Python 复习笔记 MySQL
MySQL
以前存储数据不容易,不够详细也不易备份和保存,更不易查找。而现在可以使用文件和数据库(非常特殊的文件)来存储
概念:
1.数据库的优点有:
1.持久化存储
2.读写速度极高
3.保证数据的有效性
4.对程序支撑性非常好,容易扩展
2.数据库中的信息:把每一列称为字段,每一行称为记录,如果能唯一标记某个字段称为主键,主键所在的列称为主键列,记录的集合称为数据表,数据表的集合称为数据库
3.MySQL数据库是关系型数据库
RDBMS(关系型数据库的管理系统)
SQL是结构化的查询语言,是一种用来操作RDBMS的数据库语言,当前关系型数据库都支持使用SQL语言进行操作,也就是说可以通过SQL操作oracle、server、mysql、sqlite等所有的关系型数据库
SQL语句主要分为:
DQL:数据查询语言,用于对数据的查询,如 select
DML:数据操作语言,对数据进行增加、修改、删除。如 insert、update、delete
TPL :事务处理语言,对事务进行处理,包括begin transaction、commit、rollback
DCL :数据控制语言,进行授权与权限回收,如 grant、revoke
DDL :数据定义语言,进行数据库、表的管理等,如 create 、 drop
CCL :指针控制语言,通过控制指针完成表的操作,如 declare cursor
安装:
MySQL: 是用于管理文件的一个软件
1.服务器端软件
socket服务端
本地文件操作
2.客户端软件(各种各样)
socket客户端
发送指令
解析指令
到网站上下载MySQL,然后解压,再用cmd命令窗口执行以下命令 (下面的mysqld 为服务端 mysql 为客户端)
1.MySQL的初始化 xxx\bin\mysqld --initialize-insecure --user=mysql
2.MySQL的安装 xxx\bin\mysqld -install (这样就不用用cmd窗口来启动服务端了,可以用系统服务来启动)
3.MySQL的启动 xxx\bin\net start MySQL
4.停止 : xxx\bin\net stop MySQL
5.登陆MySQL xxx\bin\mysql -u root -p
登录mysql:(因为之前没设置密码,所以密码为空,不用输入密码,直接回车即可)
也可以在环境变量里添加 xxx\bin 这样就不用每次执行都加一大串前缀
SQL语句*
一.操作账户:
默认用户:root
1.创建用户:create user '用户名'@'%'(指定哪些IP地址可以登录) identified by '密码'
2.授权:1.grant select,insert on xx.* to '用户名'@'%'
2.grant select,insert(被授权了select和insert这两个功能) on xx.*或xx.xx(对哪些权限的范围进行指定) to '用户名'@'%' (用户名@IP地址,%表示任意)
3.all privileges(表示所有功能,除了grant 这个功能)
grant all privileges on xx.* to '用户名'@'%'
二.操作文件夹
1.create database db1 default charset utf8; (创建文件夹)
2.show databases ; (显示内容)
3.drop database db1; (删除文件夹)
三.操作文件(表)
1.进入表: use db1; (进入)
2.显示表: show tables; (显示表)
3.创建表:
1 create table t1( 2 id int unsignde auto_increment primary key, 3 num decimal(10,5), 4 name char(10) 5 age ENUM('1','2','3') 6 col SET('a','b','c') 7 ) engine=innodb default charset=utf8;
4.delete from t1; (清空表,且会之前的自增会继承)即,如果把序号3删了,再插入数据就是4
5.truncate table t1; (也是清空表,但自增不继承,而且清空速度比较快)
6.drop table t1; (删除表)
7.如果上传文件或图片之类的就上传它的路径
# 列名 类型(接受数据大小)字段后都可以接null,not null(是否支持为空),接unsigned(表示有无符号);
# auto_increment primary key(一个表只能有一个)
————auto_increment(表示自增)
————primary key (表示约束:(不能重复且不能为空)和加速查找)
# engine表示使用什么引擎 innodb(支持事务,操作可以回滚,原子性操作)myisam (支持全局检索)
数据类型:
数字:
1.tinyint 小整数 有符号:-128 ~ 127. 无符号:0 ~ 255
2.int 整数 有符号:-2147483648 ~ 2147483647 无符号:0 ~ 4294967295
3.bigint 大整数
4.decimal[(m[,d])] 准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。
精确一点的数字(总位数,小数点后的位数)表示精确的小数比float和double精准
5.FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
6.DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
字符:
1.char(10)会自动填充满10个,比如:查询速度快;
2.varchar(10) 不会,比较节省空间(所以应该把定长的放前面,变长的放后面)
因为要查询char(10)后面的数据时只要直接跳过10个字符就好了,而varchar(10)不知道要跳过多少个
# ENUM()枚举类型,只能插入其中单个内容
# SET()集合类型,只能插入括号中的任意组合
四.操作文件中的内容(增删改查)
1.增
insert into t1(name) values ('小明'),('小红') ; # 一次性其实可以插入多条的
insert into t1(name) select name from t2; # 可以从别的表复制一份出来
2.删
delete from t1 where xx =!>< and or # 后可以接where条件语句,支持逻辑符号 != 也可以写成 <>
3.改
update t1 set name = 'xx' where # 同理可以接where
update t1 set name = 'xx' ,age = 12 ; # 可以改多列
4.查*
1.select id from t2 where .... # 同理
2.select id as idd from t2 ; # 可以修改查看时的表头(列的标题名称),且不影响原来的内容
3.select id,11 from t2; # 可以在查询的地方加上一个常量,这样查看的时候表头会多出一列标题和内容的是常量的列
4.select * from t1 where id in/not in (1,3,5); # 可以查询id是/不是1,3,5的,不需要用多个or
5.select * from t1 where id between 1 and 3; # 闭区间,取1,2不取3
6.select * from t1 where id in(select id from id2) ; # 可以查交集
7.通配符:select * from t1 where name like 'a%'
1.以a开头
a% 表示ab,abc,abcd..... 范围比较广,可以匹配多位
a_ 表示ab,ac,ad 只能匹配一位,abc不能匹配
2.以a结尾 %a,_a
包含a %a%,%a_ ......
8.select * from t1 limit 10; # 取前10个
9.select * from t1 limit 20,10; # 从20开始,向后取10条
10.select * from t1 limit 10 offset 20 ; # 效果和上面👆一样
11.排序:
select * from t1 order by id desc; # 从大到小
select * from t1 order by id asc; # 从小到大
select * from t1 order by id desc limit 10; # 这样就可以取后十条了
select * from t1 order by id desc,age asc; # 可以多个排列,当用 id 排有相同时,相同的项按 age 排
12.分组
1.select part_id from t1 group by part_id; # 根据 part_id 进行分组,显示所有人
2.select part_id,max/min(id) from t1 group by part_id; # 当分组后同一分组有多个时,取 “id” 最大/最小的
3.select count(id),part_id from t1 group by part_id; # 每个分组有几个 “id"
4.聚合函数还有 count max min sum avg ... # 而且可以写多个
5.如果对聚合函数进行二次筛选时,必须使用 having
select count(id),part_id from t1 group by part_id having count(id) > 1;
13.连表操作
1.如果想显示两个(多个)表且两个表有关联
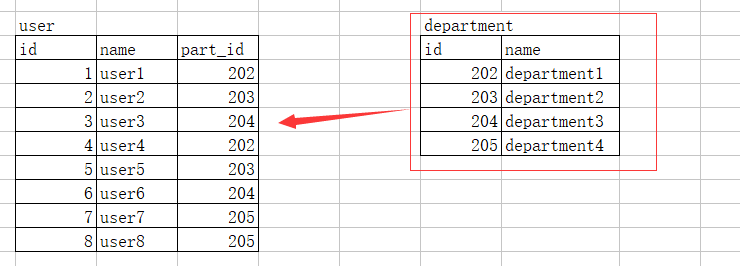
select * from user,department where user.part_id = department.id;
如果不加条件则每个用户会出现4次,属于每个部门
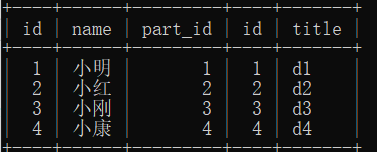
2.select * from user left join department on user.part_id = department.id ; # 这样就是左连接,记得要用 on
# 左边全部显示,user有多少显示多少,如果有空的部门ID 也不显示
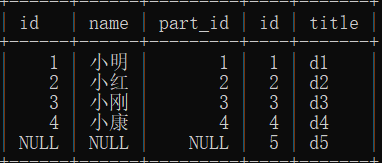
3.select * from user right join department on user.part_id = department.id; # 这样就是右连接
# 右边全部显示,如果有空的部门ID 也会显示为空NULL
当然也可以这样子混过去(/ □ \) select * from department left join user on user.part_id = department.id;
4.select * from user innder join department on user.part_id = department.id; # 如果结果出现NULL就会整行隐藏掉
5.select * from t1 union select * from t2; # 这是上下连表,只有union会自动去重
6.select * from t1 union all select * from t2; # 即使有重复的也不会重合
7.如果连表时,列名出现重复,就可以 select 表名.列名 from xx;
5.视图:
当重复使用到某个查询语句时,可以设置别名,方便日后使用,这样就叫做创建视图
1.创建:
create view 视图名称 as 查询语句 # 这是虚拟的,原来的表改变这个视图也会改变
2.修改:
alter view 视图名称 as 查询语句
3.删除:
drop view 视图名称
6.触发器:
1.在创建时,要先修改终止符,否则执行到;时就会终止,不会执行END,这样就创建不出触发器
delimiter // # 这样可以把终止符改成//
2.create trigger 名称 before/after insert on tb1 for each row begin SQL语句; END //
# 在表执行XX命令前/后时,开始执行 另一条语句
3.begin 的SQL语句可以使用NEW来取得插入的一行数据,也可以用NEW.XX来取得插入数据的某一列
删除时可以用到OLD,更新时就有NEW和OLD
比如 begin insert into t2(tname) values(NEW.sname)
4.创建完之后应该改回来 delimiter ;
5.有插入删除更新 insert delete update
7.函数:
1.内置函数
对时间进行修剪(假如time 为 2020-1-1)
select date_format(time,"%Y-%m") from t1 group date_format(time,"%Y-%m")
这样就可以通过年月对表信息进行分组
2.自定义函数
1 delimiter \\ 2 create function f1( 3 i1 int,i2 int) returns int # 限定参数和返回的值只能是int类型 4 BEGIN 5 declare num int; # 声明变量,还可以在声明变量时赋值 declare num int default 0 ; 6 set num = i1+i2; 7 return(num) 8 END \\ 9 delimiter; 10 select f1(1,2); 结果就是3
不然在过程中执行select * from t1;之类的
如果出现1418错误可以使用以下方法:
1.在客户端上执行SET GLOBAL log_bin_trust_function_creators = 1;
2.MySQL启动时,加上--log-bin-trust-function-creators,参数设置为1
3.在MySQL配置文件my.ini或my.cnf中的[mysqld]段上加log-bin-trust-function-creators=1
8.存储过程*
保存在MySQL上的别名 》》》》》一堆SQL语句,跟视图不一样,视图是表
这样就不用写基础的SQL语句了 ,有人在数据库中写了就能直接使用
1.简单存储过程
1 delimiter \\ 2 create procedure p1() 3 BEGIN 4 select * from t1; 5 insert into t1(id) values(1) 6 END \\ 7 delimiter ; 8 call p1() 9 Python中用cursor.callproc('p1')
2.传参数(in、out(跟return差不多)、inout)
delimiter \\ create procedure p1( in n1 int, out n2 int ) BEGIN select * from t1 where id > n1; n2 = n1 END \\ delimiter ; set @v1 = 0 call p1(2,@v1) # 相当于把V1当成n2传进去 select @V1; cursor.callproc('p1',(2,X))
3.特性:
1.可传参: in out inout
2.虽然没有return 但是可以用out伪造一个return
3.为什么有结果集,又有out伪造的返回值?
用于表示存储过程的执行结果(看下面的例子)
4.事务:
delimiter \\ create procedure p1( out n1 tinyint ) BEGIN # 声明如果出现异常所执行的语句 DECLARE exit handler for sqlexception BEGIN -- ERROR set n1 =1; # 如果执行失败 n1=1 rollback; # 执行回滚 END; START TRANSACTION; # 开始事务 select * from t1 where id > n1; COMMIT; # 如果执行没有出错就提交 -- SUCCESS set n1 = 2 # 如果执行成功 n1=2 END \\ delimiter ;
5.游标:(可以在MySQL中简单实现一些循环)
1.声明游标
my_cursor select aid,anum from A

获取A表数据中取数据
2.for row_id,row_num in my_cursor :
# 检测循环是否有数据,如果无数据就 break (要自己检测)
insert into B(bnum) values(row_id+row_num)
示例


1 delimiter \\ 2 create procedure p1() 3 BEGIN 4 declare row_id int ; # 自定义变量1 5 declare row_num int ; # 自定义变量2 6 declare done INT DEFAULT FALSE ; # 初始为FALSE,判断循环是否终止 7 8 declare my_cursor CURSOR FOR select aid,anum from A ; # 定义游标,从表A中获取数据 9 declare CONTINUE HANDLER FOR NOT FOUND SET done = TRUE ; # 判断,当没有数据时设done=TRUE 10 open my_cursor; # 光标开始执行 11 xxoo:LOOP # 开始循环,循环名为xxoo 12 fetch my_cursor into row_id,row_num; # 获取row_id和row_num 13 if done then # 如果done为TRUE就离开循环 14 leave xxoo; 15 END IF; 16 17 insert into B(num) values(row_id+row_num); 18 end loop xxoo; 19 close my_cursor 20 END \\ 21 delimiter ;
6.动态执行SQL(防SQL注入)
1 delimiter \\ 2 create procedure p1( 3 in arg int 4 ) 5 BEGIN
1.预检测 SQL语句的合法性
2.初始化SQL=tpl+arg
3.执行SQL语句
1 set @v1 = arg; 2 PREPARE prod FROM 'select * from A where id > ?'; 3 EXECUTE prod USING @v1; # 只接受会话级别的变量,把?替换成@v1 4 DEALLOCATE prepare prod ; # 执行SQL 5 END \\ 6 delimiter ; 7 8 call p1(6)
7. 自增操作
alter table xx auto_increment=10x; 可以设置自增量
自增步长可以设置成会话级别或全局级别的:
会话:set session auto_increment_increment = 2;
全局:set globalauto_increment_increment = 2;
自增初始值同理:
set auto_increment_offset=XX;
五.外键
优点:
节省空间
制定约束
操作:
1 创建一个表 2 create table t1( 3 id int unsignde auto_increment primary key, 4 name char(10), 5 department_id int, 6 ) engine=innodbd efault charset=utf8; 7 再创建外键的表 8 create table department( 9 id int unsignde auto_increment primary key, 10 title char(10) 11 ) engine=innodbd efault charset=utf8; 12 加入约束 13 这个方法要先创建表二 14 create table t1( 15 id int unsignde auto_increment primary key, 16 name char(10), 17 department_id int, 18 constraint fk_admin_t1 foreign key (department_id) references userinfo1 department(id) 19 ) engine=innodbd efault charset=utf8; 20 或者 21 alter table t1 add constraint fk_t1_department foreign key (department_id ) references department(id) on [delet/update ]reference_option
其中 reference_option 有以下几种(默认为RESTRICT):
1.CASCADE,级联删除/级联更新,即主表delete或update了被其他表引用的数据,对应子表的数据也被delte或update;
2.SET NULL,当主表delete或update了被其他表引用的数据,对应子表的数据被设为null,注意子表的外键不能设为not null;
3.RESTRICT,主表不允许delete或update被其他表引用的数据;当没有指定时,默认是采用RESTRICT
4.NO ACTION,在MySQL中,等效于RESTRICT;
一般来说是外键是一对多,但是如果想要一对一 可以在添加外键的同时,添加唯一索引
多对多 在查找主机的使用者时,可以使用以下方法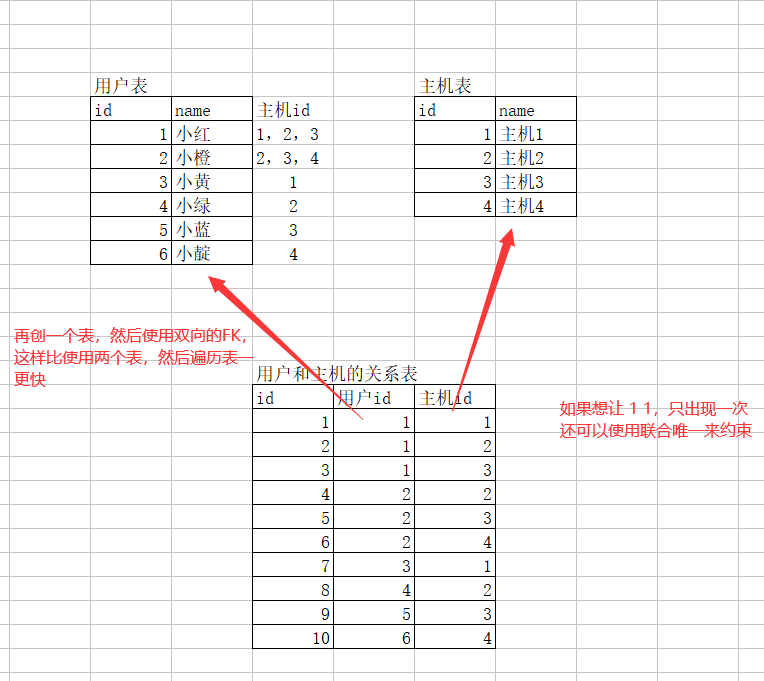
六.主键和外键的补充
1.每个表只能有一个主键,但是主键不一定只有一列,可以有多列:
(id1 int not null,
id2 int not null,
primary key(id1,id2)) ; # 把两列组合成主键
2.所以用外键约束时,也可以写两列 foreign key (id1,id2 )
七.索引:
1.create table t1(id 1int,id2 int, unique uql(id1,id2));一个称为唯一索引,两个称为联合唯一
2.好处:
1.约束:不能重复(可以回空) # 主键也不能重复(不能为空)
2.加速查找
3.索引
1.普通索引:加速查找
2.主键索引:加速查找 + 不能为空 + 不能重复
3.唯一索引:加速查找 + 不能重复
4.联合索引 (联合唯一索引)
1.联合主键索引(多列联合起来作为主键索引)
2.联合唯一索引(多列联合起来作为唯一索引)
3.联合普通索引
4.加速查找(索引就像一个目录一样,如果没有目录就要从头到尾看一遍)
无索引:从前到后依次查找
有索引:
会创建一个额外文件,如果查找时,先到额外文件茶,查到了再到数据库里找
索引种类
1.hash索引:把内容转换成hash值,把它的值和在数据库的地址存储成一个表,但位置和原来数据库的数据位置不同
优点:查找单值时非常快
缺点:不能按范围查找,如果想要按ID查到,但hash索引位置不固定就不能查找出来
2.btree索引:
把数据转换成数字然后放进二叉树中,假如是1024不需要从1查到1024查1024次,只需要2**10,查找10次
5.建立索引:
1.额外的文件保存特殊的数据结构
2.查询快;插入更新删除慢,因为在数据库和索引中同时改动
3.命中索引(创建索引并使用了索引,如果没有使用就是扯蛋)
select * from userinfo where name = '小明'; 快
select * from userinfo where name like '小明'; 慢
4.主键索引:一般创建表的时候都会创建主键,通过主键的索引就是主键索引
5.普通索引:
create index 索引名称 on 表(列名)
能创建就能删除 :drop index 索引名称 on 表;
6.唯一索引:(创建表的时候也能创建)
create unique index 索引名称 on 表(列名)
同理:drop unique index 索引名称 on 表;
7.联合索引:(普通联合索引和唯一联合索引)
create (unique) index 索引名称 on 表(列名,列名)
同理:drop (unique) index 索引名称 on 表;
最左前缀匹配:
1 create index 索引名称 on 表(id,name) ; 2 select * from userinfo where id = 9; 3 select * from userinfo where name = '小明'; 4 select * from userinfo where id = 9 and name = '小明'; # 前三种都会使用索引 5 select * from userinfo where name='小明' and id = 9; # 最后一种不是使用索引 6 # 假如列名有ABC三种 A、B、C、AB、AC、BC都会使用索引BA、CB、CA之类的都不都会使用索引,以此类推 7 组合索引效率>索引合并,但索引合并比较灵活,看情况使用
8.覆盖索引:(不是真的索引,是一种专有名词)
select id from t1i where id = 9; (假设id已经创建了索引)
这不同于 * from 从数据表中查询, id from 是直接在硬盘中创建的那个id索引文件中找条件ID
9.索引合并:(也不是真的索引,是一种专有名词)
把多个单列索引合并使用
select * from t1 where id = 9 and name = '小明' ; (假设ID和NAME都创建了索引)
这样同时使用两个单列索引的方法就叫索引合并
6.通过执行计划预估扫描时间:
虽然索引有这么多规矩,但最终判断命中索引的正确还是要通过时间,时间短才是王道。
不过也不能每次都执行语句来检测每一个的时间,然后在判断哪个时间短,所以就要用到一个工具MySQL自带的执行计划:让MySQL预估执行操作的时间(一般是正确的)
explain select * from t1;
查询出来有个type,它说明SQL语句是用什么方式访问表的,有以下几种方式,一般是通过访问方式来判断语句的查询速度
性能排序为 all<index<range<index_merge<ref_or_null<ref<eq_ref<system/const
1.ALL : 全表扫描,把数据表从头到尾找一遍 如:select * from t1; 但是也有特例,如limit explain select * from t1 limit 1; # 这个的访问类型也是ALL 但是它的执行速度也很快,因为他如果找到了所要的数据就不继续扫描了,所以访问方式也只是做个参考 2.INDEX:全索引扫描,对索引从头到尾找一遍 如:select id from t1; 3.RANDE:对索引列进行范围查找 如 select * from t1 where id = 9; 4.INDEX_MERGE : 合并索引,使用多个单列索引搜索 如:select * from t1 where id = 9 or name = '小明'; 5.REF:根据索引查找一个或多个值 如 : select * from t1 where name = '小明' 6.EQ_REF:连接时使用primary key 或 unique类型 7.CONST:常量(表最多有一个匹配行,因为仅有一行,在这行的列值可以被优化器剩余部分认为是常数,const表很快,因为它们只读取一次) 如:select id from t1 where id = 2; 8.SYSTEM:系统(表只有一行=系统表。这是const联接类型的一个特例) 如:select * from (select id from t1 where id = 2) as A;
7.温馨提示:
1频繁使用的列表才建立索引,否则平时的插入更新删除会变慢
2.如果数据被频繁查询到最好别用 like 来查找,最好用第三方工具来查找
比如数据是
| ID | DATA |
| 1 | 英国政府表示,不会提前宣布进行全国隔离,因为会导致英国民众隔离“行为疲劳 |
| 2 | 这样同时使用两个单列索引的方法就叫索引合并 |
| 3 | 英国政府表示,不会提前宣布进行全国隔离,因为会导致英国民众隔离“行为疲劳 |
ID 1,3 数据date内容都是:英国政府表示,不会提前宣布进行全国隔离,因为会导致英国民众隔离“行为疲劳”。)
1.like查询就是 select * from t1 where date like '%英国政府%' ; (比较慢)
2.而第三方工具 会把创建一个文件解析内容把“英国政府”,“全国隔离”,“行为疲劳” 记录到 ID 1,3然后select * from t1 where id in (1,3);
3.尽量不要使用函数来操作数据库(如翻转),不然会改变保存数据的方式,如果想要修改显示的方式可以在Python中修改显示
select * from t1 where reverse(name) = '小明':
4.OR(假设ID和name有索引)
1.select * from t1 where id = 9 or title = '时间'; (假设ID有索引,title没有索引,查找也会很慢)
2.但是如果select * from t1 where id = 9 or title='时间' and name = '小明' (但是如果是这样就会用ID和NAME进行索引,跳过title)
5.查询时的数据类型要和列类型一样,不然搜索时也会变慢
假如 name 列是 char 类型,如果用数据作为条件去查询
即select * from t1 where name = 9; 就会很慢
6.避免使用select *
7.count(1)或者count(列名)来代替count(*)
8.创建表时尽量用char来代替varchar
9.表的字段顺序固定长度的字段优先
10.组合索引代替多个单列索引(如果经常用到的话)
11.尽量使用短索引:比如都是9位数字的邮箱就可以只取前几位来建立索引,create index xx on t1(title(9))
12.使用连接(JOIN)来代替子查询
13.连表时注意条件类型要一致
14.索引散列值(重复数据比较少)不适合建立索引,比如:性别 就不合适
八.学会使用 Navicat,不过SQL语句依旧是必须要会的
1.导出:
mysqldump -u root db1 > db1.sql -p # 这样导出包含数据结构和数据
mysqldump -u root -d db1 > db1.sql -p # 这样导出只有数据结构没有数据
2.导入:
先创建一个文件夹 db1
然后 mysqldump -u root db1 < db1.sql -p
3.临时表:
(select * from t1) as L; # 创建临时表,还可以继续查询临时表
即 select * from (select * from t1) as L;
4.去重:
select distinct id from t1 where score > 90; # 如果成绩大于90的id有重复的话就去掉重复的
5.IF:
case when A>B then A=0 else B = 0; # 这个就跟IF语句一样
三元运算 if (exp1,exp2,exp3) # 假如exp1成立,结果就是exp2,否则就是exp3
比如: if(isnull(num),0,num) 如果num这个值为空就显示0否则就显示num的值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号