
一:orm简介
查询数据层次图解:如果操作mysql,ORM是在pymysq之上又进行了一层封装

- MVC或者MTV框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- ORM是“对象-关系-映射”的简称。



查询数据层次图解:如果操作mysql,ORM是在pymysq之上又进行了一层封装 MVC或者MTV框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动 ORM是“对象-关系-映射”的简称。
二:单表操作
1 创建表 : orm不能创建数据库,必须手动创建数据库
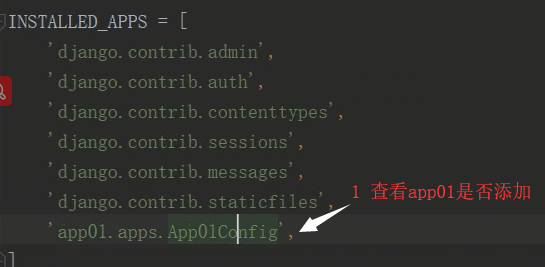
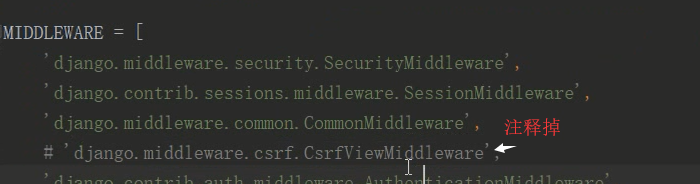
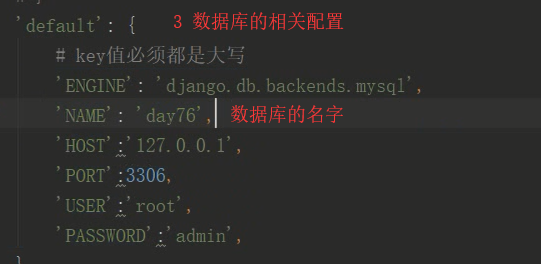
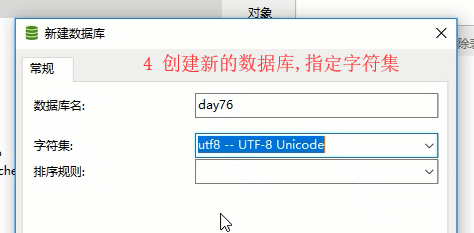

8 python3 manage.py showmigrations
9 python3 manage.py migrate 将model中的数据同步到数据库
10 在项目中创建一个文件夹
test.py
import os
import django
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "项目名.settings")
django.setup()
以上就是创建项目从配置到创建数据库到即将创建表的步骤!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
2创建名为app01的app,并在book下的models.py中创建模型
from django.db import models # Create your models here. class Book(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5, decimal_places=2) publish = models.CharField(max_length=32) author = models.CharField(max_length=32) create_data=models.DateField(null=True) def __str__(self): return '书名:%s,价格:%s 出版时间:%s'%(self.name,self.price,self.create_data)
3 更多字段和参数
每个字段有一些特有的参数,例如,CharField需要max_length参数来指定VARCHAR数据库字段的大小。还有一些适用于所有字段的通用参数。 这些参数在文档中有详细定义,这里我们只简单介绍一些最常用的: (更多信息详见https://www.cnblogs.com/liuqingzheng/articles/9472723.html#_label1)
AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - bigint自增列,必须填入参数 primary_key=True 注:当model中如果没有自增列,则自动会创建一个列名为id的列 from django.db import models class UserInfo(models.Model): # 自动创建一个列名为id的且为自增的整数列 username = models.CharField(max_length=32) class Group(models.Model): # 自定义自增列 nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) SmallIntegerField(IntegerField): - 小整数 -32768 ~ 32767 PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正小整数 0 ~ 32767 IntegerField(Field) - 整数列(有符号的) -2147483648 ~ 2147483647 PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正整数 0 ~ 2147483647 BigIntegerField(IntegerField): - 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 自定义无符号整数字段 class UnsignedIntegerField(models.IntegerField): def db_type(self, connection): return 'integer UNSIGNED' PS: 返回值为字段在数据库中的属性,Django字段默认的值为: 'AutoField': 'integer AUTO_INCREMENT', 'BigAutoField': 'bigint AUTO_INCREMENT', 'BinaryField': 'longblob', 'BooleanField': 'bool', 'CharField': 'varchar(%(max_length)s)', 'CommaSeparatedIntegerField': 'varchar(%(max_length)s)', 'DateField': 'date', 'DateTimeField': 'datetime', 'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)', 'DurationField': 'bigint', 'FileField': 'varchar(%(max_length)s)', 'FilePathField': 'varchar(%(max_length)s)', 'FloatField': 'double precision', 'IntegerField': 'integer', 'BigIntegerField': 'bigint', 'IPAddressField': 'char(15)', 'GenericIPAddressField': 'char(39)', 'NullBooleanField': 'bool', 'OneToOneField': 'integer', 'PositiveIntegerField': 'integer UNSIGNED', 'PositiveSmallIntegerField': 'smallint UNSIGNED', 'SlugField': 'varchar(%(max_length)s)', 'SmallIntegerField': 'smallint', 'TextField': 'longtext', 'TimeField': 'time', 'UUIDField': 'char(32)', BooleanField(Field) - 布尔值类型 NullBooleanField(Field): - 可以为空的布尔值 CharField(Field) - 字符类型 - 必须提供max_length参数, max_length表示字符长度 TextField(Field) - 文本类型 EmailField(CharField): - 字符串类型,Django Admin以及ModelForm中提供验证机制 IPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制 GenericIPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6 - 参数: protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6" unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启刺功能,需要protocol="both" URLField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证 URL SlugField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) CommaSeparatedIntegerField(CharField) - 字符串类型,格式必须为逗号分割的数字 UUIDField(Field) - 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 FilePathField(Field) - 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能 - 参数: path, 文件夹路径 match=None, 正则匹配 recursive=False, 递归下面的文件夹 allow_files=True, 允许文件 allow_folders=False, 允许文件夹 FileField(Field) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage ImageField(FileField) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage width_field=None, 上传图片的高度保存的数据库字段名(字符串) height_field=None 上传图片的宽度保存的数据库字段名(字符串) DateTimeField(DateField) - 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] DateField(DateTimeCheckMixin, Field) - 日期格式 YYYY-MM-DD TimeField(DateTimeCheckMixin, Field) - 时间格式 HH:MM[:ss[.uuuuuu]] DurationField(Field) - 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 FloatField(Field) - 浮点型 DecimalField(Field) - 10进制小数 - 参数: max_digits,小数总长度 decimal_places,小数位长度 BinaryField(Field) - 二进制类型 字段
(1)null 如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False. (1)blank 如果为True,该字段允许不填。默认为False。 要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。 如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。 (2)default 字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。 (3)primary_key 如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True, Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为, 否则没必要设置任何一个字段的primary_key=True。 (4)unique 如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的 (5)choices 由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,<br>而且这个选择框的选项就是choices 中的选项。
class UserInfo(models.Model): nid = models.AutoField(primary_key=True) username = models.CharField(max_length=32) class Meta: # 数据库中生成的表名称 默认 app名称 + 下划线 + 类名 db_table = "table_name" # 联合索引 index_together = [ ("pub_date", "deadline"), ] # 联合唯一索引 unique_together = (("driver", "restaurant"),) # admin中显示的表名称 verbose_name # verbose_name加s verbose_name_plural 元信息
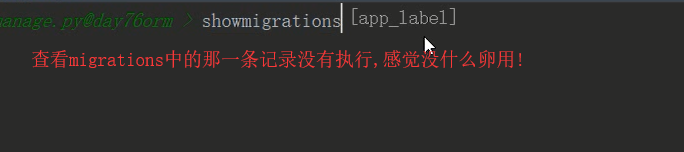
1 数据库迁移记录都在 app01下的migrations里
2 使用showmigrations命令可以查看没有执行migrate的文件
3 makemigrations是生成一个文件,migrate是将更改提交到数据量
4新增插入的数据
<1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <5> order_by(*field): 对查询结果排序('-id') <6> reverse(): 对查询结果反向排序 <8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <9> first(): 返回第一条记录 <10> last(): 返回最后一条记录 <11> exists(): 如果QuerySet包含数据,就返回True,否则返回False <12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 <13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <14> distinct(): 从返回结果中剔除重复纪录
#一*****************新增插入数据的两种方式 # models.Book.objects.create(name='红楼梦',price=56.7,publisher='中国邮电出版社',auther='曹雪芹',create_date='2018-08-08') # book=models.Book(name='水浒传',price=46.7,publisher='中国政法出版社',auther='施耐庵',create_date='2018-06-08') # book.save() # ctime=datetime.datetime.now() # book = models.Book(name='三国演义', price=66.4, publisher='中国人民出版社', auther='罗贯中', create_date=ctime) # book.save() # book1 = models.Book(name='西游记', price=106.7, publisher='中国河南出版社', auther='吴承恩', create_date='2018-09-09') # book2 = models.Book(name='西游记', price=106.7, publisher='中国河南出版社', auther='吴承恩', create_date='2018-03-09') # book1.save() # book2.save()
5 表单的数据删除
#二**************删除************ # 第一种方式,只要是叫做水浒传的书全部都删除掉 # models.Book.objects.filter(name='水浒传').delete() # 删除的第二种方式 # ret=models.Book.objects.filter(name='水浒传').first() # ret.delete() # 三*************修改************** # models.Book.objects.filter(name='水浒传').update(price="30") # 对象修改,没有update方法,但是可以用save来修改 # book=models.Book.objects.filter(name='水浒传').first() # book.price='55.5' # book.save()
6 查询 #*四******************查询************(重点)**存不是目的,目的是取********** # ret=models.Book.objects.filter()
# print(all) # 查询名字叫西游记的这本书 # ret=models.Book.objects.filter(name='西游记').first() # print(ret) # filter内可以传多个参数,用逗号隔开,他们之间是and的关系 # ret=models.Book.objects.filter(name='西游记',price='100').first() # print(ret) #get() 有且只有一个结果,才能用,如果有一个,返回的是对象, # 不是queryset对象,通常用在用id查询的情况 # ret=models.Book.objects.get(name='红楼梦') # ret=models.Book.objects.get(id=4) # print(ret) # exclude()查询名字不叫'西游记'的书,结果也是queryset对象 # ret=models.Book.objects.exclude(name='西游记',price='100') # print(ret) # order_by 按价格升序排 # ret=models.Book.objects.all().order_by('price') # print(ret)
# order_by('-price')按价格倒叙排列 # ret=models.Book.objects.all().order_by('-price') # print(ret)
# 可以传多个值,按照创建时间
# ret=models.Book.objects.all().order_by('-price','create_date') # print(ret) # reverse 对结果进行反向排列 # ret=models.Book.objects.all().order_by('price').reverse() # print(ret) # count 查询结果个数 # ret=models.Book.objects.all().count() # ret=models.Book.objects.filter(name='西游记').count() # print(ret) # last 返回book对象 # ret = models.Book.objects.all().last() # print(ret) # exists 返回结果是布尔类型 # ret = models.Book.objects.filter(name='水浒').exists() # print(ret) # value(*field): 对象里面套字典 # ret=models.Book.objects.all().values('name','price') # ret=models.Book.objects.all().values('name') # print(ret) # value_list queryset里面套元组 # ret = models.Book.objects.all().values_list('name', 'price') # print(ret) #distinct() 必须完全一样,才能去重,只要带了id 去重将毫无意义 # ret=models.Book.objects.all().values('name').distinct() # print(ret)
6 基于双下划綫的模糊查询
Book.objects.filter(price__in=[100,200,300]) Book.objects.filter(price__gt=100) Book.objects.filter(price__lt=100) Book.objects.filter(price__gte=100) Book.objects.filter(price__lte=100) Book.objects.filter(price__range=[100,200]) Book.objects.filter(title__contains="python") Book.objects.filter(title__icontains="python") Book.objects.filter(title__startswith="py") Book.objects.filter(pub_date__year=2012)
# 五:********基于双下划线的模糊查询*************** # price_gt : 查询价格大于90的queryset对象 # ret=models.Book.objects.all().filter(price__gt='90') # print(ret) # price_lt : 查询价格小于90的queryset对象 # ret = models.Book.objects.all().filter(price__lt='90') # print(ret) # price_gt : 查询价格大于等于90的queryset对象 # ret=models.Book.objects.filter(price__gte='90') # print(ret) # price_lt : 查询价格小于等于90的queryset对象 # ret = models.Book.objects.filter(price__lte='90') # print(ret) # in 在XX中 # ret=models.Book.objects.filter(price__in=['100','106.7']) # print(ret) # contains 查询名字中带有'%红%'的书 # ret = models.Book.objects.filter(name__contains='游').values('name') # print(ret) # import datetime # ctime=datetime.datetime.now() # models.Book.objects.create(name='python',price=200,publisher='老男孩教育',auther='egon',create_date=ctime) # ret=models.Book.objects.all().values('name') # print(ret) # 查询名字中带p的对象 # ret=models.Book.objects.filter(name__contains='p') # print(ret) # startswith 以XX开头来查询 # ret=models.Book.objects.filter(name__startswith='西') # print(ret) # endswith 以XX结尾来查询 # ret = models.Book.objects.filter(name__endswith='传') # print(ret) # crerate_date__year按年查询 # ret = models.Book.objects.filter(create_date__year='2018') # print(ret)
三:作业
1 查询老男孩出版社出版过的价格大于200的书籍 2 查询2017年8月出版的所有以py开头的书籍名称 3 查询价格为50,100或者150的所有书籍名称及其出版社名称 4 查询价格在100到200之间的所有书籍名称及其价格 5 查询所有人民出版社出版的书籍的价格(从高到低排序,去重) 6 查找所有书名里包含楼的书 7 查找出版日期是2017年的书 8 查找出版日期是2017年的书名 9 查找价格大于10元的书 10 查找价格大于10元的书名和价格
import os import django if __name__ == '__main__': os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day76_1.settings") django.setup() from zpp01 import models # models.Book.objects.create(name='python',price='500',publisher='老男孩出版社',auther='lqz',create_date='2017-08-08') # models.Book.objects.create(name='Djanjo',price='300',publisher='老男孩出版社',auther='egon',create_date='2017-08-08') # models.Book.objects.create(name='linux',price='150',publisher='老男孩出版社',auther='oldboy',create_date='2018-08-08') # models.Book.objects.create(name='摩天大楼',price='100',publisher='信阳出版社',auther='andy',create_date='2016-08-08') # models.Book.objects.create(name='遮天',price='40',publisher='网易出版社',auther='辰东',create_date='2015-05-05') models.Book.objects.create(name='完美世界',price='40',publisher='人民出版社',auther='辰东',create_date='2017-05-05') models.Book.objects.create(name='斗罗大陆',price='20',publisher='人民出版社',auther='唐家三少',create_date='2017-03-05') # models.Book.objects.create(name='狼图腾',price='20',publisher='佚名出版社',auther='佚名',create_date='2016-06-08') # ret=models.Book.objects.all() # print(ret) # 1查询老男孩出版社出版过的价格大于200的书籍(出版社老男孩) # ret1=models.Book.objects.filter(publisher='老男孩出版社',price__gt='200') # print(ret1) # 2查询2017年8月出版的所有以py开头的书籍名称 # ret2=models.Book.objects.filter(create_date__year=2017,create_date__month=8,name__startswith="py") # print(ret2) # 3查询价格为50, 100或者150的所有书籍名称及其出版社名称 # ret3=models.Book.objects.filter(price__in=[50, 100, 150]).values('name','publisher') # print(ret3) # 4查询价格在100到200之间的所有书籍名称及其价格 # ret4=models.Book.objects.filter(price__gt=100,price__lt=200).values('name','price') # print(ret4) # 5 查询所有人民出版社出版的书籍的价格(从高到低排序,去重) # ret5=models.Book.objects.filter(publisher='人民出版社').values('price').order_by('-price').distinct() # print(ret5) # 6查找所有书名里包含楼的书 # ret6=models.Book.objects.filter(name__contains='楼') # print(ret6) # 7 :查找出版日期是2017年的书 # ret7=models.Book.objects.all().filter(create_date__year=2017) # print(ret7) # 8 :查找出版日期是2017年的书名 # ret8=models.Book.objects.filter(create_date__year=2017).values('name') # print(ret8) # # 删除id为9-20 的所有对象 # ret=models.Book.objects.filter(id__gt=9).delete() # print(ret) # 9查找价格大于10元的书 # ret9=models.Book.objects.filter(price__gt=10) # print(ret9) # 10查找价格大于10元的书名和价格 # ret10 = models.Book.objects.filter(price__gt=10).values('name','price') # print(ret10)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号