使用HtmlAgilityPack和ScrapySharp抓取网页数据遇到的几个问题解决方法——格式编码问题
需要用到对应市区县街道居委会的区域编码,于是找到统计局的网页,对这些数据进行抓取,用到了HtmlAgilityPack和ScrapySharp,由于也是第一次从网页抓取数据,所以对于HtmlAgilityPack和ScrapySharp的使用也是不熟悉,期间遇到了很多问题,在这里对其做下总结
对于HtmlAgilityPack和ScrapySharp的使用,在网上有大量的使用demo,不过看来看去基本都是同一篇,也不知道谁是原作者,这里附上天方的博文,demo就不抄了,附上链接,需要的可以在去看看
TianFang-使用ScrapySharp快速从网页中采集数据
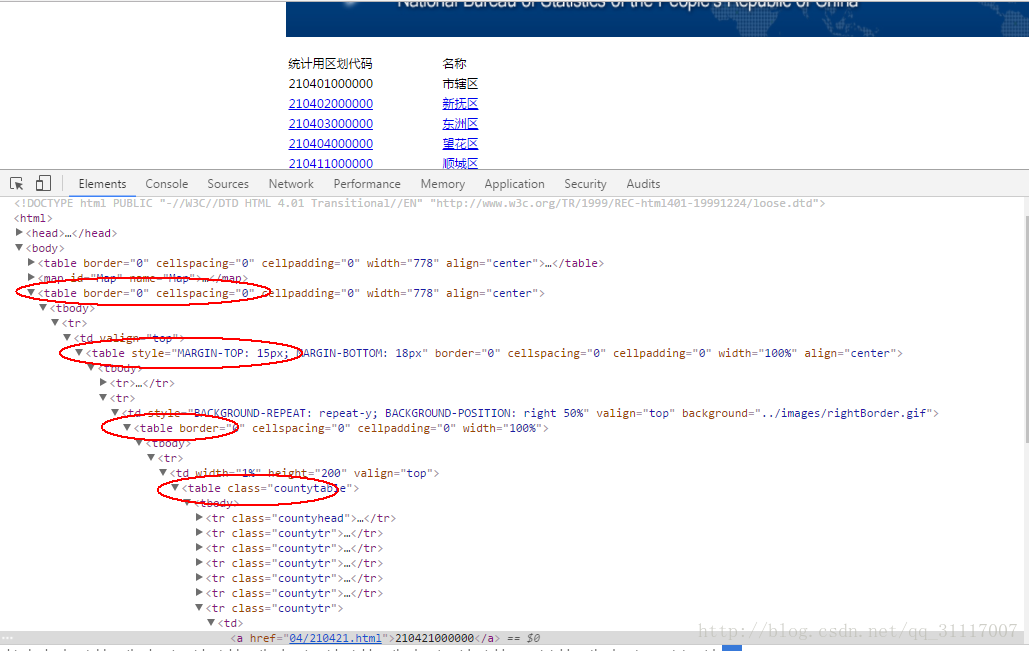
这里的CSS选择器的用法很简单,跟我们写CSS对HTML元素做定位是一样的。由于统计局的网页内容如下图
一个table套一个table,连套四个,而我们抓取数据又不仅仅是抓取一个页面的内容,所以这里只能找统一的规律,最后直接用了简单粗暴的方法var divs = html.CssSelect("table table table table tr");//直接获取到最底层的table的tr
在取到对应的值后,又遇到个问题,抓取的数据无论是读出到控制应用台还是保存到文本中,读取到的中文都是问号,最终发觉是格式编码的问题,demo上的网页用的格式编码是utf-8,而ScrapySharp抓取的默认格式编码应该也是utf-8所以不会出现问题,而统计局这的编码格式是gbk2312,因为请求抓取数据没有使用正确的编码格式,所以导致抓取到的数据变成乱码。
正如前面所说,百度一搜基本都是天方的那一篇博文,根本没有一个提出类似问题的解决方案,而且ScrapySharp的使用文档也找不到,最后在一篇擦边的文章中找到了解决方法代码如下
var browser1 = new ScrapingBrowser { Encoding = Encoding.GetEncoding("gb2312") };//在定义抓取实体时,对其进行设置,之前一直在对抓取之后的内容进行编码转换,结果都没有任何作用,真正的转换是要在抓取之前对请求进行设置至此网页内容的抓取基本是成功的了,于是开启程序开始让它抓取数据
但是在程序运行过程中遇到一个问题就是有时网络出现不稳定或者过于频繁访问该网站,导致报502错误,程序就会报异常,我的解决方法是用try catch去抓取网页内容,如果异常了这给内容赋空字符串,让它继续跑下去,这样就没有问题了,不过这个不算是一个好的解决方法,奈何目前能力有限,就只能这么用着先了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号