Python rabbitMQ
实现的效果:可以使自己的Queue队列让别人使用,通过socket数据互通
基础代码实现:
# ————————生产者—————————— import pika # 创建连接 connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'locahost')) # 创建频道 channel = connection.channel() # 创建队列 channel.queue_declare(queue = 'hello') channel.basic_publish(exchange='', routing_key='hello', # 队列名 body='Hello World!') # 内容 print("[X]Sent 'Hello World!'") connection.close() # ————————消费者—————————— import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'locahost')) channel = connection.channel() channel.queue_declare(queue = 'hello') def callback(ch,method,properties,body): print("[x]Received %r" % body) import time time.sleep(3) print('ok') ch.basic_ack(delivery_tag = method.delivery_tag) # 告诉队列处理完了 channel.basic_consume(callback, queue = 'hello', no_ack = True) print('[*]Waiting for messages. To exit press CTRL+C') channel.start_consuming()
1、acknowledgment 消息不会丢失
no_ack = False # 如果消费者遇到情况,不能完成处理,那么rabbitMQ会重新把该任务添加到队列中,避免数据丢失
2、durable(持久化保存) 消息不丢失
# 在创建队列时注明需要持久化保存 channel.queue_declare(queue='hello',durable = True)
可以和ack一起用,这样就是双重保障
3、取数据时候是按顺序取的,如果有的处理速度比较慢,继续按顺序取的话,就浪费时间了,所以rabbitMQ是跳着取自己需要的信息的
假如A、B、C都需要处理两条信息,A取1,B取2,C取3,如果A处理比较快,它会跳过2,3,直接取4号信息
但是也可以设置,谁先处理完,谁先去,如果A处理速度比较快,它可能会把2,3,4,5,6号信息全取走处理,配置如下
channel/basic_qos(prefetch_count=1)
4、往队列存放数据是 exchange 帮我们做的,因为如果我们想往多个队列发送数据,就需要多个连接,如果我们把数据放到exchange,只需连接exchange就会帮我们把数据发送给我们想发送的多个队列
1、exchange类型——fanout(发布订阅)
所有于exchange连接的队列都会收到消息,给所有队列
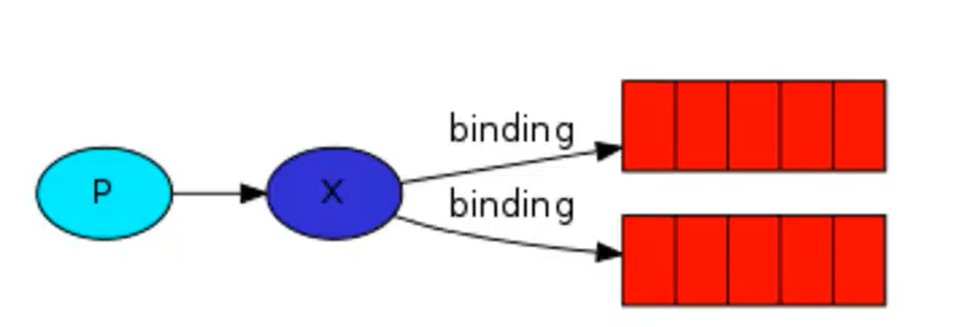
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'locahost')) channel = connection.channel() # 把exchange 类型设置为fanout channel.exchange_declare(exchange= 'logs',type = 'fanout') # 给队列随机取名 result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 绑定信息 channel.queue_bind(exchange='logs',queue=queue_name) print('[*]Waiting for messages. To exit press CTRL+C') def callback(ch,method,properties,body): print("[x] %r" % body) # 生产者——————————(不管是生产者还是消费者都需要设定类型) channel.basic_publish(exchange='logs',routing_key='',body='内容') connection.close() # 消费者——————————(需要取名、绑定信息和定义函数) channel.basic_consume(callback,queue=queue_name,no_ack=True) channel.start_consuming()
2、exchange类型——(关键字)
给队列设定关键字,一个关键字可以匹配多个队列,当发送方发送时,可以带上关键字,exchange会识别并发送
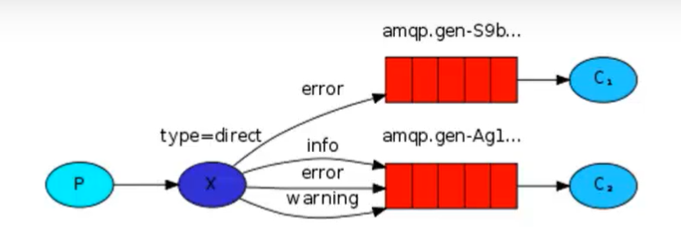
channel.exchange_declare(exchange= 'logs_direct',type = 'direct') # 生产者——发送的时候指定关键字 channel.basic_publish(exchange='logs_direct',routing_key='关键字',body='内容') # 消费者——把队列和关键字绑定起来 channel.queue_bind(exchange='logs_direct',queue_name='队列名',routing_key='关键字')
3、exchange类型——topic 关键字匹配之模糊匹配~~~
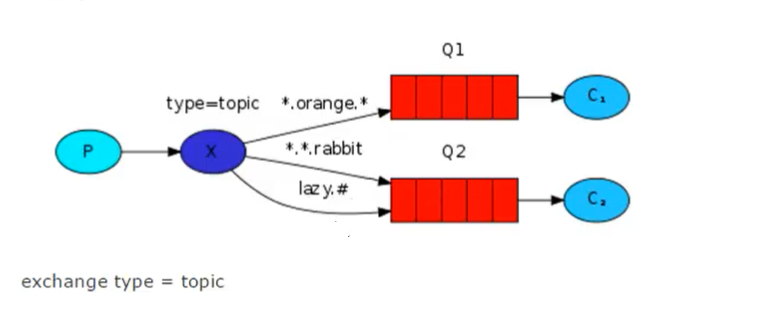
假设关键字是abcd,那么发送方可以把 ab.#或abc.*......等等最为关键字进行模糊匹配
# 表示可以匹配0个或多个单词
* 表示只能匹配一个单纯

 浙公网安备 33010602011771号
浙公网安备 33010602011771号