
mysql慢查询分析
1. 慢查询配置
开启慢查询日志
查询状态
show variables like 'slow_query_log';
设置开启或关闭
set global slow_query_log = ['ON'/'OFF'];
指定慢查询日志log文件
set global slow_query_log_file = /var/lib/mysql/slowlog.log
设置超时则写入到慢查询日志中,可以有6位小数,到微秒;设置为0,则所有sql记录到慢查询日志中
set global long_query_time = xx.xxx秒
所有未使用索引的sql记录到日志中
set globallog_queries_not _using_indexes= ['ON'/'OFF']
持久化配置:my.cnf中配置慢查询配置
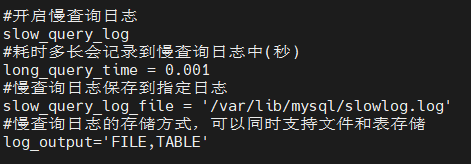
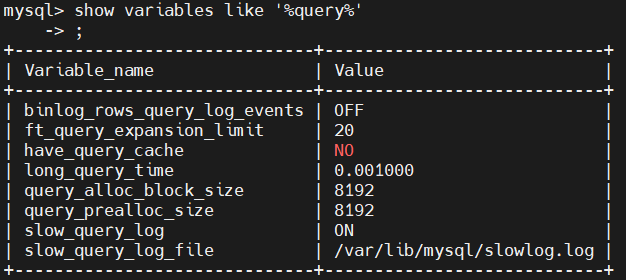
查询慢查询配置:show variables like '%query%';
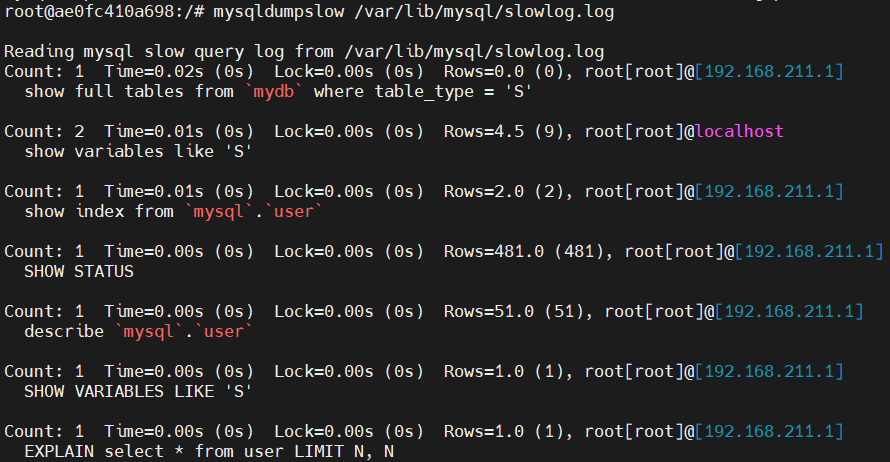
2. mysqldumpslow命令分析慢查询
/*传入慢查询日志作为参数*/
mysqldumpslow[ OPTS... ][ LOGS...]
mysqldumpslow slowlog.log
3.0 函数及存储过程耗时分析
mysql分析sql语句耗时情况
mysql -h10.3.40.98 -uroot -p command
mysql> use viewdb;
mysql> set profiling=1;
call func();
show profiles;
4. 使用Percona Toolkit工具分析慢查询

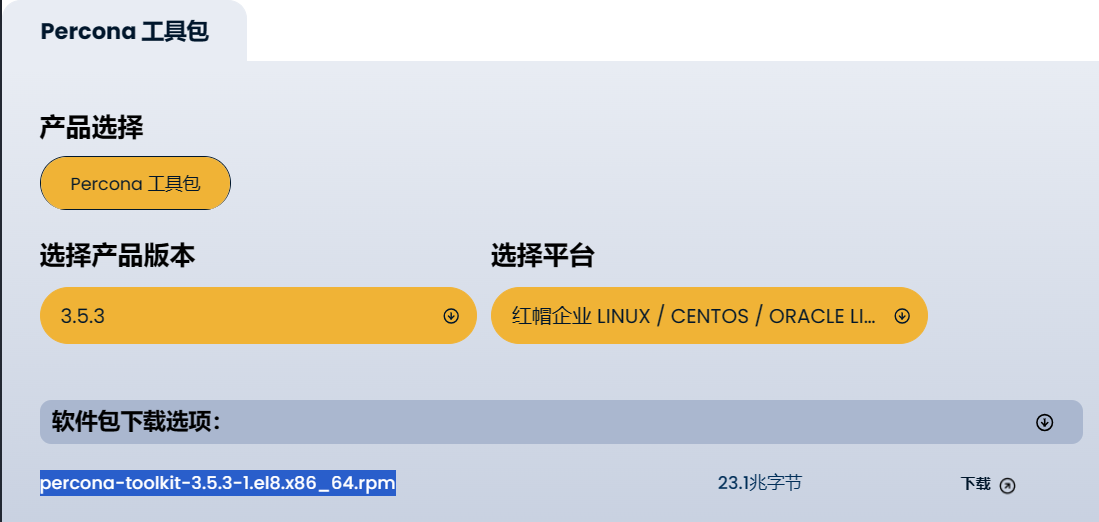
/* Percona Toolkit工具 源码下载 */
/* 安装依赖 */
yum install perl-DBI.x86_64
yum install perl-DBD-MySQL.x86_64
yum install perl-IO-Socket-SSL.noarch
yum install perl-Digest-MD5.x86_64
yum install perl-TermReadKey.x86_64
yum install perl-CPAN
yum install perl-Time-HiRes
/* 下载源码 */
wget percona.com/get/percona-toolkit.tar.gz
tar zxf percona-toolkit.tar.gz
cd percona-toolkit-3.5.5
perl Makefile.PL PREFIX=/usr/local/percona-toolkit
/* 将容器中的log复制出来 */
docker cp ae:/var/lib/mysql/slowlog.log /home/bk
/* 示例 */
pt-query-digest [OPTIONS][FILES][DSN]
pt-query-digest /home/bk/slowlog.log
5.监控长时间运行的SQL
/* 只能查询到自己账户下的sql */
SELECT id, 'user', 'host', DB, command, 'time', state, info FROM information_schema.PROCESSLIST WHERE TIME>=60;
6.EXPLAIN执行计划内容分析
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| id | select_type | table | partitions | type | possible keys | key | key_len | ref | rows | filtered | Extra |
6.1 ID
- ID表示查询执行的顺序
- ID相同时由上到下执行
- ID不同时,由大到小执行
6.2 select_type
| 值 | 含义 |
|---|---|
| SIMPLE | 不包含子查询或是UNION操作的查询 |
| PRIMARY | 查询中如果包含任何子查询,那么最外层的查询则被标记为PRIMARY |
| SUBQUERY | SELECT列表中的子查询 |
| DEPENDENT SUBQUERY | 依赖外部结果的子查询 |
| UNION | union操作的第二个或是之后的查询的值为union |
| DEPENDENTUNION | 当UNION做为子查询时,第二或是第二个后的查询的select_type值 |
| UNION RESULT | UNION产生的结果集 |
| DERIVED | 出现在FROM子句中的子查询 |
6.3 table
- 指明是从那个表中获取数据
- "unionM,N"由ID为MN查询union产生的结果集
- "derived N" 或者 "subquery N" 由ID为N的查询产生的结果
6.4 partitions
- 对于分区表,显示查询的分区ID
- 对于非分区表,显示NULL
6.5 type
| 性能 | 值 | 含义 |
|---|---|---|
| 高 | system | 这是const联接类型的一个特例,当查询的表只有一行时使用 |
| const | 表中有且只有一个匹配的行时使用,如对主键或是唯一索引的查询,这是效率最高的联接方式 | |
| eq_ref | 唯一索或主键引查找,对于每个索引键,表中只有一条记录与之匹配 | |
| ref | 非唯一索引查找,返回匹配某个单独值的所有行 | |
| ref or_null | 类似于ref类型的查询,但是附加了对NULL值列的查询 | |
| index_merge | 该联接类型表示使用了索引合并优化方法 | |
| range | 引范围扫描,常见于between、>、<这样的查询条件 | |
| index | FULLindex Scan全索扫描,同ALL的区别是,遍历的是索引树 | |
| 低 | DERIVED | 出现在FROM子句中的子查询 |
6.6 possible keys
- 指出查询中可能会用到的索引
6.7 key
- 指出查询时实际用到的索引
6.8 key_len
- 实际使用索引的最大长度
6.9 ref
- 指出那些列或常量被用于索引查找
6.10 rows
- 跟据统计信息预估的扫描的行数
6.11 filtered
表示返回结果的行数占需读取行数的百分比,越高越好
6.12 Extra
| 值 | 含义 |
|---|---|
| Distinct | 优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作 |
| Not exists | 使用notexists来优化查询 |
| Using filesort | 使用文件来进行排序,通常会出现在order by 或group by查询中 |
| Using index | 使用了覆盖索引进行查询 |
| Using temporary | MySQL需要使用临时表来处理查询,常见于排序,子查询和分组查询 |
| Using where | 需要在MySQL服务器层使用WHERE条件来过滤数据 |
| select tables optimizedaway | 直接通过索引来获得数据,不用访问表 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号