
面向对象
1.面向对象前戏之人狗大战
"""推导步骤1:代码定义出人和狗"""
person1 = {
'name': 'jason',
'p_type': '猛男',
'attack_val': 100,
'life_val': 1000,
}
dog1 = {
'name': '小白',
'p_type': '哈士奇',
'attack_val': 20,
'life_val': 400,
}
# 【缺陷】:如果要定义出多个人和多条狗则要重复创建多个字典信息
"""推导步骤2:将产生人和狗的字典封装成函数,并定义出人打狗的动作,狗咬人的动作"""
def create_person(name, type, attack_val, life_val):
person_dict = {
'name': name,
'p_type': type,
'attack_val': attack_val,
'life_val': life_val,
}
return person_dict
def create_dog(name, type, attack_val, life_val):
dog_dict = {
'name': name,
'p_type': type,
'attack_val': attack_val,
'life_val': life_val,
}
return dog_dict
# 创建人和狗
p1 = create_person('jason', '猛男', 500, 1000)
p2 = create_person('torry', '猛女', 500, 1000)
d1 = create_dog('小白', '哈士奇', 300, 1000)
d2 = create_dog('小黑', '柴犬', 300, 1000)
# 创建人打狗的动作 和 狗咬人的动作
def person_attack(person_dict, dog_dict):
print(f'人:{person_dict.get("name")},准备打狗:{dog_dict.get("name")}')
dog_dict['life_val'] -= person_dict['attack_val']
print(f'人揍了狗一拳,狗掉血{person_dict.get("attack_val")},狗剩余血量:{dog_dict.get("life_val")}')
def dog_attack(dog_dict, person_dict):
print(f'狗:{dog_dict.get("name")},准备咬人:{person_dict.get("name")}')
person_dict['life_val'] -= dog_dict['attack_val']
print(f'狗咬了人一口,人掉血{dog_dict.get("attack_val")},人剩余血量:{person_dict.get("life_val")}')
# 人狗大战
person_attack(p1, d1)
dog_attack(d1, p1)
# 【缺陷】:人可以用狗的动作,狗可以用人的动作
"""推导步骤3:让人只能调人的攻击动作,狗只能调狗的攻击动作(数据与功能的绑定)"""
def create_person(name, type, attack_val, life_val):
# 表示人的功能
def person_attack(person_dict, dog_dict):
print(f'人:{person_dict.get("name")},准备打狗:{dog_dict.get("name")}')
dog_dict['life_val'] -= person_dict['attack_val']
print(f'人揍了狗一拳,狗掉血{person_dict.get("attack_val")},狗剩余血量:{dog_dict.get("life_val")}')
# 表示人的数据
person_dict = {
'name': name,
'p_type': type,
'attack_val': attack_val,
'life_val': life_val,
'person_attack': person_attack,
}
return person_dict
def create_dog(name, type, attack_val, life_val):
# 表示狗的功能
def dog_attack(dog_dict, person_dict):
print(f'狗:{dog_dict.get("name")},准备咬人:{person_dict.get("name")}')
person_dict['life_val'] -= dog_dict['attack_val']
print(f'狗咬了人一口,人掉血{dog_dict.get("attack_val")},人剩余血量:{person_dict.get("life_val")}')
# 表示狗的数据
dog_dict = {
'name': name,
'p_type': type,
'attack_val': attack_val,
'life_val': life_val,
'dog_attack': dog_attack,
}
return dog_dict
# 创建人 与 狗的信息
p1 = create_person('jason', '猛男', 500, 1000)
d1 = create_dog('小白', '哈士奇', 300, 1000)
# 调用人打狗的动作 与 狗咬人的动作
p1.get('person_attack')(p1, d1)
d1.get('dog_attack')(d1, p1)
人狗大战总结:
将人的数据跟人的功能绑定在一起
将狗的数据跟狗的功能绑定在一起
以上得出 面向对象的核心思想:数据与功能的绑定
2.两种编程思想
(1)面向过程编程
过程就是流程,面向过程编程就是按照固定流程解决问题
eg:注册、登录、转账功能
按照指定的步骤依次执行,最终得到想要的结果
(2)面向对象编程
对象就是容器,里面是数据与功能的结合体(万物皆对象)
eg:游戏人物
只负责创造出人物及功能,至于后续发展如何不知道
"""
面向过程编程:相当于让你给出一个问题的具体解决方案
面向对象编程:相当于让你创造出一些事物,之后不用你管
"""
# 两者无好坏,需结合具体需求
# 如需求是注册登录 面向过程合适
# 如需求是游戏人物 面向对象更合适
3.类与对象
1)类与对象的概念
对象:数据与功能的结合体 对象才是核心
类 :多个对象相同数据与功能的结合体 类主要就是为了节省代码
一个人 对象
一群人 人类
一条狗 对象
一群狗 犬类
2)类与对象的创建
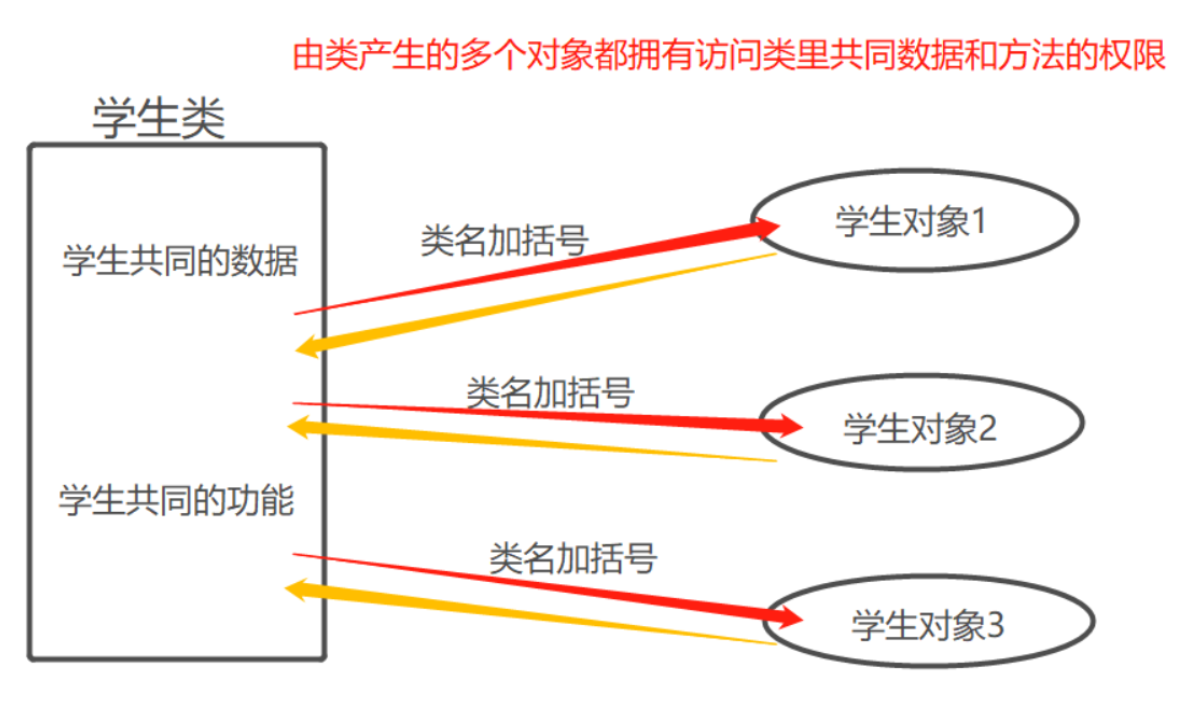
现实中一般是现有个体(对象),再有群体(类)
程序中必须先定义类,再产生对象
面向对象本质就是将数据和功能绑定在一起,为了突出面向对象编程,python专门设计了新的语法格式
1.类的语法结构
class 类名:
对象公共的数据
对象公共的功能
1.class是定义类的关键字
2.类名的命名和变量名一致,'首字母要大写'为了与函数名区分
3.数据:变量名与数据值的绑定
功能:也叫方法,其实就是函数
2.类的定义与调用
类在定义阶段就会执行类体代码,但是类的局部名称空间外界无法直接调用
类和对象获取内部数据的方法可以统一采用:句点符
类名()就会产生对象,每执行一次就会产生一个新的对象
# 定义学生类
class Student:
# 学生对象公共的数据
school = '清华大学'
# 学生对象公共的功能
def choice_course(self):
print('学生选课功能')
————————————————————————————————————————————————————————
print(Student.__dict__) # 查看名称空间(字典形式)
"""查看名称空间的方法1:(字典按K取值)"""
print(Student.__dict__.get('school')) # 清华大学
print(Student.__dict__.get('choice_course')) # <function Student.choice_course at 0x00000237F655EEE0>
"""查看名称空间统一采用方法2:(句点符)"""
print(Student.school) # 清华大学
print(Student.choice_course) # <function Student.choice_course at 0x000001BF9A96EEE0>
————————————————————————————————————————————————————————
# 类的调用(对象实例化、产生对象)
1.类名加括号产生对象,每执行一次就会产生一个新的对象
obj1 = Student()
print(obj1) # <__main__.Student object at 0x000001879A114E20>
obj2 = Student()
print(obj2) # <__main__.Student object at 0x00000200CCD59580>
2.此时如果查看对象会发现里面是空的字典
print(obj1.__dict__) # {}
print(obj2.__dict__) # {}
3.类产生的对象也可以通过句点符获取类中的公共数据和功能
print(obj1.school) # 清华大学
print(obj2.school) # 清华大学
4.修该公共数据(字典键对应的值)后所有对象点该名字时都被修改了
Student.school = '家里蹲'
print(obj1.school) # 家里蹲
print(obj2.school) # 家里蹲
#其他叫法:
数据和功能 也称为:属性
数据 也称为:属性名
功能 也称为:方法
3)对象独有的数据
# 定义学生类
class Student:
# 学生对象公共的数据
school = '清华大学'
# 学生对象公共的功能
def choice_course(self):
print('学生选课功能')
"""推导流程1:每个对象手动添加独有的数据"""
# 产生对象
obj1 = Student()
obj2 = Student()
print(obj1.__dict__) # {}
obj1.__dict__['name'] = 'jason' # 两种添加数据方式都可以
obj1.age = 18 # 两种添加数据方式都可以
print(obj1.__dict__) # {'name': 'jason', 'age': 18}
print(obj1.name) # jason
print(obj2.__dict__) # {}
obj2.name = 'torry'
obj2.__dict__['age'] = 20
print(obj2__dict__) # {'name': 'torry', 'age': 20}
print(obj2.name) # torry
#【缺陷】:代码重复
"""推导流程2:将添加对象独有数据的代码封装成函数"""
def init(obj, name, age):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
stu1 = Student()
stu2 = Student()
init(stu1, 'jason', '18')
init(stu2, 'torry', '20')
print(stu1.__dict__) # {'name': 'jason', 'age': '18'}
print(stu2.__dict__) # {'name': 'torry', 'age': '20'}
#【缺陷】:任何对象都可以调用该添加数据的函数
"""推导流程3:给学生对象添加独有数据的函数只有学生对象有资格调用(放在学生类里)"""
# 定义学生类
class Student:
# 学生对象公共的数据
school = '清华大学'
# 给学生对象添加独有数据
def init(obj, name, age):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
# 学生对象公共的功能
def choice_course(self):
print('学生选课功能')
stu1 = Student()
Student.init(stu1, 'jason', '18')
print(stu1.__dict__) # {'name': 'jason', 'age': '18'}
stu2 = Student()
Student.init(stu2, 'torry', '20')
print(stu2.__dict__) # {'name': 'torry', 'age': '20'}
"""推导流程4:init方法变形"""
'''
当内部有__init__时:
Student('jason', '18')会把产生的空对象和两个参数一起传给__init__(obj,name,age)
然后给对象添加独有的数据
'''
# 定义学生类
class Student:
# 学生对象公共的数据
school = '清华大学'
# 给学生对象添加独有数据
def __init__(obj, name, age):
obj.__dict__['name'] = name
obj.__dict__['age'] = age
# 学生对象公共的功能
def choice_course(self):
print('学生选课功能')
stu1 = Student('jason', '18')
print(stu1.__dict__) # {'name': 'jason', 'age': '18'}
————————————————————————————————————————————————————————————
"""推导终极流程5:变量名修改"""
#定义学生类
class Student:
# 学生对象公共的数据
school = '清华大学'
# 给学生对象添加独有数据(self指代的是空对象)
def __init__(self, name, age):
# 赋值符号左边是字典的键,右边是字典的值
self.name = name # 等价于:self.__dict__['name']
self.age = age # 等价于:self.__dict__['age']
# 学生对象公共的功能
def choice_course(self):
print('学生选课功能')
stu1 = Student('jason', '18')
print(stu1.__dict__) # {'name': 'jason', 'age': '18'}
print(stu1.name) # jason
print(stu1.school) # 清华大学
4)对象的独有功能(实例化方法)
"""推导流程1:直接在全局定义功能"""
#【缺陷】:该函数就不是学生对象独有的了 任何对象都可以调用
"""推导流程2:只能将函数放在类中 但是类中的函数又是对象公共的"""
'''python解释器自带的策略:定义在类中的功能 默认就是绑定给对象使用的 谁来调谁就是主人公'''
# 定义学生类
class Student:
# 学生对象公共的数据
school = '清华大学'
# 给学生对象添加独有数据
def __init__(self, name, age):
# 赋值符号左边是字典的键,右边是字典的值
self.name = name # 等价于:self.__dict__['name']
self.age = age # 等价于:self.__dict__['age']
# 学生对象公共的功能
def choice_course(self):
print(f'学生{self.name}正在选课')
stu1 = Student('jason', '18')
# 类调用功能需自己传一个参数
Student.choice_course(stu1) # 学生jason正在选课
# 对象调用功能会自动将对象当作第一个参数传入
stu1.choice_course() # 学生jason正在选课
stu2=Student('torry','20')
Student.choice_course(stu2) # 学生torry正在选课
stu2.choice_course() # 学生torry正在选课
5)补充:对象修改数据值
stu1.name = 'jack' # 当点的name已存在则会修改对应的值
stu1.pwd = 123 # 当点的pwd不存在则会新增数据
4.动静态方法
在类中定义函数有三种类型
1)类中直接定义函数 默认是绑定给对象的方法
1.对象调用会自动将对象当作第一个参数传入
2.类调用需要手动将对象当作第一个参数传入
self 用来接收对象
class Student:
school = '清华大学'
def func1(self, name):
print(f'{name}正在选课', self)
obj = Student()
print(obj) # <__main__.Student object at 0x0000027B9FE04E20>
# 对象调用
obj.func1('jason') # jason正在选课 <__main__.Student object at 0x000001F62BB14E20>
# 类调用
Student.func1(obj, 'torry') # torry正在选课 <__main__.Student object at 0x000001F62BB14E20>
2)被@classmethod修饰的函数 默认是绑定给类的方法
需被@classmethod修饰
1.类调用会自动将类当作第一个参数传入
2.对象调用会将产生该对象的类当作第一参数传入
cls 用来接收类
class Student:
school = '清华大学'
@classmethod
def func1(cls, name):
print(f'{name}正在选课', cls)
obj = Student()
print(Student) # <class '__main__.Student'>
# 对象调用
obj.func1('jason') # jason正在选课 <class '__main__.Student'>
# 类调用
Student.func1('torry') # torry正在选课 <class '__main__.Student'>
3)被@staticmethod修饰的函数 会变成普通的函数
需被@staticmethod修饰 也叫静态方法
1.无论是对象还是类调用,有多少参数就传多少参数!
class Student:
school = '清华大学'
@staticmethod
def func1(name, age):
print(f'{name}正在选课', age)
obj = Student()
# 对象调用
obj.func1('jason', 18) # jason正在选课 18
# 类调用
Student.func1('torry', 20) # torry正在选课 20
5.面向对象三大特性—继承
1)继承的概念
面向对象的三大特性:封装、继承(重要)、多态
| 继承 | 含义 | 目的 |
|---|---|---|
| 现实 | 用来表示人与人之间资源的关系 | 占有别人的财产 |
| 编程 | 用来表示类与类之间数据的关系 | 类A拥有类B中所有数据和方法的使用权 |
2)继承基本操作
1.定义类的时候类名后加括号填写要继承的类名
2.当要继承多个类的时候,括号里需逗号隔开
被继承的类:#父类、基类、超类
继承类的类:#子类、派生类
#常用父类、子类来表示
class Father:
money = 1000
def car(self):
print('我有很多车')
# 让Son类去继承Father类
class Son(Father):
pass
obj = Son()
print(Son.money) # 1000
Son.car(obj) # 我有很多车
obj.car() # 我有很多车
3)继承的本质
对象:数据与功能的结合体
子类:多个对象相同数据和功能的结合体
父类:多个子类相同数据和功能的结合体
子类与父类的本质就是为了节省代码
继承的本质:
抽象:将多个类相同的东西抽出去形成一个新的父类
继承:让子类继承刚刚抽出去的父类
就是把相同的代码抽出来变成一个父类,其他类想用的时候就变成子类继承父类,子类可以调用父类中的资源
4)对象查找名字的顺序
对象自身 >> 产生对象的类 >> 类的父类
(1)不继承的情况下
1.先去对象自身名称空间中找
2.没有再去产生该对象的类中去找
3.还没有则报错
#对象自身 >> 产生对象的类
class A1:
name = 'jason'
obj = A1()
# 对象自己的名称空间中没有,则会去产生对象的类中去找
print(obj.name) # jason
# 对象自己的名称空间中有了就用自己的
obj.name = 'zz'
print(obj.name) # zz
(2)单继承的情况下
1.先去对象自身名称空间中找
2.没有再去产生该对象的类中去找
3.没有再去继承的父类中找
#对象自身 >> 产生对象的类 >> 继承的父类
class A:
name = '这是A'
pass
class B(A):
# name = '这是B'
pass
class C(B):
# name = '这是C'
pass
obj = C()
# 当对象自身中没有就去产生对象的类中找,还没有就去继承的父类中找
print(obj.name) # 这是A
当遇到self时找谁?
变形:(遇到self时找谁?)
'当遇到self时需要先明确self是谁,如果是对象本身则从对象本身中再过一遍'
class A1:
def func1(self):
print('这是A1类中的func1')
def func2(self):
self.func1()
class B1(A1):
def func1(self):
print('这是B1类中的func1')
obj = B1()
# 当对象自身中没有就去产生对象的类中找,还没有去就继承的父类中找
obj.func2() # 这是B1类中的func1
(3)多继承的情况下
print(类.mro()) 方法可以获取名字查找顺序
🍑菱形继承
广度优先(从左到右每条道不会走最后闭合的点,最后才会走)
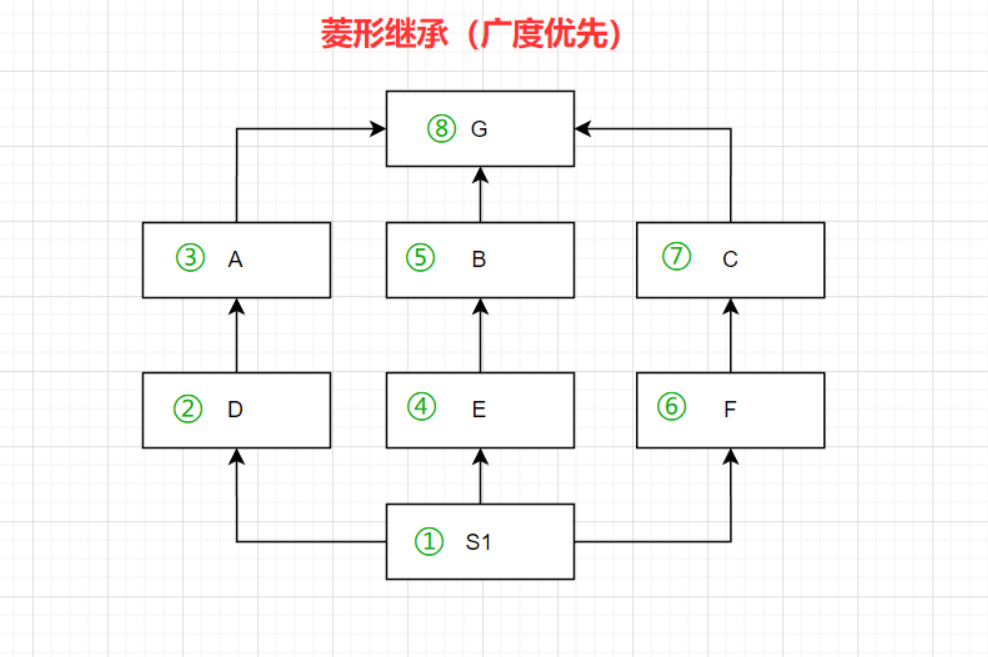
class G:
name = '这是G'
class A(G):
# name = '这是A'
pass
class B(G):
# name = '这是B'
pass
class C(G):
# name = '这是C'
pass
class D(A):
# name = '这是D'
pass
class E(B):
# name = '这是E'
pass
class F(C):
# name = '这是F'
pass
class S1(D, E, F):
pass
obj = S1()
print(obj.name) # from G
🍑非菱形继承
深度优先(从左到右每条道走完为止)
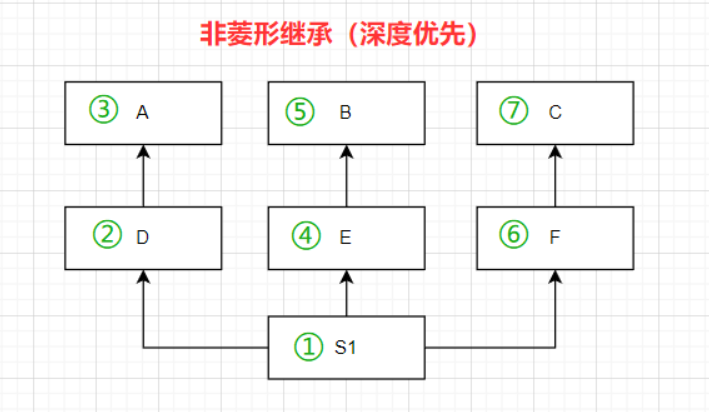
class A:
# name = '这是A'
pass
class B:
# name = '这是B'
pass
class C:
name = '这是C'
class D(A):
# name = '这是D'
pass
class E(B):
# name = '这是E'
pass
class F(C):
# name = '这是F'
pass
class S1(D, E, F):
pass
obj = S1()
print(obj.name) # 这是C
5)经典类与新式类
object中有类必备的所有功能
经典类:不继承object或其子类的类
新式类:继承了object或其子类的类
#在python2中有经典类和新式类
由于经典类中没有核心的功能所以在python3中就取消了
#在python3中只有新式类
'所有的类'默认都继承了object
今后在定义类时,如果没有要继承的父类就写继承object!目的时为了兼容python2
class A1(object):
pass
6)基于继承延伸出的 派生方法
super()在使用时和名字查找顺序不一样,super()在哪个类里,哪个就是子类。子类调用父类
子类基于父类又做了扩展可以简单理解成:想用别人的方法,又觉得别人方法不够
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
class Student(Person):
def __init__(self, name, age, play):
super().__init__(name, age) # 子类调用父类的方法
self.play = play # 自己补充的数据
obj = Student('jason', 18, 'run')
print(obj.__dict__) # {'name': 'jason', 'age': 18, 'play': 'run'}
练习:扩展列表尾部追加方法(不能追加jason)
class Mylist(list):
def append(self, v1):
if v1 == 'jason':
print('不能追加jason')
return
super().append(v1)
obj = Mylist()
print(obj, type(obj)) # [] <class '__main__.Mylist'>
obj.append(1)
print(obj) # [1]
obj.append('jason')
print(obj) # 不能追加jason [1]
5.面向对象三大特性—继承
7)派生方法实战演练
import json
import datetime
d = {'t1':datetime.date.today(),'t2':datetime.datetime.today()}
res = json.dumps(d)
print(res) # 报错
"""
当我们想把d1字典序列化时发现会报错:
raise TypeError(f'Object of type {o.__class__.__name__} '
TypeError: Object of type date is not JSON serializable
__________________________________________
原因是:能够被序列化的数据是有限的,不是所有类型都可以
可输入json.JSONEncoder查看源码发现 里里外外都必须是下列左边的类型才可以
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
"""
# 解决方法1:手动转换成字符串类型
import json
import datetime
d = {'t1':str(datetime.date.today()),'t2':str(datetime.datetime.today())}
res = json.dumps(d)
print(res) # {"t1":"2022-11-07","t2":"2022-11-07 16:10:31"}
# 解决方式2:派生方法
"""
查看json.dumps源码发现:
cls参数默认传JSONEncoder,
序列化报错是由default方法触发的,
default方法中的报错信息与上面的报错信息一致.
所以需编写类继承json.JSONEncoder重写default方法
然后调用dumps手动传cls=我们的类
"""
import json
import datetime
d = {'t1': datetime.date.today(), 't2': datetime.datetime.today()}
class MyJsonEncoder(json.JSONEncoder):
def default(self, o):
"""
:param o: 接收无法被序列化的数据
:return:返回可以被序列化的数据
"""
# 判断o是否是datetime.datetime、datetime.date类型,如果是则处理成可被序列化的类型
if isinstance(o, datetime.datetime):
return o.strftime('%Y-%m-%d %X')
elif isinstance(o, datetime.date):
return o.strftime('%Y-%m-%d')
# 最后再调用原来的方法 防止有额外操作没有做
return super().default(o)
# 去走我们自己定义的MyJsonEncoder方法
res = json.dumps(d, cls=MyJsonEncoder)
print(res) # {"t1": "2022-11-07", "t2": "2022-11-07 16:10:31"}
6.面向对象三大特性—封装
封装:就是将数据或功能隐藏起来
隐藏:隐藏起来不让用户直接调用,开设特定的接口只能间接调用,在该接口中可以添加额外的操作
伪装:将类里面的功能伪装成类里面的数据
1)如何隐藏数据或功能
类在定义阶段使用杠杠开头的名字会被隐藏起来, 类、对象都无法直接访问
class C:
__name = '这是类里的数据' # 使用杠杠开头的名字会被隐藏
def __func(self):
print('这是类里的功能') # 使用杠杠开头的名字会被隐藏
obj = C()
print(obj.name) # 报错 提示类里没有属性name
obj.func() # 报错 提示类里没有属性func
print(C.__dict__) # 查看类里的名称空间发现并没有被隐藏只是改了名字
"""
在python中其实没有真正意义上的隐藏
只是改为了_类名__名字(_C__name、 _C__func)
"""
print(obj._C__name) # 这是类里的数据
obj._C__func() # 这是类里的功能
2)如何访问隐藏的数据或功能
1.既然隐藏了就不该使用变形之后的名字去访问,因为会失去隐藏的意义
2.只允许写一个方法,调用该方法去访问(开设一个接口)
3.类体代码中可以直接使用隐藏的名字
4.今后看到单杠、杠杠开头的名字都是在表达不要直接访问,往下找可能定义了访问接口
class Person:
def __init__(self, name, age):
self.__name = name
self.__age = age
# 开设一个访问隐藏数据或功能的方法(接口)
def get_info(self):
# 类体代码中可以直接使用隐藏的名字
print(f"姓名:{self.__name} 年龄:{self.__age}")
# 开设一个修改的方法(接口),可以自定义其他功能
def set_name(self, new_name):
if len(new_name) == 0:
raise ValueError('名字不能为空')
self.__name = new_name
obj = Person('jason', 18)
print(obj.__dict__) # {'_Person__name': 'jason', '_Person__age': 18}
obj.get_info() # 姓名:jason 年龄:18
# obj.set_name('') # 报错 提示名字不能为空
obj.set_name('torry')
print(obj.__dict__) # {'_Person__name': 'torry', '_Person__age': 18}
obj.get_info() # 姓名:torry 年龄:18
3)如何把功能伪装成数据
通常:
对象查看数据:obj.name
对象查看功能:obj.func()
伪装后:
对象查看功能:obj.func
扩展知识:体质指数(BMI)=体重(kg)÷身高(m)^2
举例 :70 / (1.70 ** 1.70) = 20.76
由于BMI应该是人的基本数据而不是方法 所以需要用伪装
#【简单伪装:】 需用@property 伪装修饰
class Person(object):
def __init__(self, name, height, weight):
self.name = name
self.height = height
self.weight = weight
@property
def BMI(self):
return self.weight / (self.height ** 2)
p1 = Person('jason', 1.70, 60)
res = p1.BMI
print(res) # 20.76
print(p1.BMI) # 20.76
#【终极伪装:】了解即可
# @name.setter 修改
# @name.deleter 删除
class Foo:
def __init__(self, v):
self.__NAME = v # 将属性隐藏起来
@property # 伪装
def name(self):
return self.__NAME
@name.setter # 修改
def name(self, value):
if not isinstance(value, str): # 校验当value不是str类型时报错
raise TypeError(f'{value}必须是字符串')
self.__NAME = value # 通过类型检查后,将值value存放到真实的位置self.__NAME
@name.deleter # 删除
def name(self):
raise PermissionError('不能删除')
obj = Foo('jason')
print(obj.name) # jason
# obj.name = 123 # 报错 提示必须是字符串
obj.name = 'torry'
print(obj.name) # torry
del obj.name # 报错 提示不能删除
7.面向对象三大特性—多态
多态:一种事物的多种形态
在面向对象中多态:一种事物可以有多种形态,但是相同的功能应该有相同的方法(名字),这样无论我们拿到的是哪个具体的事物,都可以通过相同的方法调用功能。
python中还有一种限制:子类继承父类时,子类中要有一个父类的方法
但是!python又是简单自由大方的,不会限制程序员的行为,所以了解即可!
class Animal:
def spark(self):
pass
class Cat(Animal):
def spark(self):
print('喵~')
class Dog(Animal):
def spark(self):
print('汪~')
c = Cat()
c.spark() # 喵~
d = Dog()
d.spark() # 汪~
不过多态也提供了约束的方法
import abc
# 指定metaclass属性将类设置为抽象类,抽象类本身只是用来约束子类的,不能被实例化
class Animal(metaclass=abc.ABCMeta):
@abc.abstractmethod # 该装饰器限制子类必须定义有一个名为speak的方法
def speak(self): # 抽象方法中无需实现具体的功能
pass
class Cat(Animal): # 但凡继承Animal的子类都必须遵循Animal规定的标准
def speak(self):
print('喵~')
class Dog(Animal):
def run(self):
print('跑')
cat = Cat() # 若子类中没有一个名为speak的方法则会抛出异常TypeError,无法实例化
cat.speak() # 喵~
dog = Dog()
dog.run() # 报错 提示没有名为speak的方法
鸭子类型:只要你长得像鸭子、走路像鸭子、说话像鸭子,那你就是鸭子
# 定义两个类,只要一样的类型,就算不继承也应该封装一个一样的方法
class Teacher:
def run(self):pass
def eat(self):pass
class Student:
def run(self):pass
def eat(self):pass
扩展知识:
linux系统:一切皆文件
只要你能读取数据、写数据那你就是文件(文件、内存、硬盘..)
python中:一切皆对象
只要你有数据,有功能那你就是对象( 文件名(文件对象)、模块名(模块对象) )
8.反射
反射:通过字符串来操作对象的数据或方法
1)反射的四个方法
(1)hasattr()(重点)
判断对象是否含有某个字符串对应的属性名(数据名)或方法名(功能名)
(2)getattr()(重点)
根据字符串获取对象对应的属性名(值)或方法名(函数体代码)
(3)setattr()
根据字符串给对象设置或修改数据
(4)delattr()
根据字符串删除对象里的名字
目的是为了和用户交互起来
2)什么时候用反射?
只要在需求中看到关键字:..对象..字符串 就可以用反射
3)反射方法使用
1.hasattr():判断对象是否含有某个字符串对应的属性名或方法名
2.getattr():根据字符串获取对象对应的属性名(值)或方法名(函数体代码)
——————————————————————————————————————————
class Student:
school = '清华大学'
def choice_course(self):
print('学生正在选课')
# 判断对象是否含有某个字符串对应的属性名或方法名
print(hasattr(obj, 'school')) # True
print(hasattr(obj, 'choice_course')) # True
# 根据字符串获取对象对应的属性名的值 或 方法名(函数体代码)
print(getattr(obj, 'school')) # 清华大学
print(getattr(obj, 'choice_course')) # <bound method Student.choice_course of <__main__.Student object at 0x000002A02F8D1160>>
3.setattr():根据字符串给对象设置或修改数据
4.delattr():根据字符串删除对象里的名字
——————————————————————————————————————————
class Student:
school = '清华大学'
def choice_course(self):
print('学生正在选课')
obj = Student()
# 给对象设置属性
obj.name = 'jason'
print(obj.__dict__) # {'name': 'jason'}
# 用字符串给对象设置/修改属性
setattr(obj, 'age', 18)
print(obj.__dict__) # {'name': 'jason', 'age': 18}
# 给对象删除属性
del obj.name
print(obj.__dict__) # {'age': 18}
# 用字符串给对象删除属性
delattr(obj, 'age')
print(obj.__dict__) # {}
9.反射方法实战演练
举例1:根据用户输入的字符串来自动选择执行数据还是方法
class Student():
school = '清华大学'
def choice_course(self):
print('学生正在选课')
obj = Student()
while True:
target_name = input('输入你要操作的名字:').strip()
if hasattr(obj, target_name):
print('恭喜您系统中有该名字')
res = getattr(obj, target_name)
if callable(res):
print('该名字是系统中的某个功能')
res()
else:
print('该名字是系统中的某个数据')
print(res)
else:
print('抱歉系统中无该名字')
举例2:模拟cmd终端
class WinCmd:
def task(self):
print("""
1.吃饭
2.睡觉
3.玩乐
""")
def ipconfig(self):
print("""
地址:192.168.1.1
地址:上海
""")
def get(self, target_file):
print("获取指定文件", target_file)
def put(self, target_file):
print("上传指定文件", target_file)
def server_run(self):
print('欢迎进入cmd终端')
while True:
target_cmd = input('输入您的指令:').strip()
res = target_cmd.split(' ')
if len(res) == 1:
if hasattr(self, res[0]):
getattr(self, res[0])()
else:
print(f'{res[0]}不是内部或外部命令')
elif len(res) == 2:
if hasattr(self, res[0]):
getattr(self, res[0])(res[1])
else:
print(f'{res[0]}不是内部或外部命令')
obj = WinCmd()
obj.server_run()
举例3:利用反射保留某个py文件中所有的大写变量名及对应的数据值
import settings
# print(dir(settings)) # 获取对象可以使用的名字
d1 = {}
for i in dir(settings):
if i.isupper():
d1[i] = getattr(settings, i)
print(d1)
10.面向对象的魔法方法
魔法方法:类中定义的双下方法都叫魔法方法
不需要人为调用,特定条件下自动触发运行
1)八大常用魔法方法
1.__init__类名加括号对象添加独有数据时自动触发(实例化对象)
class C(object):
def __init__(self, name):
self.name = name
print('__init__')
obj = C('jason') # __init__
2.__str__对象被执行打印操作时自动触发
①给返回值且必须是字符串
②不能返回对象本身,会被循环调用
③可以返回对象的某一个值
class C(object):
def __init__(self, name):
self.name = name
def __str__(self):
return f'{self.name}说对象被打印时自动触发'
obj = C('jason')
print(obj) # jason说对象被打印时自动触发
3.__call__对象加括号调用时自动触发,且可用变量名去接收返回值。且括号里可以跟参数被args,kwargs接收
①加了该方法的对象同时拥有了函数、对象的功能
class C(object):
def __init__(self, name):
self.name = name
def __call__(self, *args, **kwargs):
print('__call__')
return 123
obj = C('jason')
obj() # __call__
res = obj() # __call__
print(res) # 123
4.__getattr__对象点不存在的名字时自动触发
①item接收不存在的名字
②该方法返回什么 打印出来的就是什么
class C(object):
def __init__(self, name):
self.name = name
def __getattr__(self, item):
print('__getattr__')
print(item)
return '返回值'
obj = C('jason')
obj.zzz # __getattr__
print(obj.zzz) # 返回值
5.__getattribute__对象点名字时自动触发 有该方法存在就不会执行__getattr__
①不管存在还是不存在 都会触发 一般很少用。
6.__setattr__给对象添加或修改数据时自动触发(对象.名字 = 值)
①因为自动执行了__init__方法,内部在用对象.名字=名字 所以会触发__setattr__
②key和value分别代表的就是变量名和数据值
③无论在什么地方只要触发了该语法就会执行
class C(object):
def __init__(self, name):
self.name = name
def __setattr__(self, key, value):
print('__setattr__')
print(key, value)
obj = C('jason') # __setattr__ name jason
7.__enter__当对象被当作with上下文管理操作的开始自动触发
①该方法返回什么as后的变量名就接收什么
8.__exit__ 当对象参与with上下文管理操作运行结束自动触发(子代码结束)
class C(object):
def __init__(self, name):
self.name = name
def __enter__(self):
return 123
def __exit__(self, exc_type, exc_val, exc_tb):
pass
obj = C('jason')
with obj as f:
print(f) # 123
2)魔法方法笔试题
# 1.补全下列代码使得运行不报错即可
class Context:
pass
with Context() as f:
f.do_something()
__________________________
class Context:
def do_something(self):
pass
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
pass
with Context() as f:
f.do_something()
"""
看到with就可以想到使用了上下文管理,魔法方法里__enter__和__exit__是一起使用的,切看到后面f去点了一个do_something(),所以f需要给一个对象也就是__enter__返回一个对象出来让f去接收。对象点do_something 所以也需要有一个do_something方法。
"""
# 2.自定义字典类型并让字典能够通过句点符的方式操作键值对
class MyDict(dict):
def __setattr__(self, key, value):
self[key] = value
def __getattr__(self, item):
return self.get(item)
obj = MyDict()
# print(obj) # {}
# print(obj.__dict__) # {}
obj.name = 'jason'
# print(obj) # {'name': 'jason'}
# print(obj.__dict__) # {}
print(obj.name) # jason
"""
字典对象拥有存储数据的能力,一个是名称空间,一个是独有的数据空间
"""
11.元类
1)元类的推导流程
"""推导流程1:如何查看数据的数据类型"""
s1 = 'hello'
l1 = [11, 22, 33]
print(type(s1)) # <class 'str'>
print(type(l1)) # <class 'list'>
# type其实是在看产生该对象的类
"""推导流程2:python中一切皆对象,那么type查看类名显示的是什么"""
class Student:
pass
obj = Student()
print(type(obj)) # <class '__main__.Student'>
print(type(Student)) # <class 'type'>
# 发现type(类名)是产生类的类:type
# 结论:我们定义的类都是由type类产生的,也叫元类(产生类的类)
2)元类简介
我们定义的类都是由type类产生的,也叫元类(产生类的类)
3)创建类的两种方式
(1)方式一:使用关键字class
class Teacher:
pass
print(Teacher) # <class '__main__.Teacher'>
(2)方式二:利用元类type(一般不用)
变量名接收 = type(类名,类的父类,类的名称空间)
cls = type('Student', (object,), {})
print(cls) # <class '__main__.Student'>
"""
了解知识:名称空间的产生
1.手动写键值对
针对绑定方法不好定义
2.内置方法exec
能够运行字符串类型的代码并产生名称空间
"""
4)自定义元类去定制类、对象的创建
目的是明白:我们可以自己高度定制化类、对象的产生行为
(1)元类定制类的产生行为
可以重写元类去干预类的产生过程
"""
对象是由类名加括号产生的 执行类里的__init__
类是由元类加括号产生的 执行元类里的__init__
"""
"""要求:所有的类必须首字母大写 否则不能产生类"""
# 类是由元类加括号产生的
# 1.自定义元类:继承type的类也称为元类
class MyMetaClass(type):
def __init__(self, what, bases=None, dict=None):
# what:类名 bases:类的父类 dict:类的名称空间
if not what.istitle(): # istitle()首字母大写
raise TypeError('类名首字母必须大写!')
super().__init__(what, bases, dict)
# 2.指定类的元类:利用关键字metaclass=某个类 来指定类的元类
class Myclass(metaclass=MyMetaClass):
info = '嘿嘿'
class myclass(metaclass=MyMetaClass):
pass
print(Myclass) # <class '__main__.Myclass'>
print(Myclass.__dict__) # 查看类的名称空间( 'info':'嘿嘿' 也在里面)
# 类名首字母小写会报错
(2)元类定制对象的产生行为
可以重写元类去干预对象的产生过程
"""
对象加括号会执行产生该对象类里的 __call__
类加括号会执行产生该类的类里的 __call__
"""
"""要求:给对象添加独有数据时必须采用关键字参数传参"""
# 1.自定义元类:继承type的类也称为元类
class MyMetaClass(type):
def __call__(self, *args, **kwargs):
# __call__做的三件事:
# 1.产生一个空对象(骨架)
# 2.调用__init__给对象添加独有的数据
# 3.返回创建好的对象
if args:
raise TypeError('给对象添加独有数据时必须采用关键字参数传参')
return super().__call__(*args, **kwargs)
# 2.指定类的元类:利用关键字metaclass=某个类 来指定类的元类
class Student(metaclass=MyMetaClass):
def __init__(self, name, age):
self.name = name
self.age = age
obj=Student(name='jason',age=18)
print(obj.__dict__) # {'name': 'jason', 'age': 18}
5)元类的双下new魔法方法
__new__方法就是用来产生一个空对象的
__init__方法专门用于给对象添加属性
类产生对象时,元类中__call__真正的执行流程:
# 1.自定义元类:继承type的类也称为元类
class MyMetaClass(type):
def __call__(self, *args, **kwargs):
# __call__做的三件事:
# 1.产生一个空对象(骨架)
obj = self.__new__(self)
# 2.调用__init__给对象添加独有的数据
self.__init__(obj, *args, **kwargs)
# 3.返回创建好的对象
return obj
class Student(metaclass=MyMetaClass):
def __init__(self, name):
self.name = name
obj = Student('jason')
print(obj.name)
12.设计模式简介及单例模式
1)设计模式简介
就是前人通过大量验证创建出来一些解决问题的固定高效方法
2)IT行业中的设计模式
①.创建型 5种
②.结构型 7种
③.行为型 11种
共有23种设计模式
3)创建型——单例模式
单例模式:类加括号无论执行多少次永远只会产生一个对象
目的:当类中有很多强大的方法 我们在程序中很多地方都需要使用
如果不做单例 会产生很多无用的对象浪费存储空间
所以用单例模式让整个程序就用一个对象
也就是节省内存
4)单例模式实现的多种方式
单例模式的思路:就是提前用该类产生一个对象 然后放在某个地方(元类、装饰器等..) 判断用户有没有传参数看是想用单例还是产生新对象
"""单例方式一:利用@classmethod绑定给类的方法去实现"""
class C1:
__instance = None
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
def singletion(cls):
if not cls.__instance:
cls.__instance = cls('jason', 18)
return cls.__instance
# 当想产生一个固定对象就去调里面的单例方法
obj1 = C1.singletion()
obj2 = C1.singletion()
print(id(obj1)) # 2173218755968
print(id(obj2)) # 2173218755968
# 当想产生新对象时
obj3 = C1('torry', 20)
print(id(obj3)) # 2485938066480
"""单例方式二:基于元类去实现"""
class Mymeta(type):
def __init__(self, name, bases, dic): # 定义类Mysql时就触发
# 事先先从配置文件中取配置来造一个Mysql的实例出来
self.__instance = object.__new__(self) # 产生对象
self.__init__(self.__instance, 'jason', 18) # 初始化对象
# 上述两步可以合成下面一步
# self.__instance=super().__call__(*args,**kwargs)
super().__init__(name, bases, dic)
def __call__(self, *args, **kwargs): # Mysql(...)时触发
if args or kwargs: # args或kwargs内有值 如果传值则表示想产生新对象
obj = object.__new__(self)
self.__init__(obj, *args, **kwargs)
return obj
return self.__instance # 如果不传值则表示想使用单例
class Mysql(metaclass=Mymeta):
def __init__(self, name, age):
self.name = name
self.age = age
# 如果不传值则表示想使用单例
obj1 = Mysql()
obj2 = Mysql()
print(id(obj1)) # 1264882352720
print(id(obj2)) # 1264882352720
# 如果传值则表示想产生新对象
obj3 = Mysql('tony', 321)
print(id(obj3)) # 2672059848304
"""单例方式三:基于模块的单例"""
# 把该文件当作模块
class C1:
def __init__(self, name):
self.name = name
obj = C1('jason')
# 其他py文件导该模块点obj就会产生一个对象
import 上面的模块名
上面的模块名.obj # 产生的就是一个对象
print(id(上面的模块名.obj))
"""单例方式四:基于装饰器实现"""
def outer(cls):
_instance = cls('jason')
def inner(*args, **kwargs):
if args or kwargs:
obj = cls(*args, **kwargs)
return obj
return _instance
return inner
@outer # Mysql=outer(Mysql)
class Mysql:
def __init__(self, name):
self.name = name
# 如果不传值则表示想使用单例
obj1 = Mysql()
obj2 = Mysql()
print(id(obj1)) # 2288062305232
print(id(obj2)) # 2288062305232
# 如果传值则表示想产生新对象
obj3 = Mysql('jason')
print(id(obj3)) # 2110355183120
13.pickle序列化模块
pickle模块与json模块很像 都是序列化、反序列化的
优势:支持序列化python所有的数据类型 比如:对象
劣势:不支持跨语言传输,只能python中使用。兼容不好
限制:在当前程序名称空间中一定要有产生该对象的类存在,如果存进去的时候有,清除类后再取会报错
# 练习:
"""产生一个对象并保存到文件中,取出来还是一个对象"""
class Myclass:
def __init__(self, name):
self.name = name
def choice_course(self):
print(f'{self.name}正在选课')
obj = Myclass('jason')
import pickle
'''pickle序列化把对象保存到文件中'''
# with open(r'a.txt', 'wb')as f:
# pickle.dump(obj, f)
'''pickle反序列化把对象取出来'''
with open('a.txt', 'rb')as f:
res = pickle.load(f)
print(res) # 打印出来是一个对象<__main__.Myclass object at 0x0000021BD0D113D0>
res.choice_course() # jason正在选课
print(res.name) # jason

 浙公网安备 33010602011771号
浙公网安备 33010602011771号