综合练习——寻找有潜力的bilibili百大UP主(1)
寻找有潜力的bilibili百大UP主(1)
防喷说明:以下仅为个人学习之余的娱乐项目,本人不主动赋予以下内容任何价值,不确保内容的准确性
欢迎各位友善的指出错误
需求描述
预测B站UP主是否有潜力成为百大UP主或知名UP主
需求是自拟的,随口提的一个想法
需求分析
关键字:预测、分类
这个需求的还是比较容易理解的,我们需要构建一个判别体系,这个判别体系能够通过已知的数据将其分到已知的类别中。
我们需要做的是
- 确定判别体系
- 获取所需数据
- 数据清洗、统计
- 确定训练模型及方法
- 训练模型
- 评价模型
判别体系
由于B站并没有公布百大UP主选取的标准(就算有也当它没有好吧),于是我们需要自己选取样本值
第一次选取
括号内为特征权重,权重总和100%
| 粉丝群体相似度(16%) | 平均视频标题字数(8%) | 平均视频时长(12%) | 平均投稿时间段(12%) | 平均弹幕占播放量比值(9%) | 平均投币占播放量比值(12%) | 平均点赞占播放量比值(9%) | 平均收藏占播放量比值(10%) | 平均评论占播放量比值(12%) |
|---|
这个判别体系是我认为能够比较客观比较UP主间类别的判别体系。
- 粉丝群体相似度:准备获取每位UP主的粉丝列表,然后用Tanimoto分值计算相似度
- 平均视频标题字数:标题长短可能有些影响,给的权重不是很多
- 平均视频时长:视频时长相似的更有可能是同一类UP
- 平均投稿时间段:选择时间点投稿一直是门玄学
- 平均弹幕占播放量比值:弹幕是视频的增香剂,好的视频弹幕量一定不少,但刷弹幕相对容易所以权重降低
- 平均投币占播放量比值:投币是对优质视频的肯定,同时刷投币比较难,所以权重高
- 平均点赞占播放量比值:点赞相对来说是比较容易的,刷点赞也多,所以权重低
- 平均收藏占播放量比值:收藏对我个人而言还是比较难接受的,就算他是优质资源也很反感收藏(可能这也是为什么呢么多下次一定的原因),所以权重相对降低
- 平均评论占播放量比值:也反映了视频质量,同时出于面子不会机刷评论,所以权重高
但由于B站对于查看他人粉丝有数量限制,无法获取UP主的完整粉丝名单,所以粉丝群体相似度这一特征无法实现
第二次选取
| 平均视频标题字数(10%) | 平均视频时长(15%) | 平均投稿时间段(15%) | 平均弹幕占播放量比值(10%) | 平均投币占播放量比值(14%) | 平均点赞占播放量比值(10%) | 平均收藏占播放量比值(12%) | 平均评论占播放量比值(14%) |
|---|
获取所需数据
确定完判别体系,我们接下来确定需要哪些数据
- 样本基本信息,及UP主的ID、昵称、头衔
- 通过ID获取每个UP的所有粉丝
- 通过ID获取每个UP的所有视频的标题、时长、发布时间、播放量、弹幕数、投币、点赞、收藏、评论
本人关注列表
-
请求URL
-
https://api.bilibili.com/x/relation/followings?
-
-
请求头参数
-
referer: https://space.bilibili.com/{vmid}/fans/follow cookie: {cookie}
-
-
携带参数
-
vmid: {vmid} pn: 2 ps: 20 order: desc order_type: attention
-
UP基本信息
-
请求URL
-
https://api.bilibili.com/x/space/acc/info?
-
-
携带参数
-
mid: {mid}
-
UP视频信息
标题、时长、发布时间、播放量
-
请求URL
-
https://api.bilibili.com/x/space/arc/search?
-
-
请求头参数
-
referer: https://space.bilibili.com/{vmid}/fans/follow
-
-
携带参数
-
mid: {mid} ps: 1 tid: 0 pn: 1 order: pubdate jsonp: jsonp
-
弹幕、投币、点赞、收藏、评论
-
请求URL
-
https://api.bilibili.com/x/web-interface/archive/stat?
-
-
请求头参数
-
referer: https://space.bilibili.com/{vmid}/fans/follow
-
-
携带参数
-
aid: {aid}
-
数据清洗、统计
获取到的视频数据中有已被删除的视频数据,这些数据的播放量为‘--’,不应计入总视频量,同时由于需要求平均操作,播放量为零的视频需要做特殊处理。
视频标题需要统计字数
视频时长获得的格式为‘HH:MM’,需要统一成秒数
视频发布时间为时间戳格式,需要统一成小时
需要对每位UP打上标签
确定训练数据及特征
接下来的操作都在MATLAB中完成
导入数据
clear,clc
[data,name] = xlsread('bilibiliUP','Sheet1','B2:J149');
save data name data
分析数据
样本总数为148个,特征项8项
特征分布
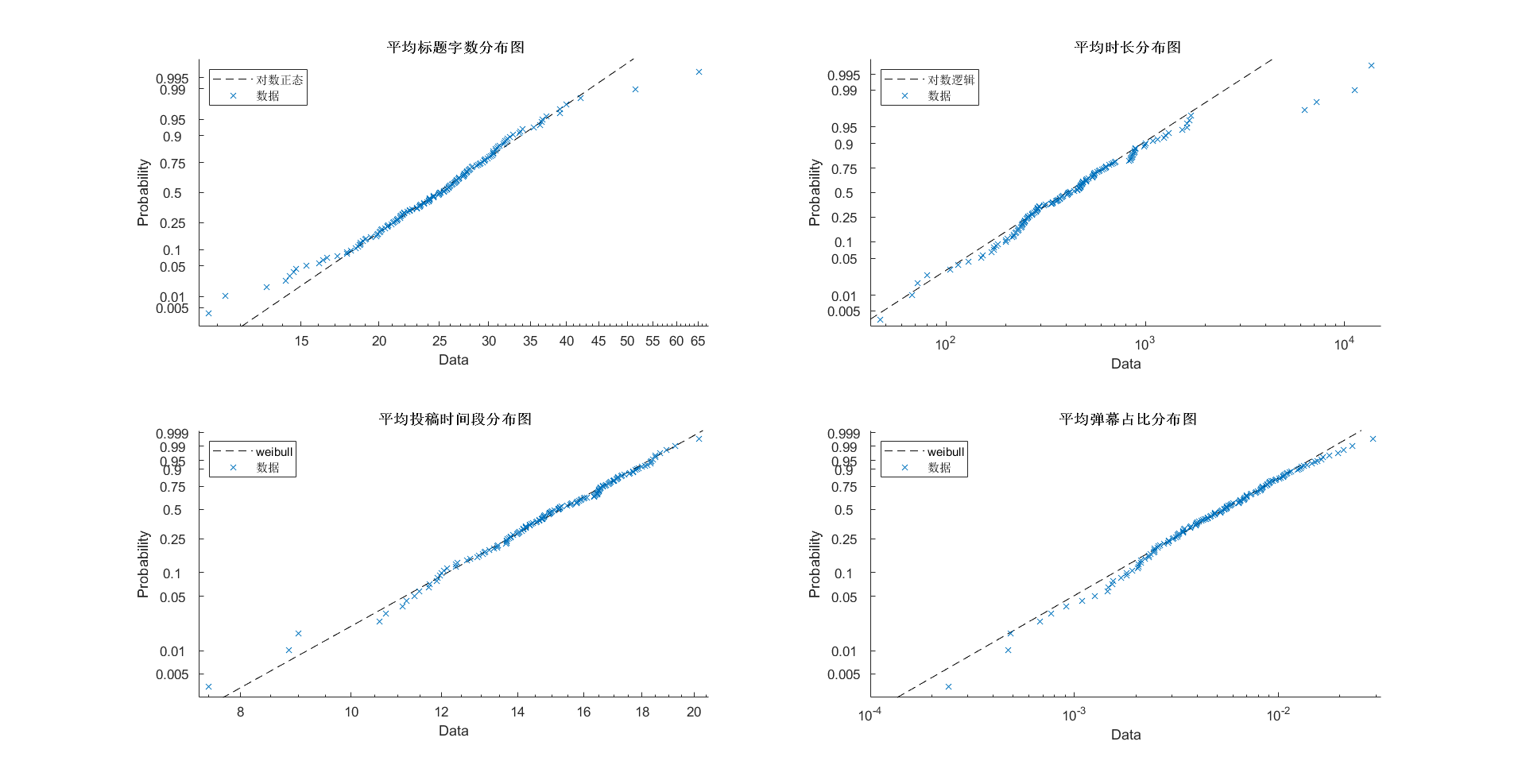
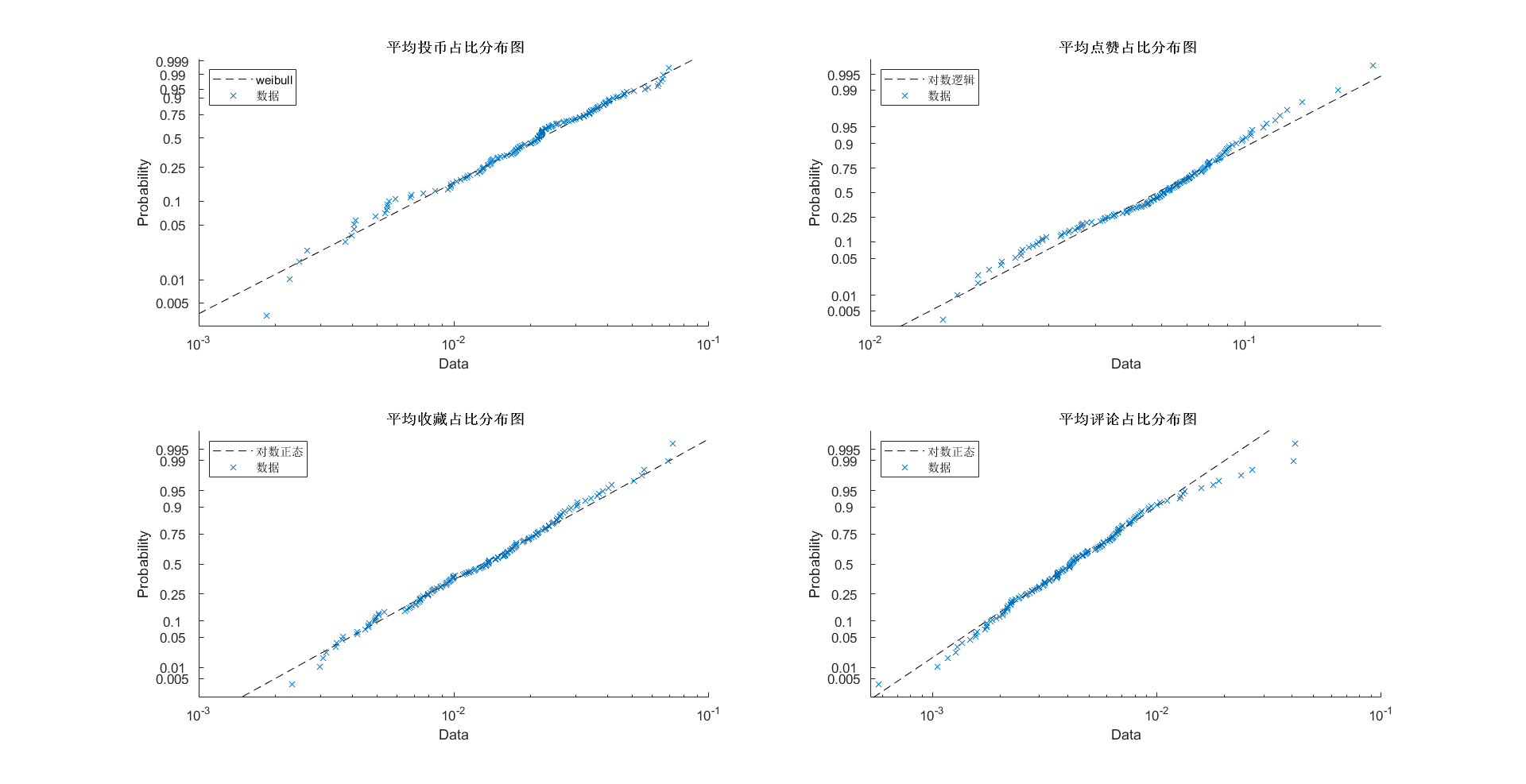
特征均值、中位数、标准差
| 平均视频标题字数(个) | 平均视频时长(s) | 平均投稿时间段(h) | 平均弹幕占播放量比值(%) | 平均投币占播放量比值(%) | 平均点赞占播放量比值(%) | 平均收藏占播放量比值(%) | 平均评论占播放量比值(%) | |
|---|---|---|---|---|---|---|---|---|
| 均值 | 25.5496 | 739.2298 | 15.0893 | 0.64 | 2.37 | 6.33 | 1.63 | 0.56 |
| 中位数 | 27.0743 | 414.5715 | 15.2024 | 0.54 | 2.14 | 6.06 | 1.36 | 0.41 |
| 标准差 | 7.0943 | 1.5957e+03 | 2.2214 | 4.7169e-03 | 1.4920e-02 | 2.9482e-02 | 1.2083e-02 | 5.7272e-03 |
相关系数矩阵
由于想做下聚类分析,所以先对特征间相关性进行分析
| 相关系数矩阵 | |||||||
|---|---|---|---|---|---|---|---|
| 1 | 0.0184325288466795 | -0.0249488481946810 | 0.000556029951779419 | -0.0781882042420524 | -0.168742474288945 | 0.0918842200982381 | 0.211218436765012 |
| 0.0184325288466795 | 1 | -0.0684400833088982 | 0.135256877104381 | -0.0839986211337289 | -0.231039187955712 | 0.161255474364964 | -0.0238979157736475 |
| -0.0249488481946810 | -0.0684400833088982 | 1 | 0.0642875823784235 | 0.182932469005339 | 0.216237989286477 | -0.0167989352674504 | -0.124649717355339 |
| 0.000556029951779419 | 0.135256877104381 | 0.0642875823784235 | 1 | 0.418871812486625 | -0.0442827567357434 | -0.0158181841190108 | 0.0996439284969066 |
| -0.0781882042420524 | -0.0839986211337289 | 0.182932469005339 | 0.418871812486625 | 1 | 0.468509412567601 | 0.438604301439134 | 0.241896824716753 |
| -0.168742474288945 | -0.231039187955712 | 0.216237989286477 | -0.0442827567357434 | 0.468509412567601 | 1 | 0.183186223938856 | 0.0503927120668548 |
| 0.0918842200982381 | 0.161255474364964 | -0.0167989352674504 | -0.0158181841190108 | 0.438604301439134 | 0.183186223938856 | 1 | 0.357856402521907 |
| 0.211218436765012 | -0.0238979157736475 | -0.124649717355339 | 0.0996439284969066 | 0.241896824716753 | 0.0503927120668548 | 0.357856402521907 | 1 |
最大相关系数为0.47,属于一般相关,这里个人仍选择进行主成分分析
主成分分析
| 贡献率(%) | 载荷矩阵 | |||||||
|---|---|---|---|---|---|---|---|---|
| 25.1275 | -0.0154356012464888 | 0.439271317949718 | -0.239468930154721 | 0.640874181590308 | 0.299234983162774 | -0.489223750723536 | 0.0908810289215616 | 0.0399568700489856 |
| 18.6910 | -0.0633151967720804 | 0.392258362039291 | 0.504163254738602 | -0.411223722446849 | 0.444807070009181 | -0.0650455225958284 | 0.440099753219734 | 0.151878186756074 |
| 14.8629 | 0.178975010961490 | -0.393567647425860 | 0.168327298137570 | 0.380362735131868 | 0.659830736056726 | 0.448429308073384 | -0.0501509982524432 | -0.0328937010028770 |
| 12.4349 | 0.269286890707300 | 0.113144944244625 | 0.678576159768060 | 0.337839313324345 | -0.359229553698078 | -0.0556086435211860 | -0.0116149200092179 | -0.455860379941969 |
| 11.5216 | 0.625773896426006 | -0.0714169658824892 | 0.155677911835697 | 0.0140278224639614 | -0.112535587324820 | -0.184136256454763 | -0.169887284588042 | 0.709536571769867 |
| 7.6773 | 0.431907250553736 | -0.415984327691833 | -0.237474739608985 | -0.140210810209029 | 0.0404217529290391 | -0.345760241577645 | 0.589026077373038 | -0.310200032544974 |
| 6.4894 | 0.449395895969865 | 0.325883099539835 | -0.181948722076682 | -0.358695083065022 | 0.299349431999138 | -0.0494929449168077 | -0.521984313795124 | -0.406876856255649 |
| 3.1955 | 0.333334561923556 | 0.448479293459293 | -0.293153813734111 | 0.113340671631467 | -0.210414742505219 | 0.629557129219618 | 0.383564575615655 | 0.0350827640124736 |
分析得:前六项累计贡献率达90.3%,故选择前六项进行分析
对新数据再次进行相关系数分析
| 相关系数矩阵 | |||||
|---|---|---|---|---|---|
| 1 | 0.182007545883040 | -0.0713354084624925 | -0.151681329692816 | 0.0614584785271987 | -0.125737466947417 |
| 0.182007545883040 | 1 | 0.324008369791875 | 0.0885939787345643 | 0.0591884996936010 | -0.133187717940026 |
| -0.0713354084624925 | 0.324008369791875 | 1 | -0.0852536338605460 | -0.00112597217476600 | 0.00576904941809119 |
| -0.151681329692816 | 0.0885939787345643 | -0.0852536338605460 | 1 | -0.174500701145123 | -0.256700669541367 |
| 0.0614584785271987 | 0.0591884996936010 | -0.00112597217476600 | -0.174500701145123 | 1 | 0.110149618536761 |
| -0.125737466947417 | -0.133187717940026 | 0.00576904941809119 | -0.256700669541367 | 0.110149618536761 | 1 |
各特征间相关系数低,符合预期
聚类分析
聚类
clear
clc
load data
Y = pdist(clearData, 'mahalanobis');
Z = linkage(Y,'average');
C = cophenet(Z,Y) %计算cophenet相关系数,取最大即可
figure
T = cluster(Z,6);
dendrogram(Z, 0, 'Orientation','left','ColorThreshold','default','Labels', name) %生成谱系图
title('{\bf 谱系图}')
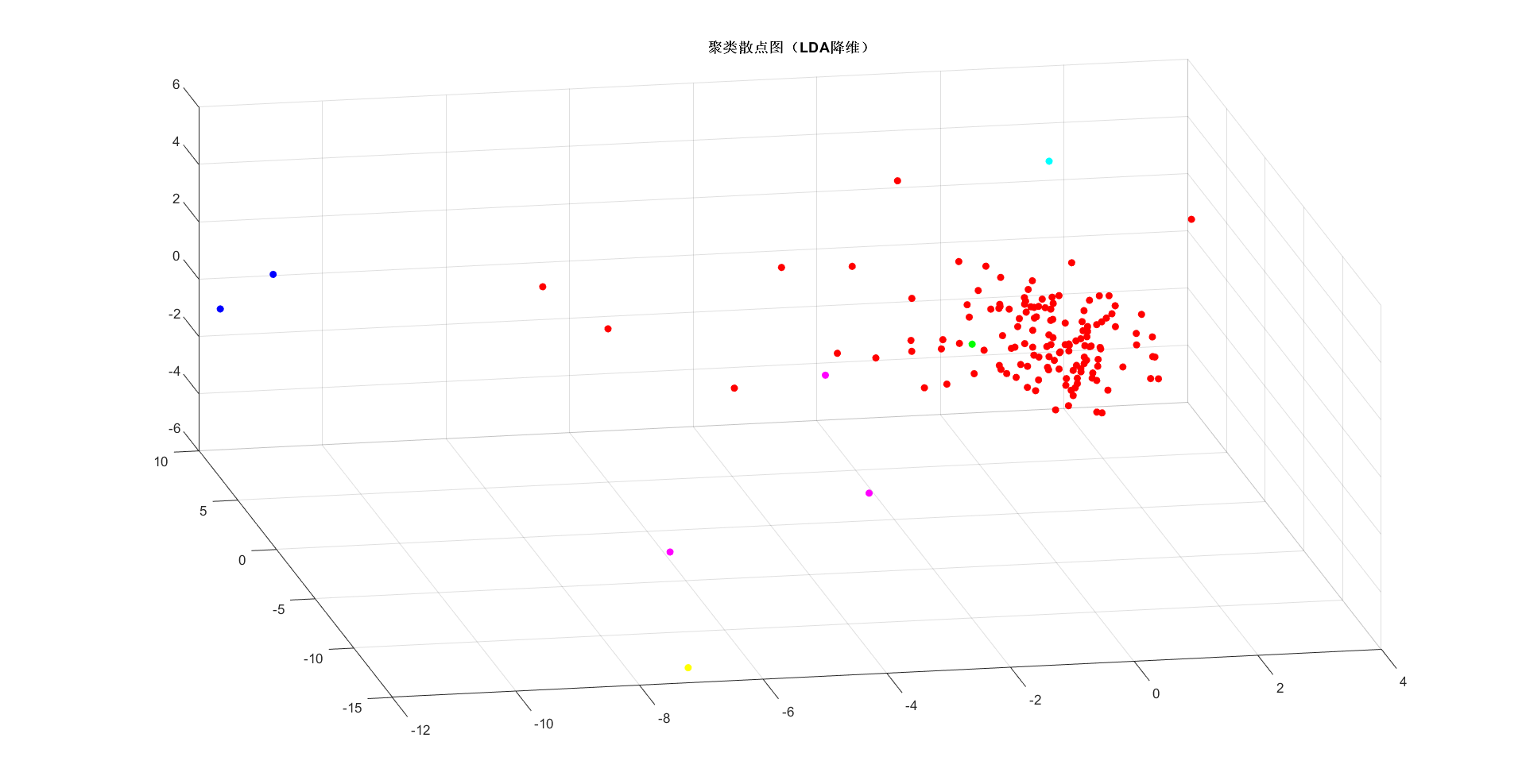
% LDA降维
[YY, WW, lambda] = LDA(clearData, T);
% Tsne
mappedX = tsne(clearData, [], 3, 6, 30);
%绘图
figure
scatter3(YY(:,1), YY(:,2), YY(:,3), 30, colorSet(T), 'filled')
title('{\bf 聚类散点图(LDA降维)}')
figure
scatter3(mappedX(:,1), mappedX(:,2), mappedX(:,3), 30, colorSet(T), 'filled')
title('{\bf 聚类散点图(Tsne)}')
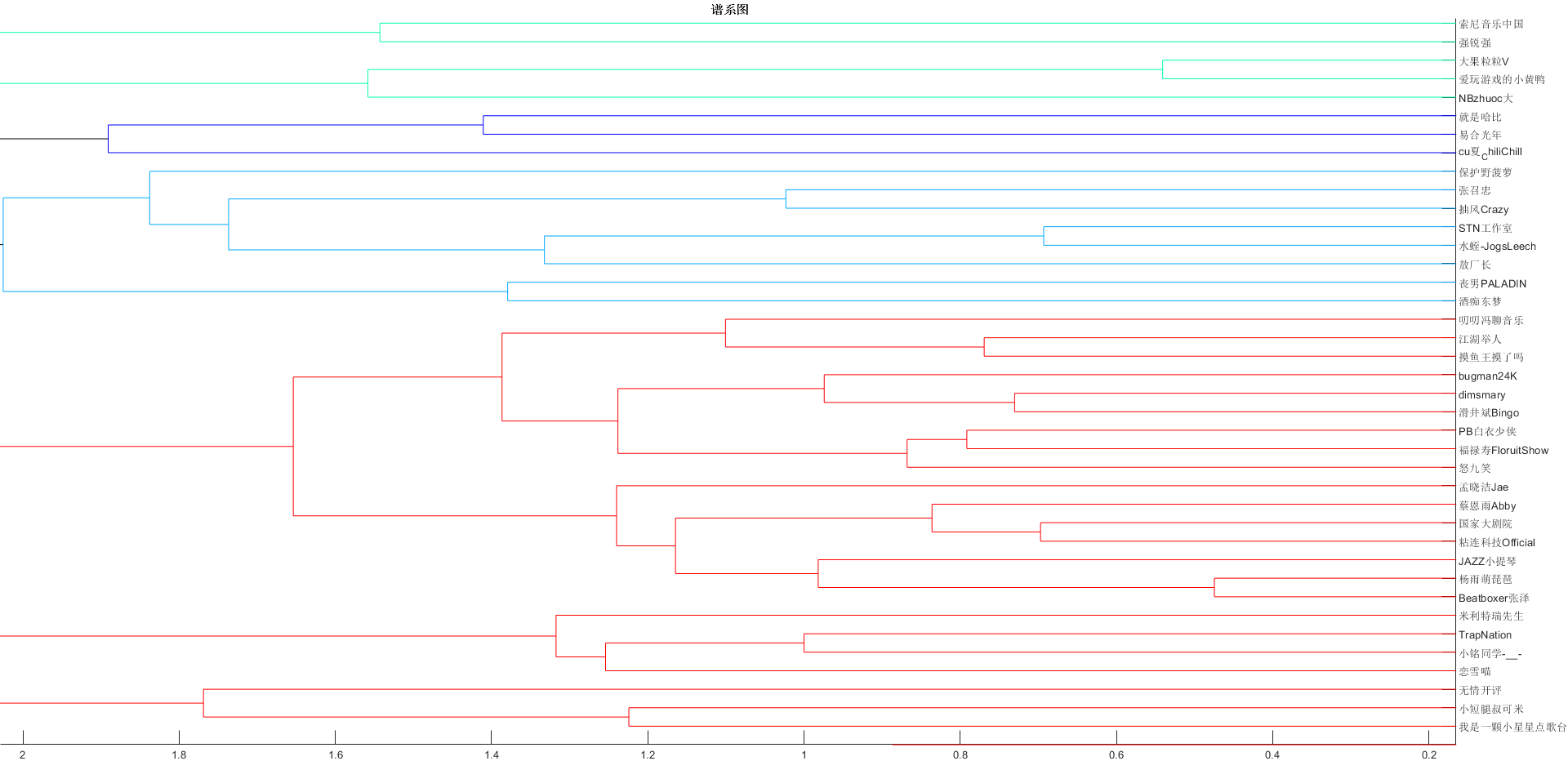
完整谱系图见 bilibiliUP谱系图下载——密码:6634_
判别
clear
clc
load data
%生成训练测试集
indices = crossvalind('Kfold', size(clearData,1), 30);
tests = (indices == 1);
train = ~tests;
trainData = clearData(train, :);
trainName = name(train,:);
testData = clearData(tests,:);
testName = name(tests,:);
%聚类
% trainData = zscore(trainData);%对抽取样本重新标准化
Y = pdist(trainData, 'euclidean');
Z = linkage(Y,'ward');
T = cluster(Z,6);%分六类
%判别
[class,err] = classify(testData,trainData,T,'diagLinear');
testName,class
%SVM
svmModel = fitcecoc(trainData, T);
classification = predict(svmModel, testData);
classification
% LDA降维
trainAndTest = [T,trainData];
trainAndTest = [trainAndTest;[class,testData];[classification,testData]];
trainLen = size(trainData, 1);
testLen = size(testData, 1);
[YY, WW, lambda] = LDA(trainAndTest(:,2:end), trainAndTest(:,1));
% 绘图
figure
scatter(YY(1:trainLen,1), YY(1:trainLen,2), 30, colorSet(trainAndTest(1:trainLen,1)), 'filled')
hold on
s2 = scatter(YY(trainLen+1:trainLen+testLen,1), YY(trainLen+1:trainLen+testLen,2), 50, colorSet(trainAndTest(trainLen+1:trainLen+testLen,1)), '^');
hold on
s3 = scatter(YY(trainLen+testLen+1:end,1), YY(trainLen+testLen+1:end,2), 50, colorSet(trainAndTest(trainLen+testLen+1:end,1)), 'v');
legend([s2,s3],'对角线性距离预测','SVM预测')
title('{\bf 基于聚类的判别(LDA降维)}')
text(YY(trainLen+testLen+1:end,1),YY(trainLen+testLen+1:end,2),testName(:,1))
hold off
使用聚类对数据进行了探索,并尝试进行判别,但并没有能够理解聚类后的UP主间的关系,哈哈。下一步准备进入主题,利用已知标签进行模型训练。
训练模型
有监督模型训练
因为接下来的训练都已知标签,所以预设的特征权重在训练中没有意义,故选择未加权的标准化数据。
clear,clc
load data
ct1 = 0;
ct2 = 0;
rR1 = zeros(2,2);%混淆矩阵
rR2 = zeros(2,2);
times = 4;
clearData = zscore(data);
indices = crossvalind('Kfold', size(clearData,1), times);
i = 1;
for i = 1 : times
tests = (indices == i);
train = ~tests;
trainData = clearData(train, :);
trainName = name(train,:);
trainScore = score(train,:);
testData = clearData(tests,:);
testName = name(tests,:);
testScore = score(tests,:);
T = trainScore;
%判别
[class,err] = classify(testData,trainData,T,'diagLinear');
%SVM
t = templateSVM('Standardize',true,'BoxConstraint',2);
svmModel = fitcecoc(trainData, T, 'Learners',t);
classification = predict(svmModel, testData);
% 计算
[m1,rR1] = mre(testScore, class, rR1);
ct1 = ct1 + m1;
[m2,rR2] = mre(testScore, classification, rR2);
ct2 = ct2 + m2;
end
'对角线性距离判别MRE、混淆矩阵、准确率、召回率:'
ct1/times
rR1
right1 = rR1./sum(rR1,1);
recall1 = rR1./sum(rR1,2);
right1(1),recall1(1)
'支持向量机MRE、混淆矩阵、准确率、召回率:'
ct2/times
rR2
right2 = rR2./sum(rR2,1);
recall2 = rR2./sum(rR2,2);
right2(1),recall2(1)
通过对角线性和支持向量机的比较,以及在不同标签下的表现,现有如下结论(评判标准为MRE、混淆矩阵、精确率、召回率):
-
在标签为2类即【百大/非百大】时,进行五十层交叉验证
- 对角线性模型
- MRE:0.4707
- 混淆矩阵 [103,30;3,12]
- 精确率 [0.9717;0.2857](非百大;百大)
- 召回率 [0.7744;0.8000]
- SVM
- MRE:0.3372
- 混淆矩阵 [130,3;14,1]
- 精确率 [0.9028;0.2500](非百大;百大)
- 召回率 [0.9774;0.0667]
- 对角线性模型
-
在标签为3类即【百大/知名/普通】时,进行五十层交叉验证
- 对角线性模型
- MRE:0.8091
- 混淆矩阵 [60,17,10;16,17,13;2,5,8]
- 精确率 [0.7692;0.4359;0.2581](普通;知名;百大)
- 召回率 [0.6897;0.3696;0.5333]
- SVM
- MRE:0.6508
- 混淆矩阵 [75,11,1;26,19,1;6,5,4]
- 精确率 [0.7009;0.5429;0.6667](普通;知名;百大)
- 召回率 [0.8621;0.4130;0.2667]
- 对角线性模型
-
在标签为4类即【百大+知名/百大/知名/普通】时,进行五十层交叉验证
- 对角线性模型
- MRE:1.1934
- 混淆矩阵 [56,11,13,7;10,13,11,12;0,2,3,1;0,3,1,5]
- 精确率 [0.8485;0.4483;0.1071;0.2000](普通;知名;百大;百大+知名)
- 召回率 [0.6437;0.2826;0.5000;0.5556]
- SVM
- MRE:0.7737
- 混淆矩阵 [75,9,2,1;25,18,2,1;1,4,1,0;1,4,2,2]
- 精确率 [0.7353;0.5143;0.1429;0.5000](普通;知名;百大;百大+知名)
- 召回率 [0.8621;0.3913;0.1667;0.2222]
- 对角线性模型
模型效果分析
经过分析,在现有样本集下,在2类预测时,对角线性预测在预测非百大时精确度高达到97%,在预测百大时召回率较高达到80%,说明当此模型预测为非百大时,有97%可能性预测正确,此模型预测为百大的所有UP中,有80%的UP能够成为百大。
同时分析发现,在现有样本集下,多类预测时,两种方式的精确率或召回率都较低,分析混淆矩阵后认为原因是样本集中标签占比不均衡导致,现有样本集下有样本148份,其中百大+知名9份、百大6份、知名46份,占比较低,导致训练模型欠拟合。
模型展示图
改进计划
经过分析,目前主要问题为数据集内不同标签数据量占比严重失衡,解决方向有两个:增加数据量占比较少的标签的数据量或者是减少占比过大的标签的数据量。介于目前标签数为4,样本数148,选择增加数据量是相对容易的方式。
由于B站有反爬措施,而百大UP主视频数据相对较多,平均每人数据需要0.5天爬取,预计增加百大UP主数量到150位,总样本数量到达300个左右,最快需要一个月时间能够爬取完毕,改进完成后会将文章链接更新在本文。

