【CV】吴恩达机器学习课程笔记第18章 | CSDN创作打卡
本系列文章如果没有特殊说明,正文内容均解释的是文字上方的图片
机器学习 | Coursera
吴恩达机器学习系列课程_bilibili
目录
18 应用案例:照片OCR
18-1 问题描述与流程(pipeline)
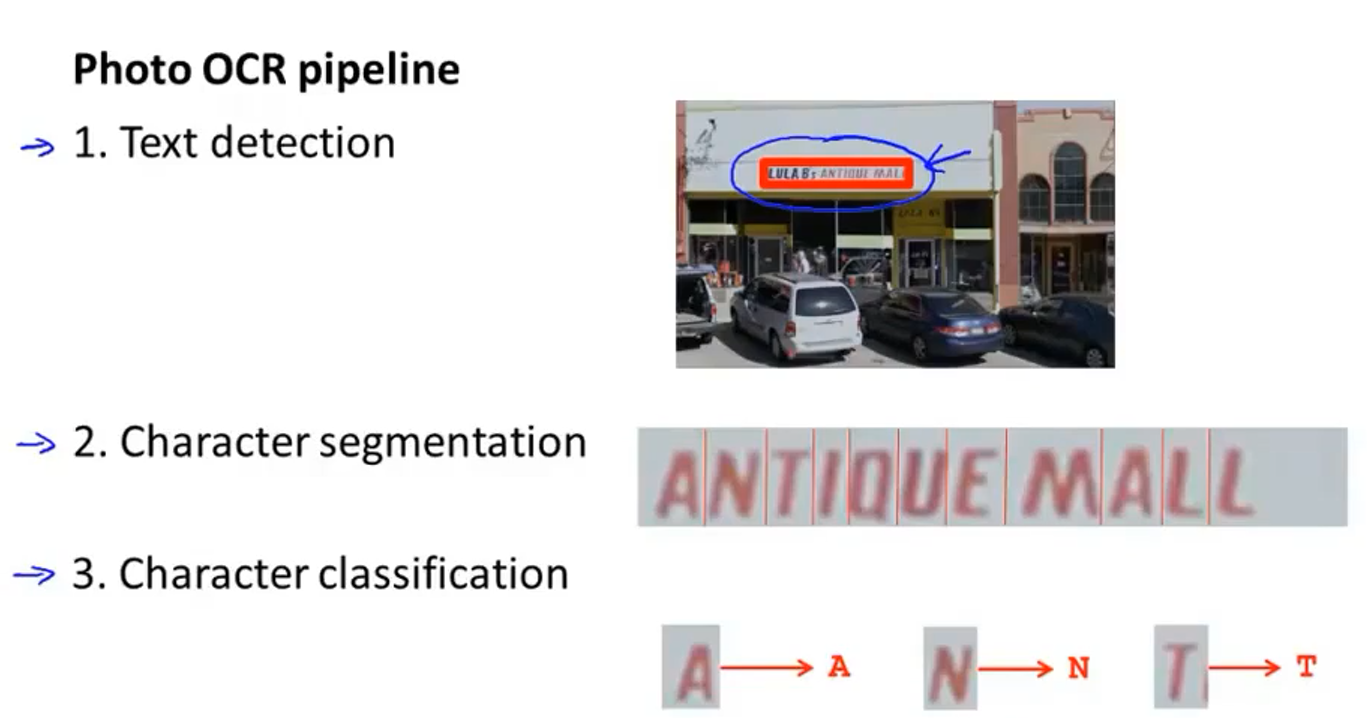
1.找到一张图片
2.首先识别出文字区域
3.然后分割出单独文字
4.最后运用分类器识别出文字
以上称为机器学习流水线,每一步都是一个机器学习模块
18-2 滑动窗口(sliding windows)分类器
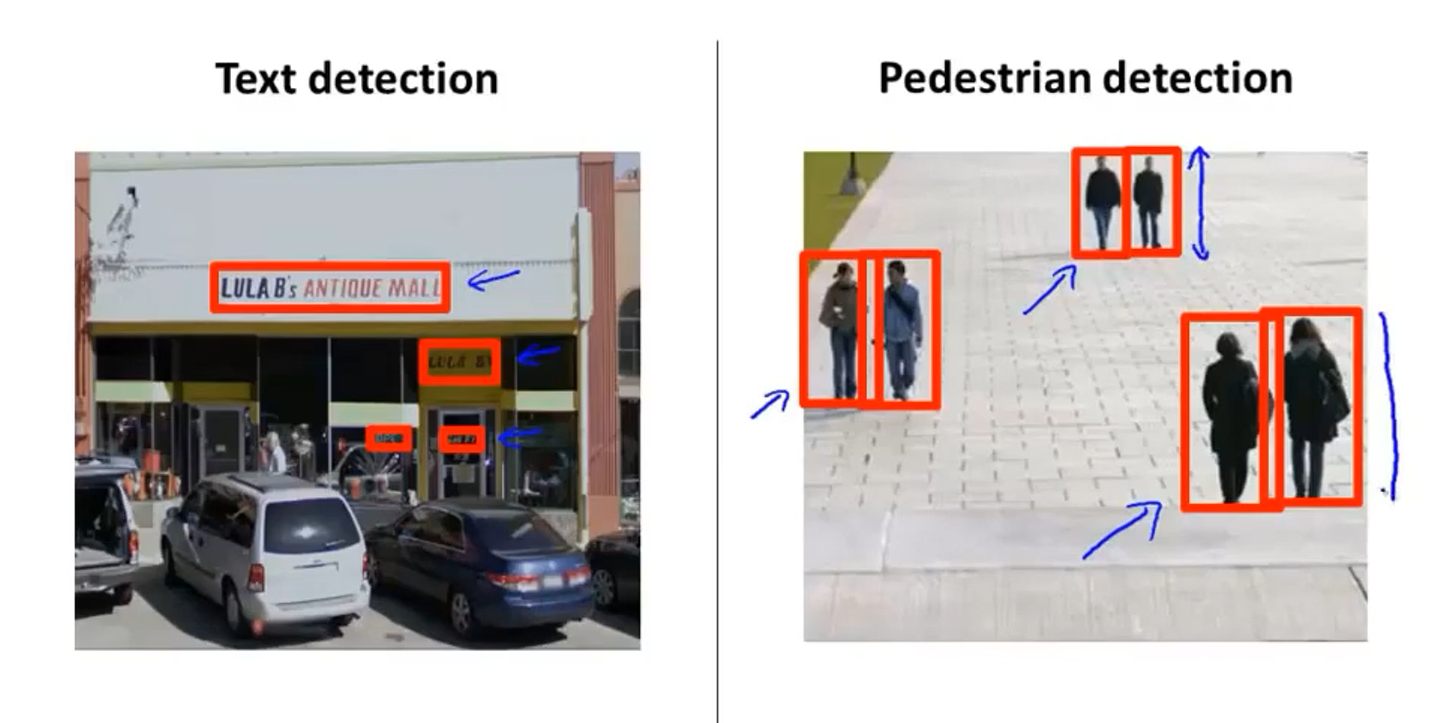
在文字区域检测模块中,要识别文字区域比较困难,因为文字区域的长宽比是不定的
而在行人检测中,人的矩形的长宽比通常是相似的,先从行人检测说起

假定用一个82×36的矩形来框定目标,则有一些正样本(y=1)和负样本(y=0),这样就可以应用监督学习

要在上图中找到行人,先在左上角框定一个符合比例的矩形,传递给检测器检测是否是行人,显然不是,所以向右移动一个距离(称为步长,一般为4-8像素),这样不断遍历整个图像,遍历完后,再换一个稍大一点的相同比例的矩形再遍历图像,这样不断循环就能找到图中的行人

在OCR中,同样需要拿出一些正样本和负样本来训练
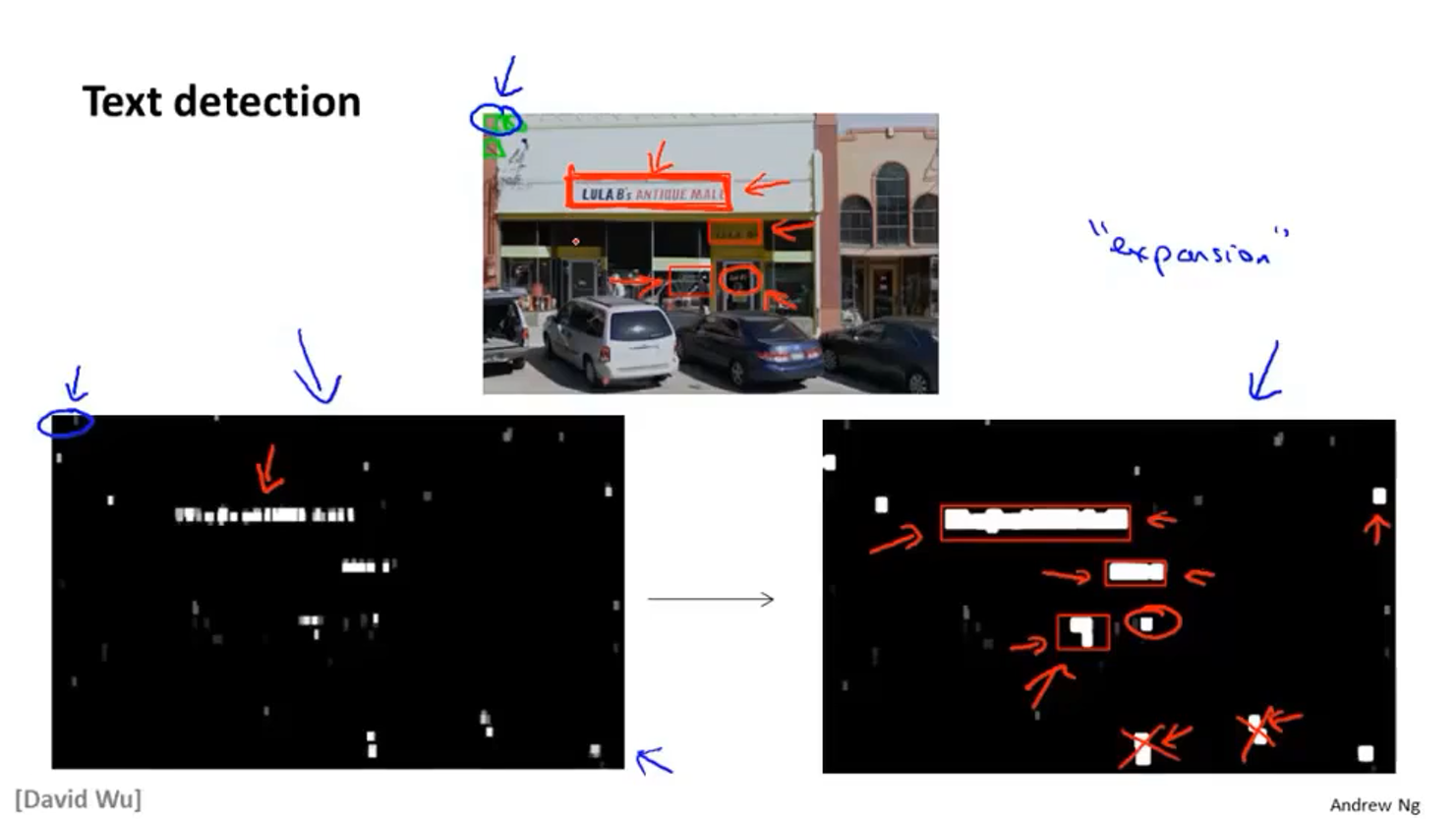
任然通过用矩形遍历的方式遍历整个图像,遍历完后的输出结果如上图左下角所示,白色表示分类器输出了很高的概率,灰色表示概率相对比较低一些,黑色表示输出的概率极低,通过图像膨胀算法变为右下角的图,然后将比例正常(瘦高的矩形肯定不是文字区域)的矩形框出来就是文字区域
然后到第二个模块↓↓

- 再次训练一个分类器,正样本为有文字分割区域的样本,负样本为没有分割区域,是整个文字的样本
- 训练完后再用一个矩形遍历文字区域的图像,找出完整的文字
最后训练一个能够识别文字的分类器即可一个个识别出文字
18-3 获取大量数据和人工数据合成
方法1:人造数据:自己从零制作数据集
方法2:扩充数据集
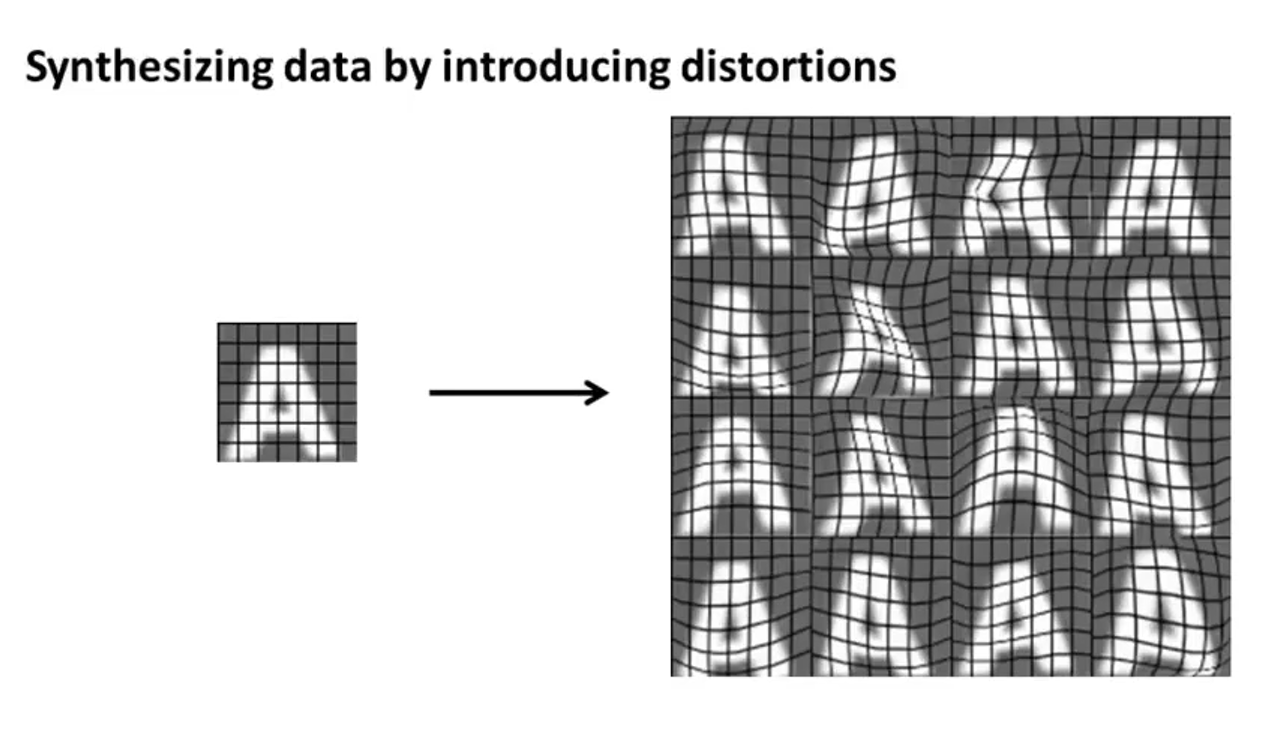
通过对一张图进行扭曲等操作将这一个样本变为了16个样本

在声音识别中通过增加背景音或噪音等方式人工制造失真来扩充数据集

上图的上半部分:在图像中添加一些在实际中可能出现的情况是正确的
上图的下半部分:在图像中添加噪声很可能是没有意义的

获取数据的建议:
- 在扩充数据集之前确保学习算法具有低偏差(可以画出学习曲线来观察),(可以通过增加特征数量或增加神经网络中隐藏层数量来获得低偏差)
- 思考获得10倍的数据集需要的工作量(有时候收集十倍的数据集非常简单)
- 人造数据集
- 自己收集数据标签
- 众包收集数据集
18-4 上限分析:下一步要做流水线中的哪一个
上限分析:确定下一步把工作中心放在流水线中的哪个模块是最高效的
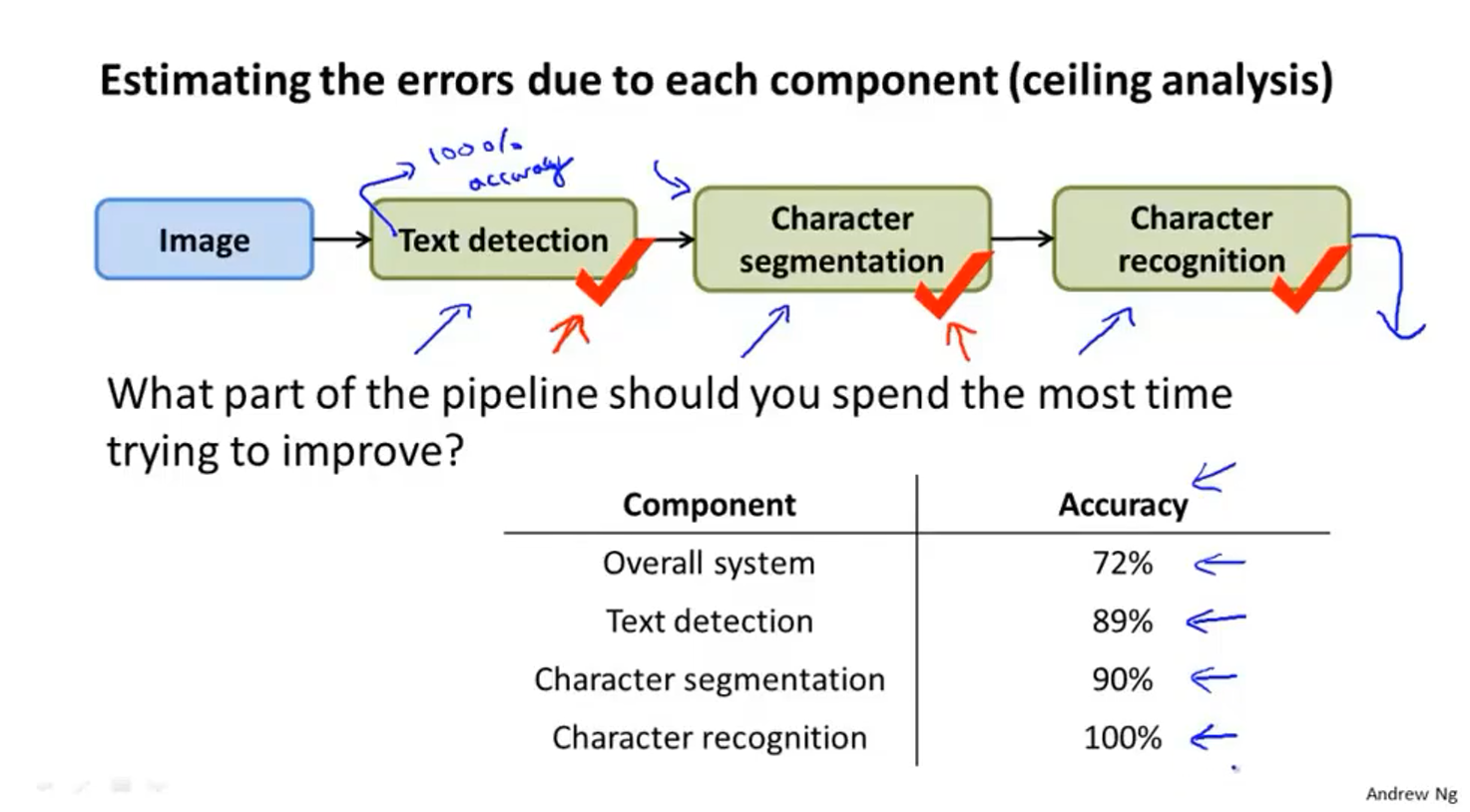
假设目前整个系统的运行准确率为72%
先人工的让Text detection模块准确率为100%(手动完成这个模块的工作),然后把模块工作结果给下一个模块,这样得出最后的系统准确率变成了89%,然后再对character segmentation模块进行相同的操作(即手动完成Text detection模块和character segmentation模块的工作),又得到系统准确率变成了90%,最后让最后一个模块也变成手动完成的(即手动完成了所有模块),显然这样得到系统准确率变成了100%
这样我们就得出了优化每个模块能够让系统准确率提高多少,比如优化Text detection模块可以让准确率提高89%-72%=17%,优化character segmentation模块可以让准确率提高90%-89%=1%
本文来自博客园,作者:Fannnf,转载请注明原文链接:https://www.cnblogs.com/overtop/p/15890736.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号