基于正则化的多任务学习
 最近导师让我做分布式多任务学习方面的工作,我开始着手阅读这方面的论文并归纳一个大致的速览。首先,我们看看什么是多任务学习,然后我们主要聚焦于基于正则化的多任务学习方法(这也是目前学术界主要的并行对象),并在此基础上讨论如何分布式并行。类似于迁移学习,多任务学习也运用了知识迁移的思想,即在不同任务间泛化知识。但二者的区别在于:迁移学习可能有多个源域;而多任务学习没有源域而只有多个目标域;且迁移学习注重提升目标任务性能,并不关心源任务的性能(知识由源任务→目标任务;而多任务学习旨在提高所有任务的性能(知识在所有任务间相互传递)。
最近导师让我做分布式多任务学习方面的工作,我开始着手阅读这方面的论文并归纳一个大致的速览。首先,我们看看什么是多任务学习,然后我们主要聚焦于基于正则化的多任务学习方法(这也是目前学术界主要的并行对象),并在此基础上讨论如何分布式并行。类似于迁移学习,多任务学习也运用了知识迁移的思想,即在不同任务间泛化知识。但二者的区别在于:迁移学习可能有多个源域;而多任务学习没有源域而只有多个目标域;且迁移学习注重提升目标任务性能,并不关心源任务的性能(知识由源任务→目标任务;而多任务学习旨在提高所有任务的性能(知识在所有任务间相互传递)。
1.导言
现在多任务学习根据实现方法可以粗略地被分为两种,一个是基于神经网络的多任务学习[1][2][3][4],这种多任务学习在CV和NLP取得了大量的应用。

然而我们最根溯源,其实多任务学习最开始并不是基于神经网络的,而是另一种经典的方法——基于正则表示的多任务学习,我们这篇文章也主要介绍后者。为什么在深度学习称为主流的今天,我们还需要了解过去的传统方法呢?
首先,经典的多任务学习和基于神经网络的多任务学习方法本质上都是基于知识共享的思想,而这种思想其他领域,比如联邦学习中得到了大量的应用(参见我的博客《分布式多任务学习及联邦学习个性化》)。而经典的基于正则表示的多任务学习更容易分布式化,因此大多数联邦多任务学习的论文灵感其实都来源于经典方法。我的研究领域主要是联邦学习,故我们下面主要介绍经典多任务学习。
2、多任务学习简介
2.1 多任务学习:迁移学习和知识表示的延伸
多任务学习(Multi-task Learning, MTL)近年来在CV、NLP、推荐系统等领域都得到了广泛的应用。类似于迁移学习,多任务学习也运用了知识迁移的思想,即在不同任务间泛化知识。但二者的区别在于:
- 迁移学习可能有多个源域;而多任务学习没有源域而只有多个目标域。
- 迁移学习注重提升目标任务性能,并不关心源任务的性能(知识由源任务→→目标任务;而多任务学习旨在提高所有任务的性能(知识在所有任务间相互传递)。
下图从知识迁移流的角度来说明迁移学习和多任务学习之间的区别所示:
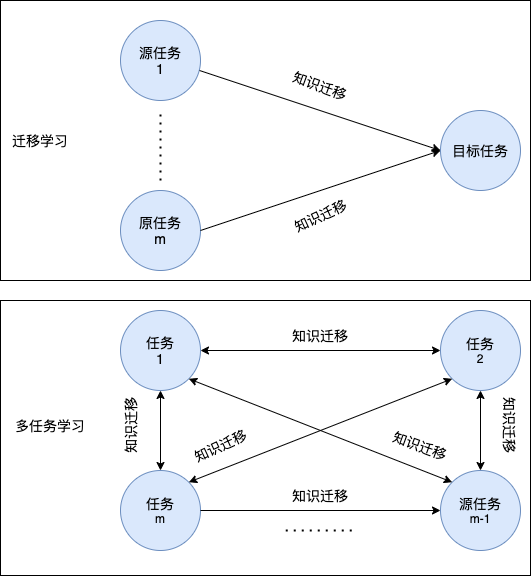
不严格地说,多任务学习的目标为利用多个彼此相关的学习任务中的有用信息来共同对这些任务进行学习。
2.2 多任务学习目前的两大主要实现方式
现在多任务学习根据数据的收集方式可以粗略地被分为两种,一个是集中化的计算方法,一种是分布式的计算方法,可以参见我的博客《分布式多任务学习及联邦学习个性化》。
3、基于正则化的多任务学习
3.1 基于正则化的多任务学习的形式表述
形式化地说,给定t个学习任务(我们这里只讨论监督学习){Tt}Tt=1,每个任务各有一个训练集Dt={(xti,yti)mti=1},其中xti∈Rd,yti∈R。多任务学习的目标是根据T个任务的训练集学习T个函数{ft(x)}Tt=1,使得ft(xti)可以很好的近似yti。学习完成后,ft(⋅)将用于对第t个任务中的新数据样本的标签进行预测。
接下来我们描述多任务学习的目标函数,若第t个任务的经验风险形式为E(xti,yti)∼Dt[L(yti,f(xti;wt))](设wt为第t个模型的参数),则一般多任务学习的目标函数形式为
(此处W=(w1,w2,...,wT)为所有任务参数构成的矩阵)
不过,如果我们直接对各任务的损失函数和∑Tt=1[1mt∑mti=1L(yti,f(xti))]进行优化,我们发现不同任务的损失函数是解耦(decoupled)的,无法完成我们的多任务学习任务。在多任务学习中一种典型的方法为增加一个正则项[5][6][7]:
这里g(W)编码了任务的相关性(多任务学习的假定)并结合了T个任务;λ是一个正则化参数,用于控制有多少知识在任务间共享。在许多论文中,都假设了损失函数f(W)是凸的,且是L-Lipschitz可导的(对L>0),然而正则项g(W)虽然常常不满足凸性(比如采用矩阵的核范数),但是我们认为其实接近凸的,可以采用近端梯度算法(proximal gradient methods)[8]来求解。
3.2 基于正则化的多任务学习分类
基于正则化的多任务学习依靠正则化来找到任务之间的相关性,大致可以分为基于特征和基于模型的这两种。
3.2.1 基于特征的多任务学习
a. 特征变换
即通过线性/非线性变换由原始特征构建共享特征表示。这种思想最早可追溯到多任务学习的开山论文——使用多层前馈网络(Caruana, 1997)[9],如下图所示:

该示例中,假设所有任务的输入相同,将多层前馈网络的隐藏层输出视为所有任务共享的特征表示,将输出层的输出视为对T个任务的预测结果。
如果采用我们采用正则化框架,多任务特征学习(Multi-Task Feature Learning, MTFL)方法[10][11](Argyrious等人,2006、2008)和多任务稀疏编码(Multi-Task Sparse Coding, MTSC)[12]方法(Maurer等, 2013)都通过酉变换ˆxti=UTxti来为每个任务先构造共享特征表示, 再在此基础上为每个任务学习线性函数ft(xti)=⟨at,ˆxti⟩。设每个ft(xti)的参数为at,设线性函数的参数矩阵为A=(a1,...,aT)。 该方法定义的优化问题表示如下:
这里U∈Rd×d是酉(正交)矩阵。
与MTFL不同, MTSC方法的目标函数定义为
此时UT∈Rd′×d(d′<d),除了学习共享特征表示之外,还会起到降维的作用,d′为降维后的新特征维度,此外我们通过l1约束使A是稀疏的。
b. 联合特征学习(joint feature learning)
通过特征选择得到原始特征的共享子集(shared feature subset),以做为共享的特征表示。我们常采用的方法是将参数矩阵W=(w1,...,wT)正则化使其称为行稀疏矩阵,从而去除特定特征对于线性模型预测的影响,只有对所有任务都有用的特征被保留。
所有正则化方法中,最广泛使用的是lp,q正则化(即采用lp,q范数做为正则项),其目标函数为:
lp,q正则化的特例是l2,1[13][14](Obozinski等人,2006、2010)和l∞无穷正则化[15](Liu等人,2009b)。l2,1正则化中采用l2,1范数||W||2,1=∑di=1||wi||2(此处d为特征维度,wi为W第i行),l∞,1正则化采用l∞,1范数||W||∞,1=∑di=1||wi||∞=∑di=1max1⩽t⩽T|wjt|,即先对每一行方向求绝对值最大,然后再沿着行方向求和(注意区分这个和矩阵的∞范数,求和与求最大的顺序是不一样的!这里相当于求向量的无穷范数之和))。为了获得对所有特征都有用的更紧凑的子集,Gong等人[16](2013)提出了上限lp,1惩罚项∑di=1min(||wi||p,θ),当θ足够大时它将退化为lp,1正则化。
3.2.2 基于模型的多任务监督学习
a. 共享子空间学习(shared subspace learning)
该方法的假设参数矩阵W为低秩矩阵,以使相似的任务拥有相似的参数向量(即W的T个列向量尽量线性相关),以使T个任务的模型参数wt都来自一个共享低秩子空间。Ando和Zhang(2005)[17]提出了一个对wt的参数化方式,即wt=pt+ΘTqt,其中线性变换ΘT∈Rd′×d(d′<d)由于构建任务的共享子空间,pt是任务特定的参数向量。在正则项设计方面,我们在Θ上使用正交约束ΘΘT=I来消除冗余,此时相应的目标函数为:
Chen等人(2009)[18]通过为W增加平方Frobenius正则化推广了这一模型(Frobenius范数表达式为||A||F=(tr(ATA))1/2=(∑mi=1∑nj=1A2ij)1/2=(∑min(d,T)i=1σi(A)2)1/2),并采用松弛技术将问题转换为了凸优化问题。
除此之外,根据优化理论,使用矩阵的核范数(nuclear norm, 有时也称迹范数(trace norm))||W||∗=tr((ATA)1/2)=∑min(d,T)i=1σi(W)来进行正则化会产生低秩矩阵,所以核范数正则化(pong等人)也在多任务学习中应用广泛,此时目标函数通常为:
核范数是一rank function[19](Fazel等人, 2001)的紧的凸松弛,可以用近端梯度下降法求解。
b. 聚类方法
该方法受聚类方法的启发,基本思想为:将任务分为若个个簇,每个簇内部的任务在模型参数上更相似。
Thrun等人(1996)[20]提出了第一个任务聚类算法,它包含两个阶段。在第一阶段,该方法根据在单任务下单独学习得到的模型来聚类任务,确定不同的任务簇。在第二阶段,聚合同一个任务簇中的所有训练数据,以学习这些任务的模型。这种方法把任务聚类和模型参数学习分为了两个阶段,可能得不到最优解,因此后续工作都采用了同时学习任务聚类和模型参数的方法。
Bakker等人(2003)[21]提出了一个多任务贝叶斯神经网络(multi-task Bayesian neural network),其结构与我们前面所展现的多层神经网络相同,其亮点在于基于连接隐藏层和输出层的权重采用高斯混合模型(Gaussian mixture model)对任务进行分组。若给定数据集D={Dt},t=1,...,T,设隐藏层维度为h,输出层维度为T,W∈RT×(h+1)代表隐藏层到输出层的权重矩阵(结合了偏置)。我们假定每个任务对应的权重向量wt(W的第t列)关于给定超参数独立同分布,我们假定第t个任务先验分布如下:
这是一个高斯分布,均值为u∈Rh+1,协方差矩阵Σ∈R(h+1)×(h+1)。
我们上面的定义其实假定了所有任务属于一个簇,接下来我们假定我们有不同的簇(每个簇由相似的任务组成)。我们设有C个簇(cluster),则任务t的权重wt为C个高斯分布的混合分布:
其中,每个高斯分布可以被认为是描述一个任务簇。式(9)中的αc代表了任务t被分为簇c的先验概率,其中task clustering(如下面左图所示)模型中所有任务对簇c的加权αc都相同;而task-depenent模型(如下面右图所示)中各任务对簇c的加权αtc不同,且依赖于各任务特定的向量ft。

Xue等人(2007)[22]根据模型参数应用Dirichlet过程(一种广泛用于数据聚类的贝叶斯模型)对任务进行分组。
除了依赖贝叶斯模型的方法,还有一些正则化方法也被用于分组任务。如Jocob等人(2008)[23]提出了一个正则化项,将任务簇内部和之间的差异都考虑在内,以帮助学习任务簇,目标函数为:
其中第一个正则项度量所有任务任务平均权重的大小,第二个正则项表示任务簇内部的差异和簇之间的差异。Π∈RT×T表示中心化矩阵,A≼B表示B−A一定是半正定(Positive Semi-Definite, PSD)矩阵。α、β、γ是三个超参数。注意在问题(10)中,Σ学习到了任务簇的结构,因此在解决优化问题(10)之后,可以基于最优Σ来确定任务簇结构。
Kang等人(2011)[24]将式(3)所示的MTFL方法扩展到多个任务簇的情况下,其中每个任务簇中任务的学习模型是MTFL方法,其目标函数为:
这里||⋅||∗是矩阵的迹范数。qct∈{0,1} 是一个二值变量,表示任务t是否被分入第c个簇。矩阵Q∈RC×T以qct作为其元素,表示任务的划分情况。Qc∈RT×T为第c个簇对应的对角矩阵,其对角元素为qct,故对角矩阵Qc可用于识别第c个聚类的情况。
为了自动确定聚类的数量,Han和Zhang(2015a)[25]提出了先将任务划分为多个层次,然后再分别将各个层次的任务划分为簇。我们假定有H个任务层次(H为用户定义的超参数),我们将权重矩阵分解为:
Wh用于学习第h层次的任务簇。Wh=(wh,1,...,wh,T)∈Rd×T,其中wh,t是在h层次中任务t的参数。该论文将最终的正则化的目标函数(论文称之为MeTaG方法)写为
这里λh是正的正则化参数,正则项用l2范数度量了Wh不同列向量之间的两两差异,促使Wh中的每对列向量wh,i和wh,j相等(即强制融合每对任务的模型参数),这样在第h层的第i个和第j个任务就同属一个任务簇。λh控制了第h层的任务任务聚类的强度,λh越大则意味着在第h层的任务簇更少。当λh→∞,Wh所有列将趋于相同,即只有一个任务簇。在求解问题(13)之后,通过比较Wh矩阵的列就可以识别任务簇的结构并确定任务簇的数量。
Kumar和Daume(2012)[26]以及Barizilai和Crammer(2015)[27]都提出了W=LS(W∈Rd×T,L∈Rd×C,S∈RC×T)的分解形式,其中L的列lc对应任务簇c的隐(latent)参数,S的列st对应一组线性组合系数(wt=Lst,相当于st对L中各列进行线性组合,以得到wt)。这两种方法的目标函数可以统一为
其中L由Frobenius范数来进行正则化,但在这两种方法中,S由不同的h(⋅)函数惩罚。我们想让S更稀疏,即让一个任务属于尽量少的任务簇(在本模型每个任务属于多个任务簇是合法的),因此Kumar和Daume(2012)定义了h(S)=||S||1(Lasso)来完成稀疏化,而Barzilai和Crammer(2015)的定义方法更为严格
该正则函数试图为每个任务只指定单一的任务簇,这里C代表集群的数量,S是一个C×T的0-1矩阵,st代表S的第t列。
综上所述,聚类⽅法的思想可以总结为:将不同任务分为不同的独⽴簇,每个簇存在于⼀个低维空间,每个簇的任务共⽤同⼀个模型。我们可以通过交替迭代学习不同簇的分配权重和每个簇的模型权重。就这种方法而言,任务之间有强的关联性,并行化难度非常大,后面我们在提到如何将基于聚类的方法并行化时再细讲。
我们对基于正则化的多任务学习方法介绍就到此为止,后面我们会介绍如何采用不同的手段对这类方法进行分布式并行。
参考文献
-
[1] Long M, Cao Z, Wang J, et al. Learning multiple tasks with multilinear relationship networks[J]. arXiv preprint arXiv:1506.02117, 2015.
-
[2] Misra I, Shrivastava A, Gupta A, et al. Cross-stitch networks for multi-task learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 3994-4003.
-
[3] Hashimoto K, Xiong C, Tsuruoka Y, et al. A joint many-task model: Growing a neural network for multiple nlp tasks[J]. arXiv preprint arXiv:1611.01587, 2016.
-
[4] Kendall A, Gal Y, Cipolla R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7482-7491.
-
[5] Evgeniou T, Pontil M. Regularized multi--task learning[C]//Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. 2004: 109-117.
-
[6] Zhou J, Chen J, Ye J. Malsar: Multi-task learning via structural regularization[J]. Arizona State University, 2011, 21.
-
[7] Zhou J, Chen J, Ye J. Clustered multi-task learning via alternating structure optimization[J]. Advances in neural information processing systems, 2011, 2011: 702.
-
[8] Ji S, Ye J. An accelerated gradient method for trace norm minimization[C]//Proceedings of the 26th annual international conference on machine learning. 2009: 457-464.
-
[9] Caruana R. Multitask learning[J]. Machine learning, 1997, 28(1): 41-75
-
[10] Evgeniou A, Pontil M. Multi-task feature learning[J]. Advances in neural information processing systems, 2007, 19: 41.
-
[11] Argyriou A, Evgeniou T, Pontil M. Convex multi-task feature learning[J]. Machine learning, 2008, 73(3): 243-272.
-
[12] Maurer A, Pontil M, Romera-Paredes B. Sparse coding for multitask and transfer learning[C]//International conference on machine learning. PMLR, 2013: 343-351.
-
[13] Obozinski G, Taskar B, Jordan M. Multi-task feature selection[J]. Statistics Department, UC Berkeley, Tech. Rep, 2006, 2(2.2): 2.
-
[14] Obozinski G, Taskar B, Jordan M I. Joint covariate selection and joint subspace selection for multiple classification problems[J]. Statistics and Computing, 2010, 20(2): 231-252.
-
[15] Liu H, Palatucci M, Zhang J. Blockwise coordinate descent procedures for the multi-task lasso, with applications to neural semantic basis discovery[C]//Proceedings of the 26th Annual International Conference on Machine Learning. 2009: 649-656.
-
[16] Gong P, Ye J, Zhang C. Multi-stage multi-task feature learning[J]. arXiv preprint arXiv:1210.5806, 2012.
-
[17] Ando R K, Zhang T, Bartlett P. A framework for learning predictive structures from multiple tasks and unlabeled data[J]. Journal of Machine Learning Research, 2005, 6(11).
-
[18] Chen J, Tang L, Liu J, et al. A convex formulation for learning shared structures from multiple tasks[C]//Proceedings of the 26th Annual International Conference on Machine Learning. 2009: 137-144.
-
[19] Fazel M, Hindi H, Boyd S P. A rank minimization heuristic with application to minimum order system approximation[C]//Proceedings of the 2001 American Control Conference.(Cat. No. 01CH37148). IEEE, 2001, 6: 4734-4739.
-
[20] Thrun S, O'Sullivan J. Discovering structure in multiple learning tasks: The TC algorithm[C]//ICML. 1996, 96: 489-497.
-
[21] Bakker B J, Heskes T M. Task clustering and gating for bayesian multitask learning[J]. 2003.
-
[22] Xue Y, Liao X, Carin L, et al. Multi-task learning for classification with dirichlet process priors[J]. Journal of Machine Learning Research, 2007, 8(1).
-
[23] Zhou J, Chen J, Ye J. Clustered multi-task learning via alternating structure optimization[J]. Advances in neural information processing systems, 2011, 2011: 702.
-
[24] Kang Z, Grauman K, Sha F. Learning with whom to share in multi-task feature learning[C]//ICML. 2011.
-
[25] Han L, Zhang Y. Learning multi-level task groups in multi-task learning[C]//Twenty-Ninth AAAI Conference on Artificial Intelligence. 2015.
-
[26] Kumar A, Daume III H. Learning task grouping and overlap in multi-task learning[J]. arXiv preprint arXiv:1206.6417, 2012.
-
[27] Barzilai A, Crammer K. Convex multi-task learning by clustering[C]//Artificial Intelligence and Statistics. PMLR, 2015: 65-73.
-
[28] 杨强等. 迁移学习[M].机械工业出版社, 2020.


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个奇形怪状的面试题:Bean中的CHM要不要加volatile?
· [.NET]调用本地 Deepseek 模型
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· spring官宣接入deepseek,真的太香了~