Spark源码编译
一、源码下载
spark源码下载:http://spark.apache.org/downloads.html
下载各个历史版本的源码包在这里下载:https://archive.apache.org/dist/spark/
我下载的是:spark-2.1.0.tgz
二、编译源码
1、编译环境:MacBookPro10.14.5
java version: 1.8.0

scala version: 2.11.8

maven version: 3.3.9

2、解压源码包和编译: tar -zxvf spark-2.1.0.tgz
进入spark-2.1.0目录进行编译:
./build/mvn -Phadoop-2.7 -Pyarn -Dhadoop.version=2.7.3 -Phive -Phive-thriftserver clean package -Dmaven.test.skip=true
参数介绍:
-Phadoop:Hadoop版本号,默认版本2.6.5;
-Dhadoop.version: 同-Phadoop;
-Pyarn :是否支持Hadoop YARN;
-Phive:是否在Spark SQL 中支持hive,hive默认版本1.2.1;
-Phive-thriftserver:同-Phive;
-Dmaven.test.skip=true:不执行测试用例,也不编译测试用例类;
三、遇到的问题
1、下载源码包失败,进行spark源码编译时,会下载一些对应的依赖包,如下图所示下载到22.2%就失败了

解决方法:
编辑./bulid/mvn,修改对应的链接地址:
把这两个链接:
curl --progress-bar -L http://downloads.typesafe.com/scala/2.11.8/scala-2.11.8.tgz
curl --progress-bar -L http://downloads.typesafe.com/zinc/0.3.15/zinc-0.3.15.tgz
修改成:
curl --progress-bar -L http://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
curl --progress-bar -L http://downloads.lightbend.com/zinc/0.3.15/zinc-0.3.15.tgz
2、编译到一半就失败了,报错如图:
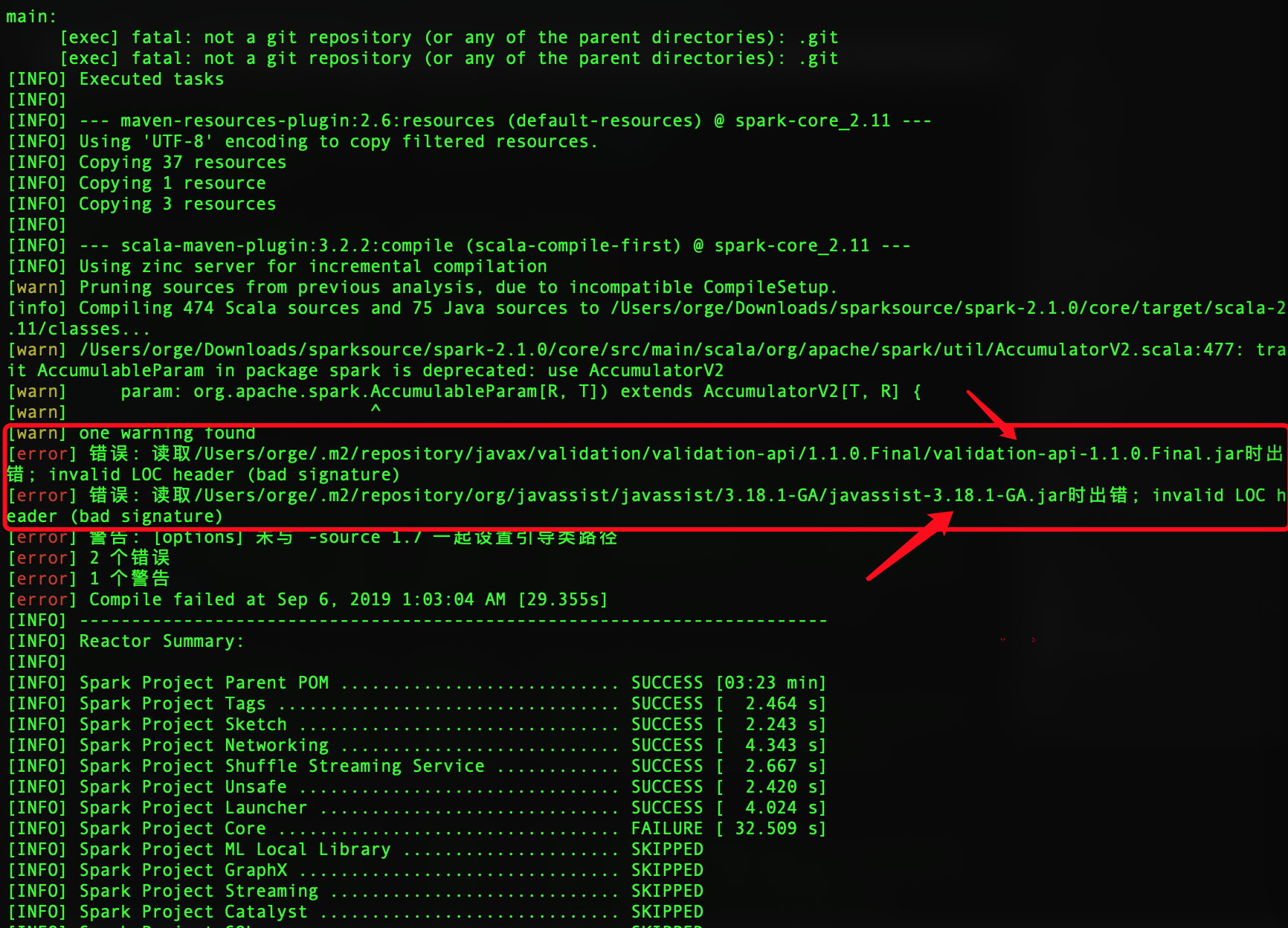
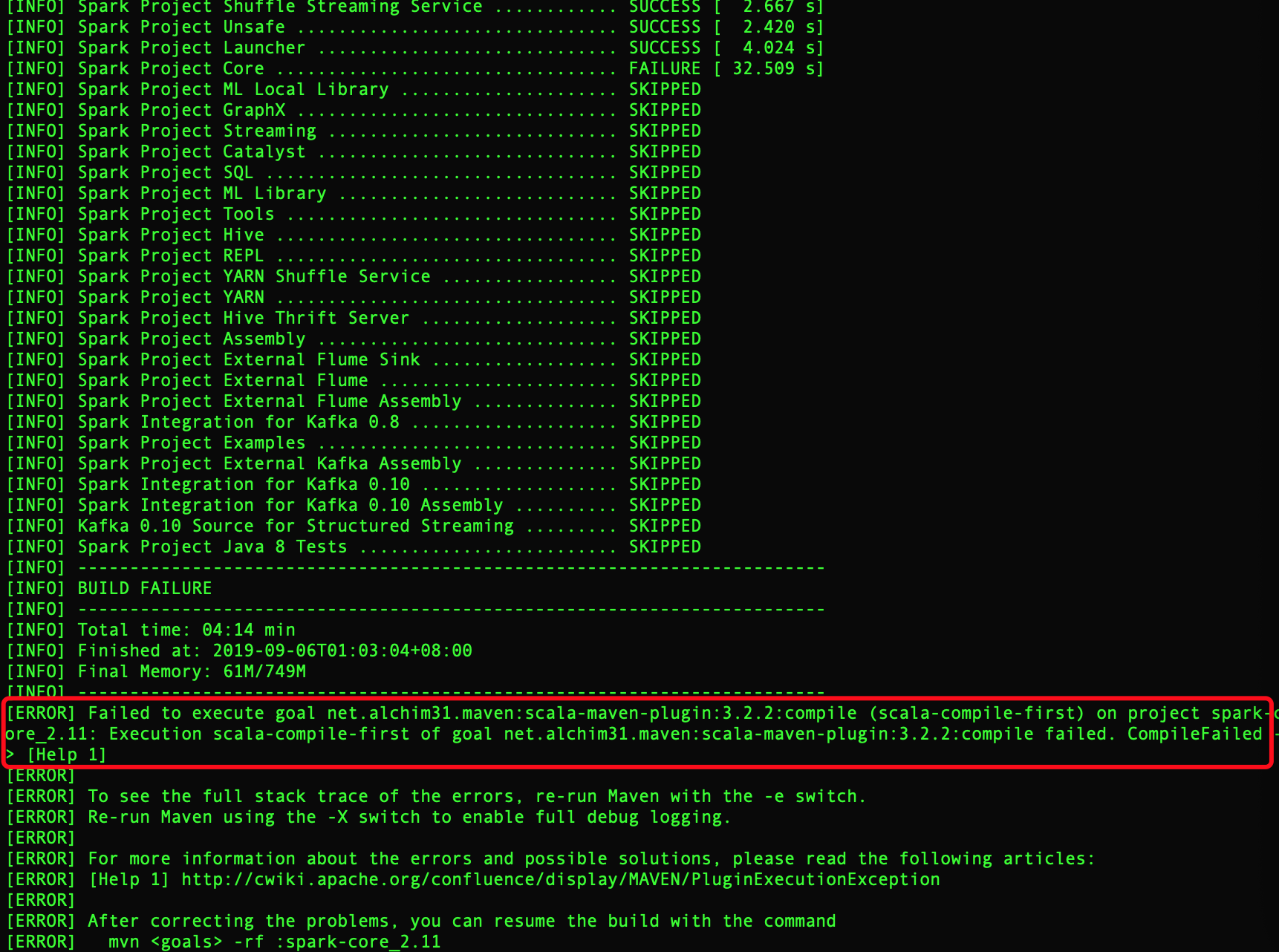
解决方法:
进入maven的仓库目录:
cd ~/.m2/repository/javax/validation/validation-api/1.1.0.Final/
删除错误的jar包,重新编译的时候maven会重新下载对应的jar包。
成功编译如下图:

编译好的源码,直接导入IDEA中就可以调试和阅读spark源码了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号