文件操作
一.字符编码
1.字符编码简介
1)字符编码只针对文本数据
2)计算机内部存储数据的本质是二进制,也就是计算机只认识0和1的二进制
3)之所以我们打出来的字可以被计算机识别是因为中间有一层转换关系:字符编码表
2.字符编码发展的三个阶段
阶段一:一家独大
由于计算机是美国人发明的,为了让计算机可以识别英文所以发明了ASCII码。ASCII码中记录了英文字母跟数字的对应关系。
用1字节来表示一个英文字符
A~Z 65~90
a~z 97~122
阶段二:群雄割据
各国有了自己的字符编码:
中国:GBK码,记录中文、英文与数字的对应关系
两个字节存储一个字符
日本:shift_JIS码,记录日文、英文与数字的对应关系
韩国:Euc_kr码,记录韩文、英文与数字的对应关系
PS:此时各个国家之间编码不一致,不同数据无法直接交互会出现乱码!
阶段三:天下一统
万国码(unicode):兼容多个国家语言与数字的对应关系。但是所有字符都是采用2字节来表示一个字符!
后来utf家族发布了优化版:utf8。英文采用1字节,中文3字节
PS:内存使用unicode,硬盘采用utf8
3.字符编码相关操作
只有字符串可以参与编码解码,其他数据类型需要先转换成字符串才可以
1)解决乱码的措施
1.当初用什么编码存的就用什么编码解码
2.一个一个切换尝试
2)编码与解码
【编码】:人类字符>>计算机字符
将人类字符按照指定的编码编成计算机可以识别的数字
#encode()编码
s1 = '张三'
res = s1.encode('utf8')
print(res)
#结果为:b'\xe5\xbc\xa0\xe4\xb8\x89'
【解码】:计算机字符>>人类字符
将计算机可以识别的数字按照指定的编码解成人类字符
#decode()解码
res1 = res.decode('utf8')
print(res1)
#结果为:张三
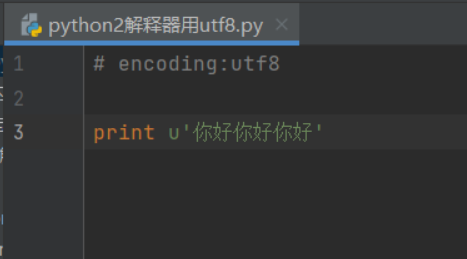
3)不同版本解释器的区别
python2默认的编码是ASCII,如果想用utf8则需要:
1.文件最开头输入:#encoding:utf8
2.每一个字符串前面都要加u: print u'你好你好你好'
python3默认的编码是utf8
二.文件操作
1.文件的概念
文件就是操作系统给用户操作硬盘的快捷方式
双击一个文件图标就是从硬盘把数据加载到内存
保存文件就是把内存中的数据刷到硬盘中保存
2.文件的操作方式
【方式一】:
不常用!因为需要自己调用close()关闭文件方法
变量名 = open('文件路径','读写模式','字符编码')
f = open('a.txt','r',encoding='utf8')
print(f.read())#读取该文件内容
f.close()#关闭该文件
【方式二】:
常用!不需要手动调用close()关闭文件方法
with open(r'文件路径','读写模式','字符编码')as 变量名:
with open(r'a.txt','r',encoding='utf8')as f:
print(f.read())#读取该文件内容
#注意: 针对路径(字母与撬棍的组合)可能会有特殊含义。所以在路径前加字母 r 可取消特殊含义
绝对路径:详细的地址
相对路径:以当前所在的路径去查找该文件的地址
'可一次性打开多个文件:'
with open(...)as f1,open(...)as f2:
print(f1.read())
print(f2.read())
3.文件的三种读写模式
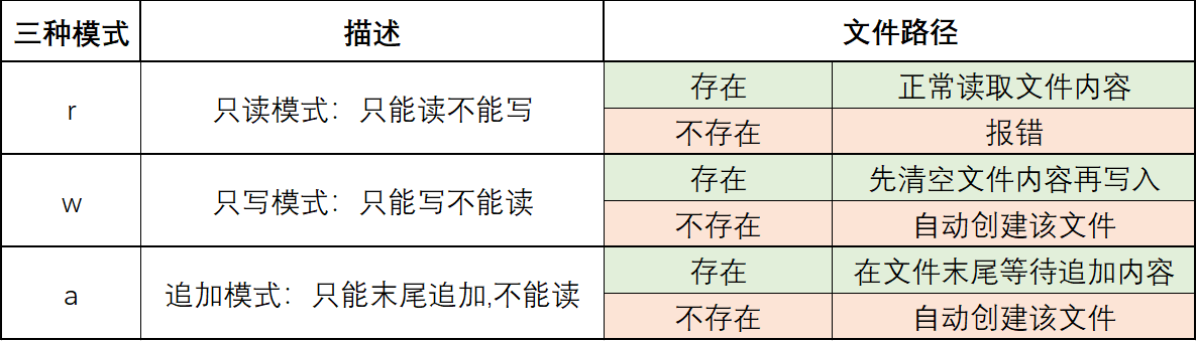
1.只读模式:只能读不能写
with open(r'a.txt','r',encoding='utf8')as f:
print(f.read())
#文件存在时:正常读取内容
#文件不存在:报错
2.只写模式:只能写不能读
with open(r'a.txt','w',encoding='utf8')as f:
f.write('阿巴阿巴')
#文件存在时:清空内容后写入数据
#文件不存在:创建该文件
3.追加模式:文件末尾追加数据,不能读
with open(r'a.txt','a',encoding='utf8')as f:
f.write('11111\n') # \n可换行追加
#文件存在时:在末尾追加新内容
#文件不存在:创建该文件
'写入的数据可跟\n换行追加,但需注意在做文本比较时有个\n在影响判断'
4.文件的操作模式
1.t 文本模式
文件操作的默认格式,r w a全称其实是rt wt at
r = rt
w = wt
a = at
1)只能操作'文本文件'
2)需指定encoding参数,不写会用系统默认编码
3)读写都是以'字符'为单位
2.b 二进制模式(bytes模式)#可以实现数据的拷贝
需自己指定不能省略
rb
wb
ab
1)可以操作'所有类型'文件
2)不用指定encoding参数(二进制不需要编码)
3)读写都是以'bytes字节'为单位
eg:
with open(r'1.jpg','rb')as f:
print(f.read())#打印读出来的数据就是二进制。用文本模式会报错!
练习:利用二进制模式实现文件拷贝:
#二进制读模式打开一个文件,再用二进制写模式打开另一个文件
with open(r'11.jpg','rb')as f1,open(r'22.jpg','wb')as f2:
#用for循环把f1中的内容一行行打印出来,目的是不占用较大内存
for i in f1:
#把f1中循环的内容写给f2即可实现拷贝
f2.write(i)
5.文件的诸多方法
1.read()
一次性读取文件内容且光标会停留在文件末尾 继续读取则没内容
1)'当文件数据较大且涉及多行时建议使用for循环'
for i in f:
print(i)
#结果会把文件内容一行行显示出来(区别在于用完第一行会自动清除不占用内存)
2)'read()括号内可以跟数字 在文本模式下表示读取几个字符'
print(f.read(5))
#结果会读取5个字符
3)'括号内的数字 在二进制模式下表示读取几个字节'
#一个英文1字节 一个中文3字节
2.readline()
一次只读一行内容,执行多次才可以读多行
3.readlines()
一次性读取文件内容 按照行数组成列表的形式#注意换行符
#结果为:['aa\n', 'bb\n', 'cc']
4.readable()
判断文件是否具备读数据的能力#结果为布尔值
5.write()
写入数据#注意读写模式中是否是清除后填写
6.writeable()
判断文件是否具备写数据的能力#结果为布尔值
7.writelines()
接收一个列表 一次性将列表中所有数据写入
f.writelines(['a\n','b\n'])
#运行后该文件就会a和b各占一行。 注意换行符
8.flush()
将内存中文件数据立刻刷到硬盘中 类似于保存
6.文件的光标移动
seek(offset,whence)
offset:控制光标移动的位移量 #字节为单位
whence:移动的模式
0是基于文件开头 #文本和二进制模式都可以使用
1是基于光标当前位置 #只能二进制模式使用
2是基于文件末尾 #只能二进制模式使用
文本模式下练习:
with open(r'a.txt','r',encoding='utf8')as f:
print(f.read()) # 张三说要努力学习
f.seek(6,0) # 移动6个字节(2个中文字符),基于文件开头
print(f.read()) # 说要努力学习
二进制模式下练习:
with open(r'a.txt','rb')as f:
# print(f.read().decode('utf8'))# 张三说要努力学习
f.seek(6,1) # 移动6个字节(2个中文字符),基于当前光标位置开头
print(f.read().decode('utf8'))# 说要努力学习
'如果第一个不注释掉 第二个则打印不出来 原因是当前光标已经在最后面 没有数据可读取'
with open(r'a.txt','rb')as f:
print(f.read().decode('utf8')) # 张三说要努力学习
f.seek(-3,2) # 移动3个字节(1个中文字符),基于文件末尾
print(f.read().decode('utf8')) # 习
'因为是在文件末尾,所以第一个参数用负数表示 则代表倒数第一个'
tell()可获取当前光标移动了多少字节数(不是字符数)
with open(r'a.txt','rb')as f:
print(f.read().decode('utf8'))#张三说要努力学习
f.seek(-6,2)
print(f.read(3).decode('utf8'))#学
print(f.tell()) #21
7.文件内光标移动案例
#监控文件新增数据案例:
import time
with open(r'a.txt', 'rb') as f:
f.seek(0, 2)#光标基于文件末尾移动0字节
while True:
line = f.readline()#一次性读取文件内容并按照行数组成列表形式
if len(line) == 0:#判断文件内容长度如果=0
time.sleep(0.5)#让程序睡眠0.5秒,目的是让cpu休息一下。否则会变成死循环一直在判断
else:
print(line.decode('utf8'), end='')#此时只要该文本文件中新增加了内容这里都会打印出来
8.计算机硬盘修改数据的原理(了解)
1.硬盘修改数据:就是覆盖在原来的数据上
2.硬盘删除数据:从占有态改为自由态(看不到不代表不存在)。只有被覆盖了才算真正删除
9.文件内容修改(了解)
方式一:覆盖写
先读取文件内容到内存,在内存中完成修改,然后w模式打开该文件写入
with open(r'a.txt','r',encoding='utf8')as f:
data = f.read()#将文本文件中的内容赋值给data
with open(r'a.txt','w',encoding='utf8')as f1:
f1.write(data.replace('张三','李四'))#将文本中的张三换成李四然后写入在f1中
"""
优点:是覆盖的模式去修改,硬盘只占用一块空间
缺点:当数据较大时会造成内存溢出
"""
方式二:重命名
先读取文件内容到内存,在内存中完成修改,然后保存到另一个文件,再将源文件删除并将新文件命名为原文件
#执行的速度太快其实就是删除文件后把第二个文件重命名
import os
with open(r'a.txt','r',encoding='utf8')as f1,open(r'aa.txt','w',encoding='utf8')as f2:
for i in f1:
f2.write(i.replace('张三', '李四'))
os.remove('a.txt') # 删除文件
os.rename('aa.txt', 'a.txt') # 重命名文件
"""
优点:不会造成内存溢出
缺点:可能临时需要占用硬盘两个地方的空间
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号