诗歌rails之rails tips
MRP启动之后,上次介绍了Phase I的完成情况,之后很久都没什么时间去折腾,最多是零零散散的更新几行代码——事实上对于大部分页面来说,也就几行代码就行了——直到开始实现查询部分的功能,这个有点麻烦,这次趁着假期才算是完成了这个部分,于是就有了这个最初的发布版本。这一篇就针对这个过程中的一些体会稍作回顾,主要涵盖的是Controller和View的部分。
我是完全意义上的Rails新手,所以这里不会有什么高深的东西,只是希望用一个例子来说进入这样一个新的体系的路径,以及可以得到的收获。
Warning!!! 非常非常的长,没有耐心的现在可以关闭这个页面了。
Step 0 一般性原则
一般来说对于新的技术学习,有一定的规律,虽然可能因人而异,但是下面这些原则是值得考虑的:
- 寻找一个可完整实现的、具有实际价值,但是又不要过于薄弱(换句话说,使用熟悉的技术可以轻易完成)的案例作为目标,注意控制时间,让它有始有终比什么都重要。
- 尽最大的可能寻找最一般的实现方案,了解和使用最大众化的技术和机制,学习最原汁原味的风格。
- 只要可能,就不要自己去实现那些一看就知道有人做过的功能——比如分页,基本上都可以找到高质量、封装的很好的可重用模块。
- 虽然这个案例有明确的目标和主题,但是在时间许可范围内,不要害怕把其他有趣的东西放进去。
毫无疑问,这次我就是这么干的,MRP是一个非常适合的目标,因为不需要写数据,所以非常简单,但是它对于Rails来说并不平凡,且实际价值明确,目标也很清晰适中,不会导致拖得很久完不成。同时,无论是Rails还是MRP都有很多可以延伸的点,例如AJAX,Rails内置了Prototype/script.aculo.us,但是我喜欢jQuery ,借助jRails的帮助,我把它们换成了jQuery——所有这些都很有趣!
Step 1 普通表格型数据展现
Controller从Model取得数据,包装成View所需要的形式,然后在View的模版中展现,这是最一般的流程,MRP需要展示的数 据:Category(分类) => Forum(论坛) => Post(主题) => Message(留言),通过4个不同的页面进行展现,同时借助超链接来逐级的钻取下去,这是最简单的部分。先来看看Controller的部分,下面是 app/controllers/categories_controller.rb 的片段:
1 | class CategoriesController < ApplicationController |
先来看看Rails的八股。line 2-3的注释说明这个方法可以用来响应的HTTP请求,用来支持其他文件类型(如XML)的REST请求;line 7-10是生成对应不同格式文档的代码,对于HTML没有特定处理,这按照Rails的约定就会去 app/views/categories/ 目录下找 index.html.erb 这个模板并渲染它作为HTML输出;XML的输出调用Rails的缺省 render 方法进行,输出的XML可以在这里看到,如果你用Firefox打开这个链接(这是我现在知道的,除了插件之外Firefox对Safari的最大优势,Safari要展示XML必须使用隐藏的Develop菜单下的console),可以看到非常漂亮的XML输出(Firefox | Safari),可用于各种非浏览器的客户端。这里你很容易加入你自己的格式,例如:
1 | respond_to do |format| |
format 后面跟的类型必须是标准MIME描述名,后面代码块的输出将作为请求这个类型资源 categories.txt 的响应。
整个关键在于line 5,调用Model类的 find 方法来生成一个对象数组,这是Rails框架中连接Model和Controller的环节。ActiveRecord的 find 方法是一个强大灵活的机制,并通过Ruby优雅的语法展现出来——基本是不解自明的。这里是比较简单的一种形式,提供一个简单的条件,设定排序方式。顺便说一句,开始干活之前以及干活的过程中,应该不断的积累好用的工具箱,这里我推荐RailsBrain作为离线的API手册。
然后来看看View的部分,下面是对应模板 categories/index.html.erb 的片段:
1 | <tbody> |
ERB是Ruby标准的HTML template,使用常见的 <% %> 标记体系,所以这个很好懂。值得关注的是line 4,使Rails和之前其他的页面标记语言不大一样的,是大量被称为helper的方法(属于ActiveView包),这些方法使页面元素的管理更加简单,代码更加干净。这里两个需要提到的方法是:
link_to: 生成一个HTML超链接,参数是链接文字和URL;Rails提供大量的helper方法来生成各种HTML标记,包括页面标题、表单、CSS和JS引用等等。category_forums_path: 这个不是预定义的helper方法,而是Rails框架自动生成的方法,用来通过对象产生REST风格的URL,具体到这个方法,它会生成 “指定category下面所有forums列表” 的URL,具体说明在下面关于RESTful的部分。
Step 2 了解框架的基本结构和机制
Rails的基本结构主要是包括目录结构、命名约定、运行环境和初始化脚本、工具集等内容(下面我们会谈到这些),那么什么称得上是Rails的基 本机制呢?我觉得是RESTful route,这个东西不仅仅是URL和代码之间的映射和连接方案,更是对应用结构的一种指导。REST的概念简单而深邃,这里就不展开了。Rails中使 用 config/routes.rb 文件来向Rails引擎注册对象,经过不断的优化,现在这个文件可以非常简单:
1 | map.search 'search', :controller => 'search', :action => 'index' |
line 5的写法和line 6-8是等价的,这种 :has_many 的语法是Rails 2.0引入的,不仅更加简洁,也和ActiveRecord的风格更加一致,这定义了一个 1:n 的”nested resource”,即嵌套的资源,这种关系在关系模型中表现为主外键,在对象模型中表现为包含关系(include),在REST中则通过这行代码表现为 /categories/13/forums 这样的URL,这表示forums资源属于某个特定的category资源,非常直观有效的R(elational)-O(bject)-R(esource)映射,不是么?
更进一步,Rails不需要你自己写这样的URL,Rails会自动生成一组helper方法来从对象出发按照约定规则生成正确的URL,这就是在前一节我们看到的类似 category_forums_path 这样的方法,新手经常搞不清这些方法里单数、复数、排列顺序等,不过Rails早就为此准备好了绝妙的工具,进入项目根目录,运行:
rake routes
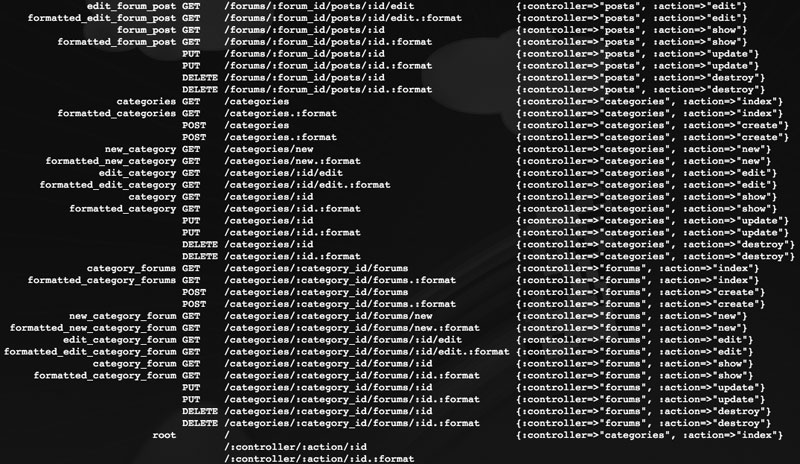
系统会扫描整个项目,生成所有routes并列出相关的helper方法,下面列出其中的一行(截图):
category_forums GET /categories/:category_id/forums {:controller=>"forums", :action=>"index"}
第一项是helper方法前缀,后面加上 _path 的方法会输出这个资源的相对于Web根的URL,后面加上 _url 的方法则会输出完整的URL;第二项是HTTP方法,只有GET才有对应的helper方法;第三项是URL模板;最后一项是这个资源的handler,包括对应的Controller和行为方法。
前面的 routes.rb 中line 1&10则是另外一种方式,相对来说比较不RESTful的方式,这个和一般Web框架用来把URL和handler绑定的那些定义文件差不多,其效果在 rake routes 的输出中也可以看到,这个强大的工具基本是排错的利器,如果发现和route有关的问题第一时间去看这个基本就搞定了。
回过头来说说Rails框架的基本结构,关于Rails框架内部的机制,我强烈推荐Obie Fernandez的’The Rails Way‘,和那本著名的’Agile Web Development with Rails‘相对看,非常互补——这里只针对我的一些体会说几点零散的经验。
Rails的目录结构基本是固定的,很少有人想过去改变它——这是Rails的”convention over configuration”精神的体现,这种相对固定带来一系列方便之处,例如引用CSS样式表的时候,只需要:
1 | <%= stylesheet_link_tag "pagination" %> |
后缀名自动补齐,前面的路径也是缺省的 /stylesheet/。
在MRP的摸索过程中,多次遇到和版本有关的问题。首先是2.1和2.0的兼容性问题。我自己的电脑上永远有最新的发布版本,所以早就是 2.1.0(前几天到了2.1.1),而很长一段时间DreamHost的服务器上都是2.0.2,这两个版本是不兼容的,当我在本地开发和测试完毕,把 最新的代码commit到SVN服务器上,然后在Web服务器上checkout或者update之后,运行会出错——而DreamHost配置的 Passenger(mod_rails)本来的目标就是drop and run,这形成了绝妙的讽刺——难道我要在本地装个2.0来开发?或者使用 rake rails:freeze:gems 来把本地环境部署到服务器上?这都是我不喜欢的事情,还好经过研究,这个问题还是比较容易解决的,只要修改两个文件,并且这两个文件都是平时不需要修改的:
config/environment.rb将RAILS_GEM_VERSION改为目标系统的版本(”2.0.2″);注释掉关于time_zone的那一行。config/initializers/new_rails_defaults.rb把所有的四行内容都注释掉。
Done. DreamHost不久前终于升级了它的缺省Rails配置,现在是2.1.0了,所以这些hacking也就没意义了。
还有一个问题也和DreamHost的共享主机机制有关,也就是安装自己的gems比较麻烦,所以目前我采用的都是把需要的gems放到 vender/plugins 目录下的办法,这个只需要使用下面的命令就可以了:
cd vendor/plugin
gem unpack <gem names>
Rails 2.1对于plugins和gems的隔离以及管理更简单了,有兴趣的可以看看Ryan Daigle著名的What’s New in Edge Rails系列中的这篇介绍。
MRP本身用到的plugins和gems很少(关键的就一个,下面会提到的mislav-will_paginate,还有一个jrails),所以维护还是很简单的。
另外我也对Ruby 1.9做了一些测试,事实证明,只要作一行修改(即去掉 config/boot.rb 中的 load_rubygems 调用,这在Ruby 1.9下是多余的 ),现在的Rails就可以在Ruby 1.9下运行,而问题是其他支持性gems上——其中最核心的是MySQL等数据库驱动,我的测试表明:
- mysql 2.7: 经典MySQL驱动,编译本地接口时出错,无法安装。
- mysqlplus 0.1.0: 这是eSpace最近掀起的NeverBlock狂热的一部分,一个使用纤程(fiber)来实现客户端无阻塞通讯的MySQL驱动,这个驱动可以正常的安装,甚至也可以“几乎”正常的运行,但是会导致某些地方显示中文出现乱码,主要是在行尾,估计是双字节的计数问题。
- mislav-will_paginate: 可以安装,但是运行出错,其他一些gems也有这类问题(例如我喜爱的utility_belt)。
我相信通过某种hacking,这些问题都是可以解决的,但是我没时间。
Step 3 分页显示
在Rails 1.2中有一个内置的分页解决方案,但是因为不够灵活以及效率低下而饱受诟病,一些第三方的分页方案于是纷纷应运而生,其中最受追捧、乃至几乎成为“非官方的官方实现”的,是mislav的will_paginate,早先经RoR社区著名的err.the_blog的介绍推广,随即因其无与伦比的简单和高效而风行。Rails 2.0将早先的内置分页从核心移除,will_paginate于是成为几乎必备的plugin。will_paginate推荐的使用方式是安装为gem:
sudo gem install mislav-will_paginate
但是在DreamHost虚拟主机上这无法实现,于是我直接把插件代码下到 vender/plugins 下面:
cd vender/plugins
git clone git://github.com/mislav/will_paginate.git
——以后只要在 vender/plugins/will_paginate 目录下运行 git pull 即可。然后在 config/environment.rb 最后加上下面这行就行了:
1 | require 'will_paginate' |
MRP中在主题(posts)列表采用了will_paginate来实现分页——和不分页的版本相比,差别仅仅是几行代码。首先来看 posts_controller.rb 的代码片段:
1 | class PostsController < ApplicationController |
line 5用URL参数 forum_id 作为id查找forums表中对应的行生成全局对象 @forum(将被模板使用的对象实例都应设定为全局的);line 6用 @forum 来查找对应的分类并保存在全局对象 @category 中;line 7首先用 @forum.posts 找出这个论坛下所有的主题,然后调用will_paginate插件注入的 paginate 方法,其中 posts_per_page 是全局方法,返回我设定的缺省每页条数值。对比一下不分页的版本:
1 | ... |
嗯,就是那么回事!再来看模板部分:
1 | ... |
line 3显示分页信息;line 4-5显示分页导航条,参数 inner_window 和 outer_window 控制显示当前页和首/末页临近的多少个链接。你可以在这里看到实际的效果(截图)。
will_pagination采用URL参数 ?page= 来传递分页信息;事实上URL参数是它会使用的唯一的参数传递方式,如果要分页的结果集是通过条件查询得到的,这些条件也必须通过URL参数来传递,这就决定了对应form的提交方式必须是 GET 而不是 POST,否则你点击分页链接的时候所有form条件都会丢失——这算一个个小小的catch,不过这是没办法的事情。
Step 4 查询
解决了分页之后,基本上所有MRP对象的REST式访问逻辑很快就搞定了,加上了导航条等必备功能之后,就只剩下查询的功能需要实现了。这个功能的核心是表单的处理,另外因为我希望把查询表单变成主页上一个可动态加载的模块,所以这里也就“顺便”成了AJAX的试验场。
一开始花了比较多的时间来考虑查询的逻辑,经过对功能和实现复杂性的权衡,最后的决定如下:
- 查询的对象是主题(posts),也就是说一个post中任何一个message符合条件,那么这个post作为符合条件的结果输出,重复的结果记录应该合并。
- 可以查询的属性包括:标题、作者、所属论坛、发表时间和内容,其中最后一项属于全文检索,暂不实现;标题的查询应该支持某种形式的自定义运算,例如AND、OR之类的,作者和论坛属于限定性条件,指定具体一个值,而发表时间是个起止范围。
- 为了使结果有意义,标题和作者条件至少必须输入一个,其他属于可选的。
Rails提供了一组helper方法来生成输入表单以及其内的各类field,看看下面的代码片段:
1 | <% form_for :post, :url => { :action => "result" }, :html => { :method => "get", :class => "cmxform" } do |f| %> |
line 1生成 form 标签,并指明提交的目标动作是当前Controller的 result 方法,:html 参数用来直接添加HTML标签属性,例如指明使用 GET 方法,而不是 POST(参见上面关于分页的说明)。第一个参数 :post 只有当这个form是和一个Model类关联的时候才有用,这里实际上是不发生效果的。
line 2&3生成两个文本输入框,参数指定了它们的名字和缺省值如 params[:subject];line 5生成提交按钮,参数是按钮文本。上面的代码会生成这样的HTML:
1 | <form action="/search/result" class="cmxform" method="get"> |
日期的输入呢?这个:
1 | <%= select_date(Time.now, :prefix => "start_date") %> |
Rails会生成年、月、日的下拉列表框,很遗憾,到目前为止,这还是跨平台兼容性最好的方案,这里没有 :name 参数,只有一个 :prefix 参数,而我们在后台要用 params[:start_date][:year] 这样的语法来访问输入值。我在这里用了个小trick,我把起始日期设为当日,而结束时间设为当日的后一天,这样如果后台收到的结束日期比当日晚就无视这个条件。
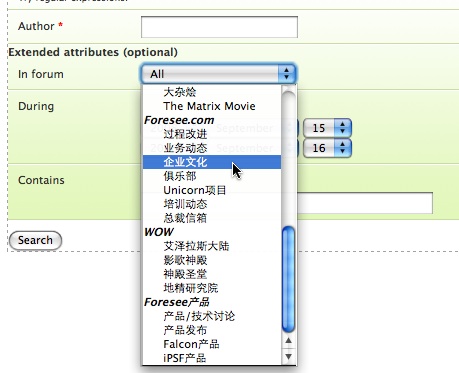
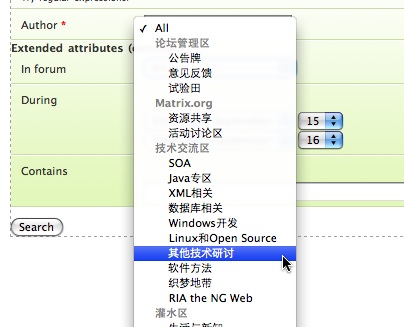
如此这般,所以这一端的事情很简单——我们来试试复杂一点的,那个选择论坛的列表,为了加点难度,让我们想办法用categories来做group——其实这也没啥,因为对于Rails来说,都是几行代码:
1 | <select name="forum_id" id="forum_id"> |
出来的效果可以在这里看到(截图:Firefox | Safari),哈!那几个参数稍微需要解释下:第1个是分组用的对象集合(数组),这里是所有的分类(全局变量 @categories 需要在Controller中准备好);第2个是这个数组中的每个对象用来取得子元素集合(这里是论坛数组)的方法名—— category.forums 可以取出一个category下的所有forums,在Part 1我们看到了,不是么?第3个是取分组名的方法名;第4和第5个是子元素取id和名字的方法名——看出来了吧,其实这个魔术很简单,动态语言的power嘛。
前台就这么多了,后台的处理有几个问题要解决。首先是不同类型的输入数据的处理,然后是怎么处理条件——因为不是没个条件都一定在那儿,需要动态的判断和组合有输入的那些条件,而忽略掉其他的,很幸运,我找到了相当漂亮的方案。下面就是这里展示的最长的代码:
1 | def result |
首先初始化一个数组,如果某个条件是有效的那么就把对应的SQL判断语句放进这个数组,Rails的 find 方法接受的查询条件中可以使用参数,既可以用用匿名参数(用 ? 来占位),也可以用命名参数,用 :subject 这样的symbol来标记,然后把参数值放到一个哈希表里一起送进 find 方法就可以了。这里我用了另外一个trick,因为大部分参数其实已经在一个哈希表了,那就是保存HTML参数的 params,所以我们的参数名就跟着 params 里面的键值,处理后的参数也写入 params ,这样可以省去另外构造一个查询参数值哈希表的代码和开销。
每组条件都测试完毕之后,我们用Ruby数组那漂亮的 join 方法,用 ' and ' 把
条件串起来,在line 30-31送进 Message 类的 find 方法的 :conditions 参数里,然后我们用 collect 方法来把结果集转换成一个整数数组,里面是查出来的所有message的post_id,好用在下一个查询里,那个查询把这些post_id对应的post对象找出来,排序,然后分页——
另外几个小的说明:
- 最后我决定不去费精力处理标题查询的组合,而是直接使用正则表达式,这使得这个部分变成MySQL only的,但是我觉得这个值得。
- 使用一个简单的查询从输入的用户名取得用户id。
- 从
params取出的forum_id是字符串,所以需要转换成整数才好直接应用在SQL查询参数表中。 make_db_time是定义在/controllers/application.rb中的全局工具方法,使用Progress I里提到的算法来生成数据库里需要的时间串。
That’s all.
Step X1 用户体验
这个问题和下面的问题都属于贯穿始终的共性问题,所以我用’X'来标记。
对于Web应用,尤其是Rails这么具有 N.0 (N>=2) 时代气息的技术,用户体验是很重要的的一环。对于我来说,至少应该努力做到:
- 尽量使用标准化的技术产生符合W3C标准的HTML。
- 使用CSS来隔离样式和内容,也使得改变样式变得简单,MRP的表格、分页导航条、输入表单都使用标准的CSS来定义显示样式,从而是高度可定制的。
- 必要时可以使用AJAX技术来增加可用性,作为尝试,可以试试在查询表单空着所有格子直接提交,这里有使用jQuery编写的校研和反馈代码;查 询表单在站点主页上还可以动态的加载,点击Search链接之后通过AJAX技术将查询页面读取并注入到主页分类列表的下面。BTW,jQuery的文档写的很好,很容易看明白,有空可以多玩玩。
具体内容因为和主旨关系不大,就不多说了,有兴趣的可以去看源码。
Step X2 DRY
DRY=Don’t Repeat Yourself,这是Rails的重要哲学,其实按照我的理解,这个不过是对于一致性和复用性的一种感性的强调(不仅仅针对代码本身,对于开发的big picture都适用)。我的骨子里是非常’DRY’的,所以我很喜欢Rails!
Rails中有很多内建的机制来帮助你变得更DRY,例如全局和局部helper类、layout等,但是其中最重要的,莫过于partial了。 partial是可重用的页面块,一般用下划线开头的文件名就是partial,凡是多次出现的长的差不多的页面结构,应该都可以考虑将之转化为 partial,然后在需要的地方用Rails标准的 render 方法来引用:
1 | <%= render :partial => "shared/post_list", |
可以看到,partial是可以接受参数的,:locals 参数给partial中的局部变量赋值,这给与了partial非常好的封装性和灵活性。MRP的主题列表就是一个可重用的partial,当它用在某个 forum的主题列表时,它有4栏,而作为查询结果显示时,则增加了”In Forum”一栏,这就是通过参数实现的。
可重用的页面模块并不新鲜,但是Rails的partial设计的精巧使它真正成为一个好用的、能够经常使用的工具。
 莫愁前路无知己,天下无人不识君。
莫愁前路无知己,天下无人不识君。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}