BYTE(key[j], 3 - i); /* 把 uint32 key[4] 先转换为矩阵 uint8 k[4][4] */
state[i][j] ^= k[i][j];
}
}
return 0;
}
//字节替换
int subBytes(uint8_t (*state)[4]) {
/* i: row, j: col */
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
state[i][j] = S[state[i][j]]; //直接使用原始字节作为S盒数据下标
}
}
return 0;
}
//逆字节替换
int invSubBytes(uint8_t (*state)[4]) {
/* i: row, j: col */
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
state[i][j] = inv_S[state[i][j]];
}
}
return 0;
}
//行移位
int shiftRows(uint8_t (*state)[4]) {
uint32_t block[4] = {0};
printf("%x", state);
/* i: row */
for (int i = 0; i < 4; ++i) {
//便于行循环移位,先把一行4字节拼成uint_32结构,移位后再转成独立的4个字节uint8_t
LOAD32H(block[i], state[i]);
block[i] = ROF32(block[i], 8 * i);
STORE32H(block[i], state[i]);
}
return 0;
}
//逆行移位
int invShiftRows(uint8_t (*state)[4]) {
uint32_t block[4] = {0};
/* i: row */
for (int i = 0; i < 4; ++i) {
LOAD32H(block[i], state[i]);
block[i] = ROR32(block[i], 8 * i);
STORE32H(block[i], state[i]);
}
return 0;
}
/* Galois Field (256) Multiplication of two Bytes */
// 两字节的伽罗华域乘法运算
uint8_t GMul(uint8_t u, uint8_t v) {
uint8_t p = 0;
for (int i = 0; i < 8; ++i) {
if (u & 0x01) { //
p ^= v;
}
int flag = (v & 0x80);
v <<= 1;
if (flag) {
v ^= 0x1B; /* x^8 + x^4 + x^3 + x + 1 */
}
u >>= 1;
}
return p;
}
// 列混合
int mixColumns(uint8_t (*state)[4]) {
uint8_t tmp[4][4];
uint8_t M[4][4] = {{0x02, 0x03, 0x01, 0x01},
{0x01, 0x02, 0x03, 0x01},
{0x01, 0x01, 0x02, 0x03},
{0x03, 0x01, 0x01, 0x02}};
/* copy state[4][4] to tmp[4][4] */
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
tmp[i][j] = state[i][j];
}
}
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) { //伽罗华域加法和乘法
state[i][j] = GMul(M[i][0], tmp[0][j]) ^ GMul(M[i][1], tmp[1][j])
^ GMul(M[i][2], tmp[2][j]) ^ GMul(M[i][3], tmp[3][j]);
}
}
return 0;
}
// 逆列混合
int invMixColumns(uint8_t (*state)[4]) {
uint8_t tmp[4][4];
uint8_t M[4][4] = {{0x0E, 0x0B, 0x0D, 0x09},
{0x09, 0x0E, 0x0B, 0x0D},
{0x0D, 0x09, 0x0E, 0x0B},
{0x0B, 0x0D, 0x09, 0x0E}}; //使用列混合矩阵的逆矩阵
/* copy state[4][4] to tmp[4][4] */
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
tmp[i][j] = state[i][j];
}
}
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
state[i][j] = GMul(M[i][0], tmp[0][j]) ^ GMul(M[i][1], tmp[1][j])
^ GMul(M[i][2], tmp[2][j]) ^ GMul(M[i][3], tmp[3][j]);
}
}
return 0;
}
// AES-128加密接口,输入key应为16字节长度,输入长度应该是16字节整倍数,
// 这样输出长度与输入长度相同,函数调用外部为输出数据分配内存
int aesEncrypt(const uint8_t *key, uint32_t keyLen, const uint8_t *pt, uint8_t *ct, uint32_t len) {
AesKey aesKey;
uint8_t *pos = ct;
const uint32_t *rk = aesKey.eK; //解密秘钥指针
uint8_t out[BLOCKSIZE] = {0};
uint8_t actualKey[16] = {0};
uint8_t state[4][4] = {0};
if (NULL == key || NULL == pt || NULL == ct) {
printf("param err.\n");
return -1;
}
if (keyLen > 16) {
printf("keyLen must be 16.\n");
return -1;
}
if (len % BLOCKSIZE) {
printf("inLen is invalid.\n");
return -1;
}
memcpy(actualKey, key, keyLen);
keyExpansion(actualKey, 16, &aesKey); // 秘钥扩展
// 使用ECB模式循环加密多个分组长度的数据
for (int i = 0; i < len; i += BLOCKSIZE) {
// 把16字节的明文转换为4x4状态矩阵来进行处理
loadStateArray(state, pt);
// 轮秘钥加
addRoundKey(state, rk);//initalround初始变换
for (int j = 1; j < 10; ++j) {
rk += 4;
subBytes(state); // 字节替换
shiftRows(state); // 行移位
mixColumns(state); // 列混合
addRoundKey(state, rk); // 轮秘钥加
}
subBytes(state); // 字节替换
shiftRows(state); // 行移位
// 此处不进行列混合
addRoundKey(state, rk + 4); // 轮秘钥加
// 把4x4状态矩阵转换为uint8_t一维数组输出保存
storeStateArray(state, pos);
pos += BLOCKSIZE; // 加密数据内存指针移动到下一个分组
pt += BLOCKSIZE; // 明文数据指针移动到下一个分组
rk = aesKey.eK; // 恢复rk指针到秘钥初始位置
}
return 0;
}
// AES128解密, 参数要求同加密
int aesDecrypt(const uint8_t *key, uint32_t keyLen, const uint8_t *ct, uint8_t *pt, uint32_t len) {
AesKey aesKey;
uint8_t *pos = pt;
const uint32_t *rk = aesKey.dK; //解密秘钥指针
uint8_t out[BLOCKSIZE] = {0};
uint8_t actualKey[16] = {0};
uint8_t state[4][4] = {0};
if (NULL == key || NULL == ct || NULL == pt) {
printf("param err.\n");
return -1;
}
if (keyLen > 16) {
printf("keyLen must be 16.\n");
return -1;
}
if (len % BLOCKSIZE) {
printf("inLen is invalid.\n");
return -1;
}
memcpy(actualKey, key, keyLen);
keyExpansion(actualKey, 16, &aesKey); //秘钥扩展,同加密
for (int i = 0; i < len; i += BLOCKSIZE) {
// 把16字节的密文转换为4x4状态矩阵来进行处理
loadStateArray(state, ct);
// 轮秘钥加,同加密
addRoundKey(state, rk);
for (int j = 1; j < 10; ++j) {
rk += 4;
invShiftRows(state); // 逆行移位
invSubBytes(state); // 逆字节替换,这两步顺序可以颠倒
addRoundKey(state, rk); // 轮秘钥加,同加密
invMixColumns(state); // 逆列混合
}
invSubBytes(state); // 逆字节替换
invShiftRows(state); // 逆行移位
// 此处没有逆列混合
addRoundKey(state, rk + 4); // 轮秘钥加,同加密
storeStateArray(state, pos); // 保存明文数据
pos += BLOCKSIZE; // 输出数据内存指针移位分组长度
ct += BLOCKSIZE; // 输入数据内存指针移位分组长度
rk = aesKey.dK; // 恢复rk指针到秘钥初始位置
}
return 0;
}
// 方便输出16进制数据
void printHex(char *tag, uint8_t *ptr, int len) {
printf("%s\ndata[%d]: ", tag, len);
for (int i = 0; i < len; ++i) {
printf("%.2X ", *ptr++);
}
printf("\n");
}
int main() {
// case 1
const uint8_t key[16] = {0x2b, 0x7e, 0x15, 0x16, 0x28, 0xae, 0xd2, 0xa6, 0xab, 0xf7, 0x15, 0x88, 0x09, 0xcf, 0x4f,
0x3c};
const uint8_t pt[16] = {0x32, 0x43, 0xf6, 0xa8, 0x88, 0x5a, 0x30, 0x8d, 0x31, 0x31, 0x98, 0xa2, 0xe0, 0x37, 0x07,
0x34};
uint8_t ct[16] = {0}; // 外部申请输出数据内存,用于加密后的数据
uint8_t plain[16] = {0}; // 外部申请输出数据内存,用于解密后的数据
aesEncrypt(key, 16, pt, ct, 16); // 加密
printHex("plain data:", pt, 16); // 打印初始明文数据
printHex("after encryption:", ct, 16); // 打印加密后的密文
aesDecrypt(key, 16, ct, plain, 16); // 解密
printHex("after decryption:", plain, 16); // 打印解密后的明文数据
printf("--------------------------------------------------------------------------------------\n");
// case 2
// 16字节字符串形式秘钥
const uint8_t key2[] = "1234567890123456";
// 32字节长度字符串明文
const uint8_t *data = (uint8_t *) "abcdefghijklmnopqrstuvwxyz123456";
uint8_t ct2[32] = {0}; //外部申请输出数据内存,用于存放加密后数据
uint8_t plain2[32] = {0}; //外部申请输出数据内存,用于存放解密后数据
//加密32字节明文
aesEncrypt(key2, 16, data, ct2, 32);
printHex("after encryption:", ct2, 32);
// 解密32字节密文
aesDecrypt(key2, 16, ct2, plain2, 32);
// 打印16进制形式的解密后的明文
printHex("after decryption:", plain2, 32);
// 因为加密前的数据为可见字符的字符串,打印解密后的明文字符,与加密前明文进行对比
printf("output plain text\n");
for (int i = 0; i < 32; ++i) {
printf("%c", plain2[i]);
}
return 0;
}
查表法实现的AES算法:
AES查表法(也叫基于查表的AES实现)可以理解为将某些复杂的数学运算(特别是GF(2^8)有限域上的运算)提前计算好,存放在查找表(lookup tables)中。当加密或解密时,使用输入的明文、密钥等值直接从查找表中进行替换或查询,这样可以大幅提高运算速度。
子密钥的生成:
while (1) {
temp = rk[3];
rk[4] = rk[0] ^
(Te2[(temp >> 16) & 0xff] & 0xff000000) ^
(Te3[(temp >> 8) & 0xff] & 0x00ff0000) ^
(Te0[(temp ) & 0xff] & 0x0000ff00) ^
(Te1[(temp >> 24) ] & 0x000000ff) ^
rcon[i];
rk[5] = rk[1] ^ rk[4];
rk[6] = rk[2] ^ rk[5];
rk[7] = rk[3] ^ rk[6];
if (++i == 10) {
return 0;
}
rk += 4;
}
这里设置出来的子密钥,Te2[(temp >> 16),Te3[(temp >> 8),Te0[(temp ), Te1[(temp >> 24)这里直接去进行移位操作,并且为什么可以通过T表来实现S盒的字节代换?随便看一个T表
static const u32 Te0[256] = {
0xc66363a5U, 0xf87c7c84U, 0xee777799U, 0xf67b7b8dU,
0xfff2f20dU, 0xd66b6bbdU, 0xde6f6fb1U, 0x91c5c554U,
0x60303050U, 0x02010103U, 0xce6767a9U, 0x562b2b7dU,
0xe7fefe19U, 0xb5d7d762U, 0x4dababe6U, 0xec76769aU,
0x8fcaca45U, 0x1f82829dU, 0x89c9c940U, 0xfa7d7d87U,
0xeffafa15U, 0xb25959ebU, 0x8e4747c9U, 0xfbf0f00bU,
0x41adadecU, 0xb3d4d467U, 0x5fa2a2fdU, 0x45afafeaU,
0x239c9cbfU, 0x53a4a4f7U, 0xe4727296U, 0x9bc0c05bU,
0x75b7b7c2U, 0xe1fdfd1cU, 0x3d9393aeU, 0x4c26266aU,
0x6c36365aU, 0x7e3f3f41U, 0xf5f7f702U, 0x83cccc4fU,
0x6834345cU, 0x51a5a5f4U, 0xd1e5e534U, 0xf9f1f108U,
0xe2717193U, 0xabd8d873U, 0x62313153U, 0x2a15153fU,
0x0804040cU, 0x95c7c752U, 0x46232365U, 0x9dc3c35eU,
0x30181828U, 0x379696a1U, 0x0a05050fU, 0x2f9a9ab5U,
0x0e070709U, 0x24121236U, 0x1b80809bU, 0xdfe2e23dU,
0xcdebeb26U, 0x4e272769U, 0x7fb2b2cdU, 0xea75759fU,
0x1209091bU, 0x1d83839eU, 0x582c2c74U, 0x341a1a2eU,
0x361b1b2dU, 0xdc6e6eb2U, 0xb45a5aeeU, 0x5ba0a0fbU,
0xa45252f6U, 0x763b3b4dU, 0xb7d6d661U, 0x7db3b3ceU,
0x5229297bU, 0xdde3e33eU, 0x5e2f2f71U, 0x13848497U,
0xa65353f5U, 0xb9d1d168U, 0x00000000U, 0xc1eded2cU,
0x40202060U, 0xe3fcfc1fU, 0x79b1b1c8U, 0xb65b5bedU,
0xd46a6abeU, 0x8dcbcb46U, 0x67bebed9U, 0x7239394bU,
0x944a4adeU, 0x984c4cd4U, 0xb05858e8U, 0x85cfcf4aU,
0xbbd0d06bU, 0xc5efef2aU, 0x4faaaae5U, 0xedfbfb16U,
0x864343c5U, 0x9a4d4dd7U, 0x66333355U, 0x11858594U,
0x8a4545cfU, 0xe9f9f910U, 0x04020206U, 0xfe7f7f81U,
0xa05050f0U, 0x783c3c44U, 0x259f9fbaU, 0x4ba8a8e3U,
0xa25151f3U, 0x5da3a3feU, 0x804040c0U, 0x058f8f8aU,
0x3f9292adU, 0x219d9dbcU, 0x70383848U, 0xf1f5f504U,
0x63bcbcdfU, 0x77b6b6c1U, 0xafdada75U, 0x42212163U,
0x20101030U, 0xe5ffff1aU, 0xfdf3f30eU, 0xbfd2d26dU,
0x81cdcd4cU, 0x180c0c14U, 0x26131335U, 0xc3ecec2fU,
0xbe5f5fe1U, 0x359797a2U, 0x884444ccU, 0x2e171739U,
0x93c4c457U, 0x55a7a7f2U, 0xfc7e7e82U, 0x7a3d3d47U,
0xc86464acU, 0xba5d5de7U, 0x3219192bU, 0xe6737395U,
0xc06060a0U, 0x19818198U, 0x9e4f4fd1U, 0xa3dcdc7fU,
0x44222266U, 0x542a2a7eU, 0x3b9090abU, 0x0b888883U,
0x8c4646caU, 0xc7eeee29U, 0x6bb8b8d3U, 0x2814143cU,
0xa7dede79U, 0xbc5e5ee2U, 0x160b0b1dU, 0xaddbdb76U,
0xdbe0e03bU, 0x64323256U, 0x743a3a4eU, 0x140a0a1eU,
0x924949dbU, 0x0c06060aU, 0x4824246cU, 0xb85c5ce4U,
0x9fc2c25dU, 0xbdd3d36eU, 0x43acacefU, 0xc46262a6U,
0x399191a8U, 0x319595a4U, 0xd3e4e437U, 0xf279798bU,
0xd5e7e732U, 0x8bc8c843U, 0x6e373759U, 0xda6d6db7U,
0x018d8d8cU, 0xb1d5d564U, 0x9c4e4ed2U, 0x49a9a9e0U,
0xd86c6cb4U, 0xac5656faU, 0xf3f4f407U, 0xcfeaea25U,
0xca6565afU, 0xf47a7a8eU, 0x47aeaee9U, 0x10080818U,
0x6fbabad5U, 0xf0787888U, 0x4a25256fU, 0x5c2e2e72U,
0x381c1c24U, 0x57a6a6f1U, 0x73b4b4c7U, 0x97c6c651U,
0xcbe8e823U, 0xa1dddd7cU, 0xe874749cU, 0x3e1f1f21U,
0x964b4bddU, 0x61bdbddcU, 0x0d8b8b86U, 0x0f8a8a85U,
0xe0707090U, 0x7c3e3e42U, 0x71b5b5c4U, 0xcc6666aaU,
0x904848d8U, 0x06030305U, 0xf7f6f601U, 0x1c0e0e12U,
0xc26161a3U, 0x6a35355fU, 0xae5757f9U, 0x69b9b9d0U,
0x17868691U, 0x99c1c158U, 0x3a1d1d27U, 0x279e9eb9U,
0xd9e1e138U, 0xebf8f813U, 0x2b9898b3U, 0x22111133U,
0xd26969bbU, 0xa9d9d970U, 0x078e8e89U, 0x339494a7U,
0x2d9b9bb6U, 0x3c1e1e22U, 0x15878792U, 0xc9e9e920U,
0x87cece49U, 0xaa5555ffU, 0x50282878U, 0xa5dfdf7aU,
0x038c8c8fU, 0x59a1a1f8U, 0x09898980U, 0x1a0d0d17U,
0x65bfbfdaU, 0xd7e6e631U, 0x844242c6U, 0xd06868b8U,
0x824141c3U, 0x299999b0U, 0x5a2d2d77U, 0x1e0f0f11U,
0x7bb0b0cbU, 0xa85454fcU, 0x6dbbbbd6U, 0x2c16163aU,
};
我们可以看到的是上面的代码是Te0[]是去&&0x0000ff00,其实我们可以看到Te0表中的第三个字节其实是S盒
查表法实现AES加密:
void AES_encrypt(const unsigned char *in, unsigned char *out,
const AES_KEY *key) {
const u32 *rk;
u32 s0, s1, s2, s3, t0, t1, t2, t3;
#ifndef FULL_UNROLL
int r;
#endif /* ?FULL_UNROLL */
assert(in && out && key);
rk = key->rd_key;
/*
* map byte array block to cipher state
* and add initial round key:
*/
s0 = GETU32(in ) ^ rk[0];
s1 = GETU32(in + 4) ^ rk[1];
s2 = GETU32(in + 8) ^ rk[2];
s3 = GETU32(in + 12) ^ rk[3]; //初始的异或
#ifdef FULL_UNROLL
/* round 1: *///进行的轮加密
t0 = Te0[s0 >> 24] ^ Te1[(s1 >> 16) & 0xff] ^ Te2[(s2 >> 8) & 0xff] ^ Te3[s3 & 0xff] ^ rk[ 4];
t1 = Te0[s1 >> 24] ^ Te1[(s2 >> 16) & 0xff] ^ Te2[(s3 >> 8) & 0xff] ^ Te3[s0 & 0xff] ^ rk[ 5];
t2 = Te0[s2 >> 24] ^ Te1[(s3 >> 16) & 0xff] ^ Te2[(s0 >> 8) & 0xff] ^ Te3[s1 & 0xff] ^ rk[ 6];
t3 = Te0[s3 >> 24] ^ Te1[(s0 >> 16) & 0xff] ^ Te2[(s1 >> 8) & 0xff] ^ Te3[s2 & 0xff] ^ rk[ 7];
/* round 2: */
s0 = Te0[t0 >> 24] ^ Te1[(t1 >> 16) & 0xff] ^ Te2[(t2 >> 8) & 0xff] ^ Te3[t3 & 0xff] ^ rk[ 8];
s1 = Te0[t1 >> 24] ^ Te1[(t2 >> 16) & 0xff] ^ Te2[(t3 >> 8) & 0xff] ^ Te3[t0 & 0xff] ^ rk[ 9];
s2 = Te0[t2 >> 24] ^ Te1[(t3 >> 16) & 0xff] ^ Te2[(t0 >> 8) & 0xff] ^ Te3[t1 & 0xff] ^ rk[10];
s3 = Te0[t3 >> 24] ^ Te1[(t0 >> 16) & 0xff] ^ Te2[(t1 >> 8) & 0xff] ^ Te3[t2 & 0xff] ^ rk[11];
/* round 3: */
t0 = Te0[s0 >> 24] ^ Te1[(s1 >> 16) & 0xff] ^ Te2[(s2 >> 8) & 0xff] ^ Te3[s3 & 0xff] ^ rk[12];
t1 = Te0[s1 >> 24] ^ Te1[(s2 >> 16) & 0xff] ^ Te2[(s3 >> 8) & 0xff] ^ Te3[s0 & 0xff] ^ rk[13];
t2 = Te0[s2 >> 24] ^ Te1[(s3 >> 16) & 0xff] ^ Te2[(s0 >> 8) & 0xff] ^ Te3[s1 & 0xff] ^ rk[14];
t3 = Te0[s3 >> 24] ^ Te1[(s0 >> 16) & 0xff] ^ Te2[(s1 >> 8) & 0xff] ^ Te3[s2 & 0xff] ^ rk[15];
/* round 4: */
s0 = Te0[t0 >> 24] ^ Te1[(t1 >> 16) & 0xff] ^ Te2[(t2 >> 8) & 0xff] ^ Te3[t3 & 0xff] ^ rk[16];
s1 = Te0[t1 >> 24] ^ Te1[(t2 >> 16) & 0xff] ^ Te2[(t3 >> 8) & 0xff] ^ Te3[t0 & 0xff] ^ rk[17];
s2 = Te0[t2 >> 24] ^ Te1[(t3 >> 16) & 0xff] ^ Te2[(t0 >> 8) & 0xff] ^ Te3[t1 & 0xff] ^ rk[18];
s3 = Te0[t3 >> 24] ^ Te1[(t0 >> 16) & 0xff] ^ Te2[(t1 >> 8) & 0xff] ^ Te3[t2 & 0xff] ^ rk[19];
/* round 5: */
t0 = Te0[s0 >> 24] ^ Te1[(s1 >> 16) & 0xff] ^ Te2[(s2 >> 8) & 0xff] ^ Te3[s3 & 0xff] ^ rk[20];
t1 = Te0[s1 >> 24] ^ Te1[(s2 >> 16) & 0xff] ^ Te2[(s3 >> 8) & 0xff] ^ Te3[s0 & 0xff] ^ rk[21];
t2 = Te0[s2 >> 24] ^ Te1[(s3 >> 16) & 0xff] ^ Te2[(s0 >> 8) & 0xff] ^ Te3[s1 & 0xff] ^ rk[22];
t3 = Te0[s3 >> 24] ^ Te1[(s0 >> 16) & 0xff] ^ Te2[(s1 >> 8) & 0xff] ^ Te3[s2 & 0xff] ^ rk[23];
/* round 6: */
s0 = Te0[t0 >> 24] ^ Te1[(t1 >> 16) & 0xff] ^ Te2[(t2 >> 8) & 0xff] ^ Te3[t3 & 0xff] ^ rk[24];
s1 = Te0[t1 >> 24] ^ Te1[(t2 >> 16) & 0xff] ^ Te2[(t3 >> 8) & 0xff] ^ Te3[t0 & 0xff] ^ rk[25];
s2 = Te0[t2 >> 24] ^ Te1[(t3 >> 16) & 0xff] ^ Te2[(t0 >> 8) & 0xff] ^ Te3[t1 & 0xff] ^ rk[26];
s3 = Te0[t3 >> 24] ^ Te1[(t0 >> 16) & 0xff] ^ Te2[(t1 >> 8) & 0xff] ^ Te3[t2 & 0xff] ^ rk[27];
/* round 7: */
t0 = Te0[s0 >> 24] ^ Te1[(s1 >> 16) & 0xff] ^ Te2[(s2 >> 8) & 0xff] ^ Te3[s3 & 0xff] ^ rk[28];
t1 = Te0[s1 >> 24] ^ Te1[(s2 >> 16) & 0xff] ^ Te2[(s3 >> 8) & 0xff] ^ Te3[s0 & 0xff] ^ rk[29];
t2 = Te0[s2 >> 24] ^ Te1[(s3 >> 16) & 0xff] ^ Te2[(s0 >> 8) & 0xff] ^ Te3[s1 & 0xff] ^ rk[30];
t3 = Te0[s3 >> 24] ^ Te1[(s0 >> 16) & 0xff] ^ Te2[(s1 >> 8) & 0xff] ^ Te3[s2 & 0xff] ^ rk[31];
/* round 8: */
s0 = Te0[t0 >> 24] ^ Te1[(t1 >> 16) & 0xff] ^ Te2[(t2 >> 8) & 0xff] ^ Te3[t3 & 0xff] ^ rk[32];
s1 = Te0[t1 >> 24] ^ Te1[(t2 >> 16) & 0xff] ^ Te2[(t3 >> 8) & 0xff] ^ Te3[t0 & 0xff] ^ rk[33];
s2 = Te0[t2 >> 24] ^ Te1[(t3 >> 16) & 0xff] ^ Te2[(t0 >> 8) & 0xff] ^ Te3[t1 & 0xff] ^ rk[34];
s3 = Te0[t3 >> 24] ^ Te1[(t0 >> 16) & 0xff] ^ Te2[(t1 >> 8) & 0xff] ^ Te3[t2 & 0xff] ^ rk[35];
/* round 9: */
t0 = Te0[s0 >> 24] ^ Te1[(s1 >> 16) & 0xff] ^ Te2[(s2 >> 8) & 0xff] ^ Te3[s3 & 0xff] ^ rk[36];
t1 = Te0[s1 >> 24] ^ Te1[(s2 >> 16) & 0xff] ^ Te2[(s3 >> 8) & 0xff] ^ Te3[s0 & 0xff] ^ rk[37];
t2 = Te0[s2 >> 24] ^ Te1[(s3 >> 16) & 0xff] ^ Te2[(s0 >> 8) & 0xff] ^ Te3[s1 & 0xff] ^ rk[38];
t3 = Te0[s3 >> 24] ^ Te1[(s0 >> 16) & 0xff] ^ Te2[(s1 >> 8) & 0xff] ^ Te3[s2 & 0xff] ^ rk[39];
if (key->rounds > 10) {
/* round 10: */
s0 = Te0[t0 >> 24] ^ Te1[(t1 >> 16) & 0xff] ^ Te2[(t2 >> 8) & 0xff] ^ Te3[t3 & 0xff] ^ rk[40];
s1 = Te0[t1 >> 24] ^ Te1[(t2 >> 16) & 0xff] ^ Te2[(t3 >> 8) & 0xff] ^ Te3[t0 & 0xff] ^ rk[41];
s2 = Te0[t2 >> 24] ^ Te1[(t3 >> 16) & 0xff] ^ Te2[(t0 >> 8) & 0xff] ^ Te3[t1 & 0xff] ^ rk[42];
s3 = Te0[t3 >> 24] ^ Te1[(t0 >> 16) & 0xff] ^ Te2[(t1 >> 8) & 0xff] ^ Te3[t2 & 0xff] ^ rk[43];
/* round 11: */
t0 = Te0[s0 >> 24] ^ Te1[(s1 >> 16) & 0xff] ^ Te2[(s2 >> 8) & 0xff] ^ Te3[s3 & 0xff] ^ rk[44];
t1 = Te0[s1 >> 24] ^ Te1[(s2 >> 16) & 0xff] ^ Te2[(s3 >> 8) & 0xff] ^ Te3[s0 & 0xff] ^ rk[45];
t2 = Te0[s2 >> 24] ^ Te1[(s3 >> 16) & 0xff] ^ Te2[(s0 >> 8) & 0xff] ^ Te3[s1 & 0xff] ^ rk[46];
t3 = Te0[s3 >> 24] ^ Te1[(s0 >> 16) & 0xff] ^ Te2[(s1 >> 8) & 0xff] ^ Te3[s2 & 0xff] ^ rk[47];
if (key->rounds > 12) {
/* round 12: */
s0 = Te0[t0 >> 24] ^ Te1[(t1 >> 16) & 0xff] ^ Te2[(t2 >> 8) & 0xff] ^ Te3[t3 & 0xff] ^ rk[48];
s1 = Te0[t1 >> 24] ^ Te1[(t2 >> 16) & 0xff] ^ Te2[(t3 >> 8) & 0xff] ^ Te3[t0 & 0xff] ^ rk[49];
s2 = Te0[t2 >> 24] ^ Te1[(t3 >> 16) & 0xff] ^ Te2[(t0 >> 8) & 0xff] ^ Te3[t1 & 0xff] ^ rk[50];
s3 = Te0[t3 >> 24] ^ Te1[(t0 >> 16) & 0xff] ^ Te2[(t1 >> 8) & 0xff] ^ Te3[t2 & 0xff] ^ rk[51];
/* round 13: */
t0 = Te0[s0 >> 24] ^ Te1[(s1 >> 16) & 0xff] ^ Te2[(s2 >> 8) & 0xff] ^ Te3[s3 & 0xff] ^ rk[52];
t1 = Te0[s1 >> 24] ^ Te1[(s2 >> 16) & 0xff] ^ Te2[(s3 >> 8) & 0xff] ^ Te3[s0 & 0xff] ^ rk[53];
t2 = Te0[s2 >> 24] ^ Te1[(s3 >> 16) & 0xff] ^ Te2[(s0 >> 8) & 0xff] ^ Te3[s1 & 0xff] ^ rk[54];
t3 = Te0[s3 >> 24] ^ Te1[(s0 >> 16) & 0xff] ^ Te2[(s1 >> 8) & 0xff] ^ Te3[s2 & 0xff] ^ rk[55];
}
}
rk += key->rounds << 2;
openssl 的 EVP 使用
https://blog.csdn.net/liao20081228/article/details/76285896/
EVP_CIPHER_CTX_init
EVP_EncryptInit_ex 、 EVP_EncryptUpdate 、 EVP_EncryptFinal_ex
EVP_CIPHER_CTX_cleanup
EVP_aes_128_cbc
白盒加密
将密钥固定下来,并且融合到算法中(静态的白盒密钥就保存在AES的表中,但是很难找得到)
也可以理解成在查表法的基础上,将算法的密钥扩展步骤也省掉
缺点是需要的表更大,更占内存,优点是攻击者很难拿到原始的密钥
白盒加密的表通常是不固定的,因为内置的密钥是不一样的
攻击者很难拿到原始密钥,一般会选择抠代码。当存在混淆
的时候,抠代码也会显得非常艰难。这就是一种保护



