

2024 NJU PA1.3
本节主要实现监视点,在此之前,需要扩展表达式的求值功能。
扩充表达式
当前的表达式求值仅支持算术求值,但我们还会用到一些复杂功能,包括:
- 布尔表达式:包括
==, !=, &&. - 寄存器:例如
$a0. - 解引用:
* addr. 和它类似的还有之前遗漏的负数表达式,例如3 - -4.
我们一个一个来。
布尔表达式
这个比较简单,打开文件$NEMU_HOME/src/monitor/sdb/expr.c, 定义新的TK_XXX类型,并在数组rules中添加对应规则:
enum {
TK_NOTYPE = 256, TK_EQ,
...
TK_NE,
TK_AND,
};
rules [] = {
...
{"!=", TK_NE},
{"&&", TK_AND},
};之后还需要在函数make_token中记录识别出的token:(以下所有代码基于PA 1.2的实现修改,仅供参考)
switch (rules[i].token_type) {
...
case '(':
case ')':
case TK_EQ: // 新添加的3行
case TK_NE: // 非常简单
case TK_AND: // 几乎没有大的改动
Assert(nr_token < 32, "token should less than 32");
...
}另外,还要为新添加的运算符实现相应的计算逻辑,这个应当写在PA 1.2中计算加减乘除的位置:
switch (tokens[r].type) {
case '+': return value_left + value_right;
...
case TK_EQ: return value_left == value_right; // 以下3行为新添加的处理逻辑
case TK_NE: return value_left != value_right;
case TK_AND: return value_left && value_right;
...
}需要注意的是,代码中所有与之相关的代码都需要修改,这取决于你的具体实现。例如,我之前定义了函数priority用于确定主运算符的优先级,添加新的运算符后,这个函数也需要修改:
priority
static int priority(int operator) {
switch (operator) {
case TK_AND:
return 0;
case TK_EQ:
case TK_NE:
return 1;
case '+':
case '-':
return 2;
case '*':
case '/':
return 3;
default:
assert(0);
}
}另外,函数find_main_operator_index也要作修改:
find_main_operator_index
static int find_main_operator_index(int p, int q) {
...
for (int i = p; i <= q; i++) {
int operator = tokens[i].type;
switch (operator) {
...
case '*':
case '/':
case TK_EQ: // 以下3行为新添加的代码
case TK_NE:
case TK_AND:
...
}这部分完成后,重新编译并使用指令p测试下,例如p 3 == 3, 结果正确的话就没问题。

寄存器
在PA 1.1中,我们已经实现了通过寄存器名获取寄存器值的函数isa_reg_str2val,它位于$NEMU_HOME/src/isa/riscv32/reg.c. 另外,在此文件中,我们还看到了riscv中寄存器的名字:
const char *regs[] = {
"$0", "ra", "sp", "gp", "tp", "t0", "t1", "t2",
"s0", "s1", "a0", "a1", "a2", "a3", "a4", "a5",
"a6", "a7", "s2", "s3", "s4", "s5", "s6", "s7",
"s8", "s9", "s10", "s11", "t3", "t4", "t5", "t6"
};现在需要为寄存器添加正则表达式,从而能在词法分析中识别出寄存器,手册要求使用寄存器时以$开头,例如ra寄存器在使用时应当写作$ra.
和之前一样,添加类型TK_REG、规则{"\\$(\\$0|ra|sp|gp|tp|t[0-6]|s[0-9]|s10|s11|a[0-7])", TK_REG}, 在函数make_token中识别出此类型的token:
switch (rules[i].token_type) {
case TK_HEX:
case TK_UINT:
case TK_REG: // TK_REG需要保存寄存器字符串,所以写在此处
...最后,在将十六进制、十进制字符串转化为整数的位置,添加将寄存器名转化为寄存器值的代码:
switch (tokens[p].type) {
...
case TK_UINT:
sscanf(tokens[p].str, "%d", &result);
return result;
case TK_REG: // 新添加的2行代码
return isa_reg_str2val(tokens[p].str + 1, success);
...
}这里需要额外说明下,调用isa_reg_str2val时,传入的字符串是tokens[p].str + 1. 由于表达式读取的寄存器前面有个$, 而函数isa_reg_str2val接受的寄存器名不带有这个$, 所以有了+1, 如果tokens[p].str保存的是字符串"$ra", tokens[p].str+1就是字符串"ra"了。
完成后,输入p $ra之类的指令试一试。
解引用
解引用运算符用于读取某个内存地址的值,例如*0x80000000表示获取内存地址为0x80000000的值。解引用运算符和乘号是同一个符号,这涉及到运算符的二义性问题,减号(负号)也有这样的问题,因此我们在这里一并处理。
判断的关键在于根据符号所处的上下文。例如,3 * 4中的*是乘号,而 3 + *$ra的*则是解引用。从而,我们发现,如果*的左边是运算符,或者*的左边没有任何token(例如*$ra + 3), 那么它就是解引用运算符。这同样适用于减号。
首先定义解引用类型TK_DEREF、负号类型TK_NEG. 我们把判断的逻辑放在make_token中:
case TK_EQ:
case TK_NE:
case TK_AND:
Assert(nr_token < 32, "token should less than 32");
tokens[nr_token].type = rules[i].token_type;
// 以下为新添加的代码
int current_token = rules[i].token_type; // 获取当前token的类型
if (current_token == '*' || current_token == '-') { // 如果当前token为 * 或 -, 需要根据前一个token的类型判断其含义
int tk = nr_token == 0 ? -1 : tokens[nr_token - 1].type; // 前一个token的类型
if (nr_token == 0 || tk == '+' || tk == '-'
|| tk == '*' || tk == '/' || tk == '(' // 注意:右括号不在其中!!!
|| tk == TK_EQ || tk == TK_NE || tk == TK_AND) {
tokens[nr_token].type = current_token == '*' ? TK_DEREF : TK_NEG;
}
}
nr_token++;
break;
default:
...接下来实现它们的求值逻辑。首先处理它们的优先级:
static int priority(int operator) {
...
case '*':
case '/':
return 3;
case TK_DEREF: // 以下3行为新添加的代码
case TK_NEG:
return 4;
...
}
static int find_main_operator_index(int p, int q) {
...
case TK_EQ:
case TK_NE:
case TK_AND:
case TK_DEREF: // 以下2行为新添加的代码
case TK_NEG:
...
} 由于这两个操作符只需要右侧的操作数,我们调整了求值的顺序:
word_t eval_expr(int p, int q, bool *success) {
...
word_t value_right = eval_expr(r+1, q, success); // 先计算右侧的表达式
if (*success == false) {
return 0;
}
if (tokens[r].type == TK_DEREF) { // 如果是解引用运算符
return vaddr_read(value_right, 4); // 使用vaddr_read读取内存并返回即可
}
if (tokens[r].type == TK_NEG) { // 如果是负号
return -value_right; // 取反并返回即可
}
word_t value_left = eval_expr(p, r-1, success); // 如有需要,再计算左侧的表达式
...
}完成后编译代码(如果遇到报错:未定义vaddr_read,在文件中添加此函数的声明即可),如果一切顺利,可以测试类似p 3 --4, p *0x80000000(结果应当为663, 即十六进制的0x297)的表达式:

在PA 1.1实现指令x时,我们曾假设表达式必须是十六进制。但现在,我们可以通过调用函数expr计算任意表达式的值,在cmd_x中调用函数expr即可。
完整代码
由于这一部分的代码在之前的代码上修改而来,为了避免误导读者,我把表达式求值的相关代码贴在这里,还是那句老话,仅供参考。
$NEMU_HOME/src/monitor/sdb/expr.c
/***************************************************************************************
* Copyright (c) 2014-2024 Zihao Yu, Nanjing University
*
* NEMU is licensed under Mulan PSL v2.
* You can use this software according to the terms and conditions of the Mulan PSL v2.
* You may obtain a copy of Mulan PSL v2 at:
* http://license.coscl.org.cn/MulanPSL2
*
* THIS SOFTWARE IS PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND,
* EITHER EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO NON-INFRINGEMENT,
* MERCHANTABILITY OR FIT FOR A PARTICULAR PURPOSE.
*
* See the Mulan PSL v2 for more details.
***************************************************************************************/
#include <isa.h>
/* We use the POSIX regex functions to process regular expressions.
* Type 'man regex' for more information about POSIX regex functions.
*/
#include <regex.h>
enum {
TK_NOTYPE = 256, TK_EQ,
/* TODO: Add more token types */
TK_UINT,
TK_HEX,
TK_NE,
TK_AND,
TK_REG,
TK_DEREF,
TK_NEG,
};
static struct rule {
const char *regex;
int token_type;
} rules[] = {
/* TODO: Add more rules.
* Pay attention to the precedence level of different rules.
*/
{" +", TK_NOTYPE}, // spaces
{"\\+", '+'}, // plus
{"==", TK_EQ}, // equal
{"-", '-'},
{"\\*", '*'},
{"/", '/'},
{"\\(", '('},
{"\\)", ')'},
{"0x[0-9AaBbCcDdEeFf]+", TK_HEX},
{"[0-9]+", TK_UINT},
{"!=", TK_NE},
{"&&", TK_AND},
{"\\$(\\$0|ra|sp|gp|tp|t[0-6]|s[0-9]|s10|s11|a[0-7])", TK_REG},
};
#define NR_REGEX ARRLEN(rules)
static regex_t re[NR_REGEX] = {};
/* Rules are used for many times.
* Therefore we compile them only once before any usage.
*/
void init_regex() {
int i;
char error_msg[128];
int ret;
for (i = 0; i < NR_REGEX; i ++) {
ret = regcomp(&re[i], rules[i].regex, REG_EXTENDED);
if (ret != 0) {
regerror(ret, &re[i], error_msg, 128);
panic("regex compilation failed: %s\n%s", error_msg, rules[i].regex);
}
}
}
typedef struct token {
int type;
char str[32];
} Token;
static Token tokens[32] __attribute__((used)) = {};
static int nr_token __attribute__((used)) = 0;
static bool make_token(char *e) {
int position = 0;
int i;
regmatch_t pmatch;
nr_token = 0;
while (e[position] != '\0') {
/* Try all rules one by one. */
for (i = 0; i < NR_REGEX; i ++) {
if (regexec(&re[i], e + position, 1, &pmatch, 0) == 0 && pmatch.rm_so == 0) {
char *substr_start = e + position;
int substr_len = pmatch.rm_eo;
Log("match rules[%d] = \"%s\" at position %d with len %d: %.*s",
i, rules[i].regex, position, substr_len, substr_len, substr_start);
position += substr_len;
/* TODO: Now a new token is recognized with rules[i]. Add codes
* to record the token in the array `tokens'. For certain types
* of tokens, some extra actions should be performed.
*/
switch (rules[i].token_type) {
case TK_NOTYPE: break;
case TK_HEX:
case TK_UINT:
case TK_REG:
Assert(substr_len < 32, "token should less than 32 characters");
strncpy(tokens[nr_token].str, substr_start, substr_len);
tokens[nr_token].str[substr_len] = '\0';
case '+':
case '-':
case '*':
case '/':
case '(':
case ')':
case TK_EQ:
case TK_NE:
case TK_AND:
Assert(nr_token < 32, "token should less than 32");
tokens[nr_token].type = rules[i].token_type;
int current_token = rules[i].token_type;
if (current_token == '*' || current_token == '-') {
int tk = nr_token == 0 ? -1 : tokens[nr_token - 1].type;
if (nr_token == 0 || tk == '+' || tk == '-'
|| tk == '*' || tk == '/' || tk == '('
|| tk == TK_EQ || tk == TK_NE || tk == TK_AND) {
tokens[nr_token].type = current_token == '*' ? TK_DEREF : TK_NEG;
}
}
nr_token++;
break;
default:
Assert(false, "unknow token type %d", rules[i].token_type);
}
break;
}
}
if (i == NR_REGEX) {
printf("no match at position %d\n%s\n%*.s^\n", position, e, position, "");
return false;
}
}
return true;
}
static bool is_paired(int p, int q) {
if (tokens[p].type != '(' && tokens[q].type != ')') {
return false;
}
int n_left = 0;
for (int i = p+1; i <= q-1; i++) {
if (tokens[i].type == '(') {
n_left++;
}
else if (tokens[i].type == ')') {
n_left--;
if (n_left < 0) {
return false;
}
}
}
return n_left == 0;
}
static int priority(int operator) {
switch (operator) {
case TK_AND:
return 0;
case TK_EQ:
case TK_NE:
return 1;
case '+':
case '-':
return 2;
case '*':
case '/':
return 3;
case TK_DEREF:
case TK_NEG:
return 4;
default:
assert(0);
}
}
static int find_main_operator_index(int p, int q) {
int main_operator_index = -1;
int main_operator = -1;
int n_left = 0;
for (int i = p; i <= q; i++) {
int operator = tokens[i].type;
switch (operator) {
case '(':
n_left++;
break;
case ')':
n_left--;
break;
case '+':
case '-':
case '*':
case '/':
case TK_EQ:
case TK_NE:
case TK_AND:
case TK_DEREF:
case TK_NEG:
if (n_left == 0 &&
(main_operator_index == -1 ||
priority(operator) <= priority(main_operator))) {
main_operator_index = i;
main_operator = operator;
}
break;
default:
break;
}
}
return main_operator_index;
}
word_t vaddr_read(vaddr_t, int);
word_t eval_expr(int p, int q, bool *success) {
if (p > q) {
*success = false;
return 0;
}
else if (p == q) {
*success = true;
word_t result = 0;
switch (tokens[p].type) {
case TK_HEX:
sscanf(tokens[p].str, "%x", &result);
return result;
case TK_UINT:
sscanf(tokens[p].str, "%d", &result);
return result;
case TK_REG:
return isa_reg_str2val(tokens[p].str + 1, success);
default:
Assert(false, "error token type %d", tokens[p].type);
}
}
else if (is_paired(p, q)) {
return eval_expr(p+1, q-1, success);
}
// else
*success = true;
int r = find_main_operator_index(p, q);
if (r < 0) {
printf("can't find main operator\n");
*success = false;
return 0;
}
word_t value_right = eval_expr(r+1, q, success);
if (*success == false) {
return 0;
}
if (tokens[r].type == TK_DEREF) {
return vaddr_read(value_right, 4);
}
if (tokens[r].type == TK_NEG) {
return -value_right;
}
word_t value_left = eval_expr(p, r-1, success);
if (*success == false) {
return 0;
}
switch (tokens[r].type) {
case '+': return value_left + value_right;
case '-': return value_left - value_right;
case '*': return value_left * value_right;
case '/': return value_left / value_right;
case TK_EQ: return value_left == value_right;
case TK_NE: return value_left != value_right;
case TK_AND: return value_left && value_right;
default: assert(0);
}
}
word_t expr(char *e, bool *success) {
if (!make_token(e)) {
*success = false;
return 0;
}
/* TODO: Insert codes to evaluate the expression. */
return eval_expr(0, nr_token-1, success);
}监视点
监视点的原理很简单:指定一个表达式,每当CPU执行一条指令后就对此表达式进行计算,如果计算结果与之前相比发生变化,那么就暂停程序。由于我们已经实现了表达式求值的功能,因此接下来的工作主要放在监视点的管理上。
与监视点有关的指令有以下3个:
| 指令名称 | 功能 | 示例 | 备注 |
w [expr] |
设置监视点 | w *0x2000 |
|
d [n] |
删除序号为 |
d 2 |
|
info w |
输出监视点的状态 |
手册要求我们使用对象池管理监视点。
对象池
通常,操作系统会将堆划分为不同大小的块,例如1KB,4KB,1MB大小的内存各若干,当用户使用
malloc申请内存时,操作系统会寻找满足需求的最小内存块。具体细节在操作系统的课程还会学习,写出这些主要是让大家感受下申请堆区内存的复杂性。
有些时候,我们需要频繁申请特定大小的内存,例如有一个结构体
Data, 我们在程序中会频繁申请/释放此结构体。既然如此,与其每次让操作系统管理内存,我们为何不自行管理内存呢?也就是说,我们首先申请一块大内存,例如sizeof(Data) * 32, 实际上是一个大小为32的Data结构体数组;每次申请内存时,就在此数组中寻找一块未使用的空间,从而避免了频繁申请内存,提升了效率。这便是对象池的概念。
监视点API
为了实现表格中的几条指令,首先设计一组API:
add_watchpoint(char* expr): 给定表达式expr, 添加一个监视点,用于实现指令w.delete_watchpoint(int no):删除编号no对应的监视点,用于实现指令d.print_watchpoint():输出所有的监视点信息,用于实现指令info w.
打开文件$NEMU_HOME/src/monitor/sdb/watchpoint.c, 首先需要为结构体struct watchpoint添加成员。目前只有编号NO和指向下一个结构体的指针,根据监视点的要求,至少还需要保存表达式和表达式的旧值:
typedef struct watchpoint {
int NO;
struct watchpoint *next;
/* TODO: Add more members if necessary */
char str[128]; // 保存表达式,128应该够大了吧?哈哈哈哈
word_t old_value; // 保存表达式的旧值
} WP;接下来是常见的链表操作,没什么好说的(框架已经实现了初始化函数init_wp_pool):
$NEMU_HOME/src/monitor/sdb/watchpoint.c
void add_watchpoint(char *str) {
Assert(free_ != NULL, "sorry, no free memory for new watchpoint");
bool success = false;
int value = expr(str, &success);
if (!success) {
printf("error: wrong expression %s\n", str);
return;
}
WP *ptr = free_;
free_ = free_->next;
int str_length = strlen(str);
strncpy(ptr->str, str, str_length);
ptr->str[str_length] = '\0';
ptr->old_value = value;
ptr->next = head;
head = ptr;
printf("Watchpoint %d: %s\n", ptr->NO, ptr->str);
}
void delete_watchpoint(int no) {
if (head->NO == no) {
WP *tmp = head;
head = head->next;
tmp->next = free_;
free_ = tmp;
}
else {
WP *ptr = head;
while (ptr->next) {
if (ptr->next->NO == no) {
WP *tmp = ptr->next;
ptr->next = tmp->next;
tmp->next = free_;
free_ = tmp;
break;
}
ptr = ptr->next;
}
}
}
void print_watchpoint() {
if (head == NULL) {
printf("No watchpoints.\n");
return;
}
printf("Num\t\tWhat\n");
WP *ptr = head;
while (ptr) {
printf("%d\t\t%s\n", ptr->NO, ptr->str);
ptr = ptr->next;
}
}有了这些API, 就可以实现指令w, d和info w. 想必大家对这套流程已经十分熟悉了吧,已经写吐了,不想再写了。
更新监视点
前面提到,当监视点的表达式取值变化时,需要暂停程序。因此我们需要提供一个新的API,在CPU每执行完一条指令后调用它,检查监视点的值是否发生变化。此API定义如下:
int update_watchpoint()
此API的返回值表示发生变化的监视点个数。一旦返回值大于0,就暂停程序的运行。实现如下:
int update_watchpoint() {
int n_changed = 0;
WP *ptr = head;
while (ptr != NULL) {
bool success = false;
word_t value = expr(ptr->str, &success);
Assert(success, "wrong expression %s\n", ptr->str);
if (value != ptr->old_value) {
n_changed += 1;
printf("Watchpoint %d: %s\n", ptr->NO, ptr->str);
printf(" Old value = 0x%08x(%d)\n", ptr->old_value, ptr->old_value);
printf(" New value = 0x%08x(%d)\n", value, value);
ptr->old_value = value;
}
ptr = ptr->next;
}
return n_changed;
}在函数trace_and_difftest($NEMU_HOME/src/cpu/cpu-exec.c)的末尾调用此函数:
if (update_watchpoint() > 0) {
nemu_state.state = NEMU_STOP;
}暂停程序运行,是通过改变nemu的状态实现的。PA 1.1曾提到,程序会反复检查nemu_state.state. 另外注意NEMU_STOP与NEMU_ABORT的区别。
到这里已经差不多可以收工了,重新编译下,但愿一切顺利。
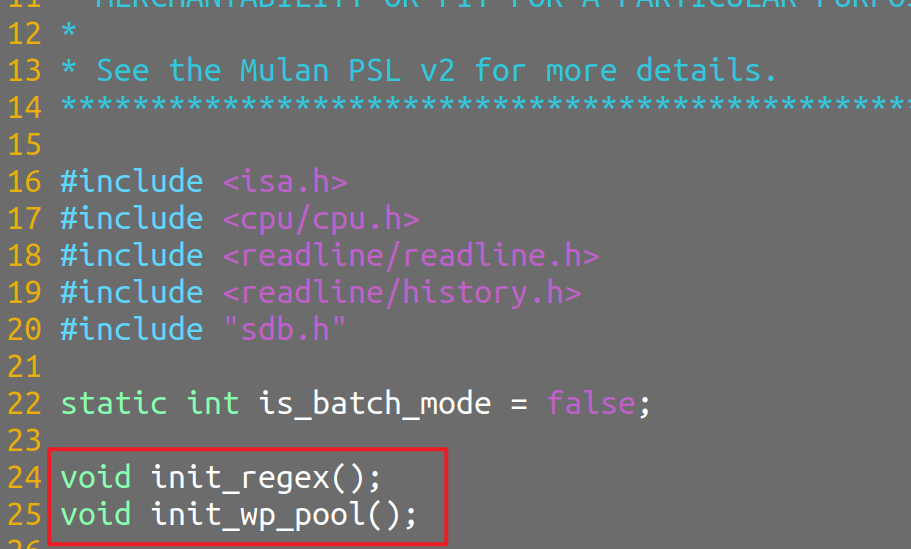
提示
如果出现报错:未定义的函数XXX,在报错的文件添加函数声明即可。类似下图红框框出的部分:
等学到符号链接时,就全懂了。
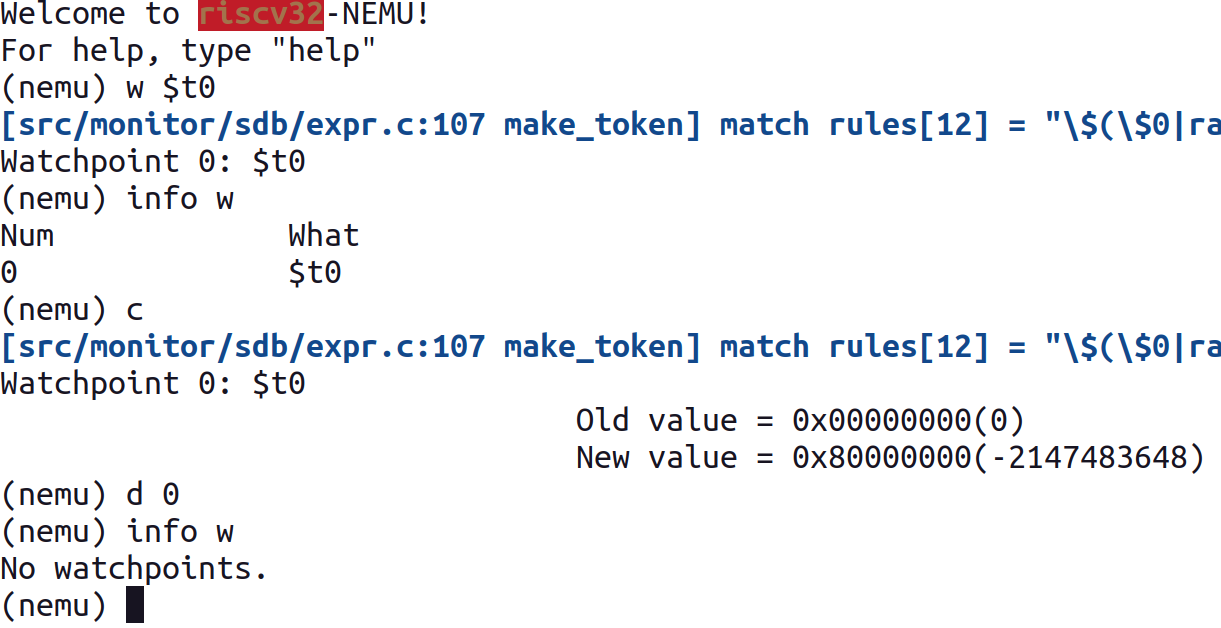
简单通过以下几个步骤测试下:
- 输入
w $t0, 设置一个监视点; - 输入
info w查看监视点; - 再输入指令
c(继续运行程序),程序应该会在执行一条指令后停止,并输出监视点的旧值、新值; - 接下来输入
d 0删除监视点; - 最后输入
info w, 应该会提示没有监视点。
设置编译选项
到这里其实已经结束了。不过,每执行完一条指令就检查所有的监视点,这听上去开销很大。为此,我们可以设置一个选项:只有开启此选项,才会启用监视点功能。
首先,打开$NEMU_HOME/Kconfig, 在适当的位置写入新的选项:
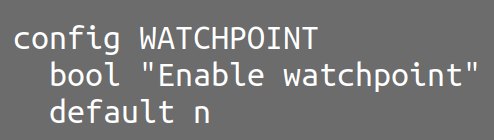
照葫芦画瓢写一个就好,此变量为bool类型,默认为不选中(default n),不必细究其含义。不过注意menu与endmenu确定了一个菜单界面,我写在了菜单Testing and Debugging内。
之后,运行make menuconfig, 就能在Testing and Debugging目录下找到此选项:
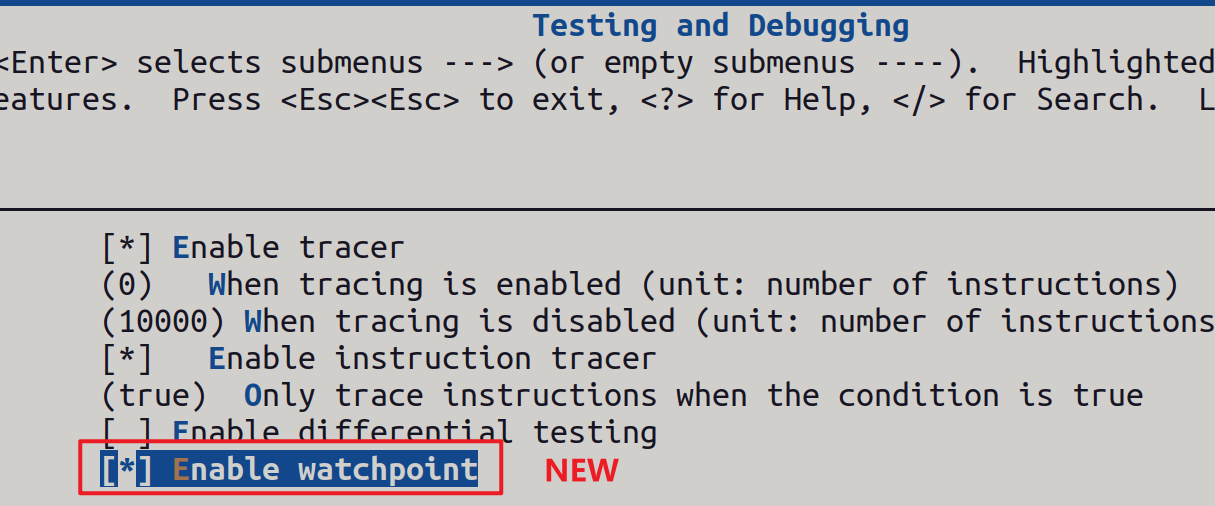
这会生成一个名为CONFIG_WATCHPOINT的宏,把之前调用update_watchpoint的代码套在这个宏里即可:
#ifdef CONFIG_WATCHPOINT
if (update_watchpoint() > 0) {
nemu_state.state = NEMU_STOP;
}
#endif现在,只有启用此开关,才会调用这部分代码。
OK,PA 1到此为止,拜拜!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步