insert into t1(name) values ('小明'),('小红') ; # 一次性其实可以插入多条的
insertintot1(name) select name from t2; # 可以从别的表复制一份出来
删
delete from t1 where xx =!>< and or # 后可以接where条件语句,支持逻辑符号 != 也可以写成 <>
改
update t1 set name = 'xx' where # 同理可以接where
update t1 set name = 'xx' ,age = 12 ; # 可以改多列
查*
select id from t2 where .... # 同理
select id as idd from t2 ; # 可以修改查看时的表头(列的标题名称),且不影响原来的内容
select id,11 from t2; # 可以在查询的地方加上一个常量,这样查看的时候表头会多出一列标题和内容的是常量的列
select * from t1 where id in/not in (1,3,5); # 可以查询id是/不是1,3,5的,不需要用多个or
select * from t1 where id between 1 and 3; # 闭区间,取1,2不取3
select * from t1 where id in(select id from id2) ; # 可以查交集
通配符:select * from t1 where name like 'a%'
以a开头
a% 表示ab,abc,abcd..... 范围比较广,可以匹配多位
a_ 表示ab,ac,ad 只能匹配一位
以a结尾 %a,_a
包含a %a%,%a_ ......
select * from t1 limit 10; # 取前10个
select * from t1 limit 20,10; # 从20开始,向后取10条
select * from t1 limit 10 offset 20 ; # 效果和上面👆一样
排序:
select * from t1 order by id desc; # 从大到小
select * from t1 order by id asc; # 从小到大
select * from t1 order by id desc limit 10; # 这样就可以取后十条了
select * from t1 order by id desc,age asc; # 可以多个排列,当用 id 排有相同时,相同的项按 age 排
分组
select part_id from t1 group by part_id; # 根据 part_id 进行分组,显示所有人
select part_id,max/min(id) from t1 group by part_id; # 当分组后同一分组有多个时,取 “id” 最大/最小的
select count(id),part_id from t1 group by part_id; # 每个分组有几个 “id"
聚合函数还有 count max min sum avg ... # 而且可以写多个
如果对聚合函数进行二次筛选时,必须使用 having select count(id),part_id from t1 group by part_id having count(id) > 1;
连表操作
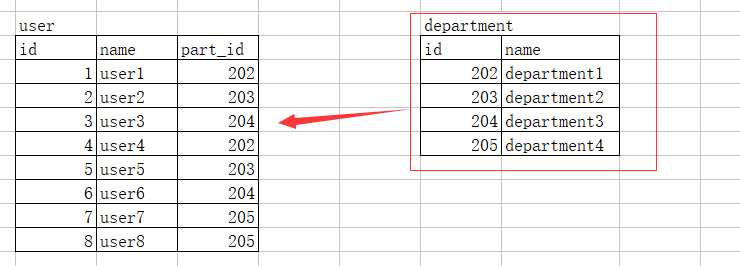
如果想显示两个(多个)表且两个表有关联 select * from user,department where user.part_id = department.id; 如果不加条件则每个用户会出现4次,属于每个部门
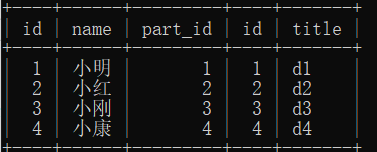
select * from user left join department on user.part_id = department.id ; # 这样就是左连接,记得要用 on # 左边全部显示,user有多少显示多少,如果有空的部门ID 也不显示
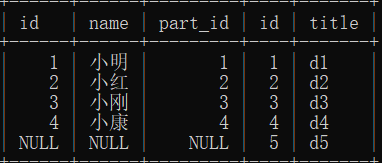
select * from user right join department on user.part_id = department.id; # 这样就是右连接 # 右边全部显示,如果有空的部门ID 也会显示为空NULL 当然也可以这样子混过去(/ □ \) select * from department left join user on user.part_id = department.id;
select * from user innder join department on user.part_id = department.id; # 如果结果出现NULL就会整行隐藏掉
select * from t1 union select * from t2; # 这是上下连表,只有union会自动去重
select * from t1 union all select * from t2; # 即使有重复的也不会重合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号