会员
周边
新闻
博问
闪存
众包
赞助商
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
Loading
Python当打之年
~代码如诗,自有远方~
首页
订阅
管理
[置顶]
【01 可视化 | Python分析中秋月饼,这几种口味才是yyds!】
摘要:
通过分析某宝中秋月饼的销售情况,看看哪些口味月饼卖得好,哪些地方月饼卖得好
阅读全文
posted @ 2024-08-27 14:34 欧K
阅读(90)
评论(0)
推荐(0)
2020年9月24日
Python 本地文件选择框
摘要: from tkinter import filedialog import tkinter #定义文件路径选择时间 def Button_command(): # Folderpath = filedialog.askdirectory() # 获得选择好的文件夹 Filepath = filedi
阅读全文
posted @ 2020-09-24 14:04 欧K
阅读(1584)
评论(0)
推荐(0)
python zip文件读取转存excel
摘要: import os import re import zipfile import logging import requests from bs4 import BeautifulSoup from openpyxl import Workbook from openpyxl.utils impo
阅读全文
posted @ 2020-09-24 13:48 欧K
阅读(918)
评论(0)
推荐(0)
2019年2月21日
Byte数组转浮点数
摘要: 数据转换--Byte数组转浮点数
阅读全文
posted @ 2019-02-21 10:34 欧K
阅读(2201)
评论(0)
推荐(0)
公告
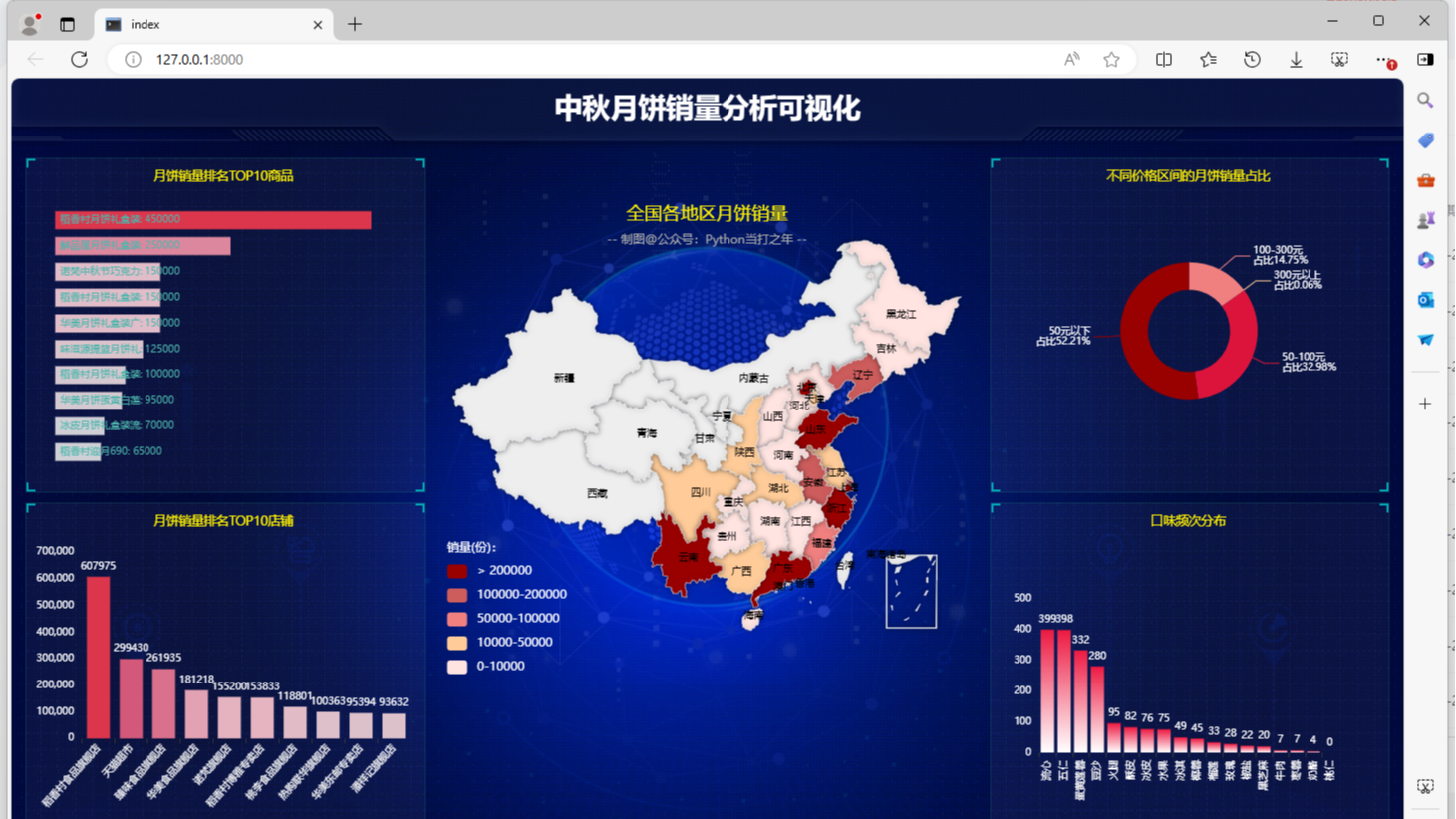 通过分析某宝中秋月饼的销售情况,看看哪些口味月饼卖得好,哪些地方月饼卖得好 阅读全文
通过分析某宝中秋月饼的销售情况,看看哪些口味月饼卖得好,哪些地方月饼卖得好 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号