点分治及动态点分治学习笔记
前置知识:点分治
点分治,是处理树上路径的一个极好的方法。
如果你需要大规模地处理一些树上路径的问题是,点分治是一个不错的选择。
具体思路
给定一棵有 个点的树,询问树上距离为 的点对是否存在。
大多数同学的暴力做法都是对于每一个点对 进行 dfs 来求解。
但其实利用分治这一种算法,可以大大减少搜索的时间复杂度。
对于一个序列上的区间和等操作,我们可以使用分治来将原问题分解成几个子问题来求解,之后再合并答案。
而在树上我们也是可以进行这一种操作的。
可是树上的每一个子树的节点数是不确定的,不能单单的取中点,或直接取一号子树。(分治的点的错误选择会导致时间复杂度十分不稳定)。
所以,引入重要概念 —— 树的重心。
定义:找到一个点,其所有的子树中最大的子树节点数最少,那么这个点就是这棵树的重心,删去重心后,生成的多棵树尽可能平衡。
方法, dfs 即可,不讲,看代码。
void find(int x, int fa)
{
siz[x] = 1;
mx[x] = 0;
for(int i = head[x]; i; i = nxt[i])
{
int v = to[i];
if(siz[v]) continue;
find(v, x);
siz[x] += siz[v];
chkmax(mx[x], siz[v]);
}
chkmax(mx[x], S - siz[x]);
if(mx[x] < mx[rt])
rt = x;
}再看最重要的部分 —— 分治。
显然对于一棵有根树,树上的路径可以分成两类:经过根节点的路径和不经过根节点的路径。
实际上,第二种路径可以转化成第一种路径,根据 大子树中所有不经过根节点的路径都可以被转化成小子树中经过根节点的路径,并且不影响答案。
从而可以考虑对子树进行分治,借此统计所有的树上路径。
根据题目,分治一棵子树时通常需要对子树进行遍历,单次时间复杂度 。
考虑找一个点,使得整棵树平衡,那么取重心即可。
设树中节点总数为 。易知以树的重心为根节点时,根节点的子树大小最大为 。故而最多递归分治 层,处理每层的时间复杂度为 。故总时间复杂度为 。
假设当前分治到以 为根的子树时,需要对子树进行遍历,求取需要的信息。
不妨求出当前分治的子树中所有节点到 的距离,记为 。
然后记点 的属于 的那棵子树的编号,记为 ,再遍历一遍子树,记录下经过的节点,依次记为 。
void get_dis(int u, int fa, int dis, int from)
{
a[++tot] = u;
d[u] = dis;
b[u] = from;
for (re int i = head[u]; i; i = edge[i].nxt)
{
int v = edge[i].to;
if (v == fa || vis[v])
continue;
get_dis(v, u, dis + edge[i].val, from);
}
}
首先将 序列按照 值排序。
然后用双指针维护答案即可。
注意,当存在节点 使得 且 同属 的一棵子树时(即 ), 到 的路径不合法(路径间有重合部分),特判即可。
点分树
给一棵 个点的树,以及一个固定的 ,所有边的权都为 ,每个点有黑白两色,一开始全是白点,接下来有 个操作。
第一种操作,询问图中距离为 的白点对数量;
第二种操作,将点 的颜色修改(黑变白,白变黑)。
简单来说就是动态点分治。
实际上,点分树就是将点分治时的重心相连,所构成的一棵树。
举个栗子,比如说有这么一棵树:
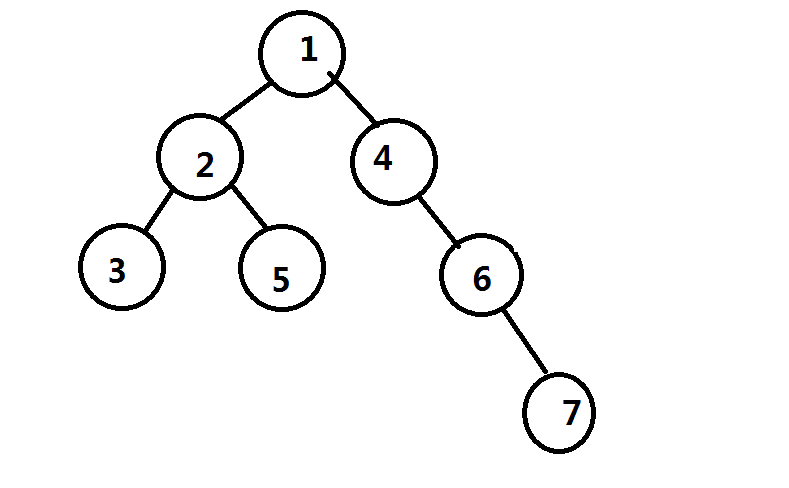
我们假设已经处理完了所有经过点 的路径,然后递归进子树继续点分,那么实际上原树被拆成了这么两棵树,两个重心分别为 和
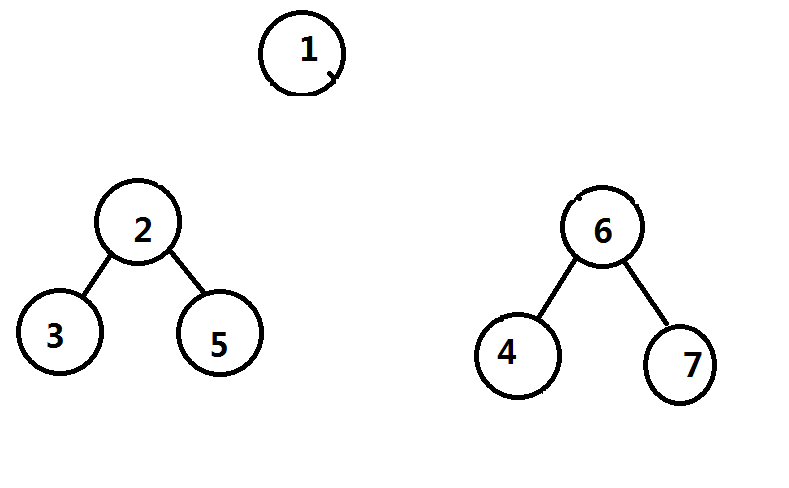
那么把第一层的重心和第二层的重心给连接起来(用红色表示)
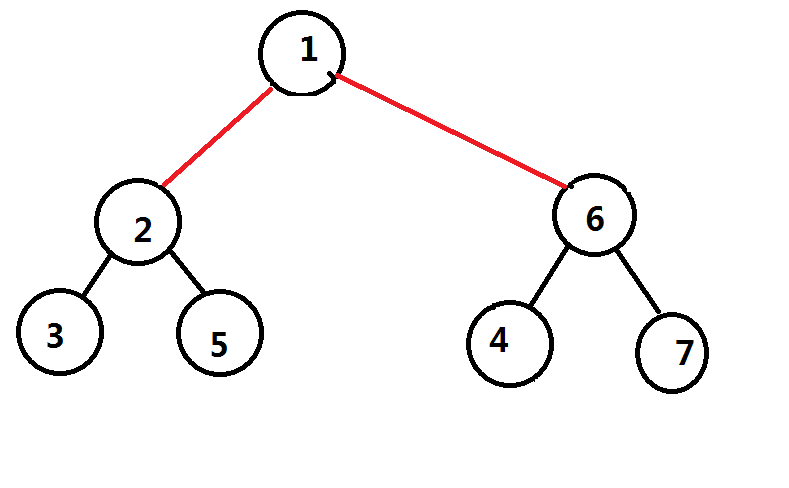
然后我们继续进行点分,我们已经把经过点 和点 的所有路径都已经处理完了,那么子树又会继续拆分
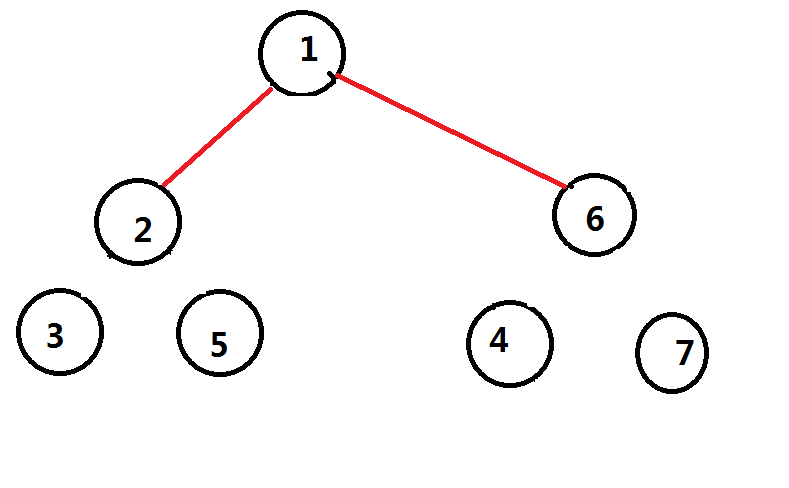
然后因为子树大小只有 ,重心就是他们自己,继续和上一层的重心连边
然后这一棵点分树就建好了。
建完点分树后,每一次分治时,我们就不用重新去找重心,直接沿着点分树向上跳即可。
点分树有两个性质:
- 原树上任意两点 在点分树上的 一定在 到 的路径上。
- 点分树的树高是 级别的。
考虑一个重心, 在它的子树内, 的深度为 (在该子树内),那么 对于该重心能产生的贡献就是深度为 的点的数量(当然要减掉 所在的那棵子树内的点)。
显然,预处理一下,是可以 求出贡献的。
于是,当每次修改某个点的颜色时,只需要从这个点开始,沿着点分树一路往上跑,沿途更新答案即可。
因为树上点分治的分治层数保证不超过 层,所以点分树的深度也不会超过 ,所以每一次的修改就是 的。
例题
P6329 【模板】点分树 | 震波
有一棵 个带权点的树,所有边的长度都是 ,现在有两种操作。
操作 :询问 周围与它距离不超过 的点的权值和(包括自己)。
操作 :修改某点的权值。
考虑使用动态点分治。
对于每一次询问,可以从 开始沿着点分树向上走,对于每个到达的点(也就是重心),我们可以统计答案,该点能提供的贡献就是深度小于等于 (这里的 的深度(即 )是相对于该重心而言的)的点的贡献和,但是还要减去与 同一棵子树内的贡献。
对于每一次修改,我们依然沿着点分树走,沿途修改对于每个重心而言深度为 的点的贡献和。
发现对于每个重心,我们有两种操作,一是统计小于等于某深度的点的权值和,一种是修改某深度的点的权值和,发现正是个改点求段操作,于是可以用树状数组解决。
还有一个坑点,就是在点分树上求解的时候,不能在发现某个时候 就停下,不继续向上跳求解。
因为在点分树上跳时,是不能保证重心到 的距离递增的。
具体见代码。
P2056 [ZJOI2007]捉迷藏
有一个 个点的树,每个节点有黑白两种颜色之一,一开始全是白点,现在有两种操作。
操作一:修改某个点的颜色(黑变白,白变黑)。
操作二,询问最远的两个白点的距离。
因为跟树上的点对距离有关系,很自然的就想到树上点分治,但是有修改操作,于是使用动态点分治即可。
那我们考虑对于每一个重心如何更新答案。
对于每一个重心,它能产生的贡献,就是子树中离自己最远的两个白点的距离之和,并且要求这两个白点来自该重心的两个不同的子树中。
那么因为有修改操作,于是我们需要用一个堆来维护这个重心的每一棵子树提供的那个最远的白点,然后取这个堆中的最大值和次大值相加便可以更新答案。
那么显然,我们还需要一个堆,去维护每一棵子树中每一个白点到重心的距离。
最后还需要一个堆,将每一个重心求出的答案进行维护,最后取堆顶便是答案。
考虑这三个数据结构:
A, 这个维护的是 数字的可重集合,即所有点贡献值的集合,这个数据结构要满足:每次查询可以快速的插入一个值、删除一个值,或者得到最大值。B[x],这个表示 点每个孩子的离 最远的白点的距离的可重集合。这个数据结构要满足:每次查询可以快速的插入一个值、删除一个值,或者得到最大值和次大值。C[x],这个表示 点子树中所有白点离 的距离的可重集合,这个数据结构要满足:每次查询可以快速的插入一个值、删除一个值,或者得到最大值。
分别维护即可。
具体见代码。
P3920 [WC2014]紫荆花之恋
本文来自博客园,作者:蒟蒻orz,转载请注明原文链接:https://www.cnblogs.com/orzz/p/18122051


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】