
部分主要对于工程中的变量进行管理和设置,支持手动拖拉至右侧画布 1全局变量:全局变量可以在整个工程中传递,被不同的子流程或函数进行调用,全局可见可调用 2 流程参数:只对子流程设置传入参数,供子流程内部使用 3 流程变量:只能用于当前流程中,不能被其他流程调用 最下方显示【工程】、【运行】和【查找】信息显示窗口,窗体可以沿着边界线进行拖动来调整显示的区域。窗口右上角一排按钮,功能分别是搜索窗口信息、清空窗口信息内容、停止运行以及窗口最大化、隐藏窗口。窗口右下角有一个小手,支持面板的移动和拖拉【固定】:点击“固定”按钮,组件界面固定显示在最前端,便于连续添加多个组件。
版本管理:
iS-RPA9.0设计器集成了 git 本地版本管理,所有工程版本都是自动管理,每次保存都会产生一个 add + commit,可以方便的对工程版本进行管理。由于自动保存的存在,日常编辑过程有了完全保障,可以随意进行恢复。
拾取:
开启拾取(F2):拾取过程中,按下F2键,关闭拾取;再次按下F2键,重新开启拾取。 CS拾取(F3):拾取过程中,按下F3键,只拾取CS。 UIA拾取(F4):拾取过程中,按下F4键,进行细粒度拾取,拾取更细化。 图片拾取(F5):拾取过程中,按下F5键,将切换为图片拾取的方式,当鼠标变为截图标志时,进行拖选截图即可。
IE拾取(F6):拾取过程中,按下F6键,只拾取IE。
JAVA拾取(F7):拾取过程中,按下F7键,只拾取JAVA。
区域拾取(F8):用于拾取所选区域中的位置进行鼠标点击。先选择需要拾取的控件区域,再按下F8,在用鼠标移动到该区域中需要鼠标点击的位置,即可完成拾取。在运行时会点击该区域中设置的鼠标位置进行点击。
Chrome拾取(F9):拾取过程中,按下F9键,只拾取Chrome。
Firefox拾取(F10):拾取过程中,按下F10键,只拾取Firefox。
退出录制拾取(F12):结束并保存录制流程。
“窗口标题”:
记录控件所在的窗口的标题信息。勾选上则表示在操作该步骤前会进行激活窗口的操作,如去掉勾选,则不会进行窗口激活的操作。
模拟按键
用于完成键盘的输入操作。通过鼠标右键选择【模拟按键】。 注:模拟的是真实的键盘输入操作,如部分控件无法拾取,可先通过鼠标点击控件,获得输入光标后,再进行键盘的##输入操作。 将需要填写的内容直接在设置中输入即可,需要加单引号。输入的内容也可以通过变量进行传递调用,输入的内容也##可以通过变量进行传递调用 如需连续操作多次设置的按键,在按键后加入空格和次数即可。
键盘-热键输入
可通过设置组合快捷键的方式来完成相关的快捷键操作,在页面或程序当中如果快捷键的设定,使用该方法较佳。 在下拉框中也可以输入自定义的按键,如a,合起来就是Ctrl+a的热键操作,用于全选。
键盘-控件输入
控件输入适用于所有浏览器中网银的密码输入,安装完银行的控件后,用控件输入拾取密码输入的元素框, 就可以实现密码数据的输入。可手工输入文本内容,也可以通过变量的方式调用。变量使用见《变量》章节。
控制-Check
通过对CheckBox类型控件(复选框)的拾取,对复选框进行勾选和去勾选的操作。 拾取的时候需要注意,需要拾取到单独的复选框,而不能拾取到外层的整个框体。
图片-截图
通过截取设置的区域位置,对区域内进行截屏并在本地生成图片的操作,需要在“图片位置”中选择图片保存在本地的路径。 截图组件可设置返回值,返回的是图片的绝对路径,可用变量保存该返回值。
关闭网页标签栏
热键输入:ctrl+w
try:
一开始流程先进开始,开始后面的代码发生异常的话,就走异常后面的代码,最后无论发生没有发生异常,都会走结束
merge
该组件主要用于将从两个excel文件或两个Sheet页中读取出的DataFrame数据集进行数据合并的操作。
列重命名
对表格列进行重命名的操作。 【df】中选择DataFrame数据集 【src_field】选择原列名 【dst_field】选择修改后的列名
RPADe解锁屏,是否锁屏等组件,Remote解锁实现服务器远程连接客户端机器。
时间
当前时间&日期 当前日期 当前时间 格式化为字符:将date日期按指定格式返回为字符串。 格式化为时间 时间相差天数 时间前|后(n)天 获取年 获取月 获取日 获取时 获取分 获取秒 获取周几
设置颜色
字体颜色,范围背景颜色
范围删除内容
zip:
【src_file】 需要解压的文件 例如 src_file = r’D:\abc\新建文abc.zip’ 多个文件夹解压,逗号隔开 src_file = r’C:\11\test2.zip,C:\11\test1.zip’ 【dst_file】 解压之后的全路径 例如 dst_file = r’D:\xlss\aaaaa’ 【密码】 给压缩后的文件设置密码。
zip解压
zip解压就是把压缩文件解压出来。 【src_file】 需要解压的文件 例如 src_file = r’D:\abc\新建文abc.zip’ 【dst_file】 解压之后的全路径 例如 dst_file = r’D:\xlss\aaaaa’
OCR
内置的OCR功能需要调用百度的库进行识别,因此需要连接外网才可以。
另外需要注意的是,OCR功能每天有使用次数的限制:验证码每天100次, 通用文字每天200次,身份证和营业执照每天各10次; 能够满足日常的测试与使用,若是超过则只能通过其他方式继续使用了。
杀死进程
import osos.system('taskkill /F /IM notepad.exe')
开启RPA的时候,尽量使用使用管理员的方式打开
字符编码错误
要是中文字符串出现过多的话导致错误,None=-UTF-8 code 的情况发生的话,就在 "C:\ueba\studio-v6\config\language\language_cn.json"中打开这个文件,然后把“# 编译日期:”,把它修改为“#coding=utf-8\n# 编译日期:”,保存。重新打开设计器
模拟中轴滚动
1 使用cmd切换到RPA工作的python路径,pip install pywin32 2 在RPA项目中创建一个全局函数组件 import win32api import win32con # -a代表下移的距离,自己设置即可 def test_1(a): win32api.mouse_event(win32con.MOUSEEVENTF_WHEEL,0,0,-a) 3 在全局函数之前加上鼠标点击组件 4 在自己的项目中运行即可
关于设置文本获取不到元素
在登录工商银行的时候,发现文本框获取不到,这样的话可以时候ctrl+点击就可以获取到元素了
输入密码的时候,使用控件输入
图片验证码的时候,使用截图先截下来,然后使用获取OCR文本,使用全局函数获取
def idcode_check(ocr_code): code=(re.sub("0-9A-Za-z","",ocr_code)) return code
鼠标拖拽功能
from ctypes import * from ctypes.wintypes import * def imouse_drag(x1, y1, x2, y2,button='left',speed=10): try: dll = windll.LoadLibrary("../Com.Isearch.Func.AutoIt/AutoItX3.dll") return dll.AU3_MouseClickDrag(button,x1,y1,x2,y2,speed) except Exception as e: raise e
可以使用全局函数包装,然后x1,y1就是鼠标开始的位置,然后将目标位置的元素拖拽到x2,y2的位置
在设计器中尝试解析 PDF 数据
首先,你需要一个解析 pdf 的包,我们在 iS-RPA5.0 之后内置了 pdfplumber 的包,选择他的主要原因是这个包对表格处理比较好,而且他是 python 的原装包,不是 java 之类转过来的包,那么我们看看简单的例子:
import pdfplumber #导入pdf包 import re #导入正则表达式包 pdf = pdfplumber.open("path/to/file.pdf") #加载pdf page0 = pdf.pages[0] #取出第一页,你可以用for来遍历所有页面 tables = page0.extract_tables() #从page0里面取出多个tables texts = page0.extract_text() #从page0里面取出所有文本 results = re.findall(r"([0-9]{1,3}(,[0-9]{3})*\.[0-9]+)", texts) #从文本中提取带千分位和小数点的数字
请注意,pdfplumber 缺省通过表格线来区分行和列,所以下列情况是无法提取出表格的:* 你的表格是图片,通过选择可以确定是否图片* 你的表格不是用线来分隔,或者分隔不全,例如列用线,行没线这种情况下,你就需要尝试:page0.extract_tables(table_settings={})table_settings 的写法参考:Github 上的 Pdfplumber这个需要大家多多尝试,另外正则表达式学习也是很关键的,因为你可以使用正则表达式来提取 page0.extract_text() 中提取到的文本。
查阅:http://support.i-search.com.cn/article/1540084292275
将 PDF 转化为图片
遇到一个项目,需要将 PDF 文件的某一页 P 一张图片上去,我的思路为先将 PDF 文件转为图片,再把两张图片合成,再将合成好的图片转为 PDF,本文将分享如何将 PDF 文件转为图片。通过查资料除了 wand 我尝试过多种方法,但是其他方法貌似都是对 linux 的支持比较好,最后我用 wand 在 windows 上运行成功了。用到 python 的三个库:io、wand、PyPDF2,涉及 wand 中的 image 类、color 类,PyPDF2 中的中的 PdfFileReader、PdfFileWriter 类。wand 库对于图片的处理功能还是比较强大的,wand 的 image 类依赖 ImageMagick,因此在使用 wand 之前我们需要先在电脑中安装 ImageMagick,ImageMagick 是一个免费的创建、编辑、合成图片的软件。这里我遇到两个坑:1.32 位、64 位的 python 与 32 位、64 位的 ImageMagick 兼容问题,大家在安装前先检查好自己的 python;2.python3 目前还不兼容 ImageMagick7 以上的版本,而 ImageMagick 的官网上下载不到 7 以下的版本,这里我把文件放在这里:c2f3a13453f14f06bfe7c29724da4d88_ImageMagick6.rar ,里边包含 6 版本的 32 位与 64 位的 ImageMagick。就是以下报错信息困扰了我好久: (这里完全看不出来是兼容性的问题 (┬_┬))安装完成后,将 ImageMagic 添加到环境变量
(这里完全看不出来是兼容性的问题 (┬_┬))安装完成后,将 ImageMagic 添加到环境变量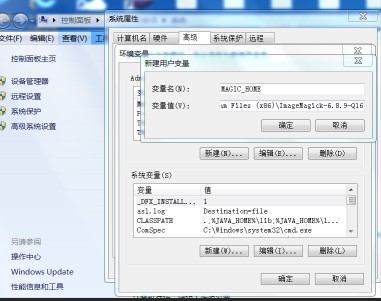 以下为代码加注解:
以下为代码加注解:
import io from wand.image import Image from wand.color import Color from PyPDF2 import PdfFileReader, PdfFileWriter def pdf_convert(filename, page, res=120): #初始化PdfFileReader对象 pdfile = PdfFileReader(filename, strict=False) idx = page + 1 #从此PDF文件中按编号检索页面 pageObj = pdfile.getPage(page) #创建PdfFileWriter对象,通常PdfFileReader生成的页面的情况下,用此对象编写PDF文件 dst_pdf = PdfFileWriter() #在PdfFileWriter中添加页面,该页面通常从PdfFileReader实例获取 dst_pdf.addPage(pageObj) #BytesIO实现了在内存中读写bytes,来操作二进制数据 pdf_bytes = io.BytesIO() #将添加到此对象的页面集合作为PDF文件写出 dst_pdf.write(pdf_bytes) #设置文件指针从0开始 pdf_bytes.seek(0) #创建Image对象(支持with)将文件流传入(resolution为分辨率参数) with Image(file=pdf_bytes, resolution=res) as img: #img = Image(file=pdf_bytes, resolution=res) #设置图片格式为png img.format = 'png' #img.compression_quality = 90 #设置背景颜色 img.background_color = Color("white") #保存到当前路径并标记页码(rindex返回字符最后出现的位置) img_path = '%s%d.png' % (filename[:filename.rindex('.')], idx) #以此文件名保存图片 img.save(filename=img_path) #img.destroy()
本代码实现了将一页 PDF 转化为图片,多页只需要加循环修改 page 的值即可。有问题欢迎大家交流,有不足的地方欢迎大家指正。另附:PdfFileReader 文档:https://pythonhosted.org/PyPDF2/PdfFileReader.htmlPdfFileWriter 文档:https://pythonhosted.org/PyPDF2/PdfFileWriter.htmlwand.image 文档:http://docs.wand-py.org/en/latest/wand/image.html
解析pdf文件
import pdfplumber import re #加载pdf文件 pdf=pdfplumber.open('C语言程序设计(第四版) 谭浩强著 高清晰版.PDF') #取出第一页,也可以用for来遍历所有页面 page0=pdf.pages[12] #从page0中取出多个tables tables=page0.extract_tables() #从page0中取数所有文本 texts=page0.extract_text() print(texts)
excel与word互转
# coding=utf-8 import pandas as pd from docx import Document from docx.shared import Pt from docx.shared import Inches from docx.oxml.ns import qn def excel_to_word(): excel_path = 'C:\\isearch\\excel_sourse.xlsx' df = pd.read_excel(excel_path,header = None) df = df.fillna('') df_list = df.values document = Document() document.add_heading(df_list[0][0],1) document.add_heading(df_list[1][0],2) for i in range(2,len(df_list)): if df_list[i][1] == '' and df_list[i][2] == '' and df_list[i][3] == '' and df_list[i][0]: if df_list[i][0].startswith('('): document.add_heading(df_list[i][0],3) else: document.add_heading(df_list[i][0],2) else: if df_list[i][0]: document.add_paragraph(df_list[i][0]+':'+str(df_list[i][1])) if df_list[i][2]: document.add_paragraph(df_list[i][2]+':'+str(df_list[i][3])) document.save('C:\\isearch\\out_word.docx') def word_to_excel(): df = pd.DataFrame(columns=('1', '2', '3','4','5')) d = Document('C:\\isearch\\out_word.docx') title_index_list = [] index_tuple_list= [] for i in range(len(d.paragraphs)): if d.paragraphs[i].style.name != 'Normal': title_index_list.append(i) for i in range(len(title_index_list)-1): if title_index_list[i+1] - title_index_list[i] !=1 : index_tuple_list.append([title_index_list[i]+1,title_index_list[i+1]]) index_tuple_list.append([title_index_list[-1]+1,len(d.paragraphs)]) tmp_dict_list = [] for i in range(len(index_tuple_list)): tmp_dict = {} for j in range(index_tuple_list[i][0],index_tuple_list[i][1]): tmp_value = d.paragraphs[j].text tmp_list = tmp_value.split(':') tmp_dict[tmp_list[0]] = tmp_list[1] tmp_dict_list.append(tmp_dict) for i in range(len(d.paragraphs)): if d.paragraphs[i].style.name != 'Normal': title_index_list.append(i) tmp_dict_list_index = 0 for i in range(len(title_index_list)-1): df.loc[len(df)] = ['' for n in range(5)] df.iloc[-1,0] = d.paragraphs[title_index_list[i]].text if title_index_list[i+1] - title_index_list[i] != 1 : df.loc[len(df)] = ['' for n in range(5)] df.loc[len(df)] = ['' for n in range(5)] tmp_key_list = [] for key in tmp_dict_list[tmp_dict_list_index].keys(): tmp_key_list.append(key) for i in range(len(tmp_key_list)):
python 转换 word,excel,ppt 到 pdf
需要使用的 win32com 库产品自带,无需额外导入。
from win32com import client #word转换为pdf def word_to_pdf(): w = client.Dispatch("Word.Application") doc = w.Documents.Open('d:\\test\\a.docx') doc.ExportAsFixedFormat('D:\\test\\word.pdf', client.constants.wdExportFormatPDF) w.Quit() #excel转换为pdf def excel_to_pdf(): xlApp = client.Dispatch("Excel.Application") books = xlApp.Workbooks.Open('d:\\test\\b.xlsx') books.ExportAsFixedFormat(0, 'D:\\test\\excel.pdf') xlApp.Quit() #ppt转换为pdf def ppt_to_pdf(): p = client.Dispatch("PowerPoint.Application") ppt = p.Presentations.Open('d:\\test\\c.pptx', False, False, False) ppt.ExportAsFixedFormat('D:\\test\\ppt.pdf', 2, PrintRange=None) p.Quit()
验证码相关
http://support.i-search.com.cn/article/1546840042899 滑动验证码和点击验证码详情
百度图像识别API
-
注册百度云账号,注册并登陆。http://ai.baidu.com/
-
登陆百度云,进入控制台,再进入应用列表创建应用,得到相应的 key
-
将 key 作为参数放到代码中后,进行简单的文本识别
-
在使用前安装aip (pip install baidu-aip)
-
from aip import AipOcr """ 你的 APPID AK SK """ APP_ID = '14404096' API_KEY = '67LMmai5y0CGA7NoHiUb9hSf' SECRET_KEY = ''xxx" client = AipOcr(APP_ID, API_KEY, SECRET_KEY) def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() image = get_file_content('path') """ 调用通用文字识别, 图片参数为本地图片 """ print(client.basicGeneral(image))
-
测试后的识别结果
-
