crystal-lang入门(一)
GETTING STARTED
为什么选择这门语言。没有为什么,觉得是门有意思的语言就跟了。
系统的话是centos8
先安装,官网写的还是很清晰的在这不说了
HELLO WORLD!
puts "hello world!"
第一个程序是经典的hello world,通过.cr后缀名保存运行
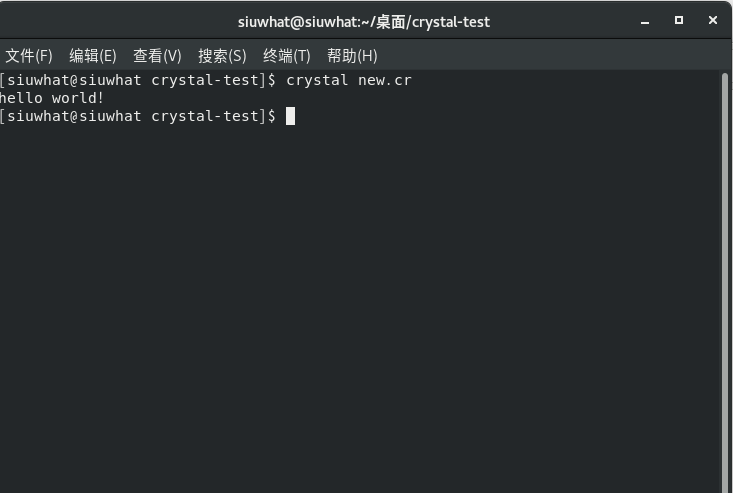
默认是crystal run模式运行
更多模式的话通过输入crystal或者官网知道
VARIABLES
message = "Hello Penny!" puts message puts message puts message
变量会自动判别类型,上述是string。我们这里默认讨论的是局部变量。
puts是一个方法,意即put string,后面跟随者一个类似\n的换行符。这之后再说。
上例我们可以复用变量,输出多个相同语句。
关于变量命名,我们这里采用蛇形命名file_name,不同于java的驼峰式命名fileName。
TYPE
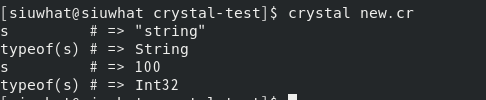
message = "Hello Penny!" p! typeof(message)
p!相似于printf,能打印表达式到标准输出上,利于debug
REASSIGNING A VALUE
message = "Hello Penny!" p! message message = "Hello Sheldon!" p! message
变量重新赋值,贴原文
This also works with values of a different type. The type of the variable changes when a value of a different type is assigned. The compiler is smart enough to know which type it has at which point in the program.
这是效果
MATH
两个常用的数字类型Int32和Float64,数字表示占用的位数,
我们可以在数字中添加下划线,以便表示大数
p! 1, typeof(1) p! 1.0, typeof(1.0) p! 100_000, typeof(100_000) p! 100_000.0, typeof(100_000.0)
See Integer literal reference and Float literal reference for a full reference on all primitive number types and alternative representations
ARITHMETIC
p! 1 == 1, 1 == 2, 1.0 == 1, -2000.0 == -2000
对于相等运算符==,具有相同数值的数字视为相等,与它们的类型无关。
OUTPUT: 1 == 1 # => true 1 == 2 # => false 1.0 == 1 # => true -2000.0 == -2000 # => true
与==符号相同,数值与类型无关
p! 2 > 1, 1 >= 1, 1 < 2, 1 <= 2
现在有个全新的运算符<=>
p! 1 <=> 1, 2 <=> 1, 1 <=> 2
c++20也引入了这个<=>运算符,称为universal comparison operator(不知道怎么翻译,通用比较运算符?),从外观来看又称为Spaceship operator(太空船运算符?),它集合了大小相等比较运算符,当两数相等,返回0,第一个数更大返回正数,第二个数更大返回负数。
OUTPUT: 1 <=> 1 # => 0 2 <=> 1 # => 1 1 <=> 2 # => -1
OPERATORS
p! 1 + 1, # addition 1 - 1, # subtraction 2 * 3, # multiplication 2 ** 4, # exponentiation 2 / 3, # division 2 // 3, # floor division 3 % 2, # modulus -1 # negation (unary)
一些运算符是二元(binary)的,以中缀的形式表示,一些运算符是一元(unary)的,以前缀的形式表示。
OUTPUT: 1 + 1 # => 2 1 - 1 # => 0 2 * 3 # => 6 2 ** 4 # => 16 2 / 3 # => 0.6666666666666666 2 // 3 # => 0 3 % 2 # => 1 -1 # => -1
如你所见,int运算的结果都是返回int类型,但是‘/’是个例外,//向下取整,一个运算在int和float之间总是返回float,否则,返回类型通常是第一个操作数的类型
更多的你可以参考the Operator reference.
PRECEDENCE
p! 4 + 5 * 2, (4 + 5) * 2
基本按照平常运算的规则,加入括号提升优先级
更多的你可以参考the Operator reference.
NUMBER METHODS
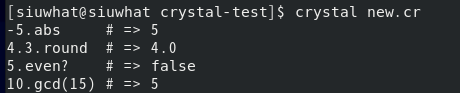
p! -5.abs, # absolute value 4.3.round, # round to nearest integer 5.even?, # odd/even check 10.gcd(16) # greatest common divisor
少见的数学运算不是运算符,是命名的方法
更多的你可以参考 the Math API docs.
CONSTANTS
p! Math::E, # Euler's number Math::TAU, # Full circle constant (2 * PI) Math::PI # Archimedes' constant (TAU / 2)
在Math 模块你可以得到这些数学常量
STRINGS
string是用UTF-8编码的Unicode字符序列。
string是不可变的:如果对字符串采用修改,实际上会得到一个包含修改内容的新字符串。原始字符串保持不变。
string作为字面量通常由双引号"包围。
INTERPOLATION
name = "Crystal" puts "Hello #{name}"
字符串插值是个相当方便的方法通过#{...},#{...}在字符串字面量中插入了在大括号之间...代表的表达式的值。
字符串插值中的表达式应当足够小,或者是变量或者是函数调用,过于复杂会降低可读性。
表达式不一定是字符串,也可以是数字,任一类型都定义了#to_s方法,会被转换为字符串,因此任一类型在这个puts中都奏效。
name = 6 puts "Hello #{name}!"
一个插值的代替就是字符串连接,我们可以用"Hello " + name + "!"来代替"Hello #{name}!",但是写起来繁琐而且对于非字符串类型会产生麻烦,所以更推荐插值
ESCAPING
puts "I say: \"Hello World!\""
"双引号在字符串字面量之中会被误解释为字符串定界符,需要一个加在双引号前面的反斜杠/构成转义序列,于是可以正确的构成双引号"。
puts "I say: \"Hello \\\n\tWorld!\""
可以在\n,\t前加\构成转义,crystal语言中字符串长度只由#size决定。
更多的你可以参考 string literal reference.
ALTERNATIVE DELIMITERS
puts %(I say: "Hello World!")
%(…)与“…”等价,只是分隔符用括号((and))而不是双引号表示。
转义和插值在此语法下仍然以相同方式运作。
UNICODE
puts "Hello 🌐"
unicode是在不同文字体系中的文本国际标准,不仅是拉丁字母或者其他语言的文字,也包含表情与图标。
puts "Hello \u{1F310}"
但是有些unicode符号有时候不被编辑器字体支持,有的甚至不是可打印的。作为替代,unicode字符可以由转义序列表达。/+u表示了unicode codepoint。codepoint 值由十六进制数字组成,包含在花括号内,当codepoint正好由4个数字组成,花括号可以被省略。(该例输出:)
OUTPUT:
Hello ἱ0
TRANSFORMATION
message = "Hello World! Greetings from Crystal." puts "normal: #{message}" puts "upcased: #{message.upcase}" puts "downcased: #{message.downcase}" puts "camelcased: #{message.camelcase}" puts "capitalized: #{message.capitalize}" puts "reversed: #{message.reverse}" puts "titleized: #{message.titleize}" puts "underscored: #{message.underscore}"
方法String#upcase 相当于转换所有小写字母到大写字母,它的相反是String#downcase,方法#camelcase和#underscore 不改变特定的字符串, 而是使他们输出 "snake_cased" 或 "CamelCased".
INFORMATION
message = "Hello World! Greetings from Crystal." p! message.size
让我们来看看string的更多细节以及我们可以从中知道些什么,首先字符串有个长度,即它包含的字符的数量,这个值可以作为String#size。
empty_string = "" p! empty_string.size == 0, empty_string.empty?
确定一个字符串是否为空,你可以检查它的size是否为0, 或仅仅使用这个:String#empty?
blank_string = "" p! blank_string.blank?, blank_string.presence
如果字符串为空或它仅仅包含空白字符(换行,空格,TAB),方法String#blank? 返回 true .如果字符串是blank,相关的方法 String#presence 返回 nil , 否则返回字符串本身。
EQUALITY AND COMPARISON
message = "Hello World!" p! message == "Hello World", message == "Hello Crystal", message == "hello world", message.compare("hello world", case_insensitive: false), message.compare("hello world", case_insensitive: true)
你可以检测两个字符串是否相等通过==运算符以及比较他们通过<=>运算符。两个字符串都是直接通过字符与字符相比较。记住,<=>返回一个int以显示两边的操作数之间的关系以及 == 返回 true 如果两边相等。
还有一个方法 #compare 提供了大小写不区分比较。
PARTIAL COMPONENTS
message = "Hello World!" p! message.includes?("Crystal"), message.includes?("World")
有时候知道一个字符串是否精确匹配另一个字符串并不重要, 你只是想知道是否一个字符串包含另一个。例如, 让我们使用 #includes? 方法来检测吧。
OUTPUT: message.includes?("Crystal") # => false message.includes?("World") # => true
有时候字符串的开头与结尾让人感兴趣。这里方法 #starts_with? 和#ends_with?就起到作用。
message = "Hello World!" p! message.starts_with?("Hello"), message.starts_with?("Bye"), message.ends_with?("!"), message.ends_with?("?")
INDEXING SUBSTRINGS
p! "Crystal is awesome".index("Crystal"), "Crystal is awesome".index("s"), "Crystal is awesome".index("aw")
我们可以得到甚至更多细节信息关系子字符串在字符串的位置通过#index方法。它返回了字符在字符串第一次出现的位置.。结果0相当于使用了starts_with?(第一位出现)。
message = "Crystal is awesome" p! message.index("s"), message.index("s", offset: 4), message.index("s", offset: 10)
该方法有一个可选 offset参数用来从不同于字符串开头位置开始检索。
message = "Crystal is awesome" p! message.rindex("s"), message.rindex("s", 13), message.rindex("s", 8)
方法#rindex同样,不过它是从字符串尾部开始搜索。
a = "Crystal is awesome".index("aw") p! a, typeof(a) b = "Crystal is awesome".index("meh") p! b, typeof(b)
如果子字符串未找到, 结果为nil。 它的基本就是表示"no value",当子字符串没有index时有意义。
查看#index的返回类型我们可以发现它返回Int32或Nil。
EXTRACTING SUBSTRINGS
message = "Hello World!" p! message[6, 5]
index accessor #[]通过字符的index和size引用子字符串.字符 indices开始于0,结束于length (即#size的值)减去1。第一个参数指定了子字符串第一个字符的index。第二个参数制定了子字符串的length。
message[6, 5] 分离子字符串,该字符串长度为5,开始于index 6。
message = "Hello World!" p! message[6, message.size - 6 - 1]
假设我们已经确定字符串以Hello开头,以!结尾,想提取中间的字符串。如果message是Hello Crystal,我们就不会得到Crystal这个词的全称,因为它超过了5个字符。
一个办法是从整个字符串的长度减去开始和结束的长度来计算子字符串的长度。
message = "Hello World!" p! message[6..(message.size - 2)], message[6..-2]
There's an easier way to do that: The index accessor can be used with a Range of character indices. A range literal consists of a start value and an end value, connected by two dots (..). The first value indicates the start index of the substring, as before, but the second is the end index (as opposed to the length). Now we don't need to repeat the start index in the calculation, because the end index is just the size minus two (one for the end index, and one for excluding the last character).
It can be even easier: Negative index values automatically relate to the end of the string, so we don't need to calculate the end index from the string size explicitly.
SUBSTITUTION
message = "Hello World!" p! message.sub(6..-2, "Crystal")
In a very similar manner, we can modify a string. Let's make sure we properly greet Crystal and nothing else. Instead of accessing a substring, we call #sub. The first argument is again a range to indicate the location that gets replaced by the value of the second argument.
message = "Hello World!" p! message.sub("World", "Crystal")
The #sub method is very versatile and can be used in different ways. We could also pass a search string as the first argument and it replaces that substring with the value of the second argument.
message = "Hello World! How are you, World?" p! message.sub("World", "Crystal"), message.gsub("World", "Crystal")
#sub only replaces the first instance of a search string. Its big brother #gsub applies to all instances.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号