神经网络入门篇:为什么深度学习会兴起?
为什么深度学习会兴起?
- 这篇我们来讲故事,关于为什么深度学习会兴起的故事~
深度学习和神经网络之前的基础技术理念已经存在大概几十年了,为什么它们现在才突然流行起来呢?
因为多亏数字化社会的来临,现在的数据量都非常巨大,我们花了很多时间活动在这些数字的领域,比如在电脑网站上、在手机软件上以及其它数字化的服务,它们都能创建数据,同时便宜的相机被配置到移动电话,还有加速仪及各类各样的传感器,同时在物联网领域我们也收集到了越来越多的数据。仅仅在过去的20年里对于很多应用,我们便收集到了大量的数据,远超过机器学习算法能够高效发挥它们优势的规模。
神经网络展现出的是,如果你训练一个小型的神经网络,那么这个性能可能会像下图黄色曲线表示那样;如果你训练一个稍微大一点的神经网络,比如说一个中等规模的神经网络(下图蓝色曲线),它在某些数据上面的性能也会更好一些;如果你训练一个非常大的神经网络,它就会变成下图绿色曲线那样,并且保持变得越来越好。因此可以注意到两点:如果你想要获得较高的性能体现,那么你有两个条件要完成,第一个是你需要训练一个规模足够大的神经网络,以发挥数据规模量巨大的优点,另外你需要能画到\(x\)轴的这个位置,所以你需要很多的数据。因此我们经常说规模一直在推动深度学习的进步,这里的规模指的也同时是神经网络的规模,我们需要一个带有许多隐藏单元的神经网络,也有许多的参数及关联性,就如同需要大规模的数据一样。事实上如今最可靠的方法来在神经网络上获得更好的性能,往往就是要么训练一个更大的神经网络,要么投入更多的数据,这只能在一定程度上起作用,因为最终你耗尽了数据,或者最终你的网络是如此大规模导致将要用太久的时间去训练,但是仅仅提升规模的的确确地让我们在深度学习的世界中摸索了很多时间。为了使这个图更加从技术上讲更精确一点,我在\(x\)轴下面已经写明的数据量,这儿加上一个标签(label)量,通过添加这个标签量,也就是指在训练样本时,我们同时输入\(x\)和标签\(y\),接下来引入一点符号,使用小写的字母\(m\)表示训练集的规模,或者说训练样本的数量,这个小写字母\(m\)就横轴结合其他一些细节到这个图像中。
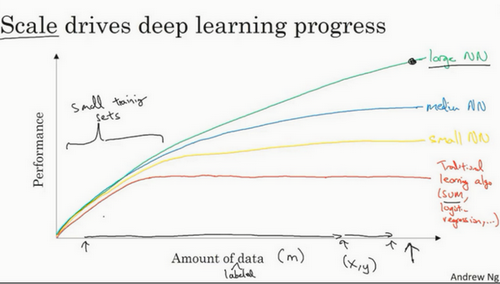
在这个小的训练集中,各种算法的优先级事实上定义的也不是很明确,所以如果你没有大量的训练集,那效果会取决于你的特征工程能力,那将决定最终的性能。假设有些人训练出了一个SVM(支持向量机)表现的更接近正确特征,然而有些人训练的规模大一些,可能在这个小的训练集中SVM算法可以做的更好。因此你知道在这个图形区域的左边,各种算法之间的优先级并不是定义的很明确,最终的性能更多的是取决于你在用工程选择特征方面的能力以及算法处理方面的一些细节,只是在某些大数据规模非常庞大的训练集,也就是在右边这个会非常的大时,我们能更加持续地看到更大的由神经网络控制的其它方法。
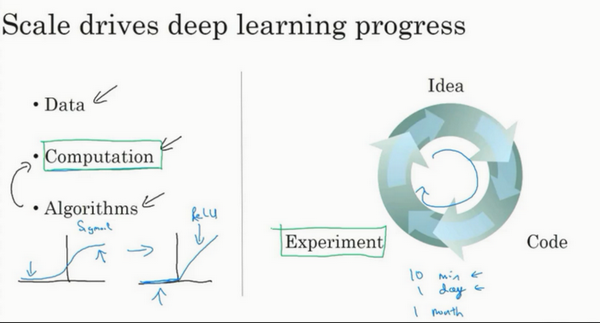
所以可以这么说,在深度学习萌芽的初期,数据的规模以及计算量,局限在我们对于训练一个特别大的神经网络的能力,无论是在CPU还是GPU上面,那都使得我们取得了巨大的进步。但是渐渐地,尤其是在最近这几年,我们也见证了算法方面的极大创新。许多算法方面的创新,一直是在尝试着使得神经网络运行的更快。
作为一个具体的例子,神经网络方面的一个巨大突破是从sigmoid函数转换到一个ReLU函数:

如果你无法理解刚才我说的某个细节,也不需要担心,可以知道的一个使用sigmoid函数和机器学习问题是,在这个区域,也就是这个sigmoid函数的梯度会接近零,所以学习的速度会变得非常缓慢,因为当你实现梯度下降以及梯度接近零的时候,参数会更新的很慢,所以学习的速率也会变的很慢,而通过改变这个被叫做激活函数的东西,神经网络换用这一个函数,叫做ReLU的函数(修正线性单元),ReLU它的梯度对于所有输入的负值都是零,因此梯度更加不会趋向逐渐减少到零。而这里的梯度,这条线的斜率在这左边是零,仅仅通过将Sigmod函数转换成ReLU函数,便能够使得一个叫做梯度下降(gradient descent)的算法运行的更快,这就是一个或许相对比较简单的算法创新的例子。但是根本上算法创新所带来的影响,实际上是对计算带来的优化,所以有很多像这样的例子,我们通过改变算法,使得代码运行的更快,这也使得我们能够训练规模更大的神经网络,或者是多端口的网络。即使我们从所有的数据中拥有了大规模的神经网络,快速计算显得更加重要的另一个原因是,训练你的神经网络的过程,很多时候是凭借直觉的,往往你对神经网络架构有了一个想法,于是你尝试写代码实现你的想法,然后让你运行一个试验环境来告诉你,你的神经网络效果有多好,通过参考这个结果再返回去修改你的神经网络里面的一些细节,然后你不断的重复上面的操作,当你的神经网络需要很长时间去训练,需要很长时间重复这一循环,在这里就有很大的区别,根据你的生产效率去构建更高效的神经网络。当你能够有一个想法,试一试,看效果如何。在10分钟内,或者也许要花上一整天,如果你训练你的神经网络用了一个月的时间,有时候发生这样的事情,也是值得的,因为你很快得到了一个结果。在10分钟内或者一天内,你应该尝试更多的想法,那极有可能使得你的神经网络在你的应用方面工作的更好、更快的计算,在提高速度方面真的有帮助,那样你就能更快地得到你的实验结果。这也同时帮助了神经网络的实验人员和有关项目的研究人员在深度学习的工作中迭代的更快,也能够更快的改进你的想法,所有这些都使得整个深度学习的研究社群变的如此繁荣,包括令人难以置信地发明新的算法和取得不间断的进步,这些都是开拓者在做的事情,这些力量使得深度学习不断壮大。
好消息是这些力量目前也正常不断的奏效,使得深度学习越来越好。研究表明我们的社会仍然正在抛出越来越多的数字化数据,或者用一些特殊的硬件来进行计算,比如说GPU,以及更快的网络连接各种硬件。我非常有信心,我们可以做一个超级大规模的神经网络,而计算的能力也会进一步的得到改善,还有算法相对的学习研究社区连续不断的在算法前沿产生非凡的创新。根据这些可以乐观地回答,同时对深度学习保持乐观态度,在接下来的这些年它都会变的越来越好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号