
数据结构与算法(十)——堆
一、概述
1、介绍
堆:是具有以下性质的完全二叉树,建堆的时间o(n)。
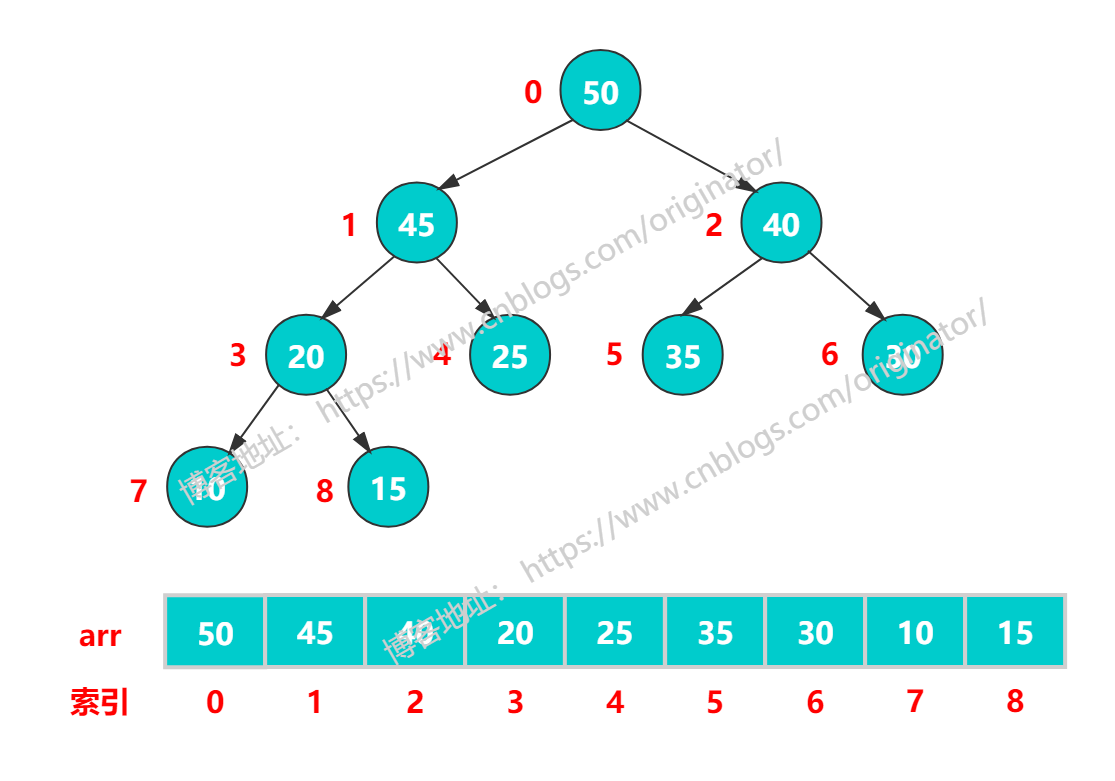
大顶堆:根结点 >= 左右孩子结点,左右孩子不要求。
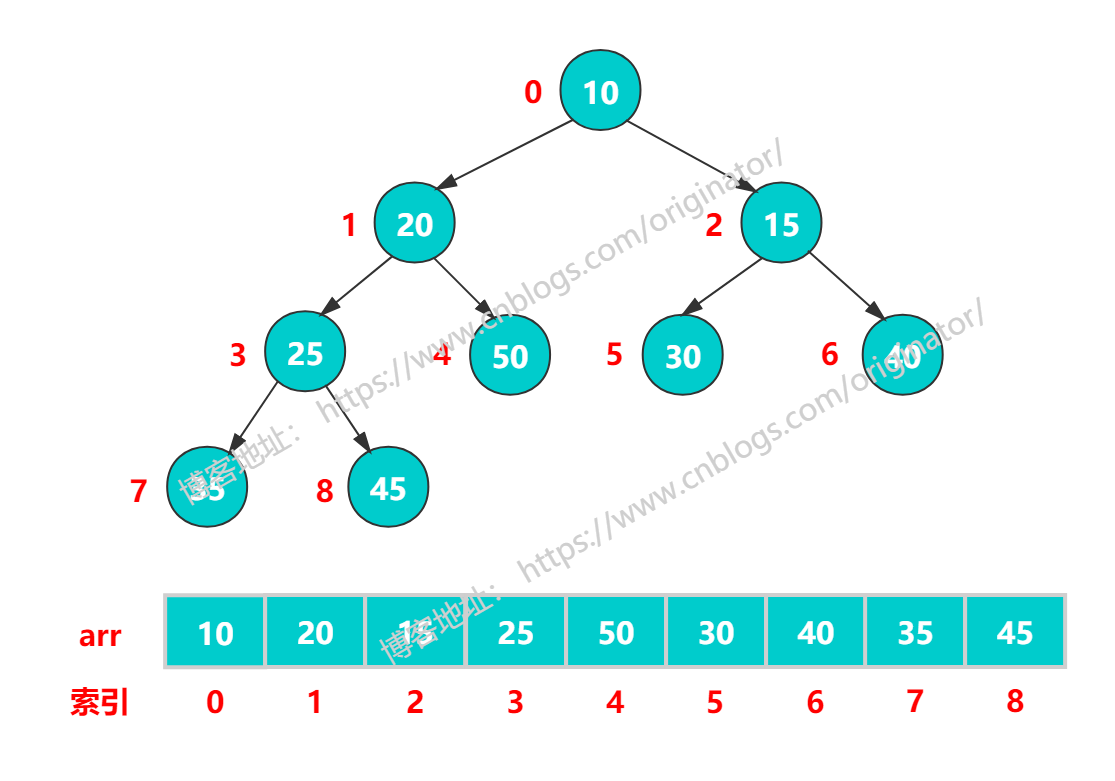
小顶堆:根结点 <= 左右孩子结点,左右孩子不要求。
大顶堆:
小顶堆:
性质:由于堆是完全二叉树,对任意结点 i 左孩子是 2i + 1,右孩子是 2i + 2,则:
①大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
②小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
③最后一个非叶子结点:arr.length / 2 - 1
2、建堆过程
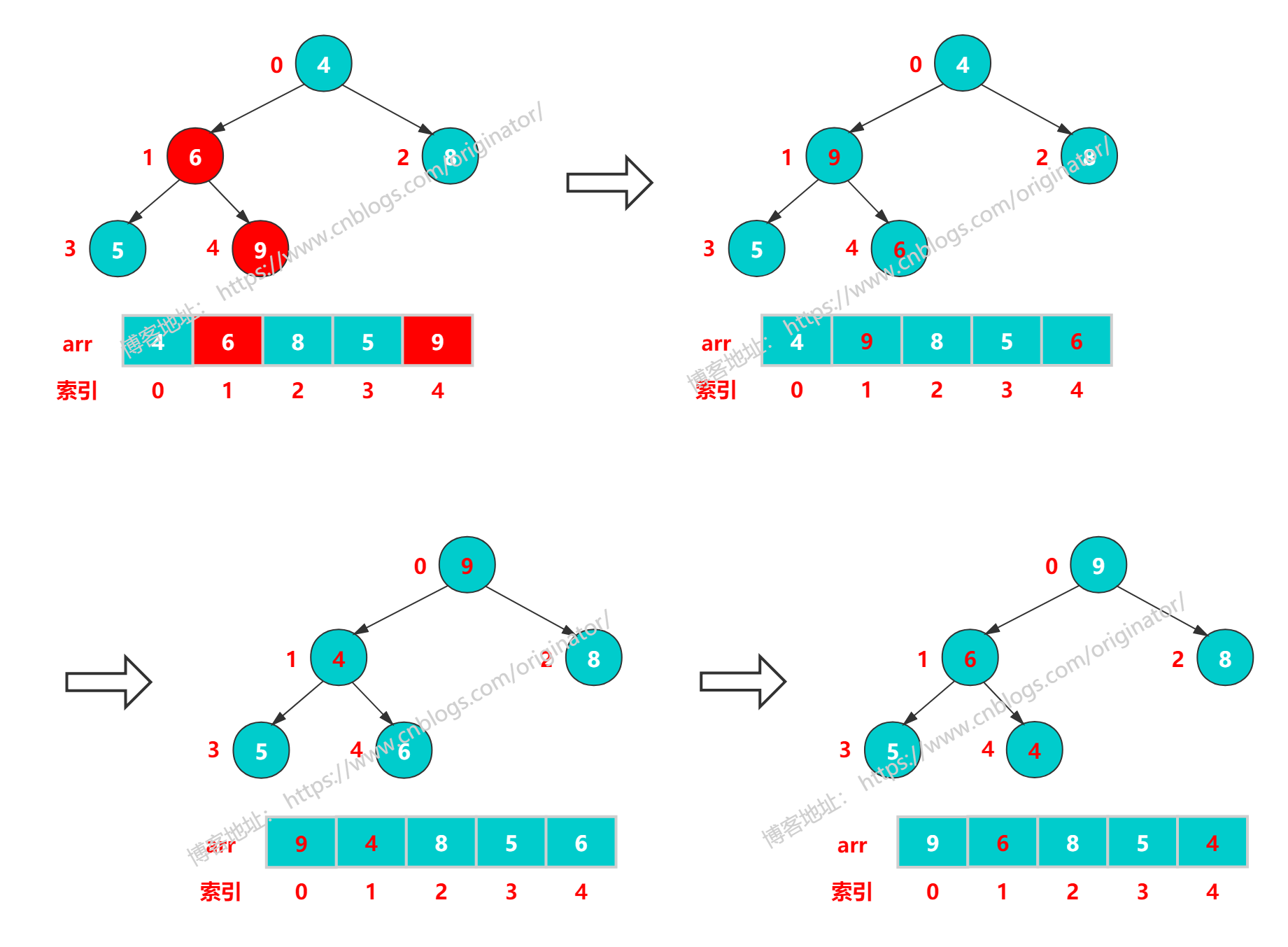
用数组 {4, 6, 8, 5, 9} 构建成一个大顶堆,从最后一个非叶子结点(6)开始倒着调整。如图:
二、堆排序
1、介绍
堆排序是利用堆这种数据结构而设计的一种排序算法,是一种不稳定的选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn)。
2、思想
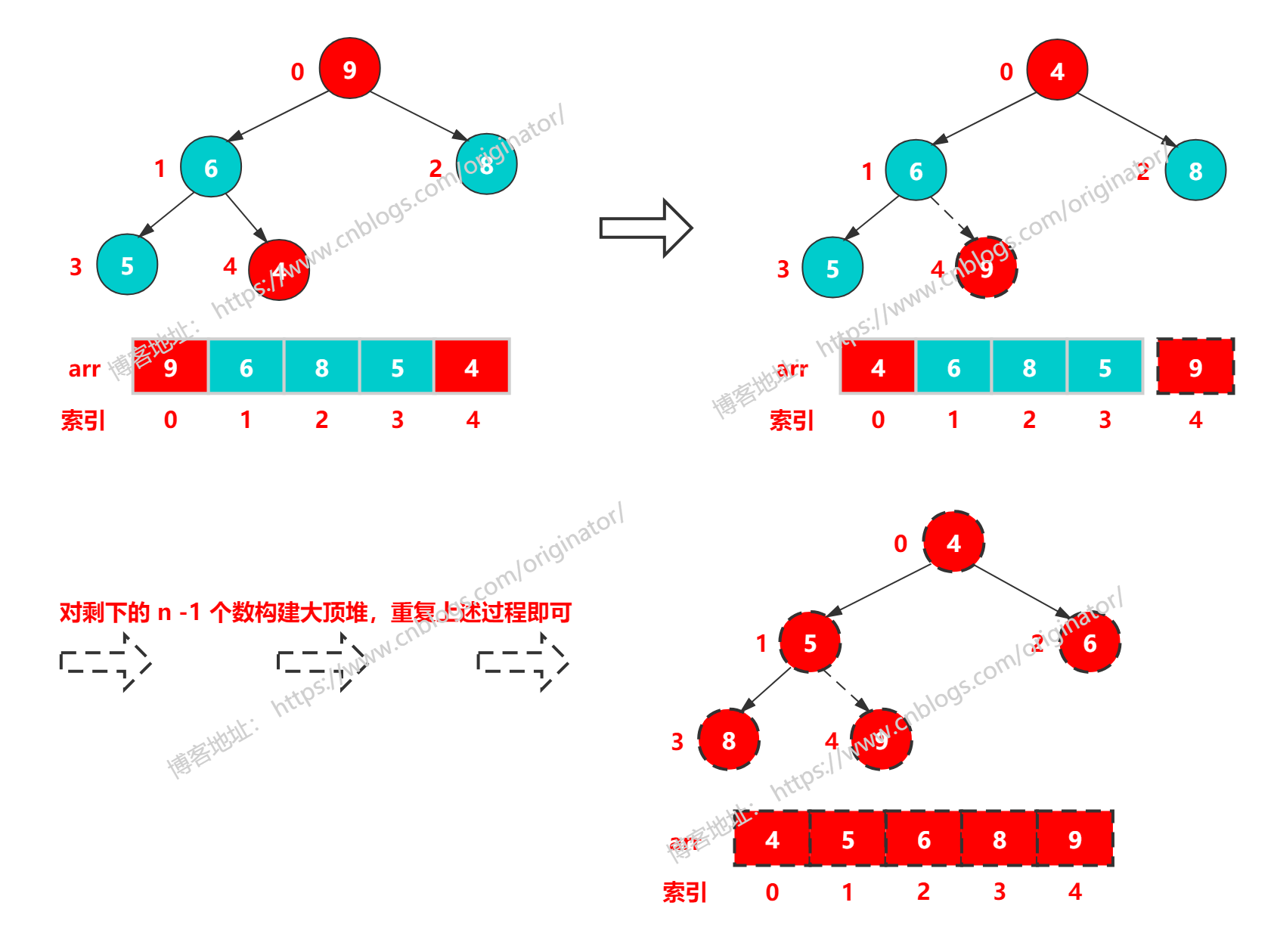
(1)将待排序数组构建成一个大顶堆,自然有,arr[0] = max{arr}。
(2)将堆顶元素(最大)与数组的末尾元素交换,此时末尾元素就是最大值。
(3)将剩余的 n - 1 个序列重新调整成一个大顶堆,这样就得到 n 个元素中的次大值。
(4)如此反复,便能得到一个有序序列了。
3、过程
4、代码
1 // 堆排序 2 public static void heapSort(int[] arr) { 3 // 1.构建大顶堆 4 for (int i = arr.length / 2 - 1; i >= 0; i--) { 5 adjustHeap(arr, i, arr.length); 6 } 7 8 // 2.交换.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端. 9 for (int i = arr.length - 1; i > 0; i--) { 10 swap(arr, 0, i); 11 adjustHeap(arr, 0, i); 12 } 13 } 14 15 /** 16 * 调整堆,以 i 对应的非叶子结点的树调整为大(小)顶堆 17 * 18 * @param arr 待调整的数组 19 * @param i 待调整的非叶子结点(数组的下标) 20 * @param length 剩下的 length 个元素继续调整,每次length会逐渐减少 21 */ 22 private static void adjustHeap(int[] arr, int i, int length) { 23 // k 是 i 的左孩子.存在 24 for (int k = 2 * i + 1; k < length; k = 2 * k + 1) { 25 // k+1 是 i 的右孩子.存在 26 if (k + 1 < length && arr[k] < arr[k + 1]) { 27 k++; 28 } 29 30 if (arr[i] >= arr[k]) { 31 break; 32 } 33 34 swap(arr, i, k); 35 36 // 继续调整因交换引起的孩子结点不满足堆的情况 37 i = k; 38 } 39 } 40 41 private static void swap(int[] arr, int i, int j) { 42 int temp = arr[i]; 43 arr[i] = arr[j]; 44 arr[j] = temp; 45 }
5、小结
堆排序升序排序:大顶堆
堆排序降序排序:小顶堆
堆排序的时间复杂度是o(nlogn)
堆排序的空间复杂度是o(1)
构建堆的时间复杂度是o(n)
堆排序是一种不稳定的排序算法
有一组数据(15,9,7,8,20,-1,7,4),用堆排序的筛选方式建立的初始堆为(-1,4,7,8,20,15,7,9)。
将数组(7,6,3,5,4,1,2)按照堆排序的方式升序排序,则第一轮排序结束后,数组顺序是(6,5,3,2,4,1,7)。
对于根元素为最小值的二叉堆。
插入结点的复杂度是o(logn)
删除最小元素的复杂度是o(logn)(删除之后需要调整堆)
查询最小元素的复杂度是o(1)
有 n 个元素的序列,若使用筛选法建堆,则从位置为n/2取下整的元素开始建堆。
哈弗曼树带权路径长度最短的树,路径上权值较大的结点离根较近。
当从一个最小堆中删除一个元素时,需要把堆尾元素填补到堆顶位置,然后再按条件把它逐层向下调整到合适位置。
三、堆的应用
1、PriorityQueue优先队列
介绍:队列是遵循先进先出模式的,但有时需要在队列中基于优先级处理对象。就需要对象具有可比性;PriorityQueue是非线程安全的,所以Java提供了PriorityBlockingQueue(实现BlockingQueue接口)用于Java多线程环境。
代码示例:应用
1 // 优先队列 2 public class PriorityQueueDemo { 3 public static void main(String[] args) { 4 Queue<Stu> priorityQueue = new PriorityQueue<>(); 5 6 // 随机添加 7 个对象到队列中 7 Random rand = new Random(); 8 for (int i = 0; i < 7; i++) { 9 int id = rand.nextInt(100); 10 priorityQueue.offer(new Stu(id, "Stu:" + id)); 11 } 12 13 // 出队列 14 while (!priorityQueue.isEmpty()) { 15 final Stu stu = priorityQueue.poll(); 16 System.out.println(stu); 17 } 18 } 19 } 20 // 使对象具有可比性 21 class Stu implements Comparable<Stu> { 22 private int id; 23 private String name; 24 25 public Stu(int id, String name) { 26 this.id = id; 27 this.name = name; 28 } 29 30 public int getId() { 31 return id; 32 } 33 34 public void setId(int id) { 35 this.id = id; 36 } 37 38 public String getName() { 39 return name; 40 } 41 42 public void setName(String name) { 43 this.name = name; 44 } 45 46 @Override 47 public int compareTo(Stu o) { 48 return this.id - o.id; 49 } 50 51 @Override 52 public String toString() { 53 return "Stu{" + 54 "id=" + id + 55 ", name='" + name + '\'' + 56 '}'; 57 } 58 }
底层实现原理:Java中 PriorityQueue 通过小顶堆实现。源码参看JDK源码。
2、top K
什么是 top K 问题?简单来说就是在一堆数据里面找到前 K 大(当然也可以是前 K 小)的数。
最直接的想法:先通过快排等算法将 n 个数排序,再取前 k 个。这种方式在数据量不大的时候可行,但固然不是最优的方法。比如在 1 亿个数中找前 10 大的数,将 1 亿个数都排序,未免有点浪费。
缺点:在海量数据下,很可能没办法一次性将数据全部加载入内存。
分布式思想处理海量数据:将数据分散在多台机器中,然后每台机器并行计算各自的 top K 数据,最后汇总,再计算得到最终的 top K 数据。
一台机器处理海量数据:堆排序。
思想:维护一个大小为 k 的小顶堆,从 i = k+1 开始遍历数组arr,如果 arr[i] > 堆顶元素,则用 arr[i] 替换堆顶元素,并重新调整堆使之为小顶堆。遍历完全部数据,堆里面就是top K。
直接使用优先队列 PriorityQueue 来实现一个小顶堆,求 top K 问题:
1 // top K 2 public List<Integer> solutionByHeap(int[] input, int k) { 3 List<Integer> list = new ArrayList<>(); 4 if (k > input.length || k == 0) { 5 return list; 6 } 7 8 Queue<Integer> queue = new PriorityQueue<>(); 9 for (int num : input) { 10 if (queue.size() < k) { 11 queue.offer(num); 12 } else if (queue.peek() != null && queue.peek() < num) { 13 // 堆顶元素出列 14 queue.poll(); 15 queue.offer(num); 16 } 17 } 18 19 while (!queue.isEmpty()) { 20 list.add(queue.poll()); 21 } 22 return list; 23 }
作者:Craftsman-L
本博客所有文章仅用于学习、研究和交流目的,版权归作者所有,欢迎非商业性质转载。
如果本篇博客给您带来帮助,请作者喝杯咖啡吧!点击下面打赏,您的支持是我最大的动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号