
理解内存对齐
原文地址: https://blog.fanscore.cn/p/24/
相信大家都听说过内存对齐的概念,不过这里还是通过一个现象来引出本篇话题。
一、求一个结构体的size
猜下下面这个结构体会占用多少字节
type S struct {
B byte // Go中一个byte占1字节,int32占4个字节,int64占8个字节
I64 int64
I32 int32
}
是不是以为是1+8+4 = 13个字节?写段代码验证下:
type S struct {
B byte
I64 int64
I32 int32
}
func main() {
s := S{}
fmt.Printf("s size:%d\n", unsafe.Sizeof(s))
}
输出:
s size:24
与预想显然不同,这是为什么呢?答案是编译器替我们做了内存对齐。
二、什么是内存对齐
要理解这个问题需要先了解一下字长的概念以及内存的物理结构
2.1 字长
在计算器领域,对于某种特定的计算机设计而言,字(word)是用于表示其自然的数据单位的术语。在这个特定计算机中,字是其用来一次性处理事务的一个固定长度的位(bit)组。一个字的位数即为字长。
字长在计算机结构和操作的多个方面均有体现,计算机中大多数寄存器(这里应该是指通用寄存器)的大小是一个字长。
上面这段话可能太过于概念化不太好理解,那么请看下面的这段64位机器上的GUN汇编器语法的汇编代码:
movq (%ecx) %eax
这段汇编代码是将eax这个寄存器中的数据作为地址访问内存,并将内存中的数据加载到eax寄存器中。
我们可以看到mov指令的后缀是q,意味着该指令将加载一个64位的数据到eax寄存器中,这样一条指令可以操作一个64位的数据,说明该机器的字长为64位,同时这段代码能够执行则说明我们机器上的CPU中的eax寄存器必定是64位的,而一条指令能够从内存中加载一个64位的数据也说明了数据总线的位宽也为64位,说明了我们的CPU可以一次从内存中加载8个字节的数据。
2.2 64位内存物理结构
内存是由若干个黑色颗粒组成的,每个内存颗粒叫做一个chip,每个chip是由8个bank组成,每个bank是二维平面上的矩阵,矩阵中的每个元素保存1个字节也就是8个bit。
对于内存中连续的8个字节比如0x0000-0x0007,并非位于一个bank上,而是位于8个bank上,每个bank保存一个字节,8个bank像是垂直叠在一起,物理上它们并不是连续的。
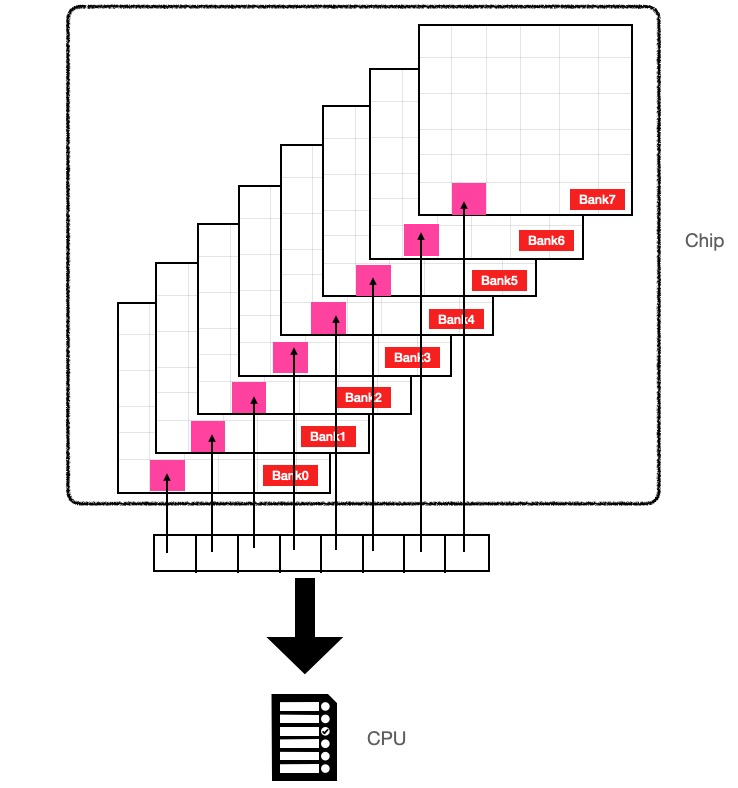
之所以这样设计是基于电路工作效率考虑,这样的设计可以并行取8个字节的数据,如果想取址0x0000-0x0007,每个bank只需要工作一次就可以取到,IO效率比较高,如果这8个字节在同一个bank上则需要串行读取该bank8次才能取到。
结合上面的结构图可以看到0x0000-0x0007是一列,0x0008-0x000F是另外一列,如果从内存中取8-15字节的数据也可以一次取出来,但如果我们要取1-9的数据就需要先取0-7的数据,再取8-15的数据然后拼起来,这样的话就会产生两次内存IO。所以基于性能的考虑某些CPU会强制只能读取8的倍数的内存,而这也导致了编译器再此类平台上编译时必须做内存对齐。
2.3 再来看结构体size的问题
以下均以64位平台,即:64位宽内存以及64位cpu(数据总线64位,寄存器64位)为前提
type S struct {
B byte
I64 int64
I32 int32
}
在不了解内存对齐前我们可能会简单以为结构体在内存中可能是这样排列的:
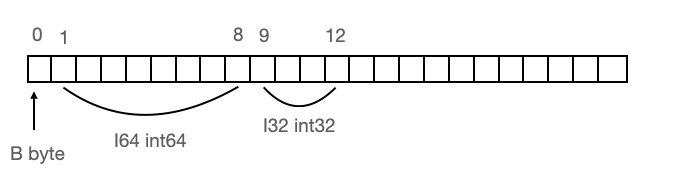
总共占用13个字节。我们可以看到 I64 这个字段的内存地址是1-8,而在64位平台上为了将这个字段加载到寄存器中,CPU需要两次内存IO。
但做内存对齐后:
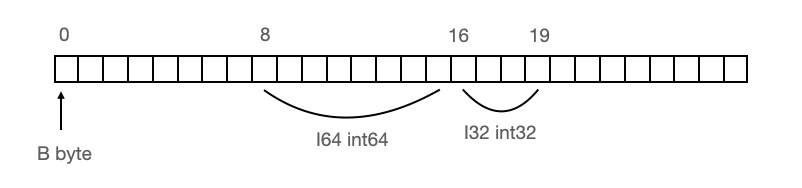
总共占用20个字节,I64这个字段的内存地址是8-15,为了将这个字段加载到寄存器中,只需要一次内存IO即可。
我们写段代码验证下是否真的占用了20个字节:
type S struct {
B byte
I64 int64
I32 int32
}
func main() {
s := S{}
fmt.Printf("s size: %d, align: %d\n", unsafe.Sizeof(s), unsafe.Alignof(s))
}
输出:
s size: 24, align: 8
程序输出了24,而非上面我们以为的20,这是怎么回事呢?原因是结构体本身也必须要做对齐,它必须在后面再额外占用4个字节以使自己的size为8的倍数。
上面的结构体如果后面跟一个4字节的变量的话理论上说不用对齐也能保证一次内存IO就可加载,所以结构体对齐的根本原因目前我还不是特别能理解,可能为编译器做的优化,了解的同学欢迎在评论区指点一下
我们再调整下结构体的声明:
type S struct {
B byte
I32 int32
I64 int64
}
再做内存对齐的话该结构体在内存中应该就是下面这个样子了:
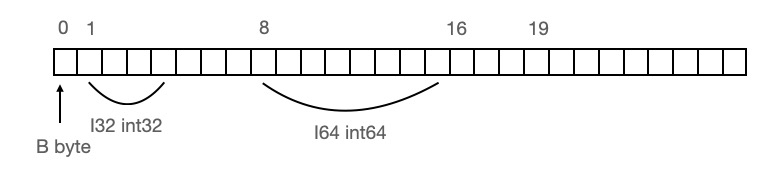
这时总共占用16个字节,相比较上面我们节省了8个字节。
写段代码验证下:
type S struct {
B byte
I32 int32
I64 int64
}
func main() {
s := S{}
fmt.Printf("s size:%v, s.B地址:%v, s.I32地址:%v, s.I64地址:%v\n", unsafe.Sizeof(s), &s.B, &s.I32, &s.I64)
}
输出结果:
s size:16, s.B地址:0xc0000b4010, s.I32地址:0xc0000b4014, s.I64地址:0xc0000b4018
确实占用了16字节,但貌似I32这个字段跟我们预想的不太一样,它被对齐到了4的倍数地址上,而非紧跟在B后边,这大概是编译器考虑到用户可能使用32位cpu/内存而导致的,目前没有查到相关资料姑且这么认为吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号