【ollama】手把手教你布置本地大语言模型 以及各种常见用途#如何加载guff模型到ollama #如何更改ollama目录

ollama介绍
Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。
以下是其主要特点和功能概述:
-
简化部署:Ollama 目标在于简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型。
-
轻量级与可扩展:作为轻量级框架,Ollama 保持了较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件。
-
API支持:提供了一个简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
-
预构建模型库:包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源。
运行界面: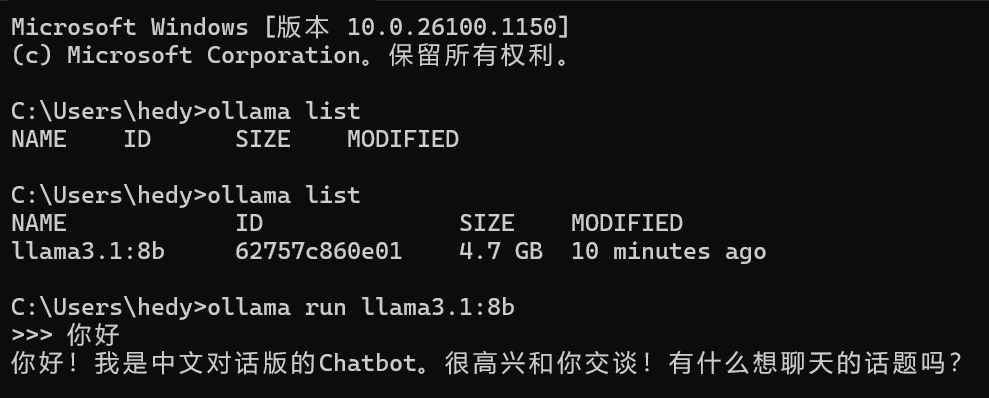
配合ChatBOX使用可以更加舒适
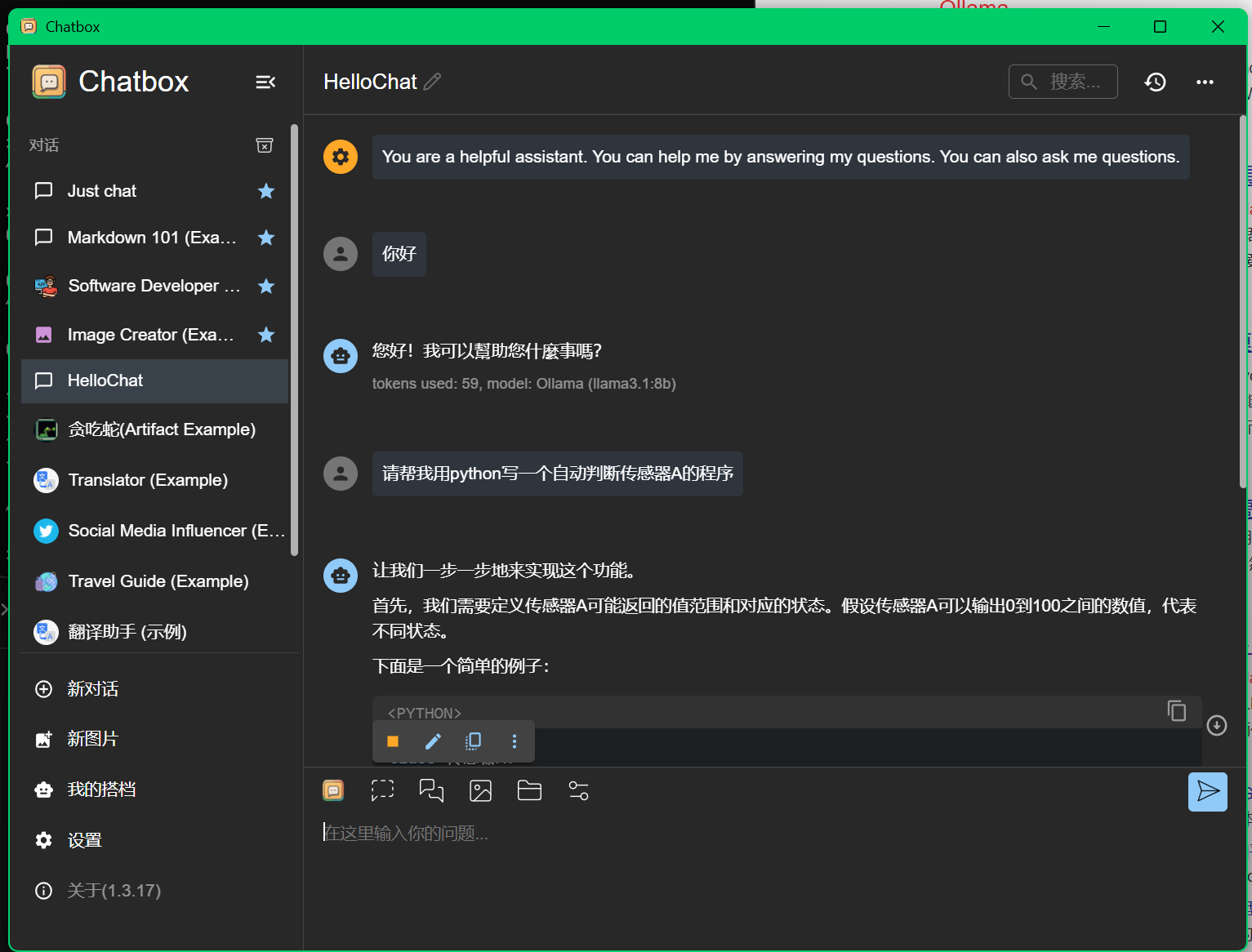
安装与使用
软件下载
如果地址失效请分别到ollama和chatbox的官网下载安装包:
ollama:https://ollama.com/
chatbox:https://chatboxai.app/zh
安装
下载完毕后进行解压,可以得到以下两个文件
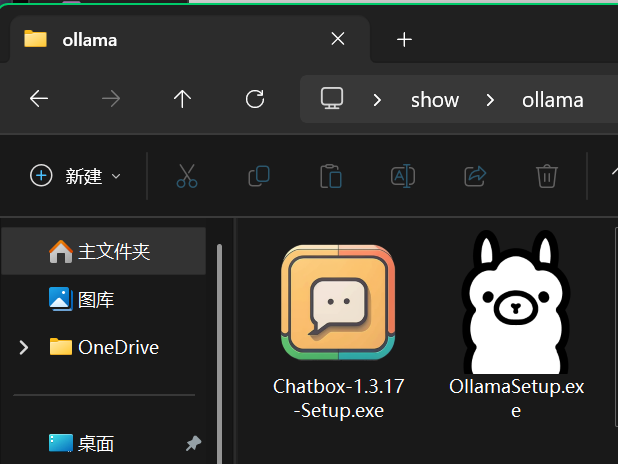
分别打开进行安装
安装完成
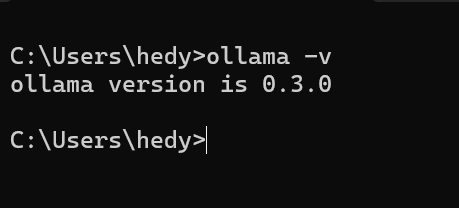
待安装完毕后,打开命令行输入ollama -v,若返回版本号,则说明ollama安装成功
ollama的配置与使用
我们上ollama的官方网站仓库里面
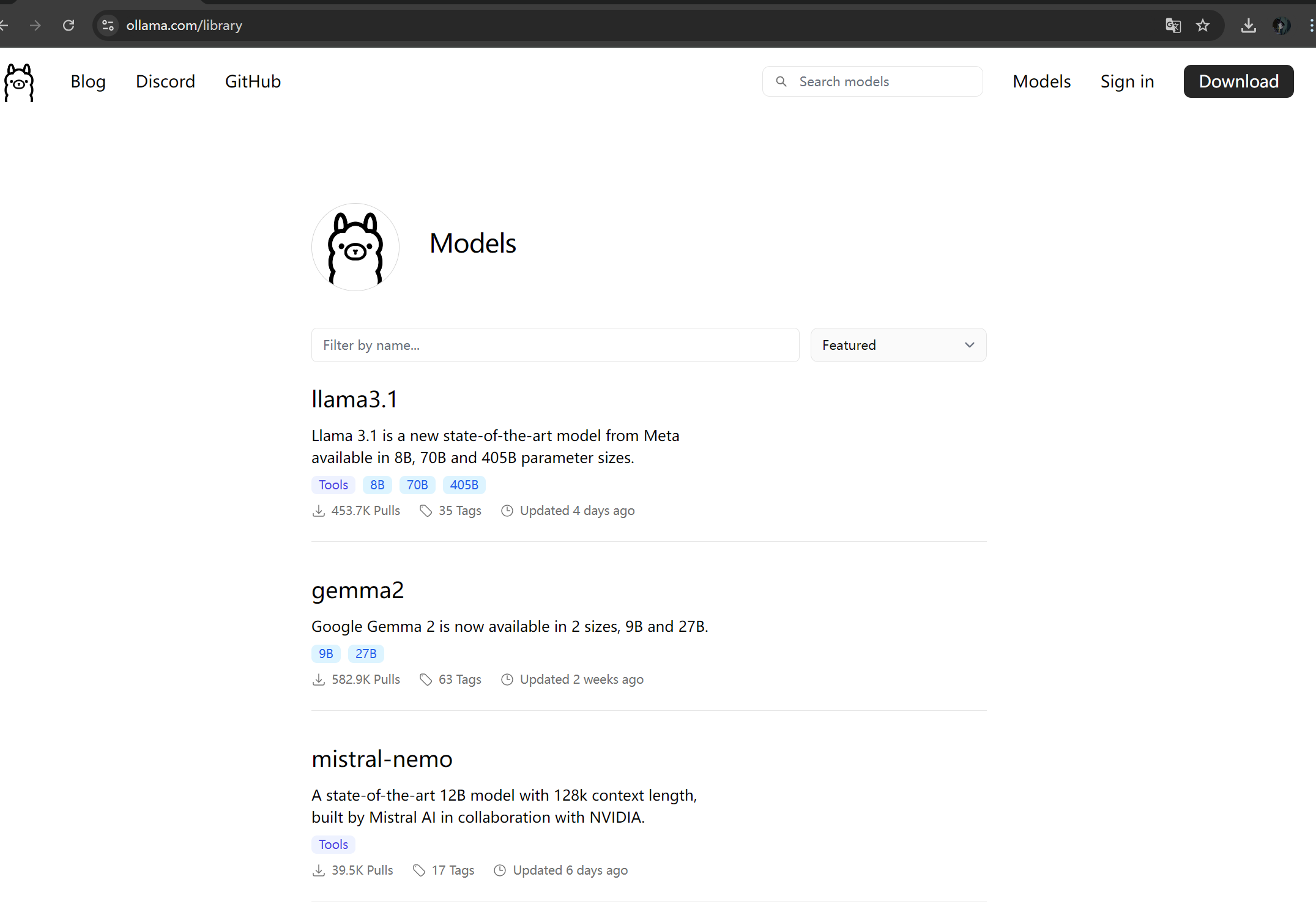
可以看到许多的模型,点击自己喜欢的模型,并选择所需要的版本
这里以llama3.1模型8B为例子:
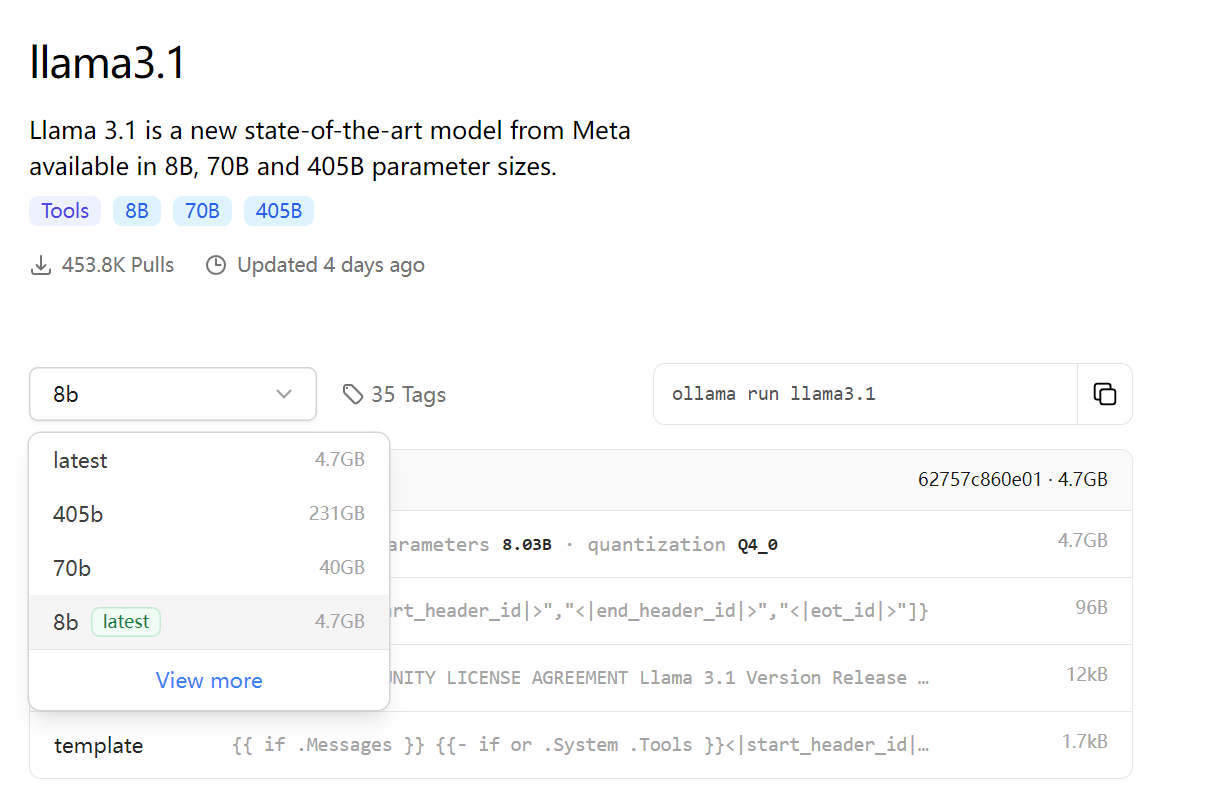
复制右上方的代码ollama run llama3.1至命令行内,模型会自行开始下载
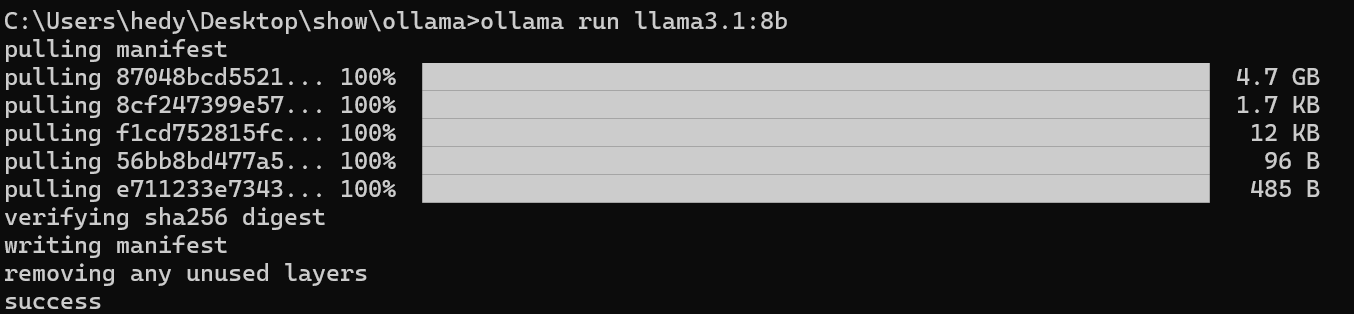
(由于镜像站在境外,所以连接比较弱,速度慢可以重试几次,正常下载速度绝不止100kb/s)
ollama使用
等下载完毕之后我们在命令行输入ollama list查看模型是否下载完成

若看到大概如上,我们便可以进入下一步,我们在命令行输入ollama run <模型名称>,我这里用llama3做示范:ollama run llama3.1:8b。
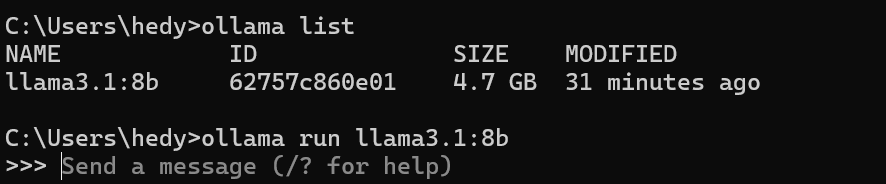
看到这个界面便是大功告成了!
chatbox使用
chatbox打开后界面如下
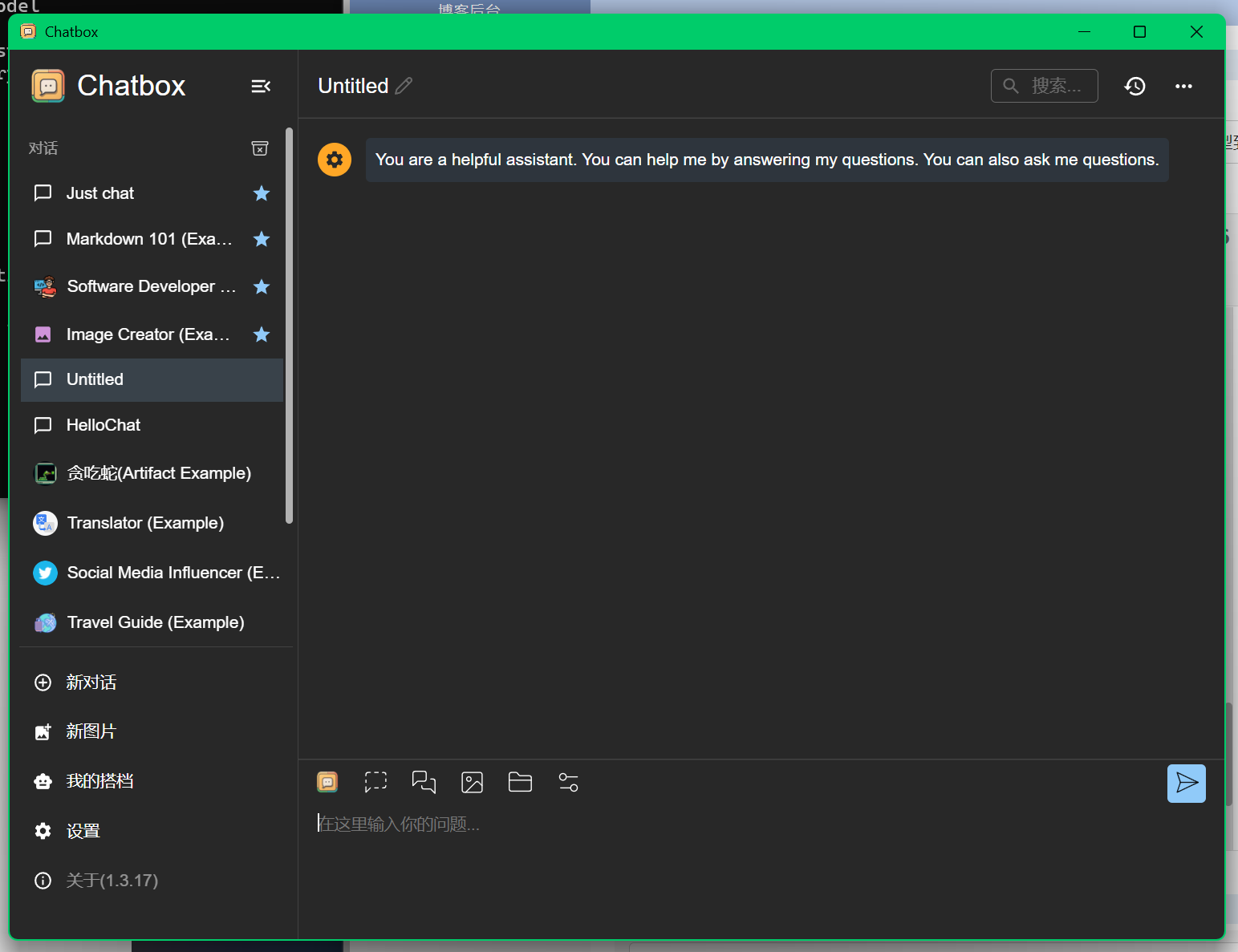
我们点进去左下角的设置
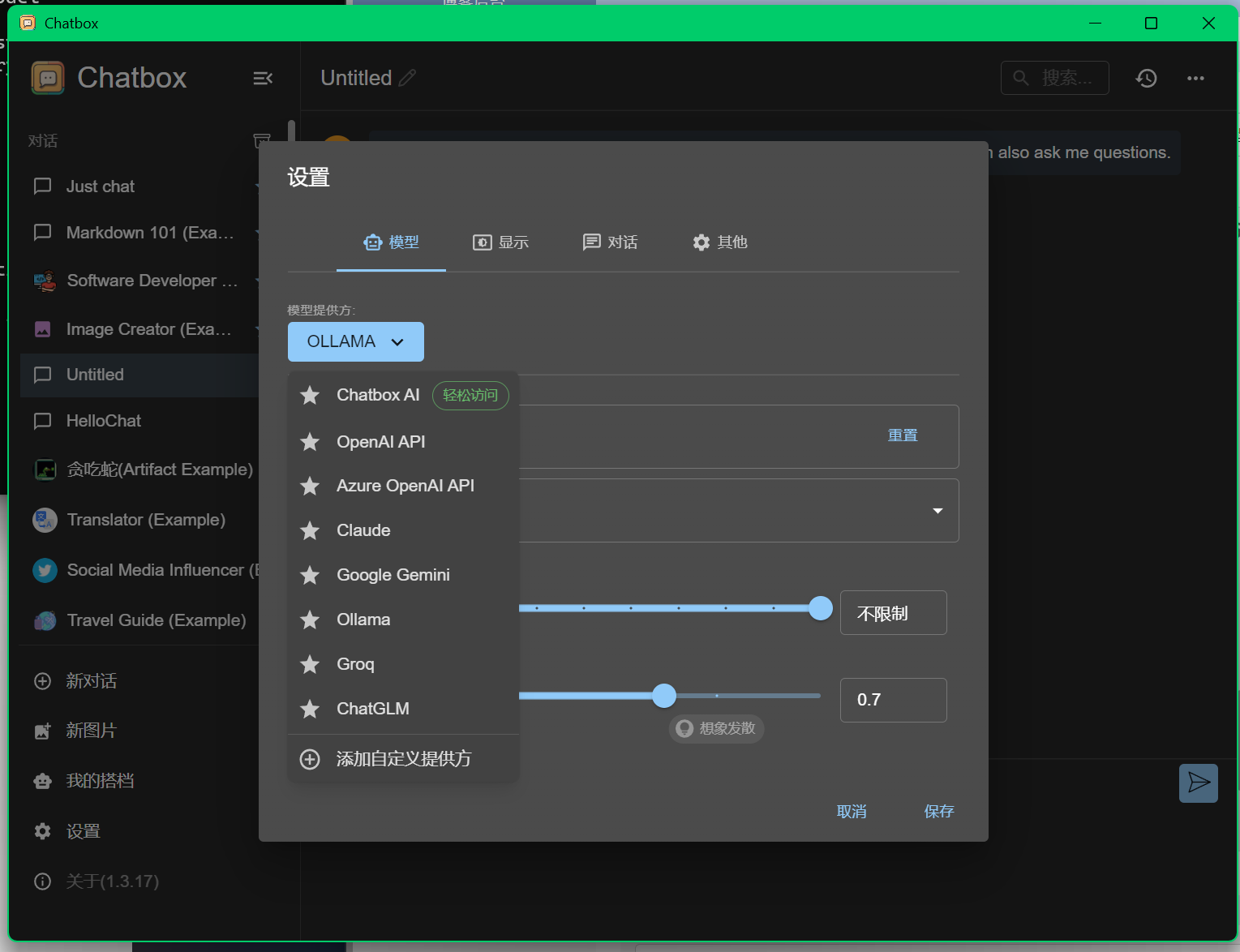
将模型提供方设置为ollama本地
api默认
模型设置为所需模型
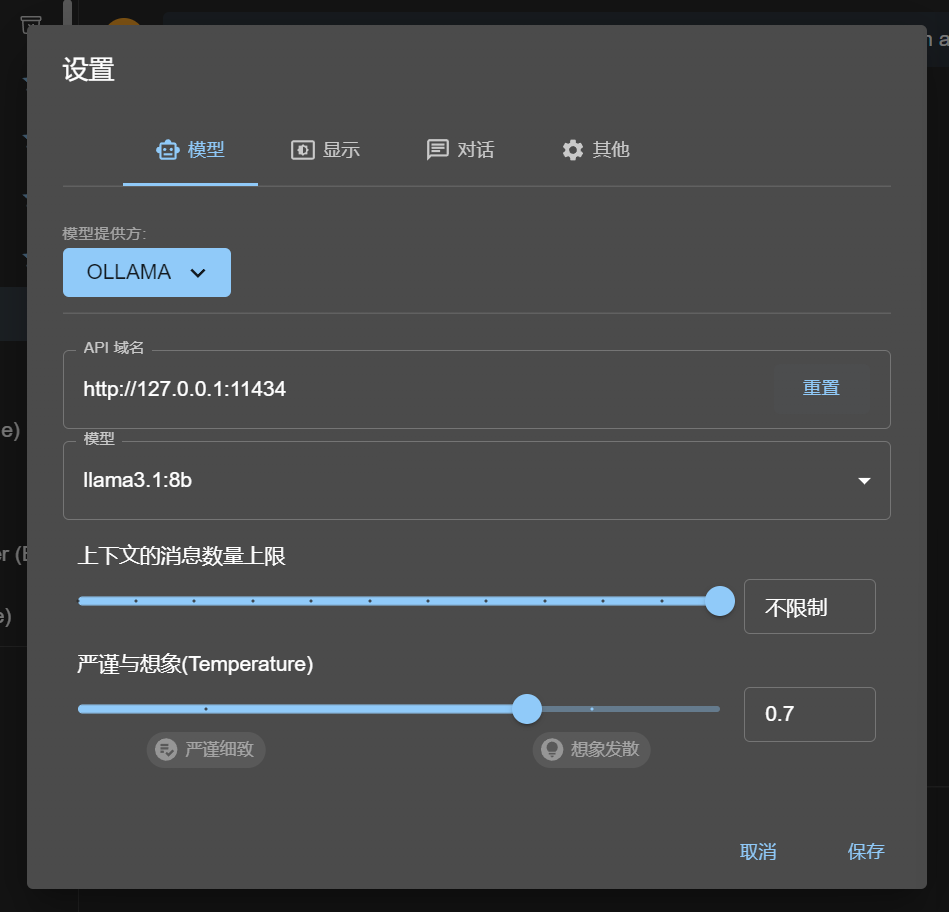
点击保存
便可以开始对话,轻松简单
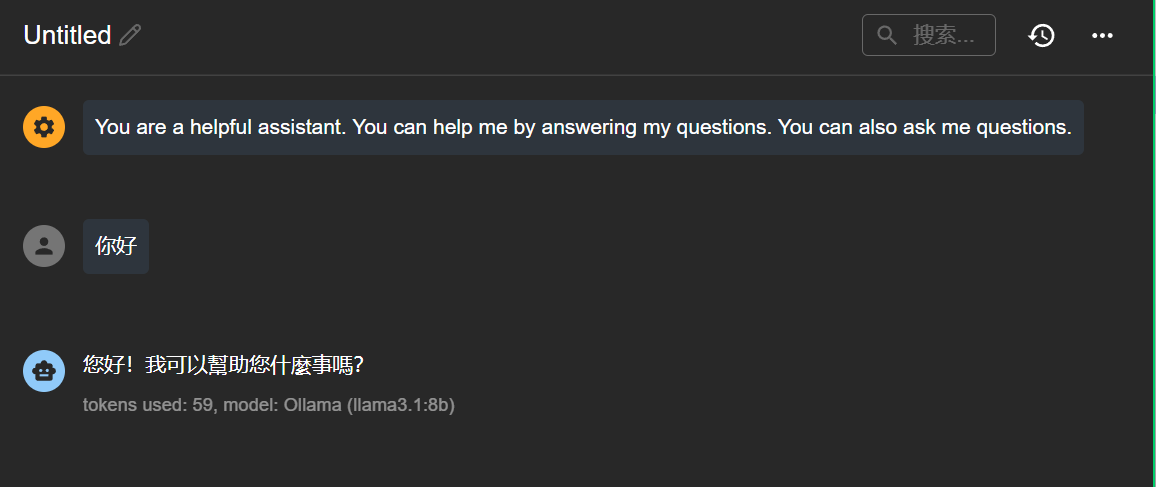
关于ollama的那些事
我在黄面下载了gguf模型,如何把gguf模型加载到ollama里面呢?
我们下面以opengpt4为例:
我有一个文件名字为open_gpt4_8x7b.Q2_K.gguf的模型
这时我们在同一个目录下新建一个文本文档,
在里面写入FROM ./<gguf文件名字>,比如我这里是:
FROM ./open_gpt4_8x7b.Q2_K.gguf
保存后将名字改为open_gpt4_8x7b.Q2_K,将txt后缀改为modelfile
即:open_gpt4_8x7b.Q2_K.modelfile
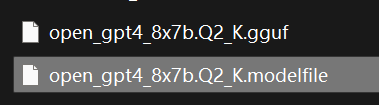
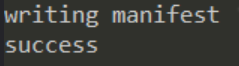
然后我们在命令行输入:ollama create open_gpt4_8x7b.Q2_K -f open_gpt4_8x7b.Q2_K.modelfile
成功的话会提示success
更改模型目录
更改默认的模型目录其实很简单
在想要用来储存的盘新建一个文件夹,并复制地址,
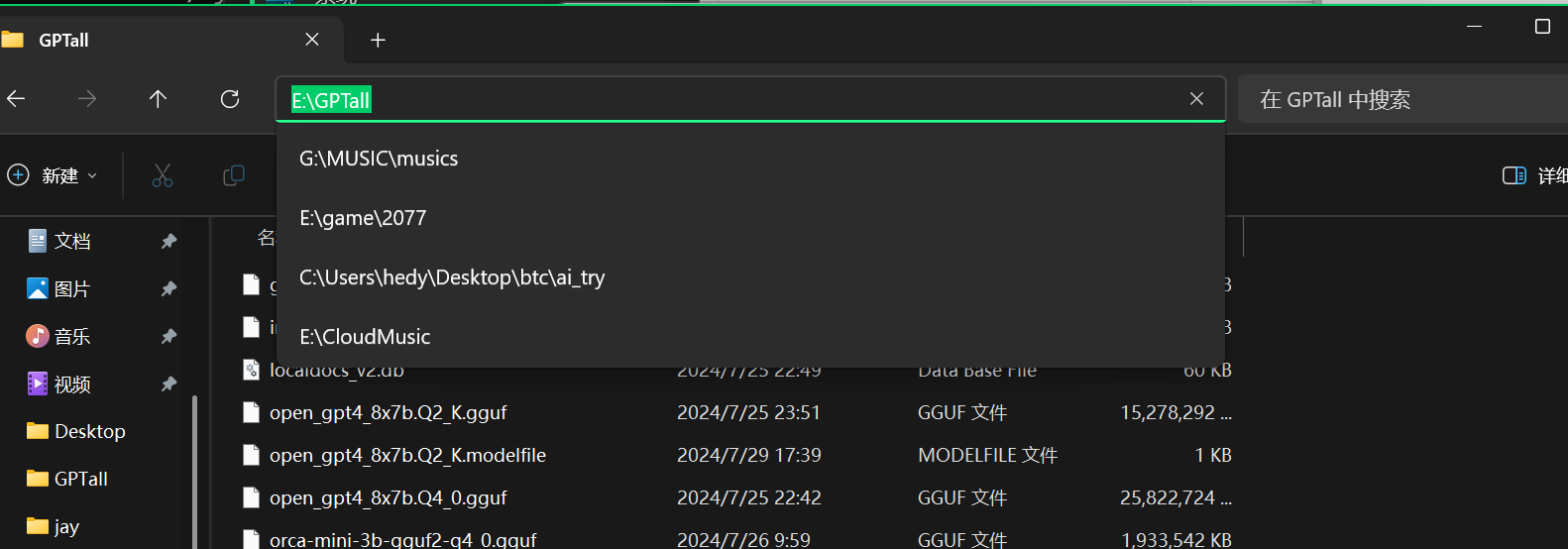
在系统设置里面新建系统环境变量:
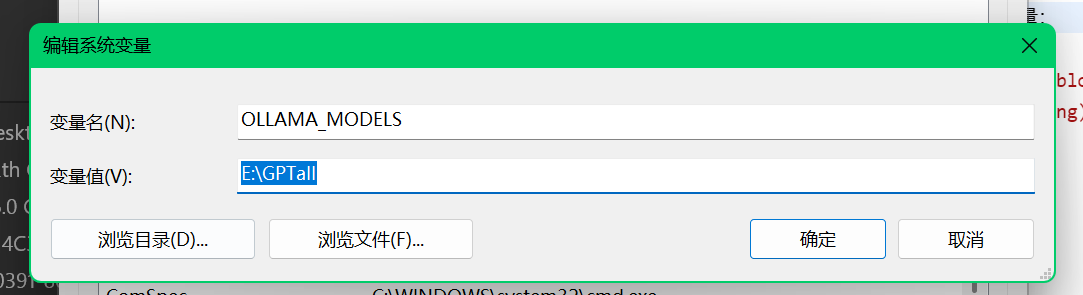
完成后点击确定 再点击上一层的确定。
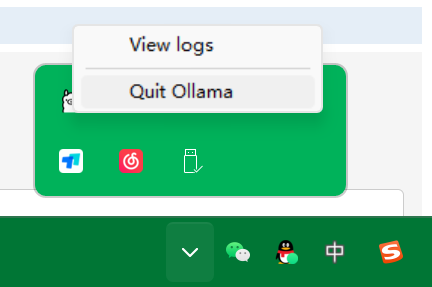
然后关闭ollama,再开启就可以更改模型目录了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号