【HICP Gaussdb】数据库 数据库管理(应急故障处理事例 同步原理) -15
应急处理手段
原则:出现重大或者紧急事故 应该立即启动应急 切记恢复业务是第一要务 避免扩大事故影响
配置文件损坏
zengine.ini是gussdb的参数配置文件,记录了数据库实例关键配置信息 配置文件的路径 侦听地址侦听端口和主备关系
如果损坏 若zengine.ini 未丢失 可以通过直接拷贝复制zengine.ini_temp 恢复
若有参数文件的备份 则从备份集拷贝恢复 然后执行对应的SQL
若无备份 可以查看运行日志和审计日志 实例启动时候会打印关键信息到运行日志 据此日志 恢复参数
无备份,日志也不存在 则根据数据库的实际配置 手动逐个编辑对应参数 ;
若无备份 且实例已经停止 ,可以查看运行日志,实例启动会打印关键参数到运行日志,param标识
若无备份 且实例已经停止 日志也不存在 则根据数据库实际配置 手动逐个对应参数
建议修改参数后 及时备份 放置zengine.ini 所在磁盘损坏时,备份太旧 无法恢复到最新配置
控制文件是数据库核心文件 ,保存数据库状态信息 数据文件和日志文件的全路径 以及核心系统表入口
场景1:数据库启动时 ,任意一个控制文件的数据块损坏
现象:数据库实例启动正常 运行报错日志如下

修复: controlfile多个镜像 自动修复

场景2: 数据库启动时 任意一个控制文件核心控制信息损坏
现象: 数据库启动正常运行报错日志如下
修复: control file 多个镜像 自动修复
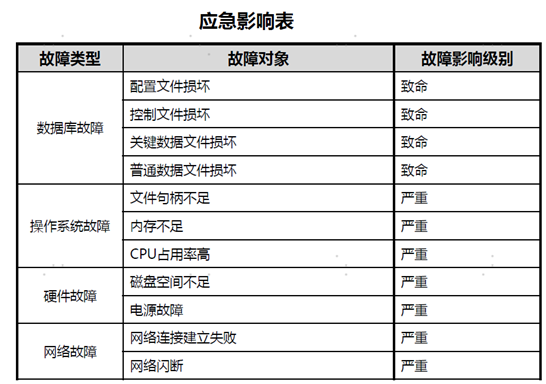
场景3 : 数据库启动时 任意控制文件丢失
现象: 数据库正常启动 运行报错日志如下
修复: control file 多个镜像文件 ,可以通过拷贝任意镜像文件恢复丢失文件
也可以通过修改control_file 参数修复 ,再zengine.ini文件中 删除丢失文件信息 (不建议 会丢失高可用性)

场景4:数据库启动时 所有控制文件都丢失 或者损坏
现象: 数据库启动失败 报错如下
修复: 全库备份恢复
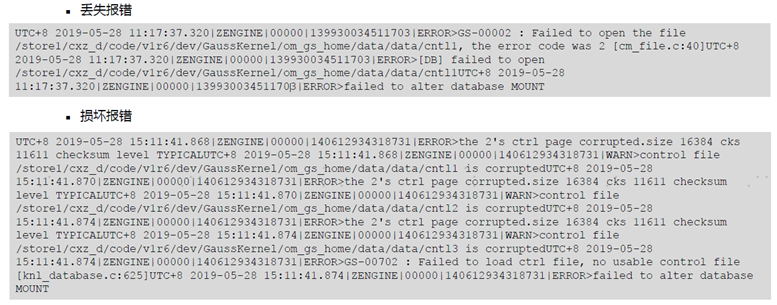
常见故障案例 :安装完成后 主备连接失败
问题现象: 安装成功且参数配置正确 但主备连接失败 报错信息为:

原因分析: Ha主备连接关系是通过参数 LOG_ARCHIVE_DEST_NARCHIVE_DEST_N 配置的链路来决定 连接发起端通过参数连接,接收端收到连接后,会解析对端的IP 并与本地配置中配置的对端IP 进行对比 ,如果两者相等 , 则接收连接
大多数情况下校验都没问题 但是如果连接发起端所在的机器上 有多个网卡 或者一个网卡中有多个IP地址 那么发起连接时源ip有可能和接收端配置IP地址不一致 ,导致连接失败

处理方法:以root身份登陆GaussDB 切换为omm用户 ,对于有多个网卡或者多个IP地址的机器 必须确定待使用的IP地址
设置本端机器配置文件的$GSDB_DATA/cfg/zengine.ini 将LOG_ARCHIVE_nARCHIVE_DEST_N参数参数的LOCAL_HOST 属性设置为正在使用的地址
设置对端机器配置文件的$GSDB_DATA/cfg/zengine.ini 将LOG_ARCHIVE_nARCHIVE_DEST_N参数参数的SERVICE 属性设置为正在使用的地址
数据库无法启动场景
问题现象: 数据库无法启动 $GSDB_DATA/log/run/zegine.rlong 运行日志错误

原因分析:数据库参数名称或者参数取值错误
处理步骤: 使用安装GAUSSDB 数据库操作系统用户 ,登陆
打开启动日志 查看是否有参数错误
打开运行日志 查看运行日志中数据库启动失败的时间点的日志
根据报错信息 修改 zengine.ini 的参数值
问题现象:zctl.py -t start 启动失败 报错如下

原因分析:数据库内存空间不足 需要结合日志分析
解决方案: 使用安装GAUSSDB 数据库操作系统用户 ,登陆
修改zengine.ini 文件中SGA相关参数
SGA_BUFF_SIZE必须满足要求为:shmmax shmmax为内核参数 定义单个共享内存段的最大值
SGA_BUFF_S114MB<SGA_BUFF_SIZEZE = LOG_BUFFER_SIZE + SHARED_POOL_SIZE + DATA_BUFFER_SIZE + TEMP_BUFFER_SIZE
log_buffer_size ,shared_buffer_size ,data_buffer_size temp_buffer_size 请根据业务实际情况
问题现象: 数据库无法启动 $GSDB_DATA/log/run/zengine.rlong 运行日志中错误信息为

分析原因:启动数据库端口被占用
处理步骤: 查看端口号的进程 需要优先启动数据库服务 , 可以先将 占用1888 端口进程 强制停止 , 打开运行日志$GSDB_DATA_/log/zengine.rlong查看报错时间点
当需要有限保障其他业务正常运行时 ,更改数据库侦听端口
数据库无法启动
问题现象: 数据库无法启动 $GSDB_DATA/log/run/zengine.rlog 运行日志异常如下

原因分析: 操作系统内存不足
处理步骤: 使用root 用户执行 top命令 检查是否符合要求 、执行ipcs -a 检查共享存储
如果未释放内存 执行ipcrm -m shmid shmid标识的共享内存段 切换omm用户 启动数据库服务
python $GSDB_HOME/BIN/zctl.py -t start
问题现象: 数据库无法启动 $GSDB_DATA/LOG/RUN/ZENGINE.RLOG 日志错误信息

原因分析: 数据库从磁盘加载日志文件 报错退出 --> 磁盘发生静默故障 导致日志文件损坏 或 非法写入 导致日志文件损坏
处理步骤: 以mount启动数据库 cd $GSDB_home/bin python zctl.py -t start -m MOUNT
找到日志中记录为 invaild log file head checksum 日志信息的 file_name
查看DV_LOG_FILES视图 记录file_name对应的status ---> select id, status ,file_name from dv_log_files ;
如果status 为inactive 或者unsed 执行下一步 否则联系华为 ----->alter database clear logfile 0 ; # 恢复redo日志
启动数据库 cd $GSDB_HOME/BIN --> python zctl.py -t stop | start
数据库无法停止:
问题现象: 由于数据库进程或者权限问题 会导致数据库无法停止 可能出现以下信息
原因分析 : 数据库进程状态可能存在问题 ,需要停止异常进程后再停止数据库
文件权限不足 ,查看zctl.py文件是否满足要求
处理步骤 : 数据库进程状态 root登录 ->> ps aux --> kill -9 pid

磁盘页面故障导致数据库停止
问题现象: 客户端报错 错误码 GS-00880 错误信息为page损坏

数据库突然停止 运行日志中 abort info :page corrupted 例如:

原因分析: 数据库从磁盘加载页面, 检测页面checksum值发现不匹配 ,即数据页面已损坏 如果此页面损坏不影响数据库正常运行 , 则会报GS -00880错误码 并打印页面ID; 如果损坏导致数据库无法继续正 常运行, 数据库即会停止 并记录 abort info : page corrupted 信息
磁盘发生静默故障 、非法写入 将数据库不支持的数据类型写入 导致页面损坏
处理方法 : 单机和HA 可以通过备份文件 以及重演日志方式修复 损坏页面
使用安装 GAUSSDB数据库操作系统用户,登录所在服务器
如果数据库已经停止 请以mount 模式启动数据库 , 若数据库正常 跳过此步骤 ----> python zctl -t start -m MOUNT
获取受损页面的datafile序号和page序号 ,可以从客户端报错运行日志中找到page序号
运行ztrst工具修复 受损磁盘页面 ----> ztrst Changeme_123:1881 -D /temp -B /data/backup/bak1 -p 3_44 -s 192.168.0.1:1888
修复完成后 若是已 mount 模式启动 ,重启数据库
方法2: HA场景下 如果发生坏页在主机, 并没有停止主机 , 或者停止后可重新启动 , 则可以利用备机修复
1、 如果数据库已停止 需要重启数据库
2、在主机设置 BLOCK_REPAIR_ENABLE 参数为True ----> alter system set block_repair_enable = True;
3、重新执行提示报错的业务数据库, 主机数据库会自动修复 遇到的损坏页面
归档日志失败
问题现象: 生成归档日志失败

原因分析: 归档日志不存在 会导致生成归档日志失败 、 归档日志的权限被该表 , 不满足权限要求、 归档日志目录被错误修改
处理步骤: 日志文件不存在的话获取日志文件的备份文件 , 恢复日志文件
日志文件权限不足: chmod 700 目录 chmod 600 目录下文件
日志文件被错误修改 则修改日志文件为正确的目录
主机备份失败
问题现象: 错误信息 GS-00719 : session killed
原因分析: 备机可能正在同时执行 switchover 导致主机同步执行switchover 最终导致主机备份失败
处理步骤: 待备机执行switchover操作后, 重新执行备份恢复数据失败:
问题现象: restore 命令恢复数据失败
原因分析: 恢复数据时 数据库需要读取日志信息, 当日志文件权限未达到要求 会导致恢复数据失败 备份数据库文件损坏或者丢失 核对备份数据库文件信息
处理步骤: 停止数据库服务 python zctl -t stop
root 登录 执行chmod 705 $GSDB_DATA/data/log* 切换为omm用户
启动数据库服务 python zctl -t start

备份文件丢失或者损坏: 获取正确备份文件 再次进行数据修复
数据库hang
问题现象: 连接数据库或执行查询时 发生hang
分析原因: 数据库发生死锁 或者有事务持有锁长期不释放
处理步骤: 已DBA身份登录数据库---> select SID,SERIAL#. EVENT , PROGRAM ,CLIENT_IP , (SYSDATE- SQL_EXEC_START) *86400, WAIT_SID ,CURRENT_SQL_SQL,SQL_ID,MODULE FROM DV_SESSIONS WHERE status ‘active ’
备份数据库文件损坏或者丢失 核对备份数据库文件信息备份数据库文件损坏或者丢失 核对备份数据库文件信息其中wait_sid 表示会话阻塞ID ,为空表示不阻塞 ,(sysdate-sql_exec_start )*86400 表示会话当前SQL 已经执行的时间 秒
根据具体情况处理 如果该阻塞关闭不影响数据库 执行命令 ---> alter system kill session 'sid ,serial#' ;
如果关闭阻塞可能影响数据库则联系华为官方是否可以执行 关闭操作
创建表失败
问题现象: GS-00103 cant allocate page from test_user
分析原因: 创建表时 会出现由于DC POOL空间不足 , 导致创建失败 此时需要动手调整增大 SHARD_POOL_SIZE
处理步骤: 修改配置文件 engine.ini 调整 shard_pool_size 参数值 , shard_pool_size 取值范围82M ~32T
shared_pool_size = 128m , 重新启动数据库服务

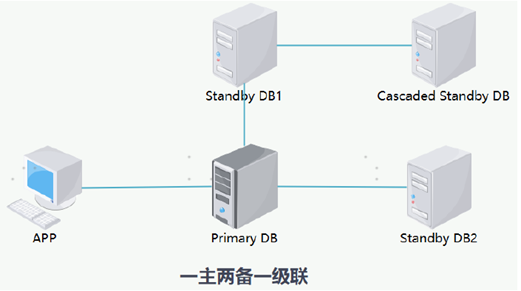
高可用: HA 物理复制 主备HA 和逻辑复制
一主一备: 主机承载业务 产生redo日志同步到备机, 备机重演日志恢复数据

一主两备一级联: 主机承载业务 产生redo日志同步到备机 备机重演日志恢复数据 备机将日志转发给级联
复制原理: GaussDB 100 有三种级别的保护模式
最大性能: 默认模式
最大保护: 保证数据零丢失
最大可用: 尽量保证数据安全 , 提供性能和数据安全的一个平衡方案



 浙公网安备 33010602011771号
浙公网安备 33010602011771号