
程序是如何执行的(三)函数调用
一、局部变量与全局变量
函数中出现的变量可以分为局部变量和全局变量,在函数内部定义的变量(没有global语句)就是局部变量,只有在函数内部才能够使用它们。在函数外定义的变量就是全局变量
全局变量的作用是增加了函数间数据联系的渠道,全局变量在全部执行过程中都占用存储单元,如果在同一个源文件中,局部变量和全局变量同名,则在局部变量的作用范围内全局变量被屏蔽即它不起作用。
静态局部变量,有时希望局部变量的值在函数调用结束后不消失而保持原值,即其占用的存储空间不释放,在下一次函数调用时,该变量已有值,即上次函数调用结束时的值,就应该指定该局部变量为"静态局部变量",用static声明。静态局部变量属于静态存储类别,在静态存储区分配内存单元,在程序整个运行期间都不释放,动态局部变量属于动态存储类别,站动态存储区,函数调用结束即释放。静态局部变量的赋值是在编译期,即只赋值一次,在程序运行时它已有初值,以后每次调用函数不再重新赋值而是保留上次函数调用结束的值,而对动态局部变量不是在编译时期进行的,而是在函数调用时进行的,每调用一次函数就重新给一次赋值
二、函数调用过程的分析
1、返回地址的存储
执行一条指令时,是根据PC中存放的指令地址,将指令由内存取到指令寄存器IR中。程序在执行时按顺序依次执行每一条语句,PC通过加1来指向下一条将要执行的程序语句。但也有一些例外:(1)调用函数(2)函数调用后的返回(3)控制结构(if else while for等)
主调函数是指调用其他函数的函数,被调函数是指被其他函数调用的函数,一个函数既调用别的函数又被另外的函数调用
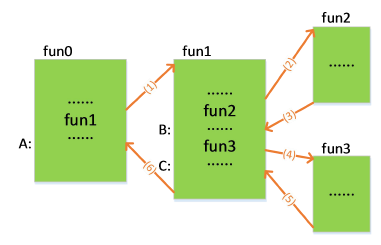
上图中,fun0函数调用fun1,fun0函数就是主调函数,fun1是被调函数
发生函数调用时,程序会跳转到被调函数的第一条语句,然后按顺序依次执行被调函数中的语句。函数调用后返回时,程序会返回到主调函数中调用函数的语句的后一条语句继续执行。换句话说,也就是“从哪里离开,就回到哪里”。
CPU执行程序时,并不知道整个程序的执行步骤是怎样的,完全是“走一步,看一步”。前面我们提到过,CPU都是根据PC中存放的指令地址找到要执行的语句。函数返回时,是“从哪里离开,就回到哪里”。但是当函数要从被调函数中返回时,PC怎么知道调用时是从哪里离开的呢?答案就是——将函数的“返回地址”保存起来。因为在发生函数调用时的PC值是知道的。在主调函数中的函数调用的下一条语句的地址即为当前PC值加1,也就是函数返回时需要的“返回地址”。我们只需将该返回地址保存起来,在被调函数执行完成后,要返回主调函数中时,将返回地址送到PC。这样,程序就可以往下继续执行了。
函数调用的特点是:越早被调用的函数,越晚返回。比如fun1函数比fun2函数先调用,但是返回的时候fun1晚于fun2返回。这一特点正是"后进先出",所以我们采用栈来保存返回地址
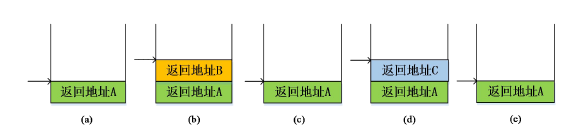 如上图调用过程(1)发生时,需要压入保存返回地址A,栈的状态如图中(a)所示;调用过程(2)发生时,需要压入保存返回地址B,栈的状态如图中(b)所示;返回过程(3)发生时,需要弹出返回地址B,栈的状态如图中(c)所示;调用过程过程(4)发生时,需要压入保存返回地址C,栈的状态如图中(d)所示;返回过程(5)发生时,需要弹出返回地址C,栈的状态如图中(e)所示;返回过程(6)发生时,需要弹出返回地址A,此时栈被清空,图中未画出具体情况
如上图调用过程(1)发生时,需要压入保存返回地址A,栈的状态如图中(a)所示;调用过程(2)发生时,需要压入保存返回地址B,栈的状态如图中(b)所示;返回过程(3)发生时,需要弹出返回地址B,栈的状态如图中(c)所示;调用过程过程(4)发生时,需要压入保存返回地址C,栈的状态如图中(d)所示;返回过程(5)发生时,需要弹出返回地址C,栈的状态如图中(e)所示;返回过程(6)发生时,需要弹出返回地址A,此时栈被清空,图中未画出具体情况
2、函数调用时栈的管理
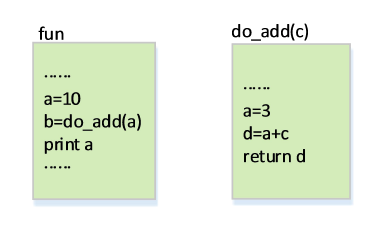
如上图所示,fun函数里的变量a和do_add函数里的变量a是两个不同的变量,这两个变量需要存放在不同的地方。局部变量a只在do_add函数内才有意义;局部变量的存储一定是和函数的开始与结束息息相关的。局部变量如同返回地址般也是存在栈里。当函数开始执行时,这个函数的局部变量在栈里被设立(压入),当函数结束时,这个函数的局部变量和返回地址都会被弹出。
当函数调用时,do_add函数里局部变量c就复制fun函数里变量a的值。在函数返回时,与参数传递同理,在传递返回值时也是将do_add函数里的值赋值给主调函数中的变量b。局部变量只在函数内有意义,离开函数后该局部变量就失效。比如do_add函数里的局部变量d,执行do_add函数时d是有意义的。但执行完do_add函数后,返回到fun函数中,do_add函数里的局部变量d就失效了。因此在弹出d时需要用一个寄存器将返回值d保存起来,所以在外面的调用函数可以来读取这个值。
局部变量的调用是和栈的操作模式“后进先出”的形式是相同的。这就是为什么返回地址是压入栈里,同样的,局部变量也会压到相对应的栈里面。当函数执行时,这个函数的每一个局部变量就会在栈里有一个空间。在栈中存放此函数的局部变量和返回地址的这一块区域叫做此函数的栈帧(frame)。当此函数结束时,这一块栈帧就会被弹出。
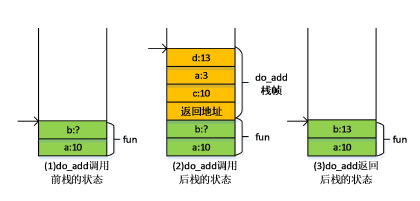
调用do_add()函数前执行的操作:(1)fun的局部变量a压入栈中,其值为10(2)局部变量b压入栈中,由于b的值还未知,因此先为b预留空间
调用do_add()函数时执行的操作:(1)返回地址压到栈中(2)局部变量c的值10压入栈中(c的值是通过复制fun函数中变量a得到的)(3)压入do_add中的局部变量a,其值为3(4)执行a+c,其中a=3,c=10,相加后得d的值为13
do_add()函数返回时执行的操作:(1)do_add()函数执行完后,依次弹出do_add()的局部变量,由于需要将d的值返回,因此在弹出d的时候需要一个寄存器将返回值d保存起来(2)弹出返回地址,将返回地址传到PC(3)返回到fun函数,fun中的局部变量b的值即为do_add()中的返回值d,此时将寄存器中的值赋给b。
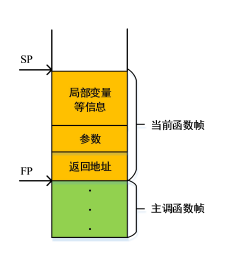
在函数调用时,用一个寄存器将栈顶地址保存起来,称为栈顶指针SP。另外还有一个帧指针FP,用来指向栈中函数信息的底端。这样,栈就被分成了一段一段的空间。每个栈帧对应一次函数调用,在栈帧中存放了前面介绍的函数调用中的返回地址、局部变量值等。每次发生函数调用时,都会有一个栈帧被压入栈的最顶端;调用返回后,相应的栈帧便被弹出。当前正在执行的函数的栈帧总是处于栈的最顶端。
由于函数调用时,要不断的将一些数据压入栈中,SP的位置是不断变化的,而FP的位置相对于局部变量的位置是确定的,因此函数的局部变量的地址一般通过帧指针FP来计算,而非栈指针SP。
综合前面所讲,可以总结出:(1)一个函数调用过程就是将数据(包括参数和返回值)和控制信息(返回地址等)从一个函数传递到另一个函数。(2)在执行被调函数的过程中,还要为被调函数的局部变量分配空间,在函数返回时释放这些空间。这些工作都是由栈来完成的。所传参数的地址可以简单的从FP算出来。下图展示了栈帧的通用结构
三、实例分析
举一个下图中例子来综合研究一下函数调用时对栈的管理

pre函数调用fac(1)函数前执行的操作:
(1)pre的局部变量m压入栈中,其值为1
(2)局部变量f压入栈中,由于f的值还未知,因此先为f预留空间
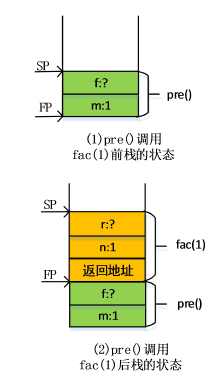
pre函数调用fac(1)函数时执行的操作:
(1)返回地址压入栈中;
(2)fac(1)的局部变量n压入栈中,其值为1;
(3)局部变量r压入栈,由于r的值还未知,因此先为r预留出空间
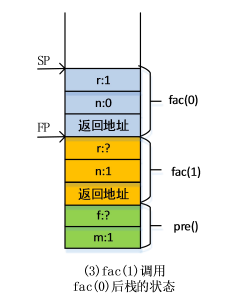
fac(1)函数调用fac(0)时执行的操作:
(1)返回地址压入栈中;
(2)fac(0)的局部变量n压入栈中,其值为0;
(3)此时递归达到了终止条件(n==0),结束递归,局部变量r压入栈,r的值为1。
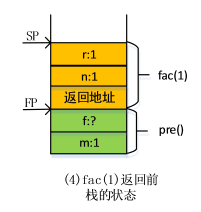
fac(0)函数返回时执行的操作
(1)fac(0)函数执行完后,依次弹出fac(0)的局部变量。在弹出r时用一个寄存器将返回值r保存起来;
(2)弹出返回地址,将返回地址传到PC;
(3)SP=FP,令SP指回fac(1)栈帧的顶部,令FP指回fac(1)栈帧的底部
(4)继续执行函数fac(1),fac(1)中的局部变量r的值即为fac(0)中的返回值乘以n

fac(1)函数返回时执行的操作
(1)fac(1)函数执行完后,依次弹出fac(1)的局部变量,在弹出r时用一个寄存器将返回值r保存起来;
(2)弹出返回地址,将返回地址传回到PC;
(3)SP=FP,令SP指回pre栈帧的顶部,令FP指回pre栈帧的底部
(4)继续执行函数pre,pre中的局部变量f的值即为fac(1)中的返回值r,此时将寄存器中的值赋值给f
各类微处理器对函数调用的处理方式会有所差异,同一体系结构中对不同语言的函数调用的处理方式也会有少许的差异。但通过栈存储局部变量和返回地址等信息,这一点是共同的。我们不需要对函数调用中的每一个执行的细节都了解清楚:知道每一次函数调用对应一个栈帧,栈帧中包含了返回地址、局部变量值等信息。还有一点要注意,解释性语言中发生函数调用时所建立的栈,不是编译时建立的(像C语言等是在编译时就建好了栈),是在有需要的时候再建立的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号