



DnCNN+SENet+CBAM
Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7839189
图像去噪:从一个有噪声的图像y=x+v中,恢复干净的图像x。
本文将图像去噪看作是一个简单的判别学习问题,即通过前馈卷积神经网络(CNN)将噪声与图像分离。使用CNN的原因有三点:第一是CNN结构非常深,提高了利用图像特征的能力和灵活性;第二是训练CNN的正则化和学习方法方面取得巨大进展,可以加快训练过程并提高去噪性能;第三是CNN适合在GPU上并行计算。
DnCNN并不直接输出去噪图像,而是将DnCNN设计成预测残差图像。同时发现残差学习和批量归一化可以相互受益,有利于CNN学习。
残差学习和批量归一化
残差学习:DnCNN使用单个残差单元来预测残差图像,通过分析其与TNRD的联系,进一步解释残差公式的基本原理,并将其扩展到解决几个一般图像去噪任务中。
批量归一化:通过在每层中的非线性之前引入归一化步骤和缩放和唯一步骤来减轻内部变量偏移。对于批量归一化,每次激活仅添加两个参数,并可以使用反向传播更新它们。
DnCNN模型
采用VGG网络结构并修改,使用残差学习公式进行网络学习,并结合批量归一化。
A:网络深度:
对于有一定噪声水平的高斯去噪,将DnCNN的感受野设置为35*35,对应深度为17;对于其他一般图像的去噪任务,采用更大的感受野并将深度设置为20.

B:网络架构

网络结构:
Conv+ReLU:64个大小为3*3*c的滤波器被用于生成67个特征图。然后将整流的线性单元用于非线性
Conv+BN+ReLU:64个3*3*64的滤波器,并将批量归一化加在卷积和ReLU之间
ConV:c个大小为3*3*64的滤波器被用于重建输出
特征:采用残差学习公式来学习R(y)并结合批量归一化来加速训练并提高去噪性能。
减少边界伪影:零填充策略
残差学习和批量归一化对图像去噪的整合:

图a所示的网络用来训练原始映射F(y)以预测x或残差映射R(y)以预测v。
图b显示了在基于梯度的优化算法和网络结构的相同设置下使用这两种学习公式获得的平均PSNR值,有无批量归一化
一方面,残差学习从批量归一化中受益,从图b可以看出,没有批量归一化的残差学习(绿线)具有快速收敛,它不如批量归一化(红线)的残差学习。
另一方面,批量归一化有利于残差学习。如图b所示,在没有残差学习的情况下,批量归一化甚至对收敛(蓝线)具有一定的不利影响。通过残差学习,可以利用批量归一化来加速训练并提高性能(红线)
Squeeze-and-Excitation Networks
论文地址:https://arxiv.org/pdf/1709.01507.pdf
1.简单介绍:
“Squeeze-and-Excitation”(SE)块 ,通过显式的建模通道间相互依赖的关系,自适应的重新校准通道式的特征响应.通过将SE块堆叠在一起,可以构建SENet架构。
SE块基本结构如下图所示:
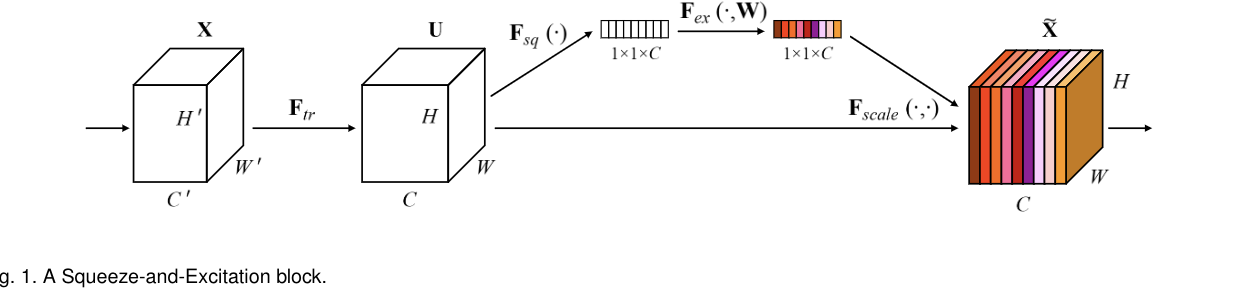
对于任意给定的变换,可以构造一个相应的SE块来执行特征重新校准。
SE网络可以通过简单地堆叠SE构建块的集合来生成。SE块也可以用作架构中任意深度的原始块的直接替换。本论证提出为网络提供一种机制来显式建模通道之间的动态、非线性依赖关系,使用全局信息可以减轻学习过程,并显著增强网络表示能力。
2.Squeeze和Excitation操作
Squeeze操作:顺着空间维度进行特征压缩,将每个二维特征通道变为一个实数,该实数具有全局感受野,并且输出的维度和输入的特征通道数相匹配。公式就是一个global average pooling。
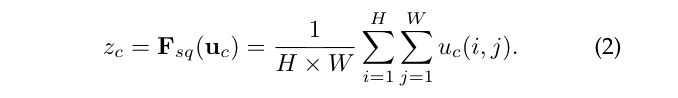
Excitation操作:该操作为了全面捕获通道依赖性,为了实现该目的,必须符合以下两个标准:第一,必须是灵活的(必须能学习通道之间的非线性交互);第二,必须学习一个非互斥的关系。因此采用了一个简单的门激活,并用sigmoid激活:
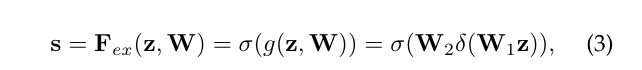
其中![]() 表示ReLU函数。之后为了限制模型复杂性,加上两层全连接层,增加通道维度。最终输出是通过以下调用完成的
表示ReLU函数。之后为了限制模型复杂性,加上两层全连接层,增加通道维度。最终输出是通过以下调用完成的
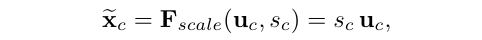
3.具体应用:
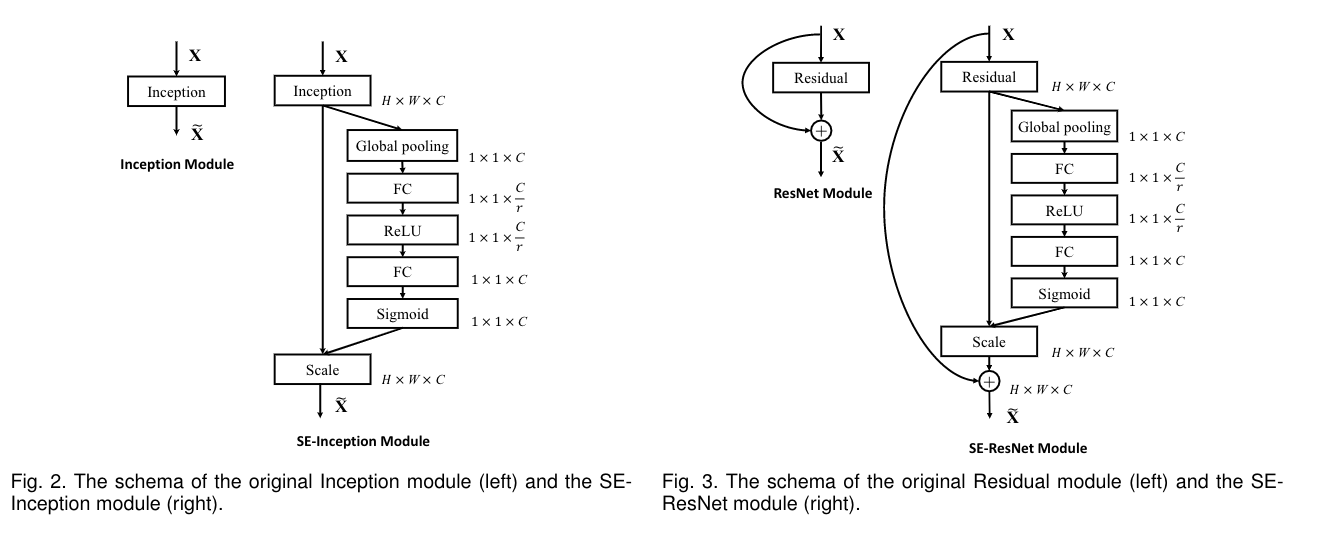
左图是将SE模块嵌入到Inception结构,右图是将SE模块嵌入到ResNet模块中
4.模型和计算复杂度
以ResNet-50和SE-ResNet-50为例:

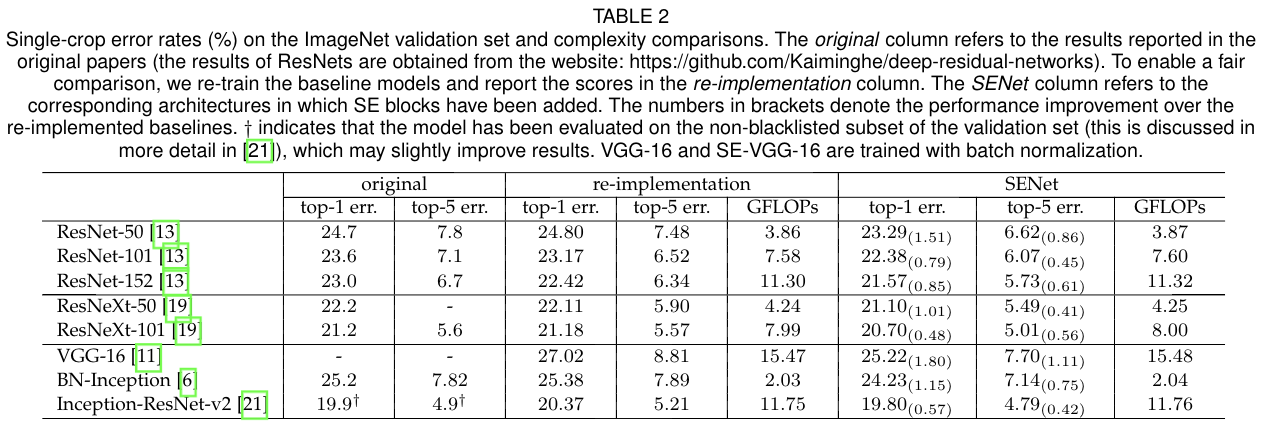
相对于ResNet-50,SE-ResNet-50参数总量增加了10%
5.pytorch代码:
代码地址:https://github.com/miraclewkf/SENet-PyTorch
https://github.com/moskomule/senet.pytorch
se模块:
from torch import nn
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
#第一个FC层起到降维作用
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
#恢复原始维度
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
#采用global average pooling来实现Squeeze操作
y = self.avg_pool(x).view(b, c)
#fc实现Excitation操作
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
CBAM: Convolutional Block Attention Module
论文地址:https://arxiv.org/pdf/1807.06521.pdf
1.简介:
本篇论文提出了一种叫做“Convolutional Block Attention Module”的网络结构,其引用了两个模块:Channel Attention Module和Spatial Attention Module(如下图所示)
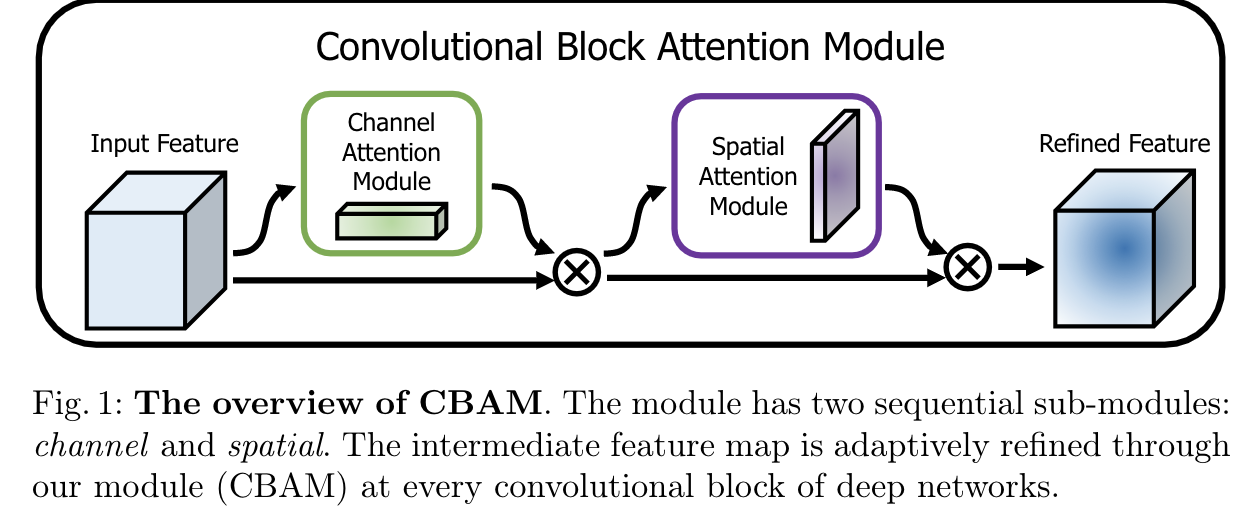
CBAM在channel和spatial两个维度上引入了attention机制。
2.Convolutional Block Attention Module
给出一个特征图F,CBAM可以推测出一维 channel attention map Mc和二维 spatial attention map Ms,整个过程如下图所示
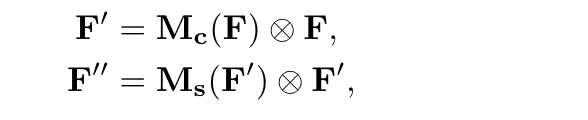
3.Channel attention module
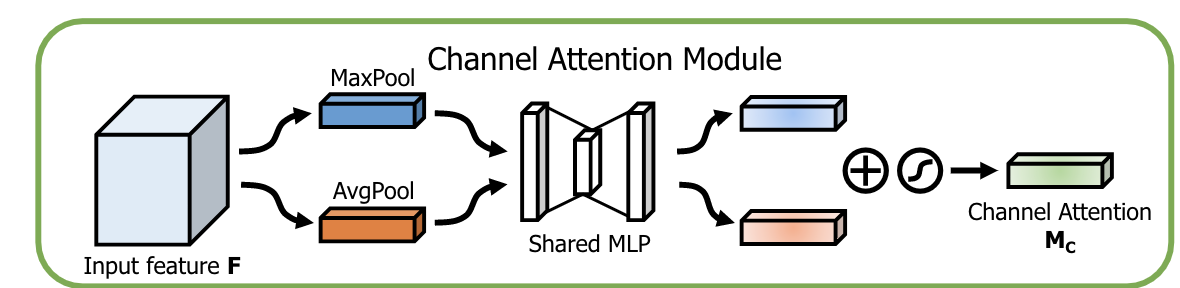
将feature map在spatial维度上进行压缩,与SENet不同的是,这次是通过MaxPool和AvgPool两个pooling函数得到两个一维向量。
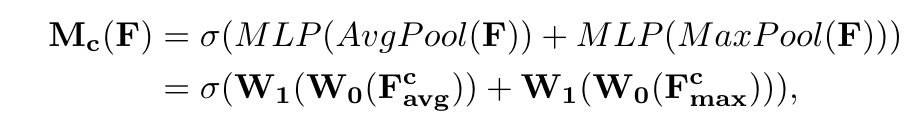
其中![]() 和
和![]() 分别代表经过global average pooling和global max pooling计算后的feature,W0和W1代表的是多层感知机模型中的两层参数
分别代表经过global average pooling和global max pooling计算后的feature,W0和W1代表的是多层感知机模型中的两层参数
4.Spatial attention module
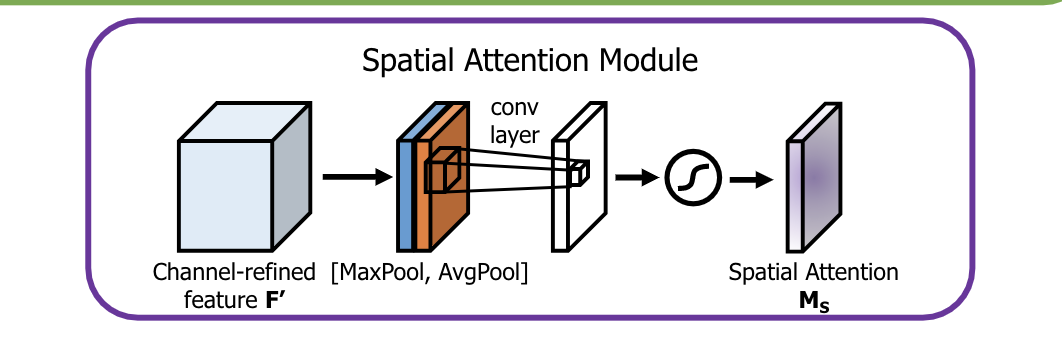
首先使用average pooling和max pooling对输入feature map进行通道压缩操作,对输入特征分别在通道维度上做了mean和max操作。最后得到了两个二维的feature,将其按通道维度拼接在一起得到一个通道数为2的feature map,之后使用一个包含单个卷积核的隐藏层对其进行卷积操作,要保证最后得到的feature在spatial维度上与输入的feature map一

论文代码:https://github.com/luuuyi/CBAM.PyTorch
Channel Attention module:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
Spatial Attention module
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
两个部分的代码结合上半部分的总结很容易理解。

