模块
- 一.模块
- 1.模块简介
- 2.模块的三大分类
- 3.导入模块的两种句式
- 4.导入模块的句式补充
- 5.循环导入问题及解决策略
- 6.判断文件类型
- 7.模块的查找顺序
- 8.模块的绝对导入与相对导入
- 9.包
- 10.编程思想的转变
- 11.软件开发目录规范
- 12.python常用内置模块
- 13.网络爬虫简介
- 14.第三方模块
一.模块
1.模块简介
1)什么是模块
内部具有一定功能(代码)的py文件
2)python模块的历史
python屈辱史:
python刚出来时被瞧不起因为太简单,写代码都是调用模块(调包侠 贬义).
后来业务扩展很多程序员也需要使用python写代码,发现好用(调包侠 褒义).
python为什么好用?
因为支持python的模块非常多还很全面.
作为python程序员将来接收到业务需求时不要一上来就想自己写,先看看有没有相应的模块已经实现可以调用.
3)模块的表现形式
(1)py文件(也称之为模块文件)
(2)含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
(3)已被编译为共享库或DLL的c或c++扩展(了解)
(4)使用c编写并链接到python解释器的内置模块(了解)
2.模块的三大分类
1)内置模块
python解释器自带可以直接使用的模块 import time等
2)自定义模块
自己写的模块 注册、登录..
3)第三方模块
别人写的模块文件,在网上下载的图形识别、图像可视化..
3.导入模块的两种句式
注意:
①.项目中所有py文件名都要是英文,没有中文和数字
②.导入模块文件不需要填写后缀名import md
③.同一个py文件中反复导入相同的模块,导入语句只会执行一次
1)import ..句式
import md
1.先产生执行文件的名称空间
2.执行模块文件的代码,产生模块名称空间
3.在执行文件的名称空间中产生一个模块文件的模块名,通过点的方式就可以使用该模块名称空间中的名字
【a.py】:
name = 'jason'
——————————————————————————————————
【md.py】:
import a
print(a.name) #执行文件中用a.name即可使用。函数等同理
#结果为:jason
2)from .. import ..句式
from a import name
1.先产生执行文键的名称空间
2.执行模块文件的代码,产生模块名称空间
3.在执行文件的名称空间中产生对应的名字绑定模块名称空间中对应的名字,通过点的方式就可以使用该模块名称空间中的名字
【a.py】:
name = 'jason'
——————————————————————————————————
【md.py】:
from a import name
print(name) #执行文件中可直接使用name。函数等同理
#结果为:jason
| import..句式 | from..import..句式 | |
|---|---|---|
| 优点 | 可以通过模块名点的方式可以使用到模块内所有的名字,且不会冲突(md.name) | 指名道姓的使用需要的名字,直接就可以使用该名字,不用模块去点(name) |
| 缺点 | 由于模块名什么都可以点,有时候不想让所有的名字都能被使用 | 容易与执行文件中的名字产生冲突 |
4.导入模块的句式补充
1)起别名
当两个模块文件中都有name时,在执行文件中打印name,结果就是当前执行文件中的name。如果想使用被导入文件的name,则需要as取别名
【a.py】:
name = 'jason'
——————————————————————————————————
【md.py】:
from a import name
name = 'torry'
print(name) #此处打印的name是当前执行文件中的name
#结果为:torry
from a import name as n #取别名
print(n)
#结果为:jason
2)导入多个模块
当多个模块功能相似时可以在一起导入,不相似的尽量分开导入
import a,b,c
from a import login,register
————————————————————————————————
import a
import b
from a import name
from a import login
3)全导入(仅针对from..import..句式)
①.需要使用模块中多个名字时可以用*号的方式
【a.py】:
name = 'jason'
age = 18
job = 'teacher'
——————————————————————————————————
【md.py】:
from a import *
print(name,age,job) #可以使用a模块文件中所有的名字
②.针对*号可以用__all__ = [变量名]控制可使用的变量名
【a.py】:
name = 'jason'
age = 18
job = 'teacher'
__all__ = [name,age]
——————————————————————————————————
【md.py】:
from a import *
print(name) # 结果为:jason
print(job) # 报错
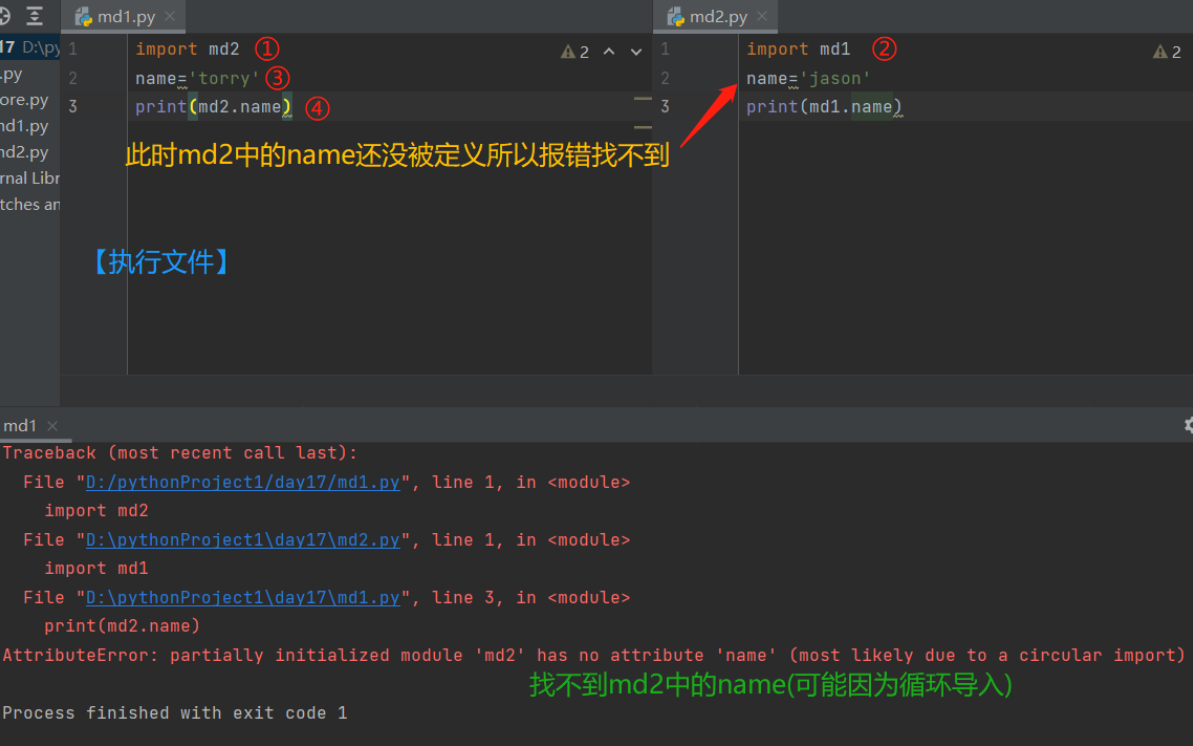
5.循环导入问题及解决策略
1)什么是循环导入?
循环导入就是两个文件彼此导入彼此,且互相使用对方名称空间中的名字。
2)如何解决循环导入问题
1.确保在使用各自名字前就把名字定义好
2.尽量避免写循环导入的代码
6.判断文件类型
所有的py文件都可以直接打印__name__判断文件类型
当文件是'执行文件'时:
print(__name__)
#结果为:__main__
当文件是'被导入文件'时:
print(__name__)
#结果为:被导入的文件名
一般__name__主要是用于测试自己代码时使用:当文件是执行文件时才往下走子代码
if __name__=='__main__'
print('当文件是执行文件时才会执行if的子代码')
#上述脚本一般只出现在整个程序的启动文件中
7.模块的查找顺序
1.先去内存中查找
#验证:在执行文件中执行被导入文件中的函数,在执行过程中删除被导入文件发现还可以使用
import md #导入执行md模块
import time #导入执行time模块
time.sleep(15) #让程序暂停15s再执行
'中途如果把md模块文件删掉 还会继续执行,因为删除的是硬盘中的,内存中的还在'
print(name)#结果为:jason
____________________________________________
2.再去内置中查找
#验证:创建一个和内置模块相同的模块文件名
【time.py】:
name = 'jason'
【执行文件.py】:
from time import name
print(name)#结果会报错
import time
print(name)#结果会报错
_____________________________________________
3.然后去执行文件所在的sys.path中查找 # 不是系统环境变量
需注意'所有路径都是参照执行文件所在的路径去查找'
#验证:如果执行文件和被执行文件在不同文件夹下,则要把模块所在的文件路径添加到执行文件的sys.path中
import sys
# print(sys.path)#执行sys.path结果为当前执行文件的环境变量,以列表显示
sys.path.append(r'D:\pythonProject1\day17\aa')#将被导入文件的路径添加
import md3
print(md3.name)#此时打印md3中的name就可以找到 不添加路径则找不到
8.模块的绝对导入与相对导入
只要涉及到模块导入就以当前执行文件路径为准! (站在执行文件路径的视角去看)
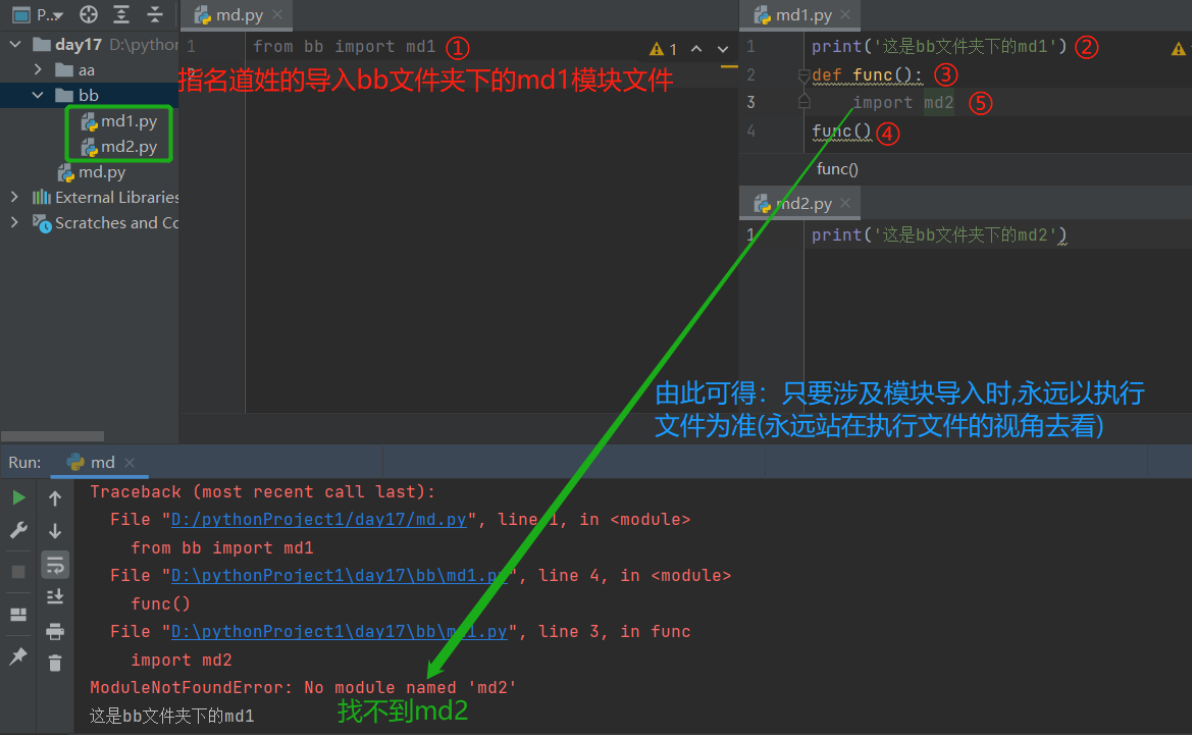
以上报错解决方案:
1.把bb文件夹路径添加到执行文件sys.path路径中
2.在md1.py文件中把import md2 改为 from bb import md2('这就是绝对导入')
1)绝对导入
(1)就是以执行文件所在的sys.path为起始位置一层一层查找
from aa import md
(2)当涉及文件嵌套多个文件名时,则要在文件名后加点和内层文件名
from aa.bb.cc import md
2)相对导入
#点号在相对导入中的作用
. 在路径中表示当前目录
.. 在路径中表示上一层目录
..\.. 在路径中表示上上一层目录
(1)相对导入可以不参考执行文件所在的路径,直接以当前模块文件路径为准!!!
from . import md2
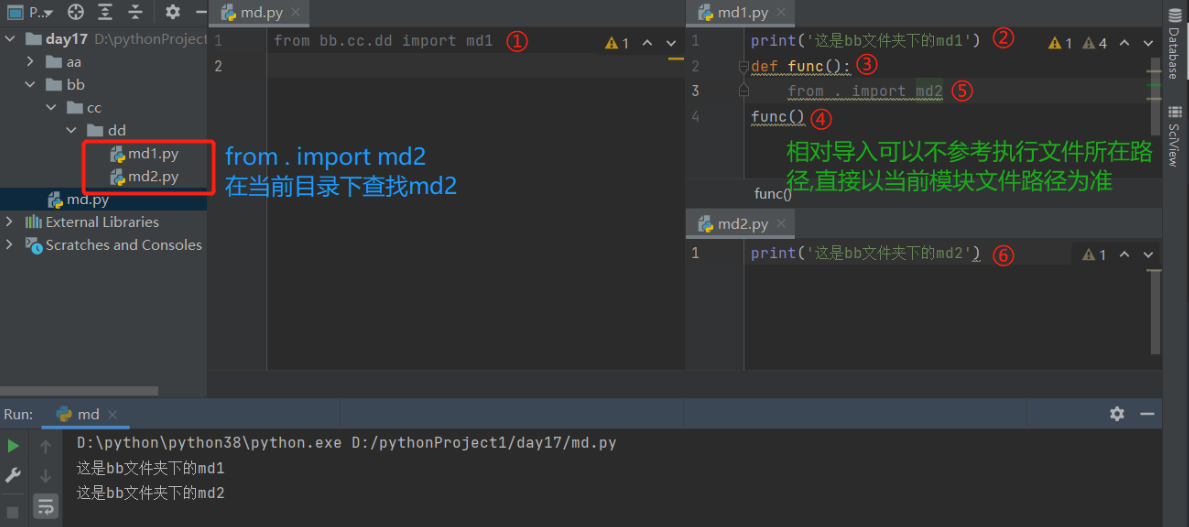
(2)缺陷:
1.只能在被导入模块文件中使用,不能在执行文件中使用!!
2.当项目较复杂时容易报错,尽量不用!!!用绝对路径就够了
9.包
1)包是什么
专业角度:内部含有__init__.py文件的文件夹就叫包
大白话为:文件夹内有多个py文件
2)不同解释器如何理解包
python3解释器:文件夹里有没有__init__.py文件都无所谓,都叫包
python2解释器:文件夹里必须有__init__.py文件才叫包
3)包的具体使用
虽然python3解释器对包的要求降低了,不需要__init__.py就可以识别,但是为了兼容考虑建议不管什么版本解释器都加上。
1.如果想只用包里的某几个模块
from aa import md1,md2
print(md1.name)#可以使用md1中的name
2.如果直接导包名则就是包下面'__init__.py文件',该文件中有什么名字就可以通过包名点什么名字
import aa
print(aa.name)#可以使用aa包里__init__.py里的名字
10.编程思想的转变
阶段一:面条版阶段(所有代码从上到下堆叠在一起)单文件
阶段二:函数版阶段(将代码按照功能的不同封装不同函数)单文件
结算三:模块版阶段(根据功能不同拆分为不同的py文件)多文件
1.阶段一可以理解为将所有文件全部存储到c盘且不分类
eg:'系统、视频、图片'
2.阶段二可以理解为将文件分类
eg:'系统文件、视频文件、图片文件'
3.阶段三可以理解为按照不同功能放在不同的盘里
eg:'C盘放系统文件、D盘放视频文件、E盘放图片文件'
#这样做就是为了资源的【高效管理】
11.软件开发目录规范
针对上述,所有程序目录都要有一些规范!
1.bin文件夹 'start.py'
启动文件#可有可无,启动文件也可放根目录下
2.conf文件夹 'settings.py'
配置文件#里面都是不常改变的常量:常量名大写
3.core文件夹 'src.py'
核心逻辑#存放项目核心功能文件
4.interface文件夹 '注册、登录..'
接口文件#根据具体业务逻辑划分对应文件
5.lib文件夹 'common.py'
公共功能#很多文件都要使用
6.db文件夹 'userinfo.txt'
存储用户数据#注册后的用户信息,今后会被数据库代替
7.log文件夹 'log.log'
日志文件#今后会被日志模块代替
8.readme.txt文件
使用说明书
9.requirements.txt文件
第三方模块#存放该程序需要的第三方模块和版本
12.python常用内置模块
1.collections模块
除了基本数据类型(dict、list、set、tuple),collections模块还提供了几个额外的数据类型:nametuple、deque、OrderedDict和Counter等
📌nametuple具名元组
就是可以给一个元组命名,通过名字可以访问内部自定义的属性
简单理解就是:如果用元组表示一个坐标,那我突然给你一个元组你分不清x和y分别对应的是什么,这个时候就可以用具名元组
# 表示二维坐标系
from collections import namedtuple
zuobiao = namedtuple('二维坐标', ['x', 'y'])
p1 = zuobiao(1, 2)
print(p1) # 二维坐标(x=1, y=2)
print(p1.x) # 1
print(p1.y) # 2
#可以用来做简单扑克牌
from collections import namedtuple
puke = namedtuple('扑克牌', ['花色', '点数'])
res1 = puke('♥', 'A')
print(res1) # 扑克牌(花色='♥', 点数='A')
📌deque双端队列
队列:先进先出,后进后出
堆栈:先进后出,后进先出
队列和堆栈都是:一边只能进,另一边只能出
一般表示队列堆栈不用该模块,仅作了解
pop()尾部弹出 popleft()首部弹出
append()尾部追加 appendleft()首部追加
列表里可没有首部弹出、首部追加哦
from collections import deque
q = deque([1, 2, 3])
q.append(4) # 尾部追加4
q.appendleft(0) # 首部追加0
print(q) # deque([0, 1, 2, 3, 4])
print(q.pop()) # 4 【队列:取出最后面的】
print(q.popleft()) # 0 【堆栈:取出最前面的】
📌OrderedDict有序字典
使用字典时K键是无序的,当想对字典做迭代时没办法保证K键的顺序。
如果想让字典有顺序则可以用有序字典
补充了解:3.6版本解释器后字典都变成按照插入顺序来的了。
d=dict()
d['name']='jason'
d['age']=18
d['job']='teacher'
for i in d:
print(i)
______________________________
from collections import OrderedDict
d=OrderedDict()
d['name']='jason'
d['age']=18
d['job']='teacher'
for i in d:
print(i)
📌defaultdict默认值字典
普通字典打印没有的键时会报错,defaultdict则会返回空
d1 = dict()
from collections import defaultdict
d2 = defaultdict(list)
print(d1['a']) # 报错
print(d2['a']) # []
📌Counter计数器
主要用来统计出现次数
#方式一:
from collections import Counter
c=Counter('aabbbccc')
print(c)
#结果为:Counter({'b':3,'c':3,'a':2})
#方式二:
s1 = 'aabbbccc'
new_dict = {}
for i in s1:
if i not in new_dict:
new_dict[i] = 1
else:
new_dict[i] += 1
print(new_dict)
#结果为:{'a':2,'b':3,'c':3}
2.time与datetime时间模块
🍊time时间模块
三种时间的表现形式:
1.时间戳 (从1970年1月1日0时0分0秒到现在的时间)
2.结构化时间(主要给计算机看的时间)
3.格式化时间(主要给人看的时间)
#其他用法:time.sleep(10) 让程序停止10秒
#1.时间戳
import time
print(time.time())
#结果为:1666174527.7080512
"""
一般用于在某个代码前后加,用来得出该代码执行时间
"""
#2.结构化时间
import time
print(time.localtime())
#结果为:查看本地时间
print(time.gmtime())
#结果为:查看UTC时间 英国伦敦
#3.格式化时间
import time
print(time.strftime('%Y-%m-%d %H:%M:%S'))
#结果为:2022-10-19 18:25:23
print(time.strftime('%Y-%m-%d'))
#结果为:2022-10-19
"""
%Y 年 | %m 月 | %d 日
%H 时 | %M 分 | %S 秒
"""
🍊datetime时间模块
"""
datetime 年月日时分秒
date 年月日
time 时分秒
"""
#获取今天【年月日 时分秒】
import datetime
res = datetime.datetime.today()
print(res) # 结果为:2022-10-19 18:48:04.737998
"""
res.year 年
res.month 月
res.isoweekday() 星期几
"""
——————————————————————————————————————
#获取今天【年月日】
import datetime
res1 = datetime.date.today()
print(res1) # 结果为:2022-10-19
【补充】:时间间隔
t1 = datetime.date.today() # 获取当前年月日
print(t1) # 2022-10-19
t2 = datetime.timedelta(days=3) # 定义时间间隔为3天
print(t1 + t2) # 2022-10-22
【补充】:指定日期时间
c = datetime.datetime(2022,5,23,12)
print(c)
#结果为:2022-05-23 12:00:00
3.random随机数模块
import random
"""随机打印数字"""
print(random.random())#产生一个从0~1的小数
print(random.randint(1,5))#产生一个从1~5的小数
print(random.randrange(1,10,2))#产生一个从1~10的奇数
"""从数据集中随机打印数据"""
print(random.choice([1,2,3]))#随机打印一个列表中的数据值
print(random.choices([1,2,3]))#随机打印一个列表中的数据值并组成列表
print(random.sample([1,2,3],2))#随机打印两个列表中的数据值并组成列表
"""打乱数据集顺序"""
l1=[1,2,3,4,5]
random.shuffle(l1)#把列表中的数据随机打乱顺序
print(l1)
练习:产生一个4位验证码,要包含大小写字母和数字
def func(n):
yzm=''
for i in range(n):
#1.先产生随机的大小写字母、数字
random_upper=chr(random.randint(65,90))
random_lower=chr(random.randint(97,122))
random_int=str(random.randint(0,9))#字符串不能和整数相加,所以转换成字符串
#2.把随机生成的字符三选一
temp=random.choice([random_upper,random_lower,random_int])
yzm+=temp
return yzm
res=func(4)
print(res)
4.os模块
import os
os模块主要是当前程序与所在的操作系统打交道
1).创建目录(文件夹)
在执行文件所在的路径下创建目录
mkedirs()创建目录
(1)创建多级目录 # 常用
os.makedirs(r'md2') #可创建单级
os.makedirs(r'md2\md3') #也可以创建多级
(2)创建单级目录 # 不常用
os.mkdir(r'md')
2).删除目录(文件夹)
rmdir()删除空的单级目录
removedirs()删除空的多级目录
(1)删除'空的单级目录' # 目录下不能有任何文件
os.rmdir(r'md1')
(2)删除'空的多级目录' # 从内到外删除,直到某目录下有其他文件为止
os.removedirs(r'md2\md3\md4\md5')
3)列举指定路径下所有文件、目录名
结果会以列表展示
listdir()举例路径下所有文件、目录名
print(os.listdir(r'md2\md3'))
# 不写路径则是执行文件路径下所有文件、目录名
4)重命名文件\目录
rename()重命名文件、目录
os.rename(r'lx.py',r'lxx.py') # 给某文件重命名
os.rename(r'md1',r'md11') # 给某目录重命名
5)删除文件(py文件)
remove()删除文件
os.remove(r'lx.py') # 删除某文件
6)获取、切换当前工作路径
getcwd()获取当前工作路径
chdir('..')切换到上一级目录
print(os.getcwd()) # D:\pythonProject1\day19
os.chdir('..') #切换到上一级目录中
print(os.getcwd()) # D:\pythonProject1
7)动态获取项目路径(重要!)
dirname(__file__)项目根路径
abspath(__file__)执行文件绝对路径
(1)动态获取'项目根路径'********
print(os.path.dirname(__file__))
# D:/pythonProject1/day19
(2)动态获取项目'根路径的上一级路径'
print(os.path.dirname(os.path.dirname(__file__)))
# D:/pythonProject1/day19
(3)动态获取执行文件的'绝对路径'
print(os.path.abspath(__file__))#D:\pythonProject1\day19\run.py
8)判断路径是否存在
exists()判断路径是否存在
isdir() 判断路径是否是目录
isfile() 判断路径是否是文件
'结果为布尔值'
(1)判断路径是否存在
print(os.path.exists(r'路径')) # 可以是详细的文件夹或py文件
#结果为:True/False
(2)判断路径是否是目录(文件夹)
print(os.path.isdir(r'路径'))
(3)判断路径是否是文件(py文件)
print(os.path.isfile(r'路径'))
9)拼接路径
join()拼接路径
项目中涉及路径拼接时不要自己去手动做,要【动态获取】
join方法会自动识别当前操作系统并转换分割符号:windows用:\ mac用:/
a=r'D:\aa'
b=r'a.txt'
new_path=os.path.join(a,b) #将a和b拼接
print(new_path) # D:\aa\a.txt
10)获取文件大小
大小单位是:bytes字节
print(os.path.getsize(r'a.txt')) # 29
5.sys模块
import sys
sys模块主要是当前程序与python解释器打交道
(1)获取执行文件的环境变量
print(sys.path)
(2)获取最大递归深度 与 修改最大递归深度
print(sys.getrecursionlimit()) # 1000
sys.setrecursionlimit(2000) # 修改解释器最大递归深度
print(sys.getrecursionlimit()) # 2000
(3)获取当前解释器版本信息
print(sys.version)
#3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)]
(4)获取当前平台信息
print(sys.platform) # win32
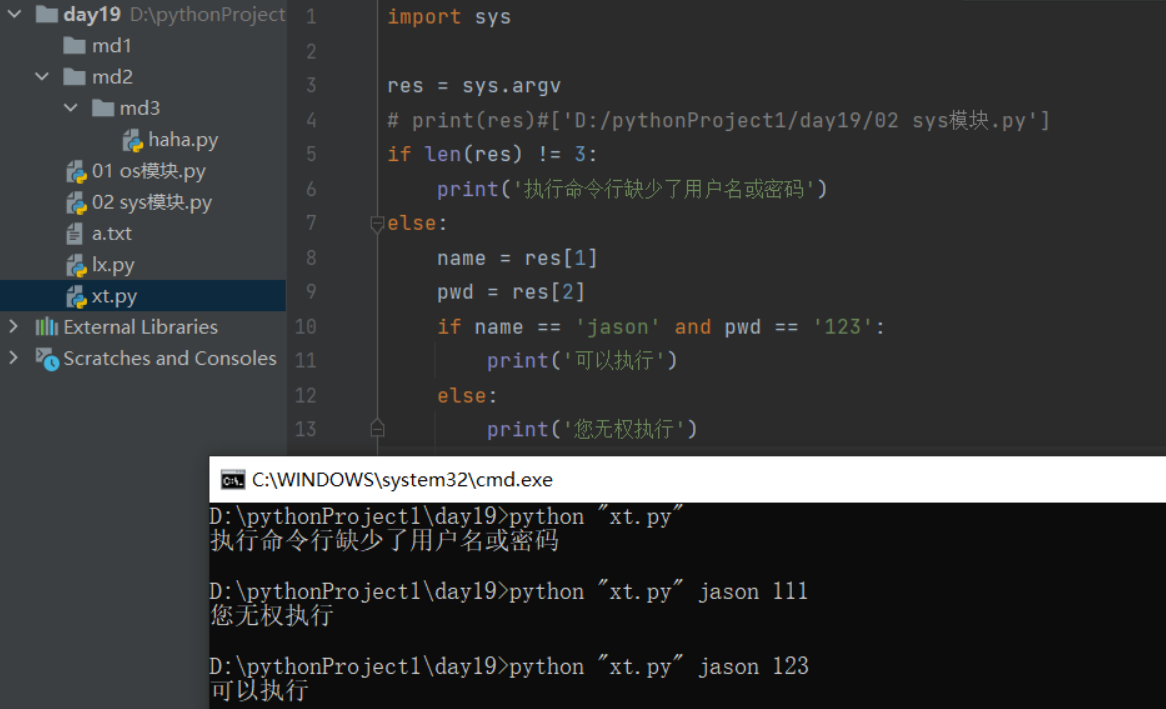
(5)实现从程序外向程序内传递参数
sys.argv #如下图
6.json模块
import json
🍥1.jason模块也称为:序列化模块,可以让不同的编程语言之间交互!
🍥2.序列化:将字典、列表等内容转换成一个字符串的过程就叫序列化
⛅3.jason格式数据属于什么类型:由于数据基于网络传输只能用二进制,python中只有字符串可以调用encode编码转二进制,所以json格式的数据也属于字符串
⛅4.json格式数据特征:字符串类型 且 引号是双引号
#针对数据
json.dumps() 将其他数据类型转换成json格式字符串
json.loads() 将json格式字符串转换成对应数据类型
#针对文件
json.dump() 将其他数据类型以json格式字符串'写入文件'
json.load() 将文件中json格式字符串读取出来并转换成对应的数据类型
(1)针对数据练习
import json
d1 = {'name': 'jason', 'pwd': '123'}
d2 = json.dumps(d1) # 将字典数据转成json格式数据
print(d2)
#{"name": "jason", "pwd": "123"}
d3 = json.loads(d2) # 将json格式数据转成原来的数据格式
print(d3)
#{'name': 'jason', 'pwd': '123'}
(2)针对文件练习
import json
d1 = {'name': 'jason', 'pwd': '123'}
with open(r'info.txt', 'w', encoding='utf8')as f:
json.dump(d1, f ) # 将字典数据转成json格式写入文件中
with open(r'info.txt', 'r', encoding='utf8')as f:
res = json.load(f) # 将文件中的json格式数据转成字典
print(res) # {'name': 'jason', 'pwd': '123'}
(3)编写简易注册登录功能
#用户注册功能
import os
import json
#1.获取文件根目录路径
base_dir=os.path.dirname(__file__)#D:/pythonProject1/day19
#2.拼接db目录路径
db_dir=os.path.join(base_dir,'db')#D:/pythonProject1/day19\db
#3.校验当db目录路径不存在时创建db目录
if not os.path.isdir(db_dir):
os.makedirs(db_dir)
#4.获取用户信息 并 构造用户信息字典
username=input('注册username>>:').strip()
password=input('注册password>>:').strip()
d1={'name':username,'pwd':password}
#5.判断用户文件是否存在(拼接该用户路径来校验),不存在则创建
user_dir=os.path.join(db_dir,f'{username}.json')#D:/pythonProject1/day19\db\jason.json
if os.path.isfile(user_dir):
print('用户已存在')
else:
with open(user_dir,'w',encoding='utf8')as f:
json.dump(d1,f)
print(f'{username}注册成功')
# 用户登录功能
import os
import json
#1.获取文件根目录路径
base_dir=os.path.dirname(__file__)#D:/pythonProject1/day19
#2.拼接db目录路径
db_dir=os.path.join(base_dir,'db')#D:/pythonProject1/day19\db
#3.获取用户登录信息,并拼接用户信息路径
username=input('输入用户名:').strip()
user_dir=os.path.join(db_dir,f'{username}.json')
#4.判断用户信息路径是否存在
if not os.path.isfile(user_dir):
print('用户名不存在')
else:
password=input('输入密码:').strip()
#5.获取用户信息文件中的密码做校验
with open(user_dir,'r',encoding='utf8')as f:
user_dict=json.load(f)
if password == user_dict.get('pwd'):
print('登录成功')
else:
print('密码错误')
7.正则表达式
正则表达式是一门独立的技术,所有编程语言都可以使用
1)正则表达式含义:
正则表达式就是用一些特殊符号的组合产生特殊含义去字符串中筛选符合条件的数据。
也可以直接写需要查找的具体字符
主要就是用来筛选、匹配数据
正则表达式线上测试网址:http://tool.chinaz.com/regex/
2)正则表达式前戏:注册手机号校验
案例:京东注册手机号校验,需求:手机号必须11位、手机号必须13、14、15、17、18、19开头,且纯数字
"""纯python代码实现"""
while True:
phone_num = input('输入您的手机号:').strip()
if len(phone_num) == 11:
if phone_num.isdigit():
if phone_num.startswith('13') or phone_num.startswith('14') or phone_num.startswith(
'15') or phone_num.startswith('17') or phone_num.startswith('18') or phone_num.startswith('19'):
print('手机号码输入合法')
else:
print('手机号码格式错误')
else:
print('手机号码必须是纯数字')
else:
print('手机号码必须11位')
————————————————————————————————————————————
"""使用正则表达式实现"""
import re
while True:
phone_num=input('输入您的手机号:').strip()
if re.match('^(13|14|15|17|18|19)[0-9]{9}$',phone_num):
print('手机号合法')
else:
print('手机号不合法')
3).正则表达式—字符组
⛅1.字符组默认匹配方式是:一个一个的匹配(一个符号一次匹配一个内容)
⛅2.字符组内所有的数据默认都是或的关系
| 字符组简写 | 字符组全称 | 含义 |
|---|---|---|
| [0-9] | [0123456789] | 匹配0~9的任意一个数字 |
| [A-Z] | [ABC...XYZ] | 匹配A~Z的任意一个字母 |
| [a-z] | [abc...xyz] | 匹配a~z的任意一个字母 |
| [0-9a-zA-Z] | 匹配0~9任意数字、大小写任意字母 |
4).正则表达式—特殊符号
⛅1.字符组默认匹配方式是:一个一个的匹配(一个符号一次匹配一个内容)
| 特殊符号 | 含义 |
|---|---|
| . | 匹配处换行符外的任意字符 |
| \w | 匹配数字、字母、下划线 |
| \W | 匹配非数字、非字母、非下划线 |
| \d | 匹配数字 |
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的结尾 |
| ^数据$ | 两者组合使用可以精确限制匹配的内容 |
| a|b | 匹配a或b |
| () | 给正则表达式分组,不影响表达式的匹配 |
| [ ] | 字符组内部填写的内容默认都是或的关系 |
| [^] | 取反操作 匹配除了字符组内填写的其他字符 |
5).正则表达式—量词
⛅1.正则表达式默认情况下都是贪婪匹配(尽可能多的匹配)
⛅2.量词不能单独使用,必须结合表达式一起,且只能影响左边第一个表达式
| 量词 | 含义 |
|---|---|
| ***** | 匹配0次或多次 默认是多次 |
| + | 匹配1次或多次 默认是多次 |
| ? | 匹配0次或1次 默认是1次 |
| {n} | 重复n次 写几次就是几次 |
| {n,} | 重复n次或更多次 默认是多次 |
| {n,m} | 重复n到m次 默认是m次 |
6).正则表达式练习题
#正则表达式 待匹配字符 结果
海. 海燕海娇海东 海燕 海娇 海东
^海. 海燕海娇海东 海燕
海.$ 海燕海娇海东 海东
李.? 李杰和李莲英和李二棍子 李杰 李莲 李二
李.* 李杰和李莲英和李二棍子 李杰和李莲英和李二棍子
李.+ 李杰和李莲英和李二棍子 李杰和李莲英和李二棍子
李.{1,2} 李杰和李莲英和李二棍子 李杰和 李莲英 李二棍
李[杰莲英二棍子]* 李杰和李莲英和李二棍子 李杰 李莲英 李二棍子
李[^和]* 李杰和李莲英和李二棍子 李杰 李莲英 李二棍子
[\d] 456bdha3 4 5 6 3
[\d]+ 456bdha3 456 3
7).贪婪匹配与非贪婪匹配
⛅1.所有的量词都是贪婪匹配, 非贪婪匹配需要在量词后加问号
⛅2.贪婪匹配与非贪婪匹配结束是由左右两边添加的表达式决定的
待匹配的文本:
<script>alert(123)</script>
正则:
<.*> # 贪婪匹配
结果:
<script>alert(123)</script>
————————————————————————————————————————
待匹配的文本:
<script>alert(123)</script>
正则:
<.*?> # 非贪婪匹配
结果:
<script>
</script>
8).转义符
"""斜杠与字母的组合有时候有特殊含义"""
\n 匹配的是换行符
\\n 匹配的是文本\n
\\\\n 匹配的是文本\\n
#在python中 可以在字符串前加r取消转义
9).正则表达式实战建议
1.编写校验用户身份证号的正则
\d{17}[\d|x]|\d{15}
2.编写校验邮箱的正则
\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}
3.编写校验用户手机号的正则
0?(13|14|15|17|18|19)[0-9]{9}
4.编写校验用户电话号的正则
[0-9-()()]{7,18}
5.编写校验用户qq号的正则
[1-9]([0-9]{5,11})
#很多时候有的正则已经有人帮我们做好了,只需要百度查到即可
8.re模块
在python中使用正则,re模块是 选择之一
1).re模块基本使用
🍨1.findall 查找所有符合正则表达式要求的数据 结果直接是一个列表
# 在文本中筛选出符合a的所有内容,结果为列表
import re
res=re.findall('a','abcabca')
print(res) # ['a', 'a', 'a']
🍨2.finditer查找所有符合正则表达式要求的数据 结果直接是一个迭代器对象
import re
res=re.finditer('a','abcabca')
print(res) # <callable_iterator object at 0x000001FFA8AD7220>
print(res.__next__()) # <re.Match object; span=(0, 1), match='a'>
print(res.__next__().group()) # a
🍨3.search匹配到一个符合条件的数据就立刻结束
import re
res=re.search('a','abcabca')
print(res) # <re.Match object; span=(0, 1), match='a'>
print(res.group()) #a
🍨4.match从头开始匹配,如果头不符合就结束
import re
res=re.match('a','abcabca')
print(res) # <re.Match object; span=(0, 1), match='a'>
res1=re.match('b','abcabca')
print(res1) # None
🍨5.compile提前准备好正则,后续可以反复使用减少代码的冗余
import re
obj=re.compile('a')
print(re.findall(obj,'abcabca')) # ['a', 'a', 'a']
print(re.findall(obj,'asssdaada')) # ['a', 'a', 'a', 'a']
print(re.findall(obj,'ddffee123a')) # ['a']
🍨6.split分割
1.按照a分割得到''和'bcd'
res = re.split('[a]','abcd')
print(res) # ['', 'bcd']
#res后可以跟索引,索引0为空(不是None),索引1为bcd
2.按照a分割得到''和'bcd',再对''和'bcd'按照b分割得到''和'cd'
res = re.split('[a,b]','abcd')
print(res) # ['', '', 'cd']
🍨7.sub替换
1.把数字全部替换成'H'
res = re.sub('\d','H','abc123')
print(res) # abcHHH
2.把某个数字替换成'H'
res = re.sub('1','H','abc123123')
print(res) # abcH23H23
🍨8.subn替换
1.把数字替换成'H',并返回元组#(替换的结果,替换的次数)
res = re.subn('\d','H','abc1231')
print(res) # ('abcHHHH', 4)
2).re模块补充使用
(1)分组优先
🍨1.findall分组优先展示:优先展示括号内正则表达式匹配到的内容
res=re.findall('www.(baidu|4399).com','www.4399.com')
print(res) # ['4399']
🍨2.取消分组优先展示(?:)
res=re.findall('www.(?:baidu|4399).com','www.4399.com')
print(res) # ['www.4399.com']
🍨3.search和match针对分组()里的正则表达式不影响
res=re.search('www.(baidu|4399).com','www.4399.com')
print(res.group()) # www.4399.com
res=re.match('www.(baidu|4399).com','www.4399.com')
print(res.group()) # www.4399.com
(2)分组别名
res=re.search('www.(?P<mingzi1>baidu|4399)(?P<mingzi2>.com)','www.4399.com')
print(res) # <re.Match object; span=(0, 12), match='www.4399.com'>
print(res.group()) # www.4399.com
print(res.group(0)) # www.4399.com
print(res.group(1)) # 4399
print(res.group(2)) # .com
print(res.group('mingzi1')) # 4399
print(res.group('mingzi2')) # .com
13.网络爬虫简介
1)什么是互联网?
将全世界的计算机连接到一起组成的网络
2)互联网发明的目的是什么?
让连接到互联网的计算机数据彼此共享
3)上网的本质是什么?
基于互联网访问其他人计算机上共享数据(服务器存在的意义就是让其他人来访问)
4)网络爬虫的本质是什么?
通过编写代码模拟计算机浏览器朝目标网址发送请求获取数据并筛选出想要的数据
5)有的页面存在防爬机制 数据无法直接拷贝获取(页面会校验是网页发送的请求还是代码发送的)
6)在做爬虫时有可能会被发现导致ip短暂拉黑,更不要爬用户敏感数据!
14.第三方模块
🍍第三方模块简介
第三方模块就是别人写好的模块,一般功能都很强大
想用第三方模块,必须要先下载才能使用!
🍍第三方模块的下载
1)cmd命令行下载
(1)下载必须借助pip工具(每个解释器都有pip工具)
如果电脑中有多个版本解释器,那就要加版本号来决定是下载到哪个版本解释器里。
python27 pip2.7
python36 pip3.6
python38 pip3.8
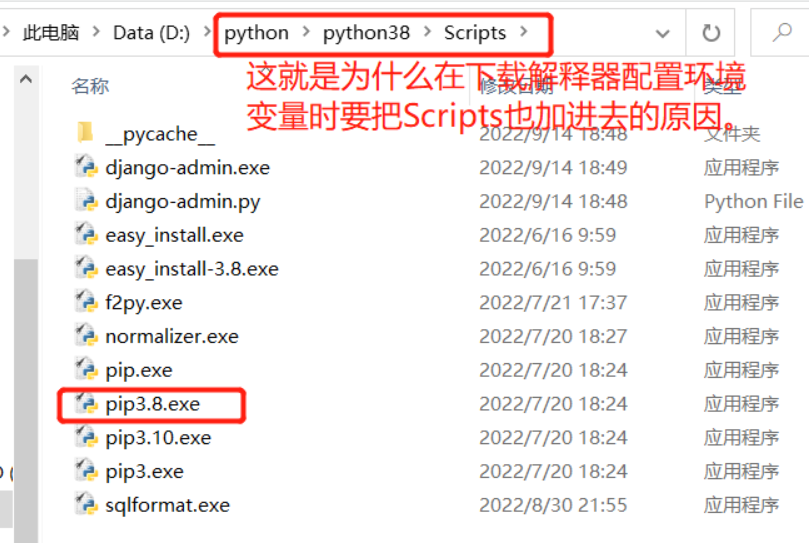
(2)下载第三方模块的句式
pip install 模块名
pip3.8 install 模块名
(3)下载第三方模块临时切换镜像源地址(常用的在最下面)
pip install 模块名 -i 镜像源地址
pip3.8 install 模块名 -i 镜像源地址
(3)下载第三方模块指定版本(不指定默认为最新版)
pip install 模块名==版本号 -i 镜像源地址
pip3.8 install 模块名==版本号 -i 镜像源地址
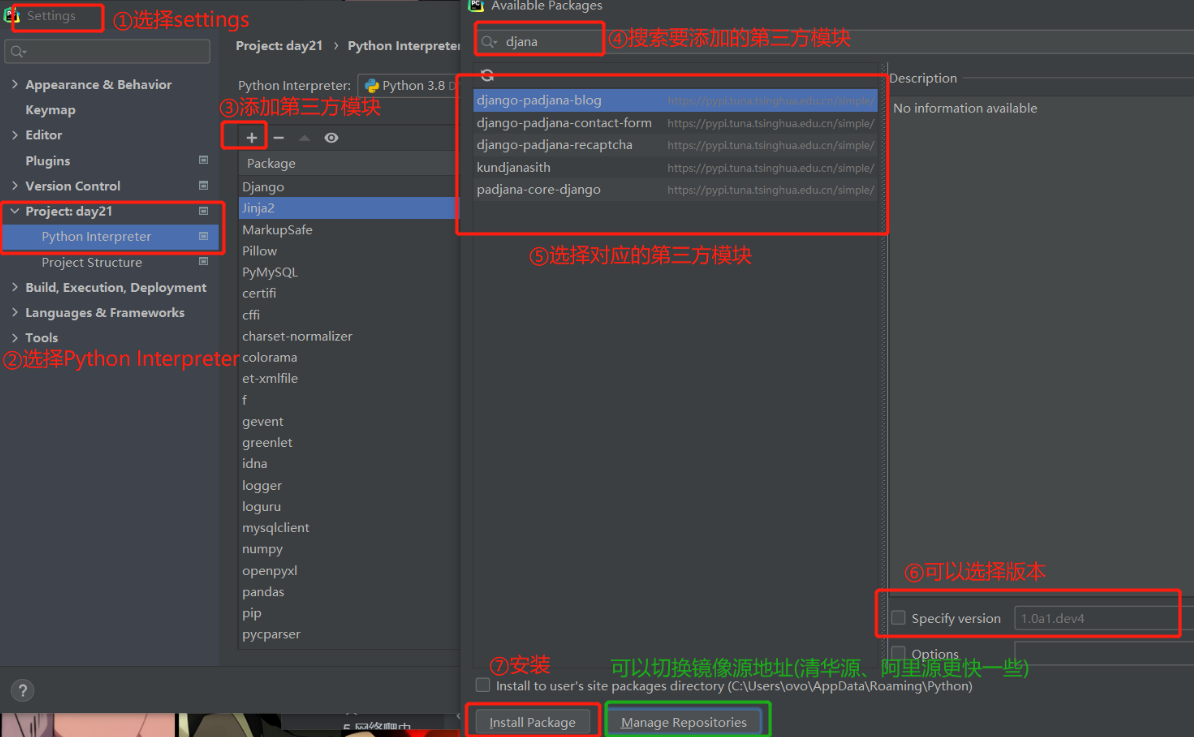
2)pycharm提供快捷下载方式
🍍第三方模块下载报错
(1)报错并有警告信息
eg:
WARNING: You are using pip version 20.2.1;
#这种是因为pip工具版本过低,拷贝后面的执行命令更新即可:
python38 -m pip install --upgrade pip
——————————————————————————————————————————————
(2)报错并有Timeout关键字
#说明当前计算机网络不稳定 只需要换网或者重新执行几次即可
——————————————————————————————————————————————
(3)报错并没有关键字
#有可能是需要配置特定环境自行百度即可
——————————————————————————————————————————————
(4)下载速度慢
#pip默认下载的镜像源地址是国外的地址可切换以下地址。
"""
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
"""
1.request模块(网络爬虫模块)
request模块可以模拟浏览器发送网络请求
朝指定网址发送请求获取页面数据(等同于浏览器地址栏输入网址按回车访问)
import request
res = requests.get('http://www.redbull.com.cn/about/branch')
# print(res.content) # 获取bytes二进制类型的网页数据
print(res.text) # 获取字符串类型的网页数据
2.网络爬虫实战
(1)爬红牛分公司数据
http://www.redbull.com.cn/about/branch
import re
import requests
# 1.朝目标地址发送网络请求
# res = requests.get('http://www.redbull.com.cn/about/branch')
# print(res.content)#获取二进制类型数据
# print(res.text)#获取文本类型数据
# 2.将二进制数据保存在html页面中
# with open(r'redbull.html', 'wb')as f:
# f.write(res.content)
# 3.获取页面字符串数据
with open(r'redbull.html', 'r', encoding='utf8')as f:
data = f.read()
# 4.用正则筛选出需要的数据
comp_name_list = re.findall('<h2>(.*?)</h2>', data)
comp_address_list = re.findall("<p class='mapIco'>(.*?)</p>", data)
comp_email_list = re.findall("<p class='mailIco'>(.*?)</p>", data)
comp_phone_list = re.findall("<p class='telIco'>(.*?)</p>", data)
# 5.导入pandas模块将数据保存在excel表格中
import pandas
d1 = {
'公司名称': comp_name_list,
'公司地址': comp_address_list,
'公司邮编': comp_email_list,
'公司电话': comp_phone_list
}
df = pandas.DataFrame(d1) # 将字典转成pandas里面的DataFrame数据结构
df.to_excel('readbull.xlsx') # 保存为excel文件
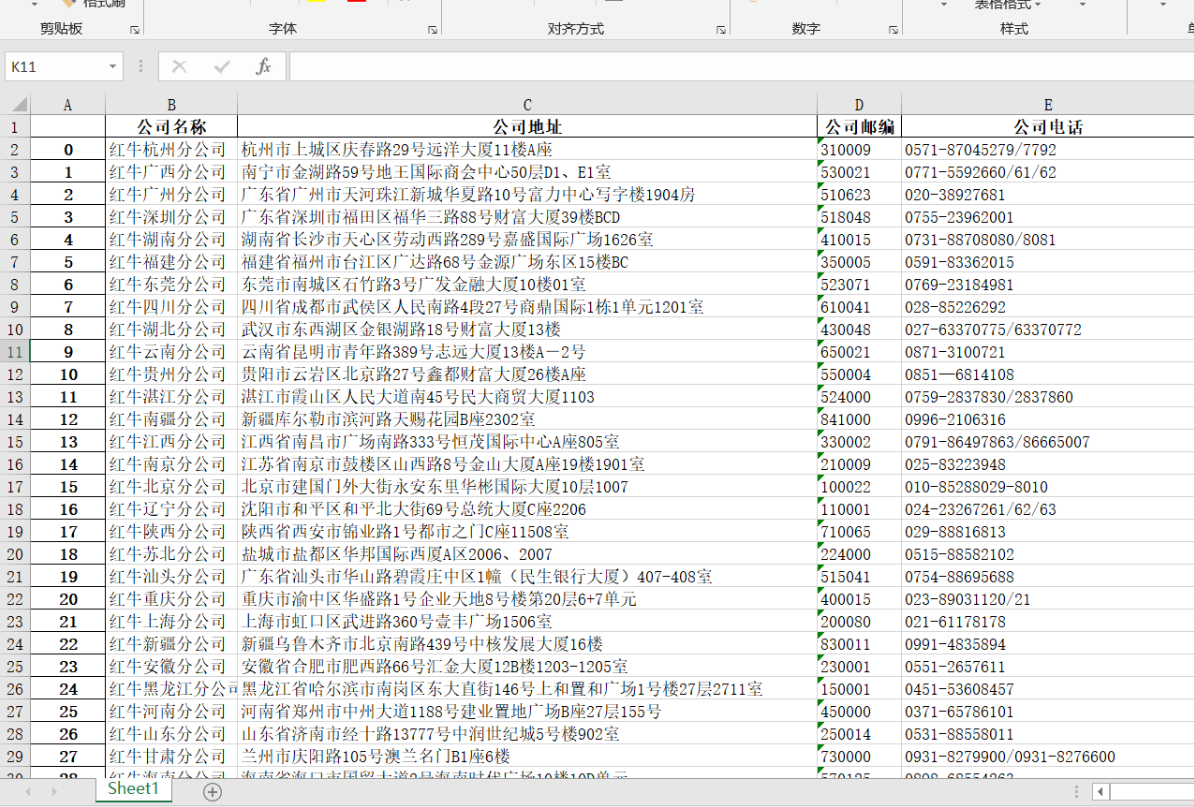
(2)爬链家二手房数据
https://sh.lianjia.com/ershoufang/pudong/
import re
import requests
# 1.朝目标地址发送网络请求
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/')
data = res.text
ljhome_title_list = re.findall('<a class="" href=".*?" target="_blank" data-log_index=".*?" data-el="ershoufang" data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>',data)
ljhome_name_list = re.findall('<a href=".*?" target="_blank" data-log_index=".*?" data-el="region">(.*?) </a>', data)
ljhome_street_list = re.findall('<div class="positionInfo"><span class="positionIcon"></span><a href=".*?" target="_blank" data-log_index=".*?" data-el="region">.*? </a> - <a href=".*?" target="_blank">(.*?)</a> </div>',data)
ljhome_info_list = re.findall('<div class="houseInfo"><span class="houseIcon"></span>(.*?)</div>', data)
ljhome_watch_list = re.findall('<div class="followInfo"><span class="starIcon"></span>(.*?)</div>', data)
ljhome_total_price_list = re.findall('<div class="totalPrice totalPrice2"><i> </i><span class="">(.*?)</span><i>万</i></div>', data)
ljhome_unit_price_list = re.findall('<div class="unitPrice" data-hid=".*?" data-rid=".*?" data-price=".*?"><span>(.*?)</span></div>', data)
import pandas
d1 = {
'房屋标题': ljhome_title_list,
'小区名称': ljhome_name_list,
'街道名称': ljhome_street_list,
'详细信息': ljhome_info_list,
'关注程度': ljhome_watch_list,
'房屋总价/万': ljhome_total_price_list,
'房屋单价': ljhome_unit_price_list,
}
df = pandas.DataFrame(d1)
df.to_excel('ljhome.xlsx')
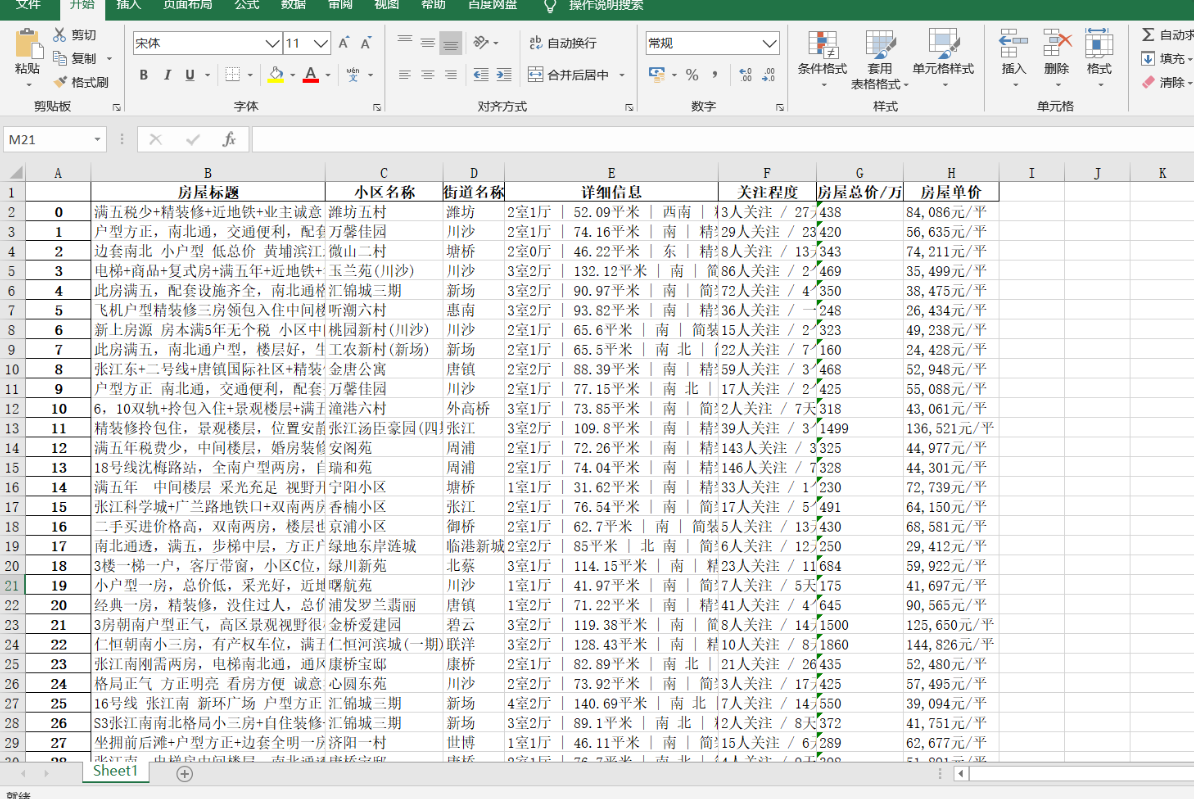
3.openpyxl模块(自动化办公)
主要用于操作excel表格,也是pandas模块底层操作表格的模块
1)excel文件的后缀名问题
excel2003版本之前后缀名为:.xls
excel2003版本之后后缀名为:.xlsx
2)可以操作excel表格的第三方模块
⛅openpyxl是近几年比较火的操作excel表格模块
但是针对03版本前的excel文件兼容较差
⛅xlwt(往表格中写数据)、xlrd(从表格中读数据)
兼容所有版本的excel文件,但是使用方法没openpyxl简单
⛅还有很多可以操作excel表格的模块:如pandas涵盖了上述模块的模块
3)创建文件、写入数据、保存数据操作
当该excel文件打开时不能做任何修改
不要忘记保存文件!!
(1).创建excel文件
from openpyxl import Workbook # 导入模块,Workbook是用来创建文件的
# 创建一个excel文件
wb = Workbook()
# 在excel文件中创建工作薄
wb1 = wb.create_sheet('学生名单')
# 在excel文件中创建工作薄 并 让该工作薄位置在最前面
wb2 = wb.create_sheet('老师名单', 0)
# 修改工作簿名称
wb2.title = '学生成绩单'
# 修改工作薄颜色
wb2.sheet_properties.tabColor = '1072BA'
"""
这里放写入数据的操作
"""
# 保存该excel文件
wb.save(r'学生信息.xlsx')
(2).在excel工作薄中写入数据
写入数据后不要忘记跟保存!
1)第一种写入方式:
wb2['A1'] = '张三' # 在A1单元格中写入'张三'
2)第二种写入方式:
wb2.cell(row=2,column=1,value='李四') # 在单元格第2行,第1列,写入'李四'
3)第三种写入方式:(批量写入)
#在单元格中最上方分别写入数据(如果有数据则在数据下一行写入)
wb2.append(['姓名','年龄','成绩'])
wb2.append(['王五','18','90'])
(3).填写数学公式
wb2['A5']='=sum(A1:A4)' # 在A5单元格写入sum公式
wb2.cell(row=5,column=1,value='=sum(A1:A4)') # 在第5行,第1列写入sum公式
(4).pandas模块也可实现数据写入
使用pandas模块时需注意字典里的V值必须是列表格式!
import pandas
company_name='腾讯'
company_address='深圳'
company_email='123@qq.com'
data={
'公司名称':[company_name,],
'公司地址':[company_address,],
'公司邮编':[company_email,],
}
df = pandas.DataFrame(data)#将字典转成pandas里面的DataFrame数据结构
df.to_excel('a.xlsx')#保存为excel文件
4)读取数据操作
openpyxl是读写分离的(写与读是两个不同的模块,需要在后面再加一个load_workbook)
"""
openpyxl不擅长读数据,所以有些模块优化了读取的方式:pandas模块
一般在公司会有专门的人负责读,python程序员只负责写出来
"""
#【创建写入数据】
from openpyxl import Workbook,load_workbook
# 创建一个excel文件
wb=Workbook()
# 创建sheet页
wb1=wb.create_sheet('第一个sheet页',0)
wb2=wb.create_sheet('第二个sheet页',1)
# 批量写入数据
wb1.append(['姓名','年龄'])
wb1.append(['jason','18'])
wb1.append(['torry','20'])
# 保存文件
wb.save('ipenpyxl写读练习.xlsx')
___________________________________________________________
#【读取数据】
# 1.查看文件中所有工作簿名称
print(wb.sheetnames) # ['第一个sheet页', '第二个sheet页', 'Sheet']
# 2.1.查看某工作簿中有几行数据,空数据默认为1行
print(wb1.max_row) # 3
# 2.2查看某工作簿中有几列数据,空数据默认为1列
print(wb1.max_column) # 2
# 3.1.读取wb1中A1单元格的数据
print(wb1['A1'].value) # 姓名
# 3.2.读取wb1中第2行第1列的数据
print(wb1.cell(row=2,column=1).value) # jason
# 4.读取整行数据并组成列表
for i in wb1.rows:
print([j.value for j in i]) # ['姓名', '年龄'] ['jason', '18'] ['torry', '20']
# 5.读取整列数据并组成列表
for i in wb1.columns:
print([j.value for j in i]) # ['姓名', 'jason', 'torry'] ['年龄', '18', '20']
4.pandas模块
封装了openpyxl模块的模块 主要也是操作表格的,如上面的爬虫爬取到数据后用pandas保存到excel表中
import pandas
d1 = {
'公司名称': ['腾讯', '飞讯', '跑讯'],
'公司地址': ['上海', '杭州', '深圳'],
}
df = pandas.DataFrame(d1) # 将字典转成pandas里面的DataFrame数据结构
df.to_excel(r'公司信息.xlsx') # 保存为excel文件
5.hashlib加密模块
1).什么是加密?
将明文数据经过处理后变成密文数据的过程就是加密
2).为什么要加密?
不想让敏感数据轻易泄露
3).如何判断当前数据是否已加密?
一般加密的都是一串没有规则的字母、数字、符号的组合
4).加密算法就是对铭文数据采用的加密策略
不同的加密算法复杂程度也不同,得出的密文长度也不同
一般密文越长说明算法越复杂
5).常见的加密算法
md5、sha系列、hmac、base64
6).代码实操
import hashlib
# 选择加密算法
md5 = hashlib.md5()
# 传入明文数据(传入的必须是二进制)
md5.update(b'hello')
# 获取加密密文
res = md5.hexdigest()
print(res) # 202cb962ac59075b964b07152d234b70
————————————————————————————————————————————————————
import hashlib
# 获取用户输入密码
password = input('输入密码:').strip()
# 选择加密算法
md5 = hashlib.md5()
# 传入明文数据(传入的必须是二进制)
md5.update(password.encode('utf8'))
# 获取加密密文
res = md5.hexdigest()
print(res)
7).注意事项
(1)相同内容不管分几次传结果都一样
加密算法不变 内容如果相同那么结果肯定相同
import hashlib
# 选择加密算法
md5 = hashlib.md5()
# 传入明文数据
# md5.update(b'aa~bb~')
md5.update(b'aa~')
md5.update(b'bb~')
# 获取加密密文
res = md5.hexdigest()
print(res)
#发现只要是相同的明文,不管是一次性传入还是分多次传入结果都一样
(2)加密后的结果无法反解密
只能从明文到密文正向推导,不能密文到明文反向推导
常见的解密其实是提前预测了很多结果去一对一匹配
(3)加盐处理
在明文中假如一些额外干扰项
import hashlib
md5 = hashlib.md5()
md5.update('加盐'.encode('utf8')) # '加盐'为干扰项
md5.update(b'123456')
res = md5.hexdigest()
print(res)
(4)动态加盐
干扰项是随机变化的(当前时间、用户名..)
(5)加密实际应用场景
1.用户加密
注册存储的是密文,'登录校验时也是在对比密文'
2.文件安全性内容加密校验
正规的软件程序写完都会做一个'内容加密',用户下载完软件后会'先对比加密后的密文是否一致',不一致可能被植入了病毒,一致则运行软件
3.大文件内容加密
当一个文件特别大时,一次性加密效率太低
所以会采用'截取一部分来加密'
#os.path.getsize() 获取文件大小
6.subprocess模块
模拟操作系统终端 执行系统命令并获取结果
import subprocess
cmd = input('输入cmd指令:').strip()
res = subprocess.Popen(
cmd, # 获取用户要执行的指令
shell=True, # 固定配置
stdin=subprocess.PIPE, # 输入指令
stdout=subprocess.PIPE, # 输出结果
)
# 获取操作系统执行命令后的正确结果
print('正确结果:', res.stdout.read().decode('gbk'))
# 获取操作系统执行命令后的错误结果
print('错误结果:', res.stderr)
windows系统底层默认的编码为GBK(特定区域)
7.logging日志模块
1)如何理解日志
简单的理解就是记录行为举止的操作
2)日志的五种级别
import logging
logging.debug('debug等级') # 10 默认不显示
logging.info('info等级') # 20 默认不显示
logging.warning('警告的') # 30 默认从warning级别开始记录
logging.error('已经发生的') # 40
logging.critical('灾难性的') # 50
3)日志模块的要求与基本使用
无需掌握,了解怎么用即可
import logging
# 产生一个日志文件,文件叫x1.log,用a追加模式,编码为utf8
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf8',)
logging.basicConfig(
# 日志格式
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# 年月日 时分秒 上午下午
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
# ERROR级别
level=logging.ERROR)
logging.error('你好')
4)日志的四个组成部分
1.loger对象:产生日志
2.filter对象:过滤日志(基本不用,因为产生日志时就可以控制想要的日志内容)
3.handler对象:输出对象
4.format对象:日志格式
import logging
# 1.日志的产生(准备原材料) logger对象
logger = logging.getLogger('购物车记录')
# 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用
# 3.日志的产出(成品) handler对象
# hd1~hd3三选一
hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到a1.log文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到a1.log文件中
hd3 = logging.StreamHandler() # 输出到终端
# 4.日志的格式(包装) formmat对象
# fm1与fm2格式复杂度二选一即可
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.给handler绑定formate对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(10) # debug
# 8.记录日志
logger.debug('写了半天 好累啊 好热啊')
5)日志配置字典
import logging
import logging.config
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
logfile_path = 'a3.log'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
# logger1 = logging.getLogger('购物车记录')
# logger1.warning('尊敬的VIP客户 晚上好 您又来啦')
# logger1 = logging.getLogger('注册记录')
# logger1.debug('jason注册成功')
logger1 = logging.getLogger('红浪漫顾客消费记录')
logger1.debug('慢男 猛男 骚男')
6)日志模块实战应用
详情可看day23各项目目录
1.#【start.py】 先找到根目录路径 添加到sys.path中(为了兼容让任何人打开都可以找到根目录)
import os
import sys
base_dir=os.path.dirname(os.path.dirname(__file__))
sys.path.append(base_dir)
if __name__ == '__main__':
from ATM.core import src
src.run()
2.#【settings.py】 将日志代码写在配置文件中
import os
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
#logfile_path = 'a3.log'
BASE_DIR=os.path.dirname(os.path.dirname(__file__))
LOG_DIR=os.path.join(BASE_DIR,'log')
if not os.path.exists(LOG_DIR):
os.makedirs(LOG_DIR)
logfile_path=os.path.join(LOG_DIR,'log.log') # 【可以起一个日志名字.log】
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5, # 最多保存5份5M的文件,个数够了就删第一个
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
3.#【common.py】 公共功能文件中创建一个函数,谁用谁调
import logging
import logging.config
from conf import settings
def get_my_logger(name):
logging.config.dictConfig(settings.LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger(name)
return logger1
4.#【user_interface.py】 接口层调用公共文件里的日志函数
from ATM.lib import common
my_log = common.get_my_logger('用户相关记录') # 【给该日志起名】
def register_interface():
my_log.info('xxx注册成功') # 【info级别记录日志内容】
def login_interface():
my_log.debug('xxx登录成功') # 【debug级别记录日志内容】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号