
如果在循环中不改变vector的大小,C++编译器是否会将.size()优化为常数?
 如果在循环中不改变vector的大小,C++编译器是否会将.size()优化为常数?
如果在循环中不改变vector的大小,C++编译器是否会将.size()优化为常数?
在C++中,可以使用以下代码计算vector<int>中所有元素的和:
vector<int> v = {1, 3, 7, 9};
sums = 0;
for (int i = 0; i < v.size(); i++) {
sums += v[i];
} 这是一段很普通的代码,问题在于:在这段代码中,v.size()会在循环开始前仅计算一次?还是会在每次循环中都计算一次?以前我总觉得,这段代码没有改变v的大小,既然我都能看出来,编译器一定也知道,从而会在循环开始前就把v.size()计算出来,之后的每次循环中,直接使用计算出的值,以减少函数调用的开销。但事实果真如此吗?
使用g++编译上面这段代码,得到的结果如下:

可以看到,每次循环时会调用v.size()获取vector大小。使用clang编译后的代码也大致类似,也会在每次循环调用v.size()获取大小:

但这是否就意味着我想错了呢?并非如此。事实上,大家可能忽略了编译器有不同的优化等级,默认情况下,编译器会忠实地按照源代码的描述编译代码。当我们开启更高级别的优化时,就会得到“源代码来了也认不出”的编译结果:

这里使用clang编译器编译并启用了-O2级别的优化。是的,你没有看错,启用此级别的优化后,循环直接被优化掉了。因为这里的vector<int>中只有4个固定的元素,因此编译器直接使用xmm(一种宽度为128位的加宽寄存器)替代了求和的循环。
为了搞清楚启用优化后.size()是否会被提前计算出,我们创建一个更大的vector:
vector<int> v {};
for (int i = 0; i < 500; i++) {
v.push_back(i);
}
int sums = 0;
for (std::size_t i = 0; i < v.size(); i++) {
sums += v[i];
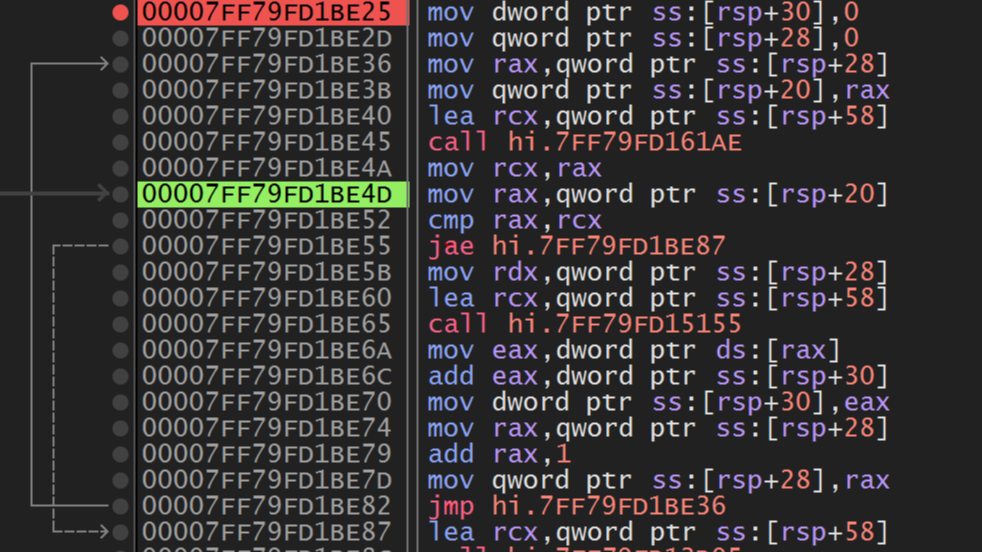
} 启用-O2级别的优化后,与求和循环相关的代码如下图所示:

可以看到:v.size()会在循环开始前计算出,并保存到寄存器rdx中。在每次循环中,vector的索引(保存在r8中)直接与寄存器rdx中的值进行比较。
由于优化后使用的是128位的xmm寄存器,因此每次循环时r8会加上8.(一个xmm可以保存4个int,以上循环中每轮读取2次数据到xmm2中,因此共4x2=8个int数据)
因此,在上述代码中,编译器是否会提前计算出.size()取决于启用优化的等级。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号