神经网络优化篇:为什么正则化有利于预防过拟合呢?(Why regularization reduces overfitting?)
为什么正则化有利于预防过拟合呢?
通过两个例子来直观体会一下。
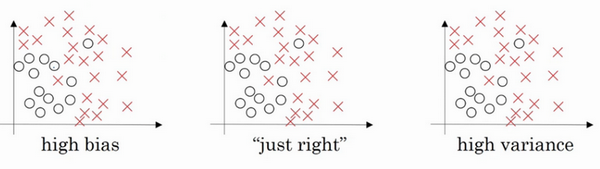
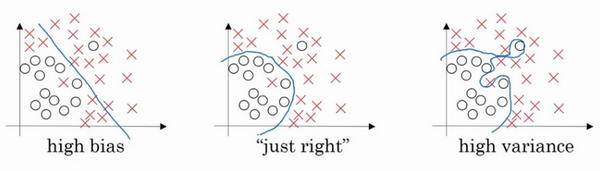
左图是高偏差,右图是高方差,中间是Just Right。
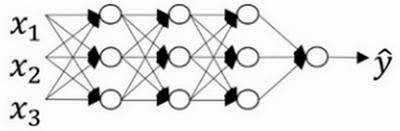
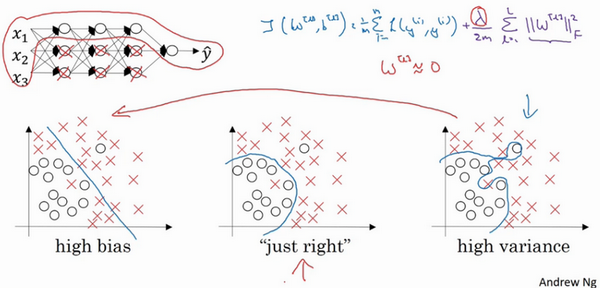
现在来看下这个庞大的深度拟合神经网络。知道这张图不够大,深度也不够,但可以想象这是一个过拟合的神经网络。这是的代价函数\(J\),含有参数\(W\),\(b\)。添加正则项,它可以避免数据权值矩阵过大,这就是弗罗贝尼乌斯范数,为什么压缩\(L2\)范数,或者弗罗贝尼乌斯范数或者参数可以减少过拟合?
直观上理解就是如果正则化\(\lambda\)设置得足够大,权重矩阵\(W\)被设置为接近于0的值,直观理解就是把多隐藏单元的权重设为0,于是基本上消除了这些隐藏单元的许多影响。如果是这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。
但是\(\lambda\)会存在一个中间值,于是会有一个接近“Just Right”的中间状态。
直观理解就是\(\lambda\)增加到足够大,\(W\)会接近于0,实际上是不会发生这种情况的,尝试消除或至少减少许多隐藏单元的影响,最终这个网络会变得更简单,这个神经网络越来越接近逻辑回归,直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了。神经网络变得更简单了,貌似这样更不容易发生过拟合,因此不确定这个直觉经验是否有用,不过在编程中执行正则化时,实际看到一些方差减少的结果。
再来直观感受一下,正则化为什么可以预防过拟合,假设用的是这样的双曲线激活函数。

用\(g(z)\)表示\(tanh(z)\),发现如果 z 非常小,比如 z 只涉及很小范围的参数(图中原点附近的红色区域),这里利用了双曲正切函数的线性状态,只要\(z\)可以扩展为这样的更大值或者更小值,激活函数开始变得非线性。
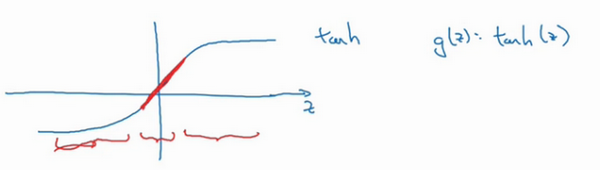
现在应该摒弃这个直觉,如果正则化参数λ很大,激活函数的参数会相对较小,因为代价函数中的参数变大了,如果\(W\)很小,
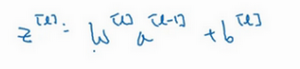
如果\(W\)很小,相对来说,\(z\)也会很小。
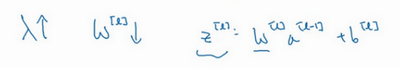
特别是,如果\(z\)的值最终在这个范围内,都是相对较小的值,\(g(z)\)大致呈线性,每层几乎都是线性的,和线性回归函数一样。

如果每层都是线性的,那么整个网络就是一个线性网络,即使是一个非常深的深层网络,因具有线性激活函数的特征,最终只能计算线性函数,因此,它不适用于非常复杂的决策,以及过度拟合数据集的非线性决策边界。
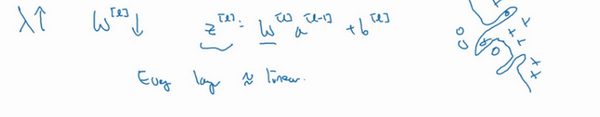
总结一下,如果正则化参数变得很大,参数\(W\)很小,\(z\)也会相对变小,此时忽略\(b\)的影响,\(z\)会相对变小,实际上,\(z\)的取值范围很小,这个激活函数,也就是曲线函数\(tanh\)会相对呈线性,整个神经网络会计算离线性函数近的值,这个线性函数非常简单,并不是一个极复杂的高度非线性函数,不会发生过拟合。
大家在编程作业里实现正则化的时候,会亲眼看到这些结果,总结正则化之前,给大家一个执行方面的小建议,在增加正则化项时,应用之前定义的代价函数\(J\),做过修改,增加了一项,目的是预防权重过大。
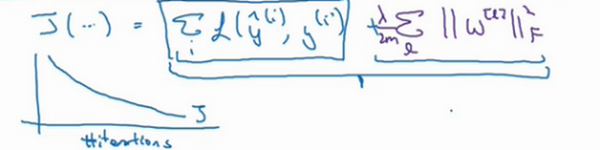
如果使用的是梯度下降函数,在调试梯度下降时,其中一步就是把代价函数\(J\)设计成这样一个函数,在调试梯度下降时,它代表梯度下降的调幅数量。可以看到,代价函数对于梯度下降的每个调幅都单调递减。如果实施的是正则化函数,请牢记,\(J\)已经有一个全新的定义。如果用的是原函数\(J\),也就是这第一个项正则化项,可能看不到单调递减现象,为了调试梯度下降,请务必使用新定义的\(J\)函数,它包含第二个正则化项,否则函数\(J\)可能不会在所有调幅范围内都单调递减。
这就是\(L2\)正则化,它是在训练深度学习模型时最常用的一种方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号